前言:
ILSVRC 2014的第二名是Karen Simonyan和 Andrew Zisserman实现的卷积神经网络,现在称其为
VGGNet。它主要的贡献是展示出网络的深度是算法优良性能的关键部分。
他们最好的网络包含了16个卷积/全连接层。网络的结构非常一致,从头到尾全部使用的是3x3的卷积和2x2的汇聚。他们的
预训练模型是可以在网络上获得并在Caffe中使用的。
VGGNet不好的一点是它耗费更多计算资源,并且使用了更多的参数,导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。
后来发现这些全连接层即使被去除,对于性能也没有什么影响,这样就显著降低了参数数量。
目前使用比较多的网络结构主要有ResNet(152-1000层),GooleNet(22层),VGGNet(19层)。大多数模型都是基于这几个模型上改进,采用新的优化算法,多模型融合等,这里
重点介绍VGG。
来源:K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprintarXiv:1409.1556, 2014
摘要:
VGG是在从Alex-net发展而来的网络。主要修改一下两个方面:
1,在第一个卷基层层使用更小的filter尺寸和间隔(3*3);
2,在整个图片和multi-scale上训练和测试图片。
3*3
filter:
引入cs231n上面一段话:
几个小滤波器卷积层的组合比一个大滤波器卷积层好:
假设你一层一层地重叠了3个3x3的卷积层(层与层之间有非线性激活函数)。在这个排列下,第一个卷积层中的每个神经元都对输入数据体有一个3x3的视野。
第二个卷积层上的神经元对第一个卷积层有一个3x3的视野,也就是对输入数据体有5x5的视野。同样,在第三个卷积层上的神经元对第二个卷积层有3x3的视野,
也就是对输入数据体有7x7的视野。假设不采用这3个3x3的卷积层,二是使用一个单独的有7x7的感受野的卷积层,那么所有神经元的感受野也是7x7,但是就有一些缺点。
首先,
多个卷积层与非线性的激活层交替的结构,比单一卷积层的结构更能提取出深层的更好的特征。其次,假设所有的数据有C个通道,那么单独的7x7卷积层将会包含
7*7*C=49C2个参数,
而3个3x3的卷积层的组合仅有个3*(3*3*C)=27C2个参数。直观说来,最好选择带有小滤波器的卷积层组合,而不是用一个带有大的滤波器的卷积层。前者可以表达出输入数据中更多个强力特征,
使用的参数也更少。唯一的不足是,在进行反向传播时,中间的卷积层可能会导致占用更多的内存。
1*1 filter:
作用是在不影响输入输出维数的情况下,对输入线进行线性形变,然后通过Relu进行非线性处理,增加网络的非线性表达能力。
Pooling:2*2,间隔s=2。
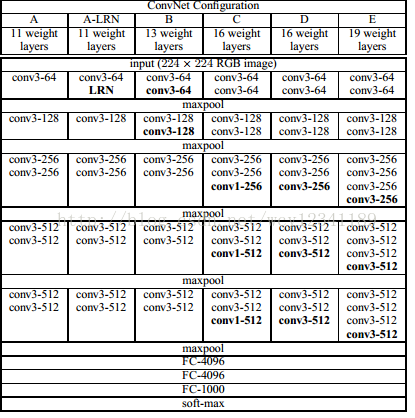
网络结构:
本文是有5个max-pooling层,所以是5阶段卷积特征提取。每层的卷积个数从首阶段的64个开始,每个阶段增长一倍,直到达到最高的512个,然后保持。
原文:
![]()
下图为VGG-19结构图:
结论:
虽然VGG比Alex-net有更多的参数,更深的层次;但是VGG只需要很少的迭代次数就开始收敛,原因:
1:深度和小的滤波器尺寸起到了隐士规则化作用。
2:一些层的pre-initialisation
pre-initialisation:网络A的权值W~(0,0.01)的高斯分布,bias为0;由于存在大量的ReLU函数,不好的权值初始值对于网络训练影响较大。
为了绕开这个问题,作者现在通过随机的方式训练最浅的网络A;然后在训练其他网络时,把A的前4个卷基层(感觉是每个阶段的以第一卷积层)
和最后全连接层的权值当做其他网络的初始值,未赋值的中间层通过随机初始化。
























 6589
6589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









