







【继承示意图】
类是实例的工厂, OOP就是在树中搜索属性,类其实就是变量名与函数打成的包
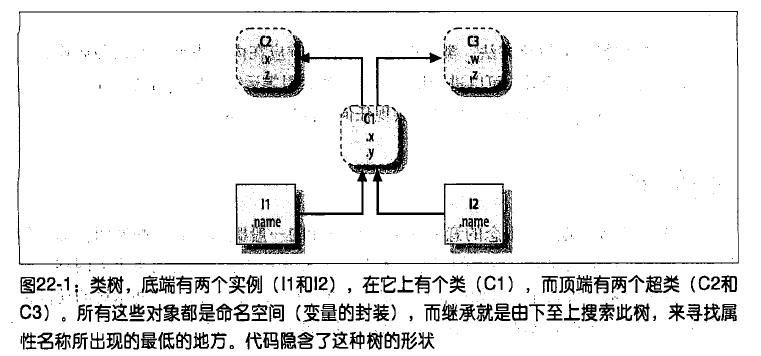
. 每个class语句会生成一个新的类对象
. 每次类调用时,就会生成一个新的实例对象
. 实例自动连接到创建这些实例的类
. 类连接到超类的方式是,将超类列在类头部(),其从左到右的顺序会决定树中的次序
有几点需要注意:
. 属性通常是在class语句中通过赋值语句添加在类中,而不是嵌入函数的def语句中
. 属性通常是在类中,对传给函数的特殊参数self,做赋值运算而添加在实例中的
【方法调用的两种方式】
def 语句出现在类中,通常称为方法:
通过实例调用:bob.giveRise()
通过类来调用:Employee.giveRise(bob)
【类与模块】
从最底层来看,类几乎就是命名空间,很像模块。但和模块不同的之处是:
1. 类也支持多个对象的产生(多态)
2. 命名空间继承(继承)
3. 运算符重载(重载)
【PYTHON类的主要特点】
. class语句创建对象并将其赋值给变量名(类似于def)
. class语句内的赋值语句会创建类的属性(属性获得:object.name)
. 类属性提供对象的状态和行为
【类的实例概要】
. 像函数那样调用对象会创建新的实例对象
. 每个实例对象继承类的属性并获得自己的命名空间
. 在方法内对self属性做赋值运算会产生每个实例自己的属性
【第一个例子】
class FirstClass: #定义类的对象
def setdata(self,value): #定义类方法
self.data = value #self是个实例
def display(self):
print self.data #self-data: 每个实例共享
创建两个实例,每个实例拥有自己的命名空间
>>> x = FirstClass()
>>> y = FirstClass()
会产生三个对象: 两个实例,一个类
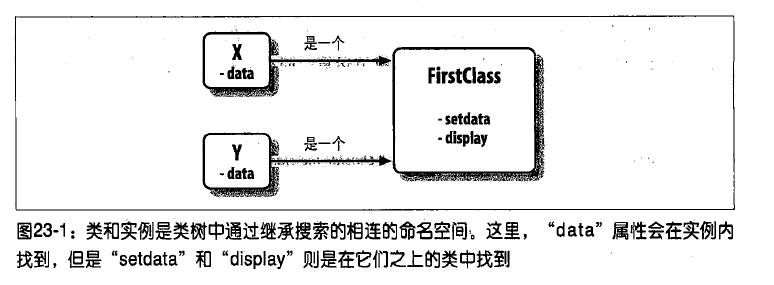
>>> x.setdata('Hello') #调setdata方法,self就是x本身
>>> y.setdata(100) #运行: FirstClass.setdata(y,100)
x,y创建不同实例对象的命名空间,所以尽管都调用display方法,值却不同
>>> x.display() #self.data在每个实例中不一样
Hello
>>> y.display()
100
另一种调用方式:
>>> x.data = "New Value" #能够获得或设置属性
>>> x.display()
New Value
也可以设置成一个全新的属性
>>> x.anothername = 'spam'
【PYTHON类继承的核心观点】
. 超类列在类开头的括号中
. 类从超类中继承属性,当读入属性时,如果不存在于子类中,PYTHON会自动搜索这个属性
. 实例会继承所有可读取类的属性. 搜索路径: 实例 ==> 创建实例的类 ==> 所有超类
. 每个object.attribute都会开启新的独立搜索
. 逻辑的修改是通过创建子类,而不是修改超类
这种搜索的结果及主要目的就是:
第一: 类支持了程序的分解和定制,比迄今为止所见到的其他任何语言工具都要好。
第二: 可以把程序的冗余度降到最低,减少维护成本,也就是把操作分解为单一,共享的实现
第三: 这样写程序时,也可以让我们队现有的程序代码进行定制,而不是实地修改或从头开始
【第二个例子】
class SecondClass(FirstClass): #继承FirstClass类中的setdata方法
def display(self): #修改display方法,也叫方法的重载
print 'Current value = %s' % self.data
搜索从实例开始==>子类==>超类,直到找到第一个为止,所以display会覆盖父类方法
>>> z = SecondClass()
>>> z.setdata('Hello,World!') #从FirstClass中发现setdata方法
>>> z.display() #SecondClass中发现display方法
Current value = Hello,World!
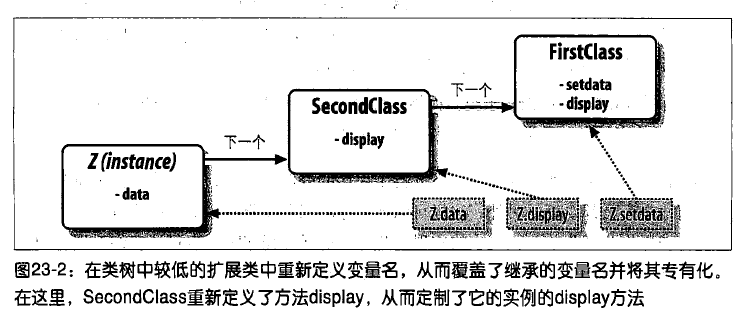
