







从并发到并行
-
摩尔定律:停止增长了吗?
指望靠单核性能的增长带来程序性能提升的时代一去不复返了,现在要我们动动手为多核优化一下老的程序,才能搭上摩尔定律的顺风车。
晶体管的密度的确仍在指数增长,但处理器主频却开始停止增长了,甚至有所下降。
结论:狭义的摩尔定律没有失效。但晶体管数量的增加,不再用于继续提升单核频率,转而用于增加核心数量。单核性能不再指数增长!
-
神话与现实:2 * 3GHz < 6GHz
一个由双核组成的3GHz的CPU实际上提供了6GHz的处理能力,是吗?
- 显然不是。甚至在两个处理器上同时运行两个线程也不见得可以获得两倍的性能。相似的,大多数多线程的应用不会比双核处理器的两倍快。他们应该比单核处理器运行的快,但是性能毕竟不是线性增长。
- 为什么无法做到呢?首先,为了保证缓存一致性以及其他握手协议需要运行时间开销。在今天,双核或者四核机器在多线程应用方面,其性能不见得的是单核机器的两倍或者四倍。这一问题一直伴随CPU发展至今。
-
并发和并行的区别
- 并发:单核处理器,操作系统通过时间片调度算法,轮换着执行着不同的线程,看起来就好像是同时运行一样,其实每一时刻只有一个线程在运行。目的:异步地处理多个不同的任务,避免同步造成的阻塞。
- 并行:多核处理器,每个处理器执行一个线程,真正的同时运行。目的:将一个任务分派到多个核上,从而更快完成任务。
-
因特尔的开源并行编程库:TBB
https://link.springer.com/chapter/10.1007%2F978-1-4842-4398-5_2
- parallel_invoke
- parallel_for
- parallel_reduce
- parallel_deterministic_reduce
- parallel_scan
- parallel_for_each
- parallel_do
- pipeline
- parallel_pipeline
- parallel_sort
-
TBB安装
ubuntu:
sudo apt-get install libtbb-dev从源码安装:
https://blog.csdn.net/weixin_42973508/article/details/111681426 -
案例代码:基于标准库
#include <iostream> #include <thread> #include <string> void download(std::string file) { for (int i = 0; i < 10; i++) { std::cout << "Downloading " << file << " (" << i * 10 << "%)..." << std::endl; std::this_thread::sleep_for(std::chrono::milliseconds(400)); } std::cout << "Download complete: " << file << std::endl; } void interact() { std::string name; std::cin >> name; std::cout << "Hi, " << name << std::endl; } int main() { std::thread t1([&] { download("hello.zip"); }); interact(); std::cout << "Waiting for child thread..." << std::endl; t1.join(); std::cout << "Child thread exited!" << std::endl; return 0; } -
TBB版本:任务组
用一个任务组
tbb::task_group启动多个任务,一个负责下载,一个负责和用户交互。并在主线程中等待该任务组里的任务全部执行完毕。区别在于,一个任务不一定对应一个线程,如果任务数量超过CPU最大的线程数,会由 TBB 在用户层负责调度任务运行在多个预先分配好的线程,而不是由操作系统负责调度线程运行在多个物理核心。
#include <iostream> #include <tbb/task_group.h> #include <string> void download(std::string file) { for (int i = 0; i < 10; i++) { std::cout << "Downloading " << file << " (" << i * 10 << "%)..." << std::endl; std::this_thread::sleep_for(std::chrono::milliseconds(400)); } std::cout << "Download complete: " << file << std::endl; } void interact() { std::string name; std::cin >> name; std::cout << "Hi, " << name << std::endl; } int main() { tbb::task_group tg; tg.run([&] { download("hello.zip"); }); tg.run([&] { interact(); }); tg.wait(); return 0; } -
