







动态并行:经常会遇到强依赖性算法流程如下所示,按传统观念以下流程是不可并行的:
void test_serial(Mat &low_energy,Mat &peak_value_ore_point_image)
{
for (int r = 1; r < low_energy.rows - 1; r++ )
{
for (int c = 1; c < low_energy.cols - 1; c++ )
{
//8邻居极值
ushort leftH = low_energy.ptr<ushort>(r)[c - 1];
ushort rightH = low_energy.ptr<ushort>(r)[c + 1];
ushort upH = low_energy.ptr<ushort>(r - 1)[c];
ushort downH = low_energy.ptr<ushort>(r + 1)[c];
ushort currentH = low_energy.ptr<ushort>(r)[c];
ushort leftUpH = low_energy.ptr<ushort>(r - 1)[c - 1];
ushort leftDownH = low_energy.ptr<ushort>(r + 1)[c - 1];
ushort rightUpH = low_energy.ptr<ushort>(r - 1)[c + 1];
ushort rightDownH = low_energy.ptr<ushort>(r + 1)[c + 1];
int count =(currentH <= leftH) + (currentH <= rightH) + (currentH <= upH) + (currentH <= downH) +
(currentH <= leftUpH) + (currentH <= leftDownH) + (currentH <= rightUpH) + (currentH <= rightDownH);
float avg = (float)(leftH + rightH + upH + downH + leftUpH + leftDownH + rightUpH + rightDownH)/8;
float rate = currentH / avg;
float K0 = 0.88;
if (count >= 7 && rate < 0.915)
{
low_energy.ptr<ushort>(r)[c] = 52428;
if(rate<K0 )
{
low_energy.ptr<ushort>(r)[c] = 0;
}
}
}
}
}在i7-6700上测试,如下所示性能提升50%!!!这已经是巨大的性能提升了,我原以为这种强依赖性流程就这样了无法加速了,原来还是可以提升的。我觉得如果依赖性流程内部计算量更大,则加速比更大。
image 0 time: serial:8.28996 parallel: 4.36827 ms!
image 1 time: serial:8.20621 parallel: 4.69727 ms!
image 2 time: serial:8.21747 parallel: 4.42042 ms!
image 3 time: serial:8.22632 parallel: 4.45671 ms!
image 4 time: serial:8.21633 parallel: 4.43818 ms!
image 5 time: serial:8.21107 parallel: 4.43394 ms!
image 6 time: serial:8.17935 parallel: 4.67812 ms!
image 7 time: serial:8.15103 parallel: 4.53115 ms!
image 8 time: serial:8.17055 parallel: 4.32604 ms!
image 9 time: serial:8.33905 parallel: 5.32993 ms!
image 10 time: serial:8.25718 parallel: 4.40927 ms!
image 11 time: serial:8.12002 parallel: 4.4775 ms!
image 12 time: serial:8.08636 parallel: 4.59426 ms!
image 13 time: serial:8.24948 parallel: 4.73721 ms!
image 14 time: serial:8.10095 parallel: 4.48008 ms!
image 15 time: serial:8.11938 parallel: 4.26852 ms!
image 16 time: serial:8.12885 parallel: 4.54245 ms!
image 17 time: serial:8.33526 parallel: 4.53592 ms!
image 18 time: serial:8.32469 parallel: 5.01244 ms!
image 19 time: serial:8.17616 parallel: 4.42041 ms!
image 20 time: serial:8.0406 parallel: 4.6124 ms!
image 21 time: serial:8.01685 parallel: 4.35252 ms!
image 22 time: serial:7.99626 parallel: 4.85486 ms!
image 23 time: serial:8.01509 parallel: 4.66033 ms!
image 24 time: serial:8.0412 parallel: 5.21661 ms!
image 25 time: serial:8.00112 parallel: 5.12366 ms!
image 26 time: serial:8.00872 parallel: 5.30759 ms!
image 27 time: serial:8.08212 parallel: 4.46521 ms!
image 28 time: serial:7.99662 parallel: 4.54408 ms!
image 29 time: serial:8.01913 parallel: 4.57607 ms!
image 30 time: serial:8.02753 parallel: 4.28367 ms!
