







高阶函数
1.函数:
函数本身也可以赋值给变量,即:变量可以指向函数。

函数名其实就是指向函数的变量!

上述操作发现:abs为函数名,给abs=1重新赋值后,abs已不是函数,而是一个整数。
2.高阶函数
变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。

3.map函数
map() 函数接收两个参数,一个是函数,一个是序列, map 将传入的函数依次作用到序列的每个元素,并把结果作为新的 list 返回。

不需要 map() 函数,写一个循环,也可以计算出结果。
map()作为高阶函数,把运算规则抽象了。
4.reduce函数
reduce 把一个函数作用在一个序列[x1, x2, x3...]上,这个函数必须接收两个参数,reduce 把结果继续和序列的下一个元素做累积计算。

reduce函数
•Python 提供的 sum() 函数可以接受一个 list 并求和,请编写一个 prod()函数,可以接受一个 list 并利用 reduce() 求积。

5.filter函数
filter() 也接收一个函数和一个序列。和 map() 不同的时,filter() 把传入的函数依次作用于每个元素,然后根据返回值是 True还是 False 决定保留还是丢弃该元素。
在一个 list 中,删掉偶数,只保留奇数:

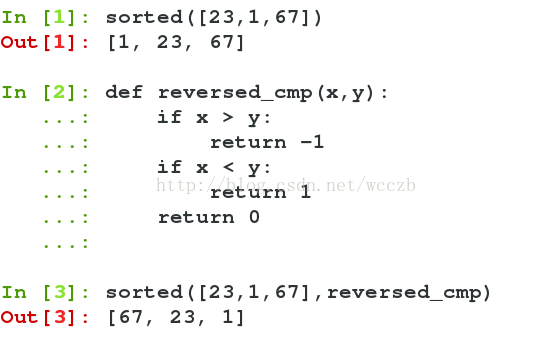
6.sorted函数
• 排序也是在程序中经常用到的算法。 无论使用冒泡排序还是快速排序,排序的核心是比较两个元素的大小。通常规定如下:
x < y, return -1
x == y, return 0
x > y, return 1
• python内置的 sorted() 函数就可以对 list 进行排序;
• 如果要倒序排序呢?
• 如果要对字符串进行排序呢?
倒序排序
高阶函数的抽象能力非常强大,而且核心代码可以保持得非常简洁。
函数作为返回值
高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回。
def lazy_sum(*args):
def sum():
ax = 0
for n in args:
ax = ax + n
return ax
return sum
1
5
6
7
8
9
3
f = lazy_sum(1,2,3,4)
2
#调用 lazy_sum() 时,返回的并不是求和结果,而是求和函数
f()
4,10
#调用函数 f 时,才真正计算求和的结果
调用 lazy_sum() 时,每次调用都会返回一个新的函数,即使传入相同的参数
7.匿名函数
•当我们在传入函数时,有些时候,不需要显式地定义函数,直接传入匿名函数更方便。
•关键字 lambda 表示匿名函数,冒号前面的 x 表示函数参数。

• 匿名函数有只能有一个表达式,不用写 return ,返回值就是该表达式的结果。
• 因为匿名函数没有名字,不必担心函数名冲突。 此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数;