NOTE:作为一条规则,因为继承可以让我们在外部组件内(也就是在子类内)进行修改,类所支持的扩展和重用通常比函数或模块更好!
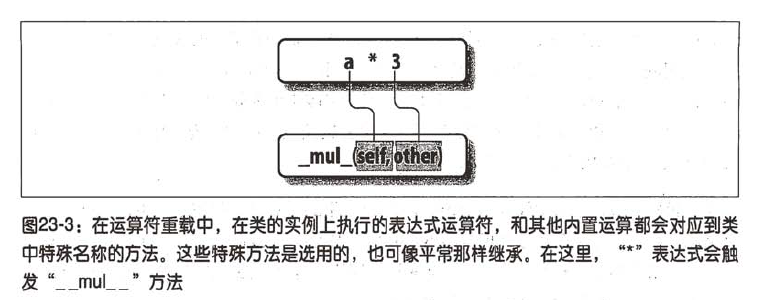
【第三个例子】: 关于运算符重载
定义SecondClass的子类,实现三个特殊名称的属性,让PYTHON自动调用:
当新的实例构造时,会调用__init__(self是新的ThirdClass对象)
当ThirdClass实例出现在+或*表达式中时,则分别调用__add__和__mul__
class ThirdClass(SecondClass): #ThirdClass类,继承自SecondClass
def __init__(self,value): #ThirdClass类中的值
self.data = value
def __add__(self,other): #注意这种调用方式 self + other
return ThirdClass(self.data + other)
def __mul__(self,other):
self.data = self.data * other #self * other
执行结果:
>>> a = ThirdClass('AB') #调用__init__构造函数
>>> a.display() #继承的方法
Current value = AB
>>> b = a + 'XY' #新的__add__:造一个新的实例
>>> b.display()
Current value = ABXY
>>> a * 3 #新的__mul__:在当地改变实例
>>> a.display()
Current value = ABABAB
NOTE:
__add__方法创建并返回这个类的新的实例对象
__mul__方法会在原处修改当前的实例对象
【OOP最重要的两个概念】
方法函数中的特殊self参数和__init__构造器方法是PYTHON中OOP的两个基石
【最常用的运算符重载】
运算符重载是由特定名称的方法写成的。这些方法的开头和结尾都是双下划线,通过这种方法使其变得独特。这些不是内置或保留字。当实例出现在相应的运算中时,PYTHON就会自动执行它们。PYTHON为这些运算和特殊方法的名称定义了对应的关系。
__init__构造器是最常用的。几乎每个类都使用这个方法为实例属性进行初始化,以及执行其他的启动任务。
【变量名相同的例子】
class MixedNames: #定义类:MixedNames
data = 'spam' #赋值类属性:data
def __init__(self,value): #赋值方法名:
self.data = value #赋值实例属性:data
def display(self):
print MixNames.data,self.data #类属性,实例属性
输出结果:
>>> ins1 = MixedNames(1) #类工厂造两个实例对象x,y
>>> ins2 = MixedNames(2) #每个实例对象有自己的数据
>>> ins1.display();ins2.display() #self.data不同,subclass.data却是相同的,都是从data = 'spam'继承而来
spam 1
spam 2
>>> MixedNames.display(ins1) #这种写也是可以的
【另一个例子】
message = 'Global Message!'
class NextClass:
message = 'Class Message'
def printer(self,value):
self.message = value
print 'message', message
print 'NextClass.message',NextClass.message
print 'self.message',self.message
输出结果:
>>> x = NextClass() #造实例
>>> x.printer('Instance Message!') #调实例的方法
message is: Global Message!
NextClass.message is: Class Message!
self.message is: Instance Message!
其他调用:
>>> NextClass.printer(x,'class call') #正确:直接调用类