image 31 time: serial:8.00196 parallel: 4.36592 ms!
image 32 time: serial:7.99319 parallel: 4.85871 ms!
image 33 time: serial:8.05612 parallel: 4.40619 ms!
image 34 time: serial:7.98108 parallel: 4.25851 ms!
image 35 time: serial:7.97976 parallel: 4.20541 ms!
image 36 time: serial:7.95081 parallel: 5.24846 ms!
image 37 time: serial:7.97135 parallel: 4.49553 ms!
image 38 time: serial:7.92144 parallel: 4.14441 ms!
image 39 time: serial:7.96547 parallel: 4.54834 ms!
image 40 time: serial:7.95329 parallel: 4.29757 ms!
image 41 time: serial:7.91904 parallel: 4.55894 ms!
image 42 time: serial:7.96026 parallel: 4.72673 ms!
image 43 time: serial:7.91893 parallel: 4.98076 ms!
image 44 time: serial:7.96942 parallel: 4.38226 ms!
image 45 time: serial:7.9518 parallel: 4.5566 ms!
image 46 time: serial:7.97113 parallel: 4.67357 ms!
image 47 time: serial:8.02315 parallel: 4.42928 ms!
image 48 time: serial:8.17986 parallel: 4.12026 ms!
image 49 time: serial:7.99211 parallel: 4.79029 ms!
image 50 time: serial:7.97364 parallel: 4.73891 ms!
image 51 time: serial:8.00514 parallel: 4.92114 ms!
image 52 time: serial:8.01574 parallel: 4.43331 ms!
image 53 time: serial:8.03744 parallel: 4.98955 ms!
image 54 time: serial:8.04146 parallel: 4.56716 ms!
image 55 time: serial:8.22792 parallel: 4.55482 ms!
image 56 time: serial:8.14872 parallel: 5.26019 ms!
image 57 time: serial:8.2234 parallel: 4.54216 ms!
image 58 time: serial:8.20317 parallel: 4.71279 ms!
image 59 time: serial:8.1112 parallel: 4.27128 ms!
image 60 time: serial:8.11511 parallel: 4.16982 ms!
image 61 time: serial:8.19568 parallel: 4.86366 ms!
image 62 time: serial:8.23643 parallel: 4.75979 ms!
image 63 time: serial:8.15154 parallel: 4.97772 ms!
image 64 time: serial:8.1823 parallel: 4.80278 ms!
image 65 time: serial:8.24163 parallel: 4.77684 ms!
image 66 time: serial:8.19567 parallel: 4.63034 ms!
image 67 time: serial:8.1491 parallel: 4.83211 ms!
image 68 time: serial:8.27648 parallel: 4.84047 ms!
image 69 time: serial:8.41745 parallel: 4.87089 ms!
image 70 time: serial:8.1813 parallel: 4.33512 ms!
image 71 time: serial:8.1935 parallel: 4.51868 ms!
image 72 time: serial:8.30606 parallel: 4.54615 ms!
image 73 time: serial:8.383 parallel: 5.01877 ms!
image 74 time: serial:8.49949 parallel: 5.91977 ms!
image 75 time: serial:8.42695 parallel: 4.9541 ms!
image 76 time: serial:8.23593 parallel: 4.80936 ms!
image 77 time: serial:8.22413 parallel: 4.63376 ms!
image 78 time: serial:8.22005 parallel: 5.10463 ms!
image 79 time: serial:8.21625 parallel: 4.7416 ms!
image 80 time: serial:8.19174 parallel: 4.33946 ms!测试代码传在:依赖性流程的动态并行方案-小程序文档类资源-CSDN下载
我还测了一下对时间很短流程哪怕1ms的改动态并行后也不会因为开销而变大多少,依旧保持整体加速比大的优点。
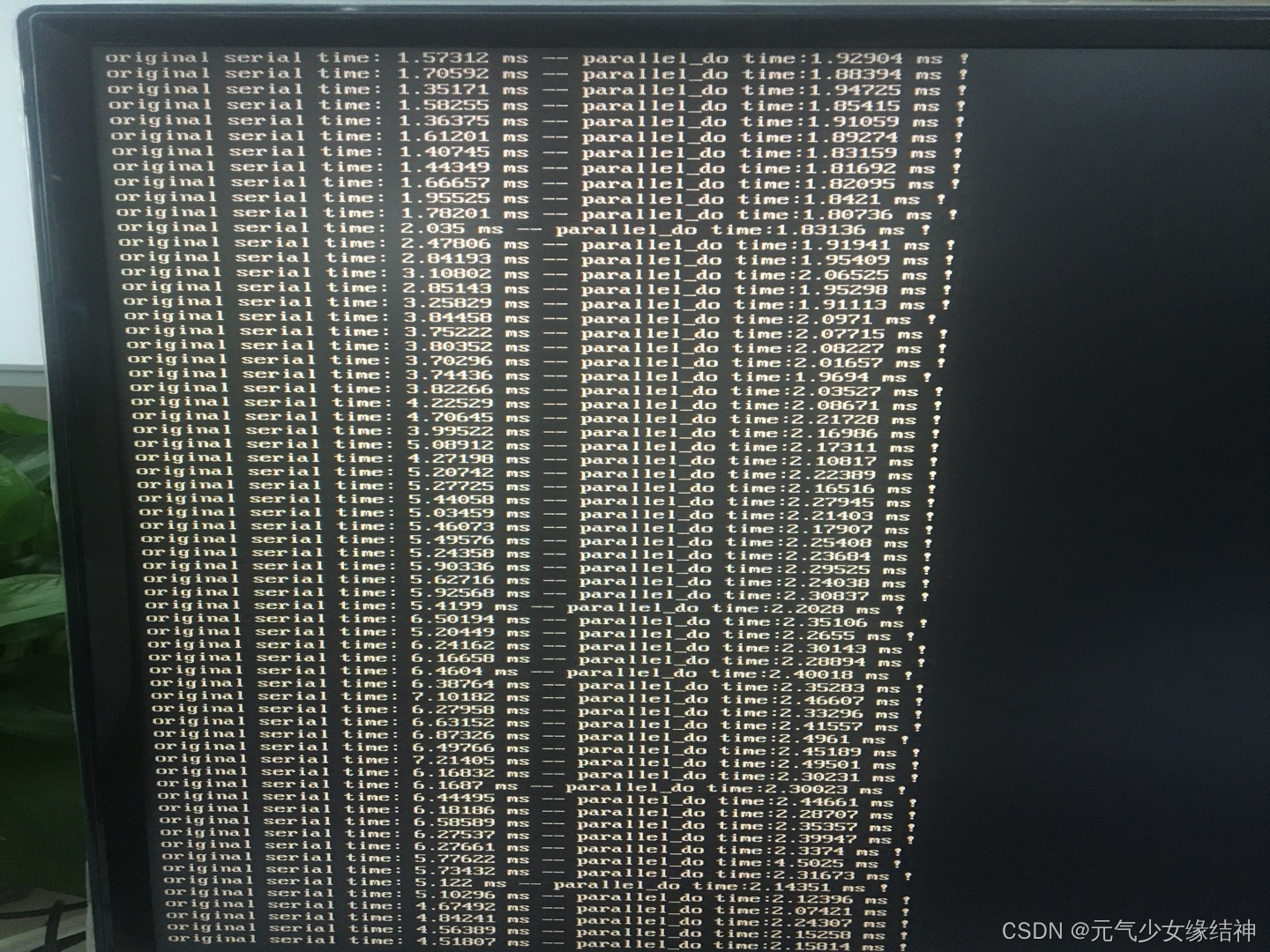
看上图结果,哪怕这种耗时短的流程,也可加速起来!!!
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
学习的书籍是《Pro TBB--c++ programming with TBB》

