







 本文详细探讨了CUDA Occupancy Calculator的使用,解释了占用率的计算原理,涉及显卡的线程束、寄存器资源等概念。同时,介绍了显卡算力的计算方法,包括FP32、FP16以及Tensor Core的性能差异,并通过代码展示了不同计算模式下的性能峰值。强调理解设备特性和公式的重要性,避免被误导。
本文详细探讨了CUDA Occupancy Calculator的使用,解释了占用率的计算原理,涉及显卡的线程束、寄存器资源等概念。同时,介绍了显卡算力的计算方法,包括FP32、FP16以及Tensor Core的性能差异,并通过代码展示了不同计算模式下的性能峰值。强调理解设备特性和公式的重要性,避免被误导。
我的显卡是RTX 2060 super,其计算能力是7.5。最近发现CUDA提供了自动计算占用率的计算器即CUDA Occupancy Calculator,官网自行下载即可。
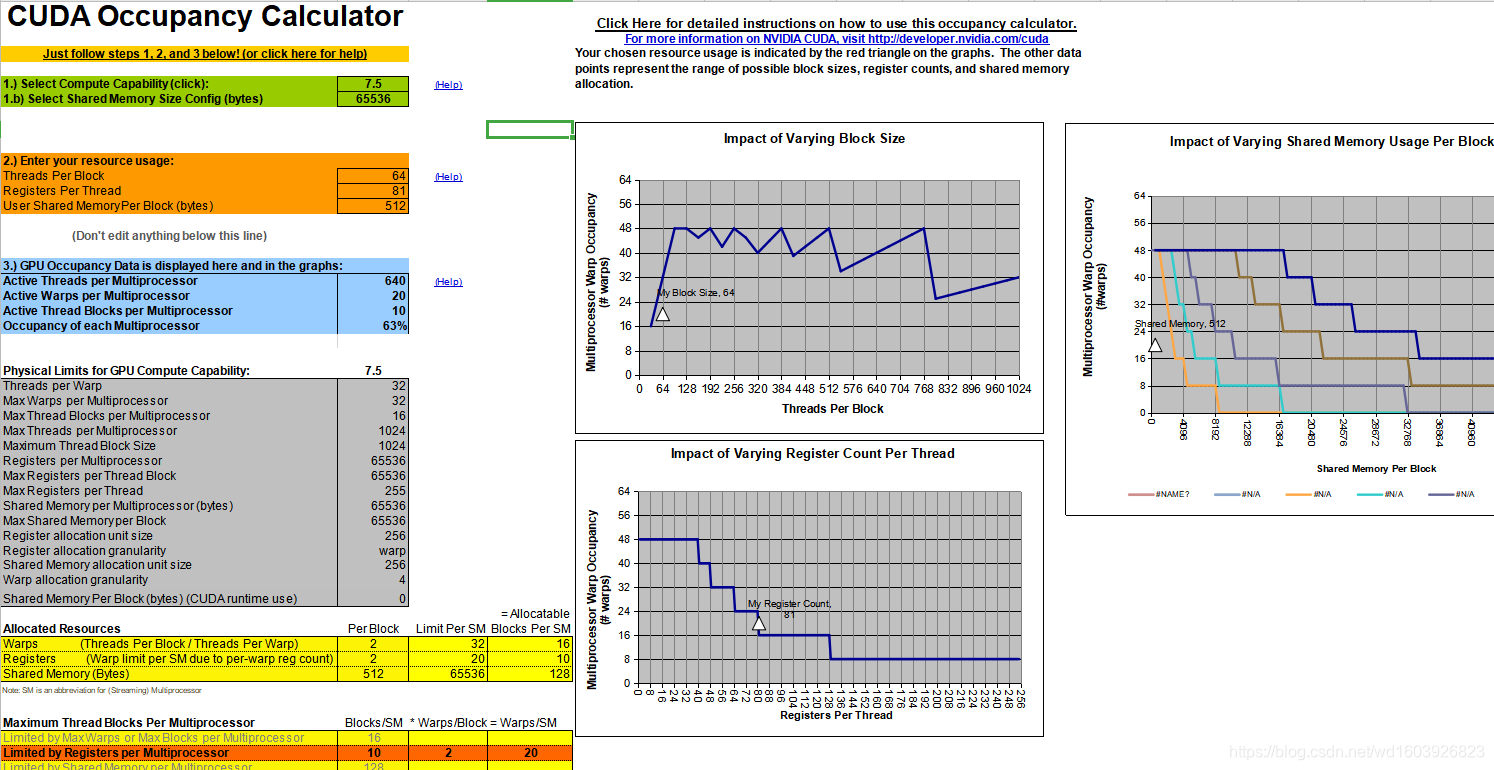
我下载下来后,阅读完说明,设置了下图紫色圈中的几个数值。开始想了很久,不知道为何占用率给出竟然是63%,现在已明白,记录在此。
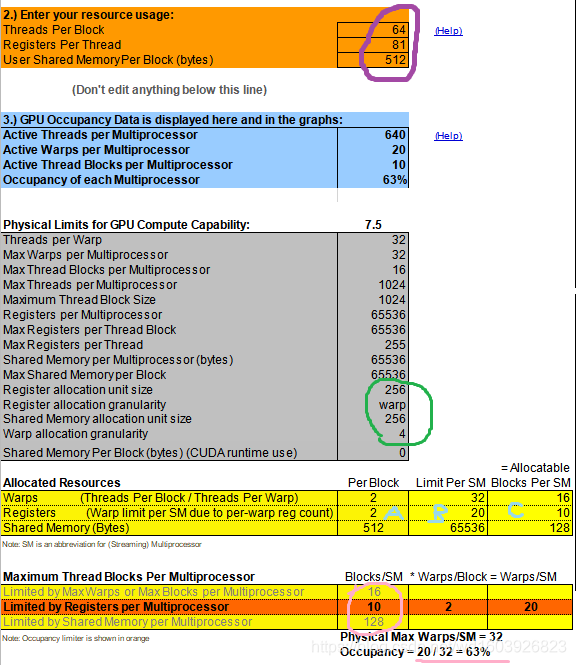
首先,不要忽略绿色圈中的那几个设备特性,我原来一直不知道这几个对占用率有何影响。
1、然后占用率公式大家都知道:每个SM中活跃线程束的数量/每个SM中最大的线程束的数量。可以看到我的设备每个SM中最大线程束是32固定的,所以现在问题变为活跃线程束为什么是20。粉色圈中的部分的最小值才是决定占用率的因素,所以可以看到占用率是由上图中粉色圈中的寄存器因素计算而来。寄存器因素显示:(每个SM有10个活跃blocks)*(每个block有2个线程束)=20.(所以占用率公式的分子即活跃线程束的数量就是这样来的)。
2、所以现在变为寄存器因素中每个SM中活跃blocks为什么是10。也就是浅蓝色C为什么是10。易知,C=B/A。所以此时问题变为A为什么==2,B为什么==20。
3、我查看了下A的公式:=IF(myAllocationGranularity="block",CEILING(CEILING(MyWarpsPerBlock,myWarpAllocationGranularity)*MyRegCount*limitThreadsPerWarp,myAllocationSize),MyWarpsPerBlock) 而绿色圈中显示寄存器分配粒度不是"block",而是warp,所以此时A=myWarpsPerBlock=64/32=2