>>> NextClass.printer('class call') #错误:必须在第一个位置放实例名
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unbound method printer() must be called with NextClass instance as first argument (got str instance instead)
【调用超类的构造器】
如果除了想调用自身的构造函数,还想调用超类的,那么就必须用下面的方式
class Super:
def __init__(self,x):
pass
class Sub(Super):
def __init__(self,x,y):
Super.__init__(self.x)
pass
I = Sub(1,2)
【继承方法的专有化】
继承树搜索模式是将系统专有化的最好的方式,继承会先在子类中寻找变量名,然后才查找超类,子类可以对超类的属性重新定义来取代默认的行为。实际上,可以把整个系统做成类的层次,再新增外部的子类来对其进行扩展,而不是在原处修改已重载的逻辑。
. 子类可以完全取代继承的属性
. 子类可以找到并获得超类属性
. 子类可以通过已覆盖的方法回调超类来扩展超类的方法
class Super:
def method(self):
print 'start Super.method'
class Sub(Super):
def method(self): #重写方法
print 'starting Sub.method' #增加行为
Super.method(self) #运行默认的行为,NOTE:self的使用
print 'ending Super.method'
直接调用超类方法是这里的重点。Sub类取代了Super的方法函数.但是,取代时,Sub又回调了Super所导出的版本,从而实现了默认的行为。也就是说:Sub.method只是扩展了Super.method的行为,而不是完全取代。
输出结果:
>>> x = Super() #造一个Super实例
>>> x.method() #调Super类中的method方法
Start Super.method
>>> x = Sub() #造一个Sub实例
>>> x.method() #调Sub类中的method,其中又回调了父类的方法
Start Sub.method
Start Super.method
Ending Super.method
【类接口技术】
扩展只是一种同超类接口的方式,下面示范了specialize.py文件定义了多个类,示范了一些常用的技巧
Super: 定义了一个method函数以及一个delegate函数
Inheritor: 没有提供任何新的变量名,因此会获得Super中定义的一切内容
Replacer: 用自己的版本来覆盖Super的method
Extender: 覆盖并回调默认的method,从而定制Super的method
Provider: 实现Super的delegate方法预期的action方法
#File: specialize.py
<span style="font-family:SimHei;font-size:14px;">class Super:
def method(self):
print 'in Super.method'
def delegate(self):
self.action()
class Inheritor(Super):
pass
class Replacer(Super):
def method(self):
print 'in Replacer.method'
class Extender(Super):
def method(self):
print 'starting Extender.method'
Super.method(self)
print 'ending Extender.method'
class Provider(Super):
def action(self):
print 'in Provider.action'
if __name__=='__main__':
for klass in (Inheritor,Replacer,Extender):
print '\n' + klass.__name__ + '...'
