







VGG网络算是一个比较经典的骨干网络,其中主要是利用小卷积核替代大卷积核,通过设计网络中5层中不同层的卷积次数来设计成不同的VGG结构,是一个利用小卷积核不断加深网络的一次尝试。
VGG网络的结构可能没有那么熟悉,但下图这个经典的VGG16的图你一定很熟悉,从图中可以看到,VGG其实是通过不断的卷积->下采样->卷积->下采样…最后使用全连接层,输出类别数量的分数的一个网络。他是由牛津大学视觉组设计而来,是一种经典的卷积神经网络架构,在2014年的ILSVRC分类任务中大放异彩,取得了第二名的成绩,惜败于GoogLeNet。现今距离VGG出现已经过去很多年了,但VGG仍旧被广泛用在图像识别,目标检测、机器人等众多领域。
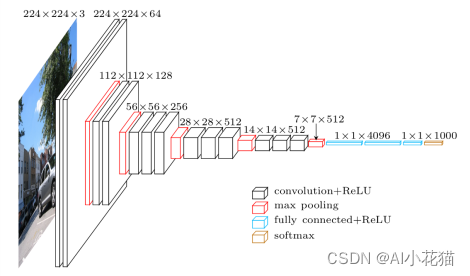
1、网络结构
VGG网络可以理解为有5个stage堆叠而成的主干特征提取网络加上3个全连接层组成的结构,stage与与stage之间通过maxpool进行下采样连接,从而增加通道数降低特征图分辨率。每个stage的卷积模块的堆叠数目不尽相同,因此也就构成6个不同种类的VGG网络。具体的卷积核以及通道数参考下图所示,需要注意的是:vgg网络都是采用3*3的卷积并使用padding为1保证输入输出的特征图保持不变,仅在stage变化的时候通过maxpool进行下采样。
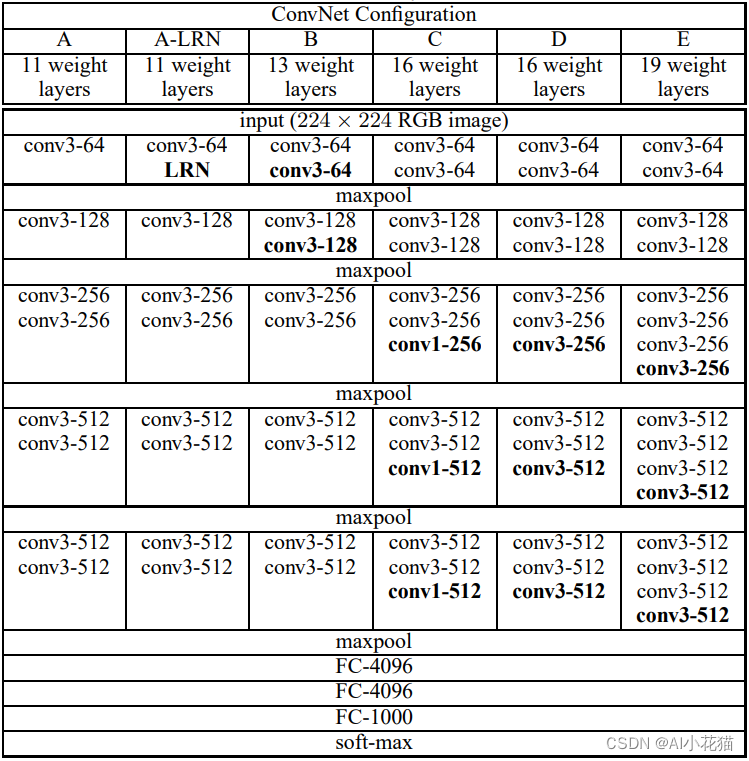
2、两个重要概念----感受野/参数量
文中提到两个重要概念,其一为感受野,其二为参数量减少,下面具体介绍一下如何计算感受野和参数量
2.1 感受野计算:
文中有提到两个3*3的卷积感受野与一个5*5的卷积感受野相同,3个3*3的卷积感受野和一个7*7的卷积感受野相同,那感受野如何计算的了?