4、我查看了下B的公式:
=IF(myAllocationGranularity="block",limitRegsPerBlock,FLOOR(limitRegsPerBlock/CEILING(MyRegCount*limitThreadsPerWarp,myAllocationSize),myWarpAllocationGranularity)) 而绿色圈中显示寄存器分配粒度不是"block",而是warp,所以此时B=FLOOR(limitRegsPerBlock/CEILING(MyRegCount*limitThreadsPerWarp,myAllocationSize),myWarpAllocationGranularity) 代入我紫色圈中的设置数值后:
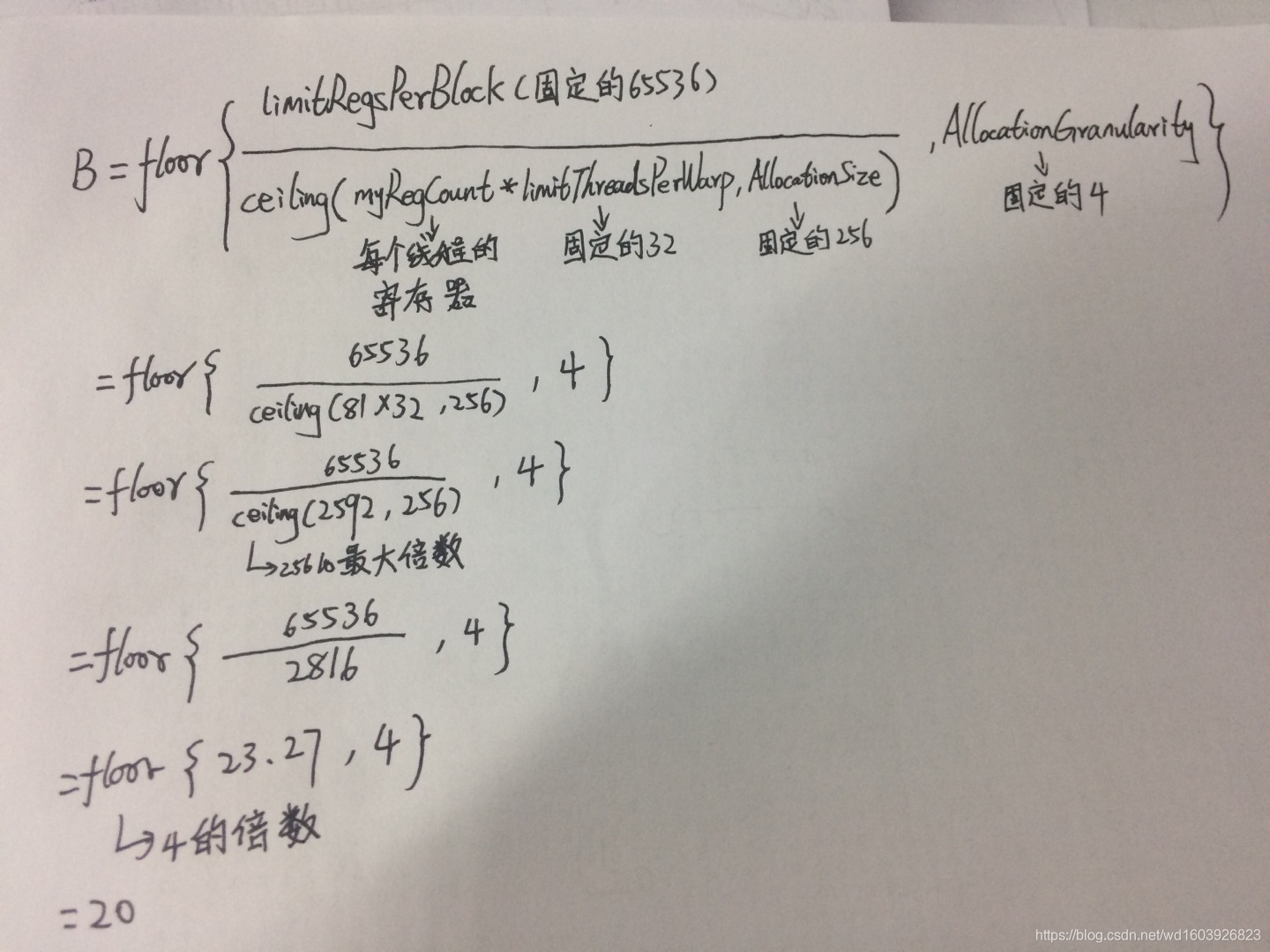
所以到此为止,就知道ABC三处是怎么计算的了。
5、关于warps的B位置为什么是32,我看了下公式:max warps per SM即查灰色部分的设备特性可知=32。
总结:反正遇到不会的地方很多时候还是得靠自己查自己想自己查这样反复,因为网上常常没有答案甚至很多人的答案是错的。反正是CUDA提供的自动计算器,点开单元格就知道公式了。 网上很多人讲的都是错的,而且不要寄希望于一些CUDA群,都是一群僵尸。
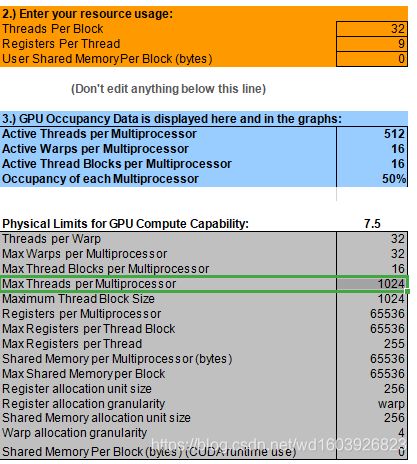
6、突然想到一个问题,基本每本书上都说每个SM跑多少个block或者说多少个线程,是由寄存器资源与共享内存决定的。假设我没用共享内存,如下图,我只用了寄存器,每个线程9个寄存器,我以前以为每个SM上65536个寄存器,那么这个SM上最多应该可以跑65536/9=7281个线程!而这个CUDA提供的计算器却给死了每个SM最多跑1024个线程,16个blocks!所以我有点不知道书上说那些话的意义在哪儿了??
~~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~~~~~
下面我们看显卡算力怎么计算,买显卡肯定要考虑算力,除了在GPU Database | TechPowerUp上面查,还可以自己计算:
由官网,我们可以查到Nvidia CUDA Cores的个数假设为core_num,GPU每个CUDA Core单个周期浮点计算系数是2 ,以及Boost Clock (GHz)假设为blockfreq,那么FP32即Single-Precision Performance即标准算力=core_num*blockfreq*2/1000= (单位 :TFLOPS,这个公式标记为公式1) (Nvidia官网给出的各个显卡的算力就是如此计算的,以 https://www.nvidia.cn/content/dam/en-zz/Solutions/Data-Center/tesla-p100/pdf/nvidia-tesla-p100-datasheet.pdf 为例大家可以看到官文通常说的显卡的算力正是如此计算)
但还有一种算力,大家看下面Nvidia官网给的A100的规格表:
 这个红色部分FP32=CUDA核心数6912*Boost Clock 1.41*2/1000=19.5 TFLOPS (此处是按公式1计算所得)。证明之前所述公式是正确的(按道理就该如此计算)。
这个红色部分FP32=CUDA核心数6912*Boost Clock 1.41*2/1000=19.5 TFLOPS (此处是按公式1计算所得)。证明之前所述公式是正确的(按道理就该如此计算)。
但加了Tensor的就不是如此计算,即所谓的Tensor FP32或者说TF32(Tensor Float 32,是一种截短的 Float32 数据格式,将 FP32 中 23 个尾数位截短为 10 bits,而指数位仍为 8 bits,总长度为 19 (=1 + 8 + 10) bits。为什么选择 1 + 8 + 10 这个配置?按照 NVIDIA 官方的说法,TF32 保持了与 FP16 同样的精度(尾数位都是 10 位),同时还保持了 FP32 的动态范围(指数位都是 8 位)。)就到了156 TFLOPS。至于156TFLOPS是怎么计算出来的,大家可以看聊聊 GPU 峰值计算能力 - 知乎大神这一篇的代码。所以我们买产品时别被忽悠了,说FP16性能达到多少多少 TFLOPS,可能是玩文字游戏,因为他可能说的是Tensor Core FP16峰值计算能力,两者是不一样的:
printf("=================GPU #%d=================\n", i);
CHECK_CUDA(cudaGetDeviceProperties(&prop, i), "cudaGetDeviceProperties error");
printf("GPU Name = %s\n", prop.name);
printf("Compute Capability = %d.%d\n", prop.major, prop.minor);