1、flow graph加速方式是task overlap,应该也是事先分配到不同的core上,然后对每个core上的多个tasks进行overlap吧?

2、parallel_for仅仅就是将多个tasks分配在不同的core上吧,比如本来是对一个vector内80个目标进行for循环,应用parallel_for后可能就是共8个cores,每个core上分配10个目标,但每个core上的10个目标应该是串行执行吧?

3、SIMD并不是将多个数据分配在不同cores上来并行吧,它是怎么做到并行的为每个数据开个线程?就是单指令多数据这种模式。另外这里不是容器也可以用SIMD哦?然后如果改写的这个地方原本有continue或者break怎么办呢?

4、是这样理解吧?

5、是这样看有没有增加workitem吗?(已明白)

6、为什么这里说斜对角这里的数据计算没有依赖性??明明有啊,不跟其他地方的数据一样需要依赖左边和上面的数据计算完毕?(已明白)

7、这里我没看懂,--ref_count这里怎么是这样??
另外使用parallel_do的情景:要么是无法随机访问的容器进行顺序访问;要么是循环是动态的,即每次循环内部不止访问一个元素,而是可能需要访问别的元素?

8、figure2_25应该就是上图这样理解吧,parallel_pipeline增大吞吐率。红外3D立体图的例子不完全是这样,但类似这样来增大吞吐率。
a,但parallel_pipeline的滤镜种类filter::serial_in_order和filter::parallel分别什么时候使用??我觉得书上的2-27,2-28两个例子不够让我明白。
b,2-30下面说线性滤镜、非线性滤镜,说parallel_pipeline只适合线性filters。到底什么叫线性filters,什么叫非线性??
c,这样看来parallel_pipeline单单这个指令就可以实现task overlap以及吞吐率变大。而flow graph也是有task overlap的功能,但区别就是graph适合非线性filters?

9、plus<double>()这句是什么意思??

10、3-16这个例子没看懂

11、PSTL一般只适合不复杂的算法很简单的算法,此时用TBB反而不适合。这个例子里用到了SIMD指令,pstl::execution::seq就是传统串行,那加不加这个指令没什么区别呀??unseq就是只有一个线程但这个线程内对多个目标的操作可overlap,par就是开了多个线程每个线程处理多少目标而且每个线程内对多个目标执行的每个操作串行,par_unseq就是开了多个线程每个线程处理多少目标而且每个线程内对多个目标执行的每个操作可overlap。是这样理解吗?