klass().method()
print '\nProvider...'
x = Provider()
x.delegate()</span>1. 末尾的自我测试代码在for循环中建立三个不同类的实例
2. 类也有特殊的__name__属性,就像模块。它默认类首行中的类名称的字符串
运行结果:
D:\>python specialize.py
Inheritor...
in Super.method
Provider...
in Provider.action
Replacer...
in Replacer.method
Provider...
in Provider.action
Extender...
starting Extender.method
in Super.method
ending Extender.method
Provider...
in Provider.action
【抽象超类】
上例中的Provider类中,当通过Provider实例调用delegate方法时,两个独立的继承搜索将会发生:
1. 在最初的x.delegate调用中,PYTHON会搜索Provider实例和它上层的对象,知道在Super中找到delegate的方法。实例x会像往常一样传递给这个方法的self参数
2. 在Super.delegate方法中,self.action会对self以及它上层的对象启动新的独立继承搜索。因为self指的是Provider实例,就会找到Provider子类中的action
这种填空式的代码结构一般就是OOP的软件框架。从delegate方法的角度来看,这个例子中的超类也称为抽象类--也就是类的部分行为默认是由其子类来实现。如果逾期的方法没有在子类中定义,当继承搜索失败时,PYTHON会引发未定义变量名的异常。一般会使用assert语句,使这种子类需要更为明显,或者引发内置的异常NotImplementedError:
<span style="font-family:SimHei;font-size:14px;">class Super:
def method(self):
print 'In Super.method'
def delegate(self):
self.action
def action(self):
assert 0, 'action must be defined!'</span>【运算符重载】
. 运算符重载让类拦截常规的PYTHON运算
. 类可重载所有PYTHON表达式运算符
. 类可重载打印、函数调用、属性点号运算等运算
. 重载使类实例的行为像内置类型
. 重载是通过特殊名称的类方法实现的
简单例子
<span style="font-family:SimHei;font-size:14px;">class Number:
def __init__(self,start): #on Number(start)
self.data = start
def __sub__(self,other): #On instance - other
return Number(self.data - other) #Result is a new instance</span>>>> from number import Number #Fetch class from Module
>>> X = Number(5) #Number.__init__(X,5)
>>> Y = X -2 #Number.__sub__(X,2)
>>> Y.data #Y is new Number instance
3
【常见的运算符重载】

【__getitem__拦截索引运算】
下面的类将返回索引值的平方
<span style="font-family:SimHei;font-size:14px;">class indexer:
def __getitem__(self,index):
return index ** 2</span>
<span style="font-family:SimHei;font-size:14px;">>>> X = indexer()
>>> X[2]
4
>>> for i in range(5):
... print X[i],
...