先看看这个直观感受:
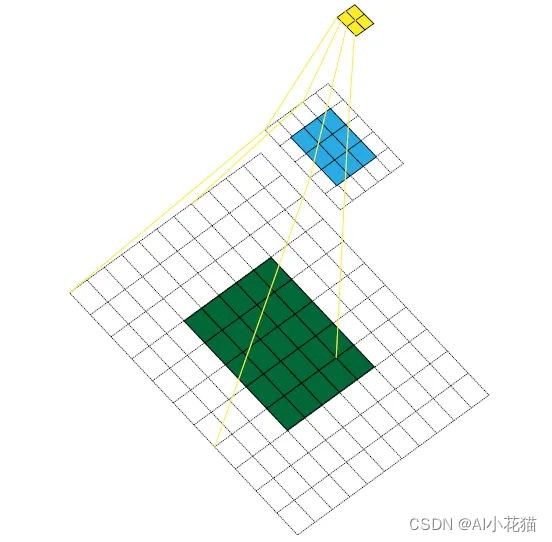
如上图所示,原始图像大小5*5,经过kernel大小为3*3,padding为1,stride为2的卷积后,大小变为3*3,再经过kernel大小为3*3,padding为1,stride为2的卷积后,大小变为2*2,感受野的意思就是最后卷积完成的特征图中每一个特征点(图中为黄色)在原始图像(绿色)上面所能看到的区域大小。
具体来说就是,黄色特征图上的一个特征点在蓝色特征图上的感受野为3*3,而这个3*3的蓝色区域在绿色原始图像上的感受野就是黄色特征图在原始图上的感受野,因此我们只需要计算蓝色特征图上3*3的区域在原始图上的感受野就行,很幸运,我们有现成的计算公式:
RF(N-1) = (RF(N) - 1) * stride(N-1) + kernel(N-1)
以上面的卷积过程为例,计算感受野如下:
kernels = [3,3] # 卷积核大小反着推依次为3,3
strides = [2,2] # stride反着推依次为2,2
RF = 1 ## 初始的感受野都为1
for i in range(len(strides)):
RF = (RF-1)*strides[i]+kernels[i]
print('感受野为:{}'.format(RF))

2.2 参数量计算:
论文还提到,卷积过程均是使用3*3的卷积核,不使用较大的卷积核如7*7或者5*5,主要考虑了参数量的计算问题。
具体对比计算如下:
假定三层3 × 3卷积堆栈的输入和输出都有C通道,而它们的参数量为3*(3^2 * C^2)= 27C^2,与之相对应的相同感受野的7*7的卷积核,其参数量为 7^2 * C^2 = 49C^2,因此参数量较之小卷积核多出81%。如果是5*5的,则多出39%的样子。
那参数量究竟如何计算了?
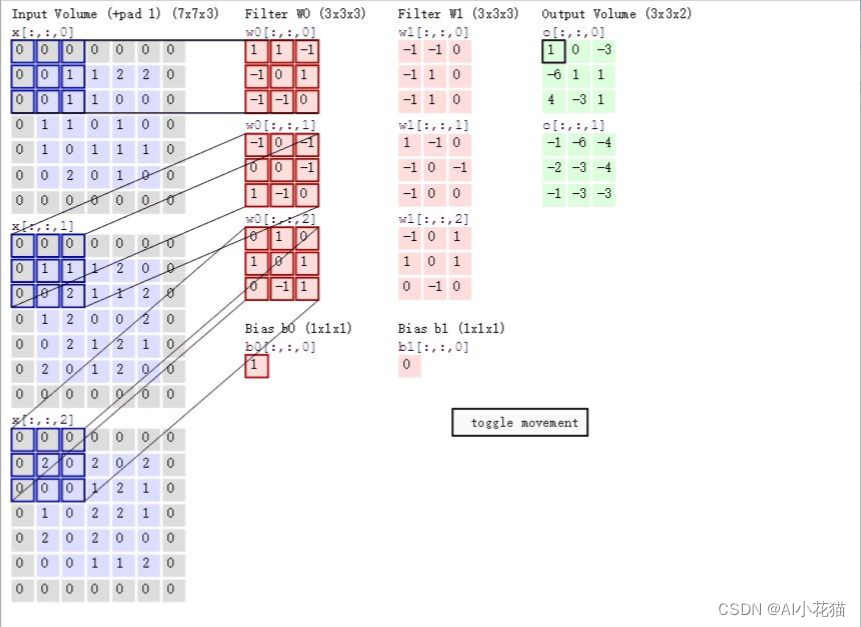
如下图所示的普通卷积过程,原始图像[bs,3,5,5],使用两个卷积核进行卷积,每个卷积核带三个通道,因此卷积核大小[2,3,3,3],最后输出[bs,2,3,3]。计算过程为每个卷积核和对应的图像相同块大小进行卷积操作,因此,计算量为kernel_size * kernel_size * channel_in,整个卷积过程包含两个卷积核,这核输出的通道数相同,因此最终的计算结果不加bias,可以简化为:
params = (kernel_size* kernel_size* channel_in)* channel_out
考虑到使用bias,则计算结果为:
params = (kernel_size* kernel_size* channel_in+1)* channel_out
3、模型代码
依据原论文,使用pytorch进行复现的代码如下所示:该代码适用于A、B、D、E四种模型,针对A-LRN以及C需要进行修改,A-LRN需要在第一个stage后面的加上LRN模块,C则需要在3、4、5最后一个卷积将卷积核变为1即可。
import torch.nn as nn
import torch
class VGG(nn.Module):
def __init__(self, stages=None, channels=None, num_classes=1000, in_channel=3):
"""
:param stages: vgg A\B\D\E四种模块不同stage的卷积个数
:param channels: vgg A\B\D\E四种模块不同stage的通道数
:param num_classes:类别
:param in_channel:输入通道
"""
super(VGG, self).__init__()
if stages is None:
stages = [2, 2, 3, 3, 3]
self.stages = stages
if channels is None:
channels = [64, 128, 256, 512, 512]
self.channels = channels
self.in_channel = in_channel
self.num_classes = num_classes
self.features = nn.Sequential(*self.make_layers())
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, self.num_classes)
)
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self._initialize_weights()
def make_layers(self, batch_norm=True):
convs = []
for stage, channel in zip(self.stages, self.channels):
for i in range(stage):
if i == 0:
convs.append(nn.Conv2d(in_channels=self.in_channel, out_channels=channel, kernel_size=3, stride=1,
padding=1))
if batch_norm:
convs.append(nn.BatchNorm2d(channel))
convs.append(nn.ReLU(inplace=True))
self.in_channel = channel
else:
convs.append(
nn.Conv2d(in_channels=channel, out_channels=channel, kernel_size=3, stride=1, padding=1))
if batch_norm:
convs.append(nn.BatchNorm2d(channel))
convs.append(nn.ReLU(inplace=True))
convs.append(nn.MaxPool2d(kernel_size=2, stride=2))
return convs
def _initialize_weights(self):
"""
权重初始化
"""
for m in self.modules():
if isinstance(m, nn.Conv2d):
# 卷积层使用 kaimming 初始化
nn.init.kaiming_normal_(
m.weight, mode='fan_out', nonlinearity='relu')
# 偏置初始化为0
if m.bias is not None:
nn.init.constant_(m.bias, 0)
# 批归一化层权重初始化为1
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# 全连接层权重初始化