12、是这样理解吧,假共享导致的乒乓效应?
(接下来跳到第9章去学习了,因为我要查一个东西,后续看完再来看5到8章)

13、TBB使用的是任务而非OMP一样用的线程,TBB会动态的将并行任务分配到限制的硬件资源上,加上有TBB线程池和窃取式调度器,所以即使面对嵌套并行也不怕。 线程池和窃取式调度器??

14、并发和并行是不是如上图该这样理解:某一段时间内,看到A和B都有执行,这叫并发。可以看到9-4两个图标记的这段时间内AB都有执行,所以两个都可以叫并发。其中的特例是如果A和B是同时开始的,那么这就叫并发中的一种即并行。
这个图9-4下的这一段话什么意思?是说9-5的这两个并行执行的循环是否是并发就看这两个loop是在同一个进程中还是在不同的进程中?
15、关于第5~7点所述的动态并行时需注意逻辑问题如下:
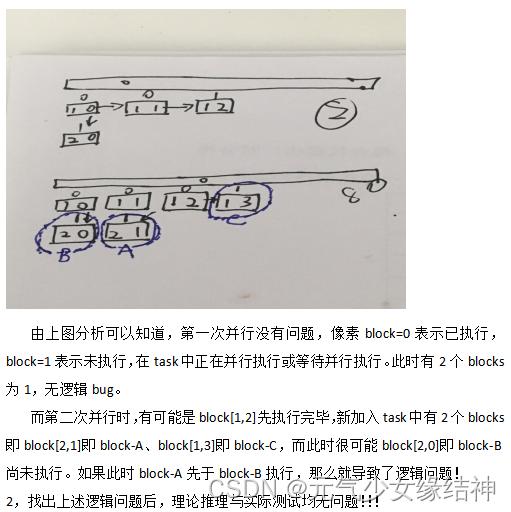 文章一开始那个改动态并行的工程就是这个逻辑问题困扰我很久,改正过来后就正确了,而且实现了加速。大家使用动态并行时也一定要注意这样的逻辑漏洞。
文章一开始那个改动态并行的工程就是这个逻辑问题困扰我很久,改正过来后就正确了,而且实现了加速。大家使用动态并行时也一定要注意这样的逻辑漏洞。
16、补充关于并发容器concurrent_vector,之前囫囵吞枣看过,但是没有切实感受需要小心使用,直到我遇到下面的问题:
首先我是如下写,没有问题,能得到vec1、vec2正确结果:
std::vector<Point> std_vecdata;
//一些计算得到std_vecdata内容,此处省略
concurrent_vector<Point> vec1;
concurrent_vector<Point> vec2;
parallel_for_(Range(0, std_vecdata.size()), [&](const Range& range)
{
for (int id = range.start; id < range.end; id++)
{
Point tmp_pt1;
//一些计算,此处省略
vec1.push_back(tmp_pt1);
Point tmp_pt2;
//一些计算,此处省略
vec2.push_back(tmp_pt2);
}
});可是当我改成如下写时,得到的vec1、vec2的结果却错误?!!!
std::vector<Point> std_vecdata;
//一些计算得到std_vecdata内容,此处省略
concurrent_vector<Point> vec1;
concurrent_vector<Point> vec2;
for(int id=0;id!=std_vecdata.size();id++)
{
Point tmp_pt1;
//一些计算,此处省略
vec1.push_back(tmp_pt1);
Point tmp_pt2;
//一些计算,此处省略
vec2.push_back(tmp_pt2);
}为何错误呢,我以为第二种写法不应该错误的啊,相当于把这两个并发容器当做普通std容器在使用,怎么可能错呢。于是我去查这本书对应的地方,看到了书上所述:

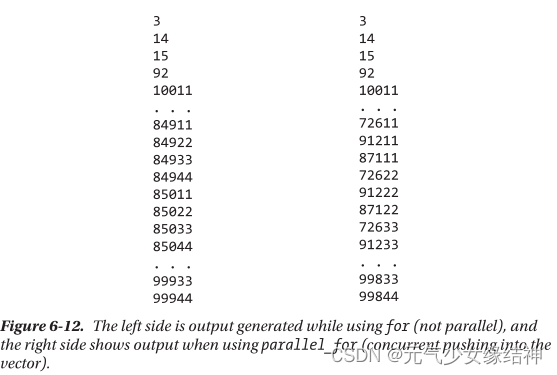
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
之前很纠结的为什么应用TBB后没有每个核跑到100%,其实不用纠结,要么是计算不够,要么是加速部分程序被应用到了大的工程里,其实将其单独拿出来可以把核跑满的。不必纠结这个问题。
















 216
216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