printf("GPU SMs = %d\n", prop.multiProcessorCount);
printf("GPU CUDA cores = %d\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount);
printf("GPU SM clock rate = %.3f GHz\n", prop.clockRate/1e6);
printf("GPU Mem clock rate = %.3f GHz\n", prop.memoryClockRate/1e6);
printf("FP32 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2);
if(has_fp16(prop.major, prop.minor))
{
printf("FP16 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2 * 2);
}
if(has_fp16_hfma2(prop.major, prop.minor))
{
printf("FP16 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2 * 4);
}
if(has_bf16(prop.major, prop.minor))
{
printf("BF16 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2 * 2);
}
if(has_int8(prop.major, prop.minor))
{
printf("INT8 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2 * 4);
}
if(has_tensor_core_v1(prop.major, prop.minor))
{
printf("Tensor Core FP16 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2 * 8);
}
if(has_tensor_core_v2(prop.major, prop.minor))
{
printf("Tensor Core FP16 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2 * 8);
printf("Tensor Core INT8 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2 * 16);
}
if(has_tensor_core_v3(prop.major, prop.minor))
{
printf("Tensor Core TF32 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2 * 8);
printf("Tensor Core FP16 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2 * 16);
printf("Tensor Core BF16 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2 * 16);
printf("Tensor Core INT8 Peak Performance = %.3f GFLOPS\n", cc2cores(prop.major, prop.minor) * prop.multiProcessorCount * (prop.clockRate / 1e6) * 2 * 32);
}如大神代码中所述:
SM clock rate也就是公式1所述的Boost Clock(单位GHz),SMs(MultiProcessorCount)以及CUDA Cores官网会给出,那么大神代码中的cc2cores=CUDA Cores/SMs。那么之前的公式1也可写成FP32 PP(Peak Performance)=cc2cores*SMs*SM clock rate*2 (大家可以套A100的参数 结果均是1.95TFLOPS )
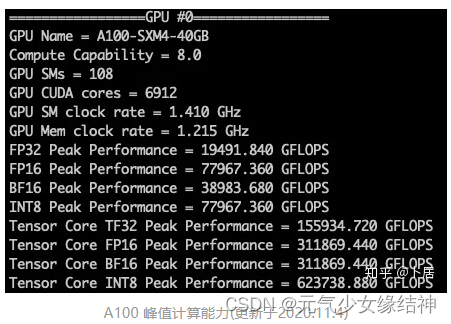
FP16 PP=FP32 PP*2或者FP32 PP*4
Tensor Core FP16 PP=FP32 PP*8或者FP32 PP*16
Tensor Core TF32 PP=FP32 PP*8 (所以上图中,19491.84*8=155934.720=156TFLOPS,与下图官网所述相同了)
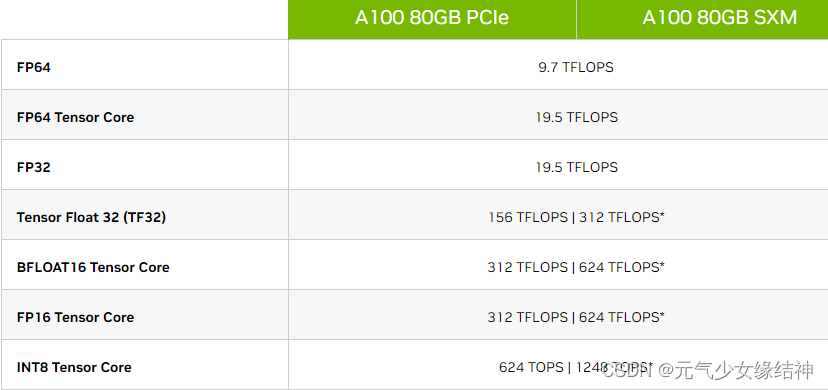
参考: A100 Tensor Float 32 性能实测 - 知乎


















 327
327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