封装好了的:
parallel_invoke#include <iostream> #include <tbb/parallel_invoke.h> #include <string> void download(std::string file) { for (int i = 0; i < 10; i++) { std::cout << "Downloading " << file << " (" << i * 10 << "%)..." << std::endl; std::this_thread::sleep_for(std::chrono::milliseconds(400)); } std::cout << "Download complete: " << file << std::endl; } void interact() { std::string name; std::cin >> name; std::cout << "Hi, " << name << std::endl; } int main() { tbb::parallel_invoke([&] { download("hello.zip"); }, [&] { interact(); }); return 0; }更好的例子:
#include <iostream> #include <tbb/parallel_invoke.h> #include <string> int main() { std::string s = "Hello, world!"; char ch = 'd'; tbb::parallel_invoke([&] { for (size_t i = 0; i < s.size() / 2; i++) { if (s[i] == ch) std::cout << "found!" << std::endl; } }, [&] { for (size_t i = s.size() / 2; i < s.size(); i++) { if (s[i] == ch) std::cout << "found!" << std::endl; } }); return 0; }
并行循环
-
时间复杂度(time-efficiency)与工作量复杂度(work-efficiency)
对于并行算法,复杂度的评估则要分为两种:
-
时间复杂度:程序所用的总时间(重点)
-
工作复杂度:程序所用的计算量(次要)
-
这两个指标都是越低越好。时间复杂度决定了快慢,工作复杂度决定了耗电量。
-
通常来说,工作复杂度 = 时间复杂度 * 核心数量
-
1个核心工作一小时,4个核心工作一小时。时间复杂度一样,而后者工作复杂度更高。
-
1个核心工作一小时,4个核心工作1/4小时。工作复杂度一样,而后者时间复杂度更低。
-
并行的主要目的是降低时间复杂度,工作复杂度通常是不变的。甚至有牺牲工作复杂度换取时间复杂度的情形。
-
并行算法的复杂度取决于数据量 n,还取决于线程数量 c,比如 O(n/c)。不过要注意如果线程数量超过了 CPU 核心数量,通常就无法再加速了,这就是为什么要买更多核的电脑。
-
也有一种说法,认为要用 c 趋向于无穷时的时间复杂度来衡量,比如 O(n/c) 应该变成 O(1)。
-
-
一个映射的例子
#include <iostream> #include <vector> #include <cmath> int main() { size_t n = 1<<26; std::vector<float> a(n); for (size_t i = 0; i < n; i++) { a[i] = std::sin(i); } return 0; }结论:串行映射的时间复杂度为 O(n),工作复杂度为 O(n),其中 n 是元素个数
-
并行映射