0 1 4 9 16</span>
<span style="font-family:SimHei;font-size:14px;">class stepper:
def __getitem__(self,i):
return self.data[i]
</span>
<span style="font-family:SimHei;font-size:14px;">>>> X = stepper() #X is a stepper object
>>> X.data = 'spam'
>>> X[1] #Indexing calls __getitem__
'p'
>>> for item in X: #for loops call __getitem__
... print item, #for index items 0..N
...
s p a m</span>>>> 'p' in X
True
>>> [c for c in X]
['s', 'p', 'a', 'm']
>>> map(None,X)
['s', 'p', 'a', 'm']
>>> (a,b,c,d) = X
>>> a,c,d
('s', 'a', 'm')
>>> list(X);tuple(X);''.join(X)
['s', 'p', 'a', 'm']
('s', 'p', 'a', 'm')
'spam'
>>> X
<number.stepper instance at 0x00000000025EE088>
【__getattr__和__setattr__捕捉属性的引用】
__getattr__方法是拦截属性点号运算。当通过未定义属性名称和实例进行点号运算时,就会用属性名称为字符串调用这个方法。
__getattr__例子:
class empty:
def __getattr__(self,attrname):
if attrname == "age":
return 40
else:
raise AttributeError,attrname
运行结果
>>> X = empty()
>>> X.age
40
>>> X.name
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "number.py", line 6, in __getattr__
raise AttributeError,attrname
AttributeError: name
__setattr__例子:
class accesscontrol:
def __setattr__(self,attr,value):
if attr == 'age':
self.__dict__[attr] = value
else:
raise AttributeError,attr + 'not allowed'
运行结果:
>>> X = accesscontrol()
>>> X.age = 40
>>> X.age
40
>>> X.name = 'bob'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "number.py", line 6, in __setattr__
raise AttributeError,attr + 'not allowed'
AttributeError: namenot allowed
【__call__拦截调用】
当实例调用时,使用__call__方法。可以让实例的外观和用法类似于函数。
class Prod:
def __init__(self,value):
self.value = value
def __call__(self,other):
return self.value * other
>>> X = Prod(2)
>>> X(3)
6
下面的例子也能提供类似功能:
class Prod:
def __init__(self,value):
self.value = value
def comp(self,other):
return self.value * other
>>> X = Prod(2)
>>> X.comp(3)
6
当需要为函数的API编写接口时,__call__就变得很有用:这可以编写遵循所需要的函数来调用接口对象,同时又能保留状态信息。这是除了__init__构造方法以及__str__和__repr__显示格式外,第三个最常用的运算符重载方法了。
【__del__析构器】
每当实例产生时,就会调用__init__构造方法。
每当实例收回时,就会调用__del__析构方法来自动执行。
class Life:
def __init__(self,name='unknown'):
print 'Hello',name
self.name = name
def __del__(self):
print 'Goodbye',self.name
执行结果:
>>> name = Life('Jerry')
Hello Jerry
>>> name = 'Alice'
Goodbye Jerry
基于某些原因,在PYTHON中,析构方法不像其他OOP语言那么常用。
原因之一: 因为PYTHON在实例收回时,会自动回收实例所拥有的的所有空间,对于空间管理来说是不需要析构方法的。
原因之二: 无法轻易地预测实例何时收回
【命名空间完整例子】
X = 11
def f():
print X
def g():
X = 22
print X
class C:
X = 33
def m(self):
X = 44
self.X = 55
if __name__=='__main__':
print X
f()
g()
print X
obj = C()
print obj.X
obj.m()
print obj.X
print C.X
X=11 #模块属性
X=22 #函数内的本地变量
X=33 #类属性
X=44 #方法中的本地变量
X=55 #实例属性
【命名空间字典】
类和实例都具有内置属性__dict__,看一个例子:
class super:
def hello(self):
self.data1 = 'spam'
class sub(super):
def hola(self):
self.data2 = 'eggs'实例有个__class__属性链接到它的类
而类有个__bases__属性是一个元祖,其中包含了通往更高的超类的链接
>>> X = sub()
>>> X.__dict__
{}
>>> X.__class__
<class __main__.sub at 0x0000000002EA2588>
>>> sub.__bases__
(<class __main__.super at 0x0000000002EA2528>,)
>>> super.__bases__
()
当类为self属性赋值时,会填入实例对象。也就是说,属性会最后会位于实例的属性命名空间字典内,而不是类的。实例对象的命名空间保存了数据,会随实例的不同而不同,而self正是进入其命名空间的钩子.