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
# x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
if __name__ == '__main__':
import torch
from torchsummary import summary
vgg = VGG(num_classes=2)
inputs = torch.rand((1, 3, 224, 224))
res = vgg(inputs)
print(res.shape)
summary(vgg, (3, 224, 224), device='cpu')
4、训练细节
优化函数:SGD ,momentum=0.9, weight decay = 5*10^-4
batch_size: 256
学习率:初始化为0.01, 总计训练74epoch,当验证集准确率不提升时学习率下降为原来的1/10,整个训练过程下降了三次
模型收敛较快的原因:1、更小更深的卷积带来的隐式正则,2、优秀的预初始化参数
5、基于猫狗数据集的分类网络训练
5.1 构建猫狗数据集
直接继承Dataset,实现其中的两个主要函数__getitem__以及__len__即可。
from torchvision import transforms
import os
from torch.utils.data import Dataset
from PIL import Image
class CatDogDataset(Dataset):
def __init__(self, img_root, transform=None, is_train=True):
super(CatDogDataset, self).__init__()
self.img_root = img_root
self.transform = transform
self.train = is_train
self.imgs = self.get_all_img()
def get_all_img(self):
img_paths = []
for root, dirs, files in os.walk(self.img_root):
if files is not None:
for file in files:
if file.endswith('.jpg'):
img_path = os.path.join(root, file)
img_paths.append(img_path)
return img_paths
def __getitem__(self, idx):
img_path = self.imgs[idx]
img = Image.open(img_path).convert('RGB')
label_name = img_path.split('\\')[-2]
if label_name in ['Cat']:
label = 0
else:
label = 1
if self.train and self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
5.2 模型训练
from backbone.vgg import VGG
from dataset.cat_dog_data import CatDogDataset, data_transform
import torch
import torch.optim as optim
from backbone.vgg import VGG
import torch
import time
from data_augment.albu_weather_aug import visualize
if __name__ == '__main__':
BATCH_SIZE = 8
LEARNING_RATE = 0.001
EPOCH = 50
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
train_root = r'D:\personal\data\public_data\catsdogs\train'
val_root = r'D:\personal\data\public_data\catsdogs\val'
train_cat_dog = CatDogDataset(img_root=train_root, transform=data_transform['train'], is_train=True)
val_cat_dog = CatDogDataset(img_root=val_root, transform=data_transform['val'], is_train=False)
train_dataloader = torch.utils.data.DataLoader(train_cat_dog, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
val_dataloader = torch.utils.data.DataLoader(val_cat_dog, batch_size=1, shuffle=False, num_workers=0)
net = VGG(num_classes=2)
net = net.to(device)
cost = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=LEARNING_RATE, momentum=0.9, weight_decay=5e-4)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer)
for epoch in range(EPOCH):
net.train()
avg_loss = 0.0
cnt = 0
for images, labels in train_dataloader:
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
pred = net(images)
loss = cost(pred, labels)
avg_loss += loss.data
cnt += 1
print('[{}/{}],loss={},avg_loss={}'.format(epoch, EPOCH,loss, avg_loss/cnt))
loss.backward()
optimizer.step()
scheduler.step(avg_loss)
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











