







使用场景:主要用于索引,以提高搜索数据速度
例如百度搜索
运行环境:windows下VM虚拟机,centos系统,hadoop2.2.0,三节点 ,java 1.7
需要处理的数据为
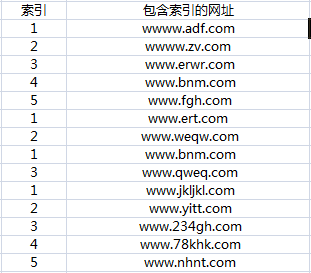
求出每个索引所对应的包含索引的网址
package boke;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class descSort extends Configured implements Tool{
//map任务主要是把每行数据切分,把索引作为key,网址作为vaule
public static class Map extends
Mapper<LongWritable,Text,Text,Text>
{
public void map(LongWritable key,Text value,Context context)throws InterruptedException,IOException
{
String[] lineSplit=value.toString().split(" ");
context.write(new Text(lineSplit[0]), new Text(lineSplit[1]));
}
}
//reudce阶段是把相同key(索引)的网址统一放到集合中,再统一输出
public static class Reduce extends Reducer<Text,Text,Text,Text>
{
public void reduce(Text key,Iterable<Text> values,Context context)throws InterruptedException,IOException
{
StringBuffer sb =new StringBuffer();
boolean sign=false;
for(Text id : values)
{
if(sign)
{
sign=true;
}
else
{
sb.append(" ");
}
sb.append(id.toString());
}
context.write(key, new Text(sb.toString()));
}
}
public int run(String[] args)throws Exception
{
Configuration conf=getConf();
Job job=new Job(conf,"descSort");
job.setJarByClass(descSort.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
//这里用了combiner可聚合每个map结果,减少reduce传输数据容量,从而优化性能
job.setCombinerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
return job.isSuccessful()?1:0;
}
public static void main(String[] args)throws Exception
{
int rsa=ToolRunner.run(new Configuration(), new descSort(), args);
System.exit(rsa);
}
}
运行结果

注:combiner和reduce阶段对数据处理的方法相同,如
(1 ,wwww.adf.com)(1 ,www.ert.com)
在combiner阶段会合并成(1,wwww.adf.com www.ert.com)
map阶段结束后会把数据存在本地,reduce阶段把需要的数据通过网络传输到reduce节点本地,combiner可聚合map的结果,从而降低传输数据的大小,优化性能















 4811
4811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