>>> Y = sub()
>>> X.hello()
>>> X.__dict__
{'data1': 'spam'}
>>> X.hola()
>>> X.__dict__
{'data1': 'spam', 'data2': 'eggs'}
>>> Y = sub()
>>> X.hello()
>>> X.__dict__
{'data1': 'spam', 'data2': 'eggs'}
>>> sub.__dict__
{'__module__': '__main__', '__doc__': None, 'hola': <function hola at 0x0000000002EAB6D8>}
>>> super.__dict__
{'__module__': '__main__', 'hello': <function hello at 0x0000000002EAB0B8>, '__doc__': None}
>>> sub.__dict__.keys();super.__dict__.keys()
['__module__', '__doc__', 'hola']
['__module__', 'hello', '__doc__']
>>> Y.__dict__
{}
属性是PYTHON的字典键,因此有两种方式可以读取并对其进行赋值:
. 通过点号运算
. 通过键索引运算
>>> X.data1;X.__dict__['data1']
'spam'
'spam'
>>> X.data3 = 'toast'
>>> X.__dict__
{'data1': 'spam', 'data3': 'toast', 'data2': 'eggs'}
>>> X.__dict__['data3'] = 'ham'
>>> X.data3
'ham'
其他的还有dir函数
>>> X.__dict__
{'data1': 'spam', 'data3': 'ham', 'data2': 'eggs'}
>>> X.__dict__.keys()
['data1', 'data3', 'data2']
>>> dir(X)
['__doc__', '__module__', 'data1', 'data2', 'data3', 'hello', 'hola']
>>> dir(sub)
['__doc__', '__module__', 'hello', 'hola']
>>> dir(super)
['__doc__', '__module__', 'hello']
【PYTHON和OOP】
PYTHON的OOP实现可以概括为三个概念:
继承: 继承是基于PYTHON中的属性查找的
多态: 在X.method方法中,method的意义取决于X的类型
封装: 方法和运算符实现行为,数据隐藏默认是一种惯例
【通过调用标志重载】
下面的方法不提倡:
class C:
def meth(self,x): ...
def meth(self,x,y,z): ...
下面的方法同样不提倡:
class C:
def meth(self,*args):
if len(args) == 1:
...
elif type(arg[0]) == int:
...
通常来讲,不应该这样做:而应该把程序代码写成预期的对象接口,而不是特定的数据类型。这样一来,不论现在还是以后,都可在更多的类型和应用中使用。
class C:
def method(self,x):
x.operation #假设x具有这种操作
【绑定方法】
绑定方法即带self.方法,结合实例和方法函数;
调用时候,不用刻意传入实例对象,因为原始实例依然可用.
【新式类】
class newStytle(object): ...
所有以object做为超类的类,称为新式类。和经典类几乎没什么区别。
PYTHON 3.0开始,所有的类都将试为超类.
【钻石继承例子】
由上述新式类衍生出来的经典例子:
>>> class A: attr = 1
>>> class B(A): pass
>>> class C(A): attr = 2
>>> class D(B,C): pass
>>> X = D()
>>> X.attr
1
如果是经典类,搜索的路径是D-B-A, 然后才是C,搜索到A的属性后停止
>>> class A(object): attr = 1 #新式类>>> class B(A): pass
>>> class C(A): attr = 2
>>> class D(B,C): pass
>>> X = D()
>>> X.attr
2
如果是新式类,搜索的路径是D-B-C,然后才是A,搜索到C的属性后停止















 51万+
51万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