#include <iostream> #include <tbb/task_group.h> #include <vector> #include <cmath> int main() { size_t n = 1<<26; std::vector<float> a(n); size_t maxt = 4; tbb::task_group tg; for (size_t t = 0; t < maxt; t++) { auto beg = t * n / maxt; auto end = std::min(n, (t + 1) * n / maxt); tg.run([&, beg, end] { for (size_t i = beg; i < end; i++) { a[i] = std::sin(i); } }); } tg.wait(); return 0; }结论:并行映射的时间复杂度为 O(n/c),工作复杂度为 O(n),其中 c 是线程数量
-
封装好了:
parallel_forvoid parallel_for(const Range &range, const Body &body);#include <iostream> #include <tbb/parallel_for.h> #include <vector> #include <cmath> int main() { size_t n = 1<<26; std::vector<float> a(n); tbb::parallel_for(tbb::blocked_range<size_t>(0, n), [&] (tbb::blocked_range<size_t> r) { for (size_t i = r.begin(); i < r.end(); i++) { a[i] = std::sin(i); } }); return 0; } -
面向初学者:
parallel_forvoid parallel_for(Index first, Index last, const Function &f)#include <iostream> #include <tbb/parallel_for.h> #include <vector> #include <cmath> int main() { size_t n = 1<<26; std::vector<float> a(n); tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t i) { a[i] = std::sin(i); }); return 0; }这种写法虽然简单,但是有代价,编译器在这里可能并不能在这里simd优化。
-
基于迭代器区间:
parallel_for_eachvoid parallel_for_each(Interator first, Interator last, const Body &body);#include <iostream> #include <tbb/parallel_for_each.h> #include <vector> #include <cmath> int main() { size_t n = 1<<26; std::vector<float> a(n); tbb::parallel_for_each(a.begin(), a.end(), [&] (float &f) { f = 32.f; }); return 0; } -
二维区间上的 for 循环:
blocked_range2d#include <iostream> #include <tbb/parallel_for.h> #include <tbb/blocked_range2d.h> #include <vector> #include <cmath> int main() { size_t n = 1<<13; std::vector<float> a(n * n); tbb::parallel_for(tbb::blocked_range2d<size_t>(0, n, 0, n), [&] (tbb::blocked_range2d<size_t> r) { for (size_t i = r.cols().begin(); i < r.cols().end(); i++) { for (size_t j = r.rows().begin(); j < r.rows().end(); j++) { a[i * n + j] = std::sin(i) * std::sin(j); } } }); return 0; } -
3维区间上的 for 循环:
blocked_range3d#include <iostream> #include <tbb/parallel_for.h> #include <tbb/blocked_range3d.h> #include <vector> #include <cmath> int main() { size_t n = 1<<13; std::vector<float> a(n * n); tbb::parallel_for(tbb::blocked_range3d<size_t>(0, n, 0, n, 0, n), [&] (tbb::blocked_range3d<size_t> r) { for (size_t i = r.pages().begin(); i < r.pages().end(); i++) { for (size_t j = r.cols().begin(); j < r.cols().end(); j++) { for (size_t k = r.rows().begin(); k < r.rows().end(); k++) { a[(i * n + j) * n + k] = std::sin(i) * std::sin(j) * std::sin(k); } } } }); return 0; }