•也可以把匿名函数作为返回值返回

8.装饰器:
•装饰器就是用来装饰函数。
• 想要增强原有函数的功能;
• 但不希望修改now()函数的定义;
• 在代码运行期间动态增加功能的方式。
•定义的装饰器实质是返回函数的高阶函数。(试试下面的装饰器)
import time
def timeIt(func):
def warp(arg):
start = datetime.datetime.now()
func(arg)
end = datetime.datetime.now()
cost = end - start
print "execute %s spend %s" % (func.__name__,cost.total_seconds())
return warp
@timeIt # 这里是 python 提供的一个语法糖
def func(arg):
time.sleep(arg)
func(3)
模块与包
1.模块
在 Python 中,一个.py文件就称之为一个模块(Module)。
•大大提高了代码的可维护性;
•编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。
import sys
def test():
args = sys.argv
if len(args) == 1:
print 'Hello world'
elif len(args) == 2:
print 'Hello %s!' %args[1]
else:
print 'Too many arguments!'
if __name__ == '__main__':
test()
调用模块时用import xxx
2.包
如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python 又引入了按目录来组织模块的方法,称为包(Package)
创建包的步骤:
创建一目录为包名;
在该文件夹下创建__init__.py文件存放包的信息,该文件可以为空;
根据需要存放脚本文件,已编译的扩展及子包;
可以用import,import as,from import等语句导入模块和包;
3.作用域
在一个模块中,我们可能会定义很多函数和变量,但有的函数和变量我们希望给别人使用,有的函数和变量我们希望仅仅在模块内部使用。
在 Python 中,是通过 _ 前缀来实现。比如__author__ , __name__就是特殊的,__func__,__fun为私有函数,不能直接引用。
4.安装第三方模块
- 需要联网 ;
- 通过 setuptools 这个工具完成;
- pip install 包名 或 pycharm中安装。
5.模块搜索路径
- 当我们试图加载一个模块时,Python 会在指定的路径下搜索对应的.py 文件;
- 默认情况下,Python 解释器会搜索当前目录、所有已安装的内置模块和第三方模块,搜索路径存放在 sys 模块的 path 变量中;
文件操作
1.文件读写
• Python 内置了读写文件的函数,用法和 C 是兼容的。
• 操作系统不允许普通的程序直接操作磁盘,所以,读写文件就是请求操作系统打开一个文件对象(又称文件描述符),然后,通过操作系统提供的接口从这个文件对象操作。
思考:
把大象放进冰箱的过程。
思考文件读写的过程:
1. 打开文件
2. 向文件中写入内容;
3. 关闭文件。
f = open('/root/hello')
# 如果文件不存在, open() 函数就会抛出一个 IOError 的错误,并且给出错误码和详细的信息告诉你文件不存在。
f.read()
#如果文件打开成功,接下来,调用 read() 方法可以一次读取文件的全部内容。
f.close()
#文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源。
思考:
read()会一次性读取文件的全部内容,如果文件有 10G,内存就
爆了。怎么解决?
• 如果文件很小, read() 一次性读取最方便;
• 如果不能确定文件大小,反复调用 read(size)
• 比较保险;如果是配置文件,调用 readlines()
• 二进制文件
要读取二进制文件,比如图片、视频等等,用 'rb' 模式打开文件即可
>>> f = open('/root/test.jpg', 'rb')
>>> f.read()
'\xff\xd8\xff\xe1\x00\x18Exif\x00\x00...' # 十六进制表示的字节。
• 字符编码
要读取非 ASCII 编码的文本文件,就必须以二进制模式打开,再解码,Python 还提供了一个 codecs 模块帮我们在读文件时自动转换编码,直接读出 unicode。
import codecs
with codecs.open('/Users/michael/gbk.txt', 'r', 'gbk') as f:
f.read() # u'\u6d4b\u8bd5'。
2.open函数的模式
r 以读的方式打开,定位到文件开头 , 默认的 mode。
r+ 以读写的方式打开,定位文件开头 , 可以写入内容到文件。
w 以写的方式打开,打开文件的时候会清空文件的内容,并且不能读。
w+ 以读写的方式打开,定位到文件头,并且打开文件的时候也会清空文件的内容。
a 以写的方式打开,定位到文件的末尾,是一个追加的操作 , 但并不允许读。
a+ 以读写的方式打开,定位到文件的末尾,追加的方式。
在使用以上 mode 打开文件的时候,如果增加了b 模式,表示以二进制方式打开。
3.文件的其它操作
f.flush()函数,将缓冲区的内容写入到硬盘中
f.seek(offset[,whence]),offset 表示移动多少字节, whence 为 1 的时候表示相对于当前位置移动的;当 2 的时候从文件的末尾往后移动,但不一定所有的平台都支持;默认为 0 表示从文件开头往后移动
f.tell()函数,返回当前文件指针的偏移量。
fileno() 函数,返回当前的文件描述符,一个数字
isatty() 函数,当前打开的文件是否是一个终端设备
closed 属性,当前文件是否关闭 ,|True,False, f.closed
file 对象是一个迭代器:
next() 方法 , 一行一行的读 , 每次读取一行。
4.with语法
一般情况打开一个文件,经过操作之后,都要显式的执行xx.close() 将文件关闭 .with 用于需要打开、关闭成对的操作,可以自动关闭打开对象 .with expression as obj:# 将打开的对象赋值给 obj
expression
#obj 的作用域只在 with 语句中。
面向对象编程
1.编程范式
•面向对象编程——Object Oriented Programming,简称 OOP,把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数。
•面向过程把函数继续切分为子函数,来降低系统的复杂度。
2.基础概念
• 类: 在 Python 中,所有数据类型都可以视为对象,当然也可以自定义对象。自定义的对象数据类型就是面向对象中的类(Class)。
• OOP首选思考的不是程序的执行流程,而是某个数据类型应该被视为一个对象,这个对象拥有的属性(Property)。
• 方法: 给对象发消息实际上就是调用对象对应的关联函数,我们称之为对象的方法(Method)。
3.类
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
def print_score(self):
print '%s: %s' % (self.name, self.score)
• Class 是一种抽象概念,比如我们定义的 Class——Student,是指学生这个概念;
• 实例(Instance)则是一个个具体的 Student;
• 面向对象的抽象程度又比函数要高,因为一个 Class 既包含数据,又包含操作数据的方法。
• object表示该类是从哪个类继承下来的。通常,如果没有合适的继承类,就使用 object 类,这是所有类最终都会继承的类。
• 创建实例的方式:student1 = Student()
• 可以自由地给实例变量绑定属性,student1.name,student1.score;
•可定义一个特殊的 __init__ 方法,在创建实例的时候,就把name , score等属性绑上去。
• __init__ 方法的第一个参数永远是 self ,表示创建的实例本身;
• 在类中定义的函数只有一点不同,就是第一个参数永远是实例变量self ,并且调用时,不用传递该参数。
4.数据封装
• 数据和逻辑被“封装”起来了,调用很容易,但却不用知道内部实现的细节。
• 封装的另一个好处是可以给类增加新的方法;
5.访问限制
• 在 Python 中,实例的变量名如果以 __ 开头,就变成了一个私有变量(private);
• 双下划线开头的实例变量是不是一定不能从外部访问呢?NO
6.继承和多态
class Animal(object):
def run(self):
print 'Animal is running...'
class Dog(Animal):
pass
class Cat(Animal):
pass
• 对于 Dog 来说,Animal 就是它的父类,对于 Animal 来说,Dog 就是它的子类;
• 继承最大的好处是子类获得了父类的全部功能。
•继承的另一个好处:多态。子类的覆盖了父类的方法。
7.获取对象信息
• 使用 type();
• 使用 isinstance()
• 使用 dir()
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









