




 倒排索引是搜索引擎的重要数据结构,用于快速定位单词到文档的映射。本文介绍了如何使用MapReduce实现倒排索引,包括文档倒排算法、基本结构、实验任务、设计细节如value-to-key转换、Combiner、Partitioner和Reducer的设计。同时讨论了在实现过程中遇到的问题和解决方案。
倒排索引是搜索引擎的重要数据结构,用于快速定位单词到文档的映射。本文介绍了如何使用MapReduce实现倒排索引,包括文档倒排算法、基本结构、实验任务、设计细节如value-to-key转换、Combiner、Partitioner和Reducer的设计。同时讨论了在实现过程中遇到的问题和解决方案。
文档倒排算法简介
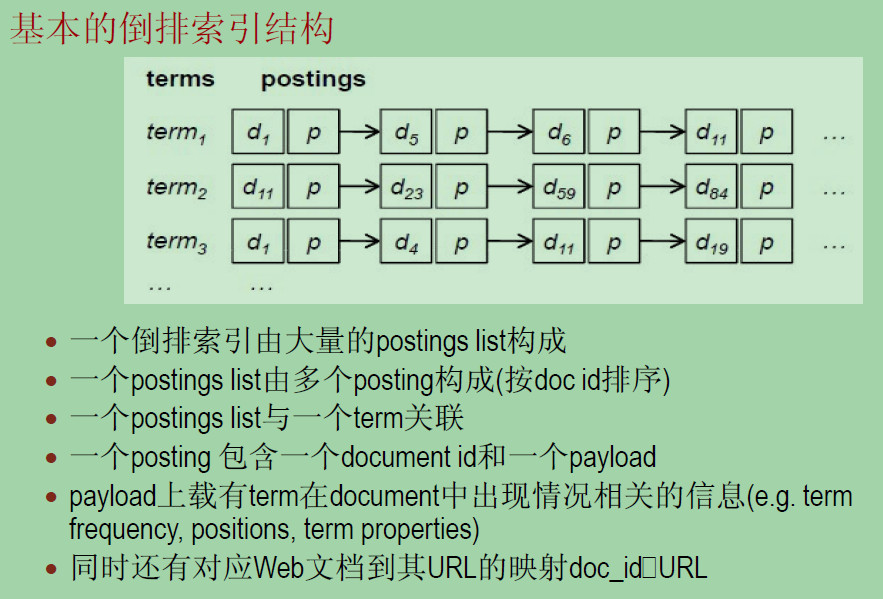
Inverted Index(倒排索引)是目前几乎所有支持全文检索的搜索引擎都要依赖的一个数据结构。基于索引结构,给出一个词(term),能取得含有这个term的文档列表(the list of documents)
Web Search中的问题主要分为三部分:
- crawling(gathering web content) ,网页爬虫,收集数据
- indexing(construction of the inverted index) ,根据大量数据构建倒排索引结构
- retrieval(ranking documents given a query),根据一个搜索单词进行索引并对结果进行排序,比如可以根据词频多少来排
crawling和indexing都是离线的,retrieval是在线、实时的。
此处有个问题,索引结构会如何进行存储呢?
给定一个单词,如何快速得到结果呢?
一般可以采用两种存储方式,一种是hash链表,还有一种则是B(B+)树。
说起存储我就想到我同学面试时被问到一个问题:a~z26个单词如何存储能快速索引?
(⊙﹏⊙)b居然是26叉树,好丧心病狂啊!
基本的倒排索引结构
实验任务
请实现课堂上介绍的“带词频属性的文档倒排算法”。
在统计词语的倒排索引时,除了要输出带词频属性的倒排索引,还请计算每个词语的“平均
提及次数”(定义见下)并输出。
“平均提及次数”在这里定义为:
平均提及次数= 词语在全部文档中出现的频数总和/ 包含该词语的文档数
假如文档集中有四本小说:A、B、C、D。词语“江湖”在文档A 中出现了100 次,在文档B
中出现了200 次,在文档C 中出现了300 次,在文档D 中没有出现。则词语“江湖”在该文
档集中的“平均提及次数”为(100 + 200 + 300) / 3 = 200。
输出格式
对于每个词语,输出两个键值对,两个键值对的格式如下:
[词语] \TAB 词语1:词频, 词语2:词频, 词语3:词频, …, 词语100:词频
[词语] \TAB 平均提及次数
下图展示了输出文件的一个片段(图中内容仅为格式示例):

设计
倒排索引可以看做是wordcount的拓展,它需要统计一个单词在多个文件中出现的次数,那么它的Mapper和Reducer该如何设计呢?
很自然地我们会想到
Mapper:
- 对于文件file中任一word,
- Key = word, Value = fileName + 1.
Reduer:
- 对于输入Key, Iterable(Text) Values,
- 统计Values中每个Value,记录出现的fileName以及频数.
这里有个问题,它需要假定对于一个相同的Key,Mapper给出的输出
design trick: value-to-key conversion
Value到Key的转换
比如说对于原来的(term, (docid, tf))可以将value中的docid放到key中从而得到
新的键值对((term, docid), tf)。
这样具有相同key值的键值对数目就降低啦!
关于Mapper里边的代码我遇到两个问题:
1.用空格 ” “来对line做分词,在最后的输出结果里边会出现空白单词,很奇怪,虽然我在输出的时候加了token为” “或”\t”的时候都不输出,但是最后结果里边还是有空白单词,匪夷所思诶。
2.Mapper的输出如果采用((term:docid), tf)的形式,使用“:”来分隔term和docid,那么在Combiner里边如果我使用”:”来分隔key(也就是下边错误的Mapper方式),那么得到的String个数有时候长度居然<2,所以我现在使用”->”来进行分隔。
public static class InverseIndexMapper extends Mapper<LongWritable, Text, Text, Text>{
@Override
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
String line = value.toString();
String[] strTokens = line.split(" ");
FileSplit inputSplit = (FileSplit)context.getInputSplit();
Path path = inputSplit.getPath();
String pathStr = path.toString();
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 453
453


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