缩进与扫描
-
缩并(reduce)
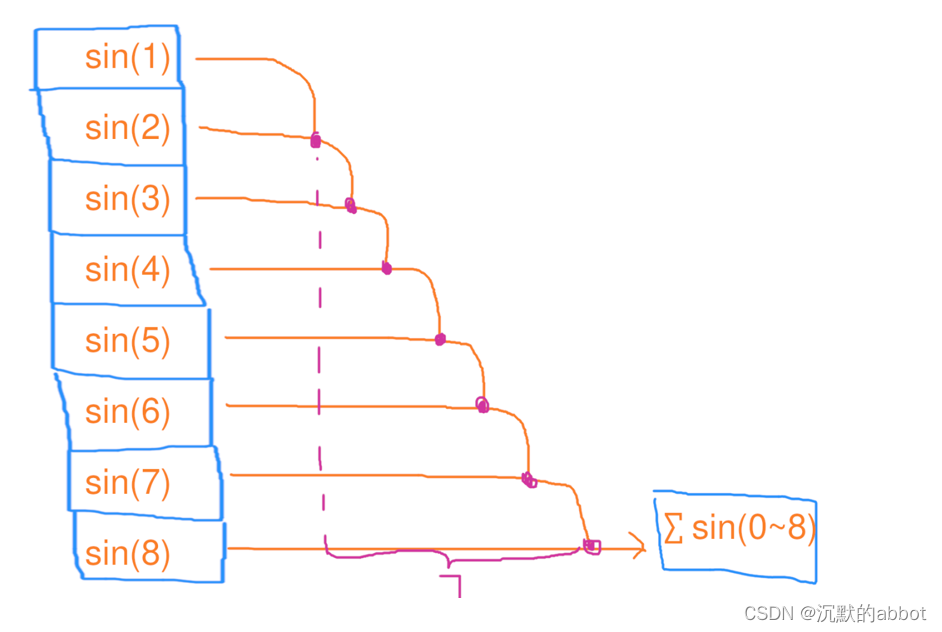
1个线程,依次处理8个元素的缩并,花了7秒
用电量:17=7度电
总用时:17=7秒#include <iostream> #include <vector> #include <cmath> int main() { size_t n = 1<<26; float res = 0; for (size_t i = 0; i < n; i++) { res += std::sin(i); } std::cout << res << std::endl; return 0; } -
并行缩并
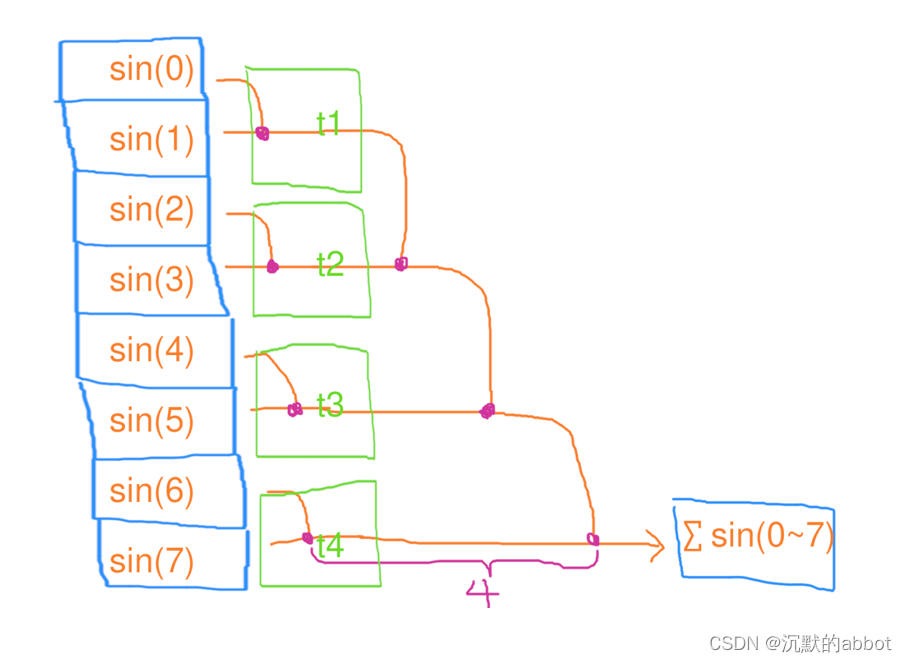
第一步、4个线程,每人处理2个元素的缩并,花了1秒第二步、1个线程,独自处理4个元素的缩并,花了3秒
用电量:4*1+1*3=7度电
总用时:1+3=4秒
#include <iostream> #include <tbb/task_group.h> #include <vector> #include <cmath> int main() { size_t n = 1<<26; float res = 0; size_t maxt = 4; tbb::task_group tg; std::vector<float> tmp_res(maxt); for (size_t t = 0; t < maxt; t++) { size_t beg = t * n / maxt; size_t end = std::min(n, (t + 1) * n / maxt); tg.run([&, t, beg, end] { float local_res = 0; for (size_t i = beg; i < end; i++) { local_res += std::sin(i); } tmp_res[t] = local_res; }); } tg.wait(); for (size_t t = 0; t < maxt; t++) { res += tmp_res[t]; } std::cout << res << std::endl; return 0; }结论:并行缩并的时间复杂度为 O(n/c+c),工作复杂度为 O(n),其中 n 是元素个数
-
改进的并行缩并(GPU)
刚才那种方式对 c 比较大的情况不友好,最后一个串行的 for 还是会消耗很多时间。
因此可以用递归的模式,每次只使数据缩小一半,这样基本每次都可以看做并行的 for,只需 log2(n) 次并行 for 即可完成缩并。
这种常用于核心数量很多,比如 GPU 上的缩并。
结论:改进后的并行缩并的时间复杂度为 O(logn),工作复杂度为 O(n)。
-
封装好了:
parallel_reduceValue parallel_reduce(const Range &range, const Value &identity, const RealBody &real_body, const Reduction &reduction);#include <iostream> #include <tbb/parallel_reduce.h> #include <tbb/blocked_range.h> #include <vector> #include <cmath> int main() { size_t n = 1<<26; float res = tbb::parallel_reduce(tbb::blocked_range<size_t>(0, n), (float)0, [&] (tbb::blocked_range<size_t> r, float local_res) { for (size_t i = r.begin(); i < r.end(); i++) { local_res += std::sin(i); } return local_res; }, [] (float x, float y) { return x + y; }); std::cout << res << std::endl; return 0; } -
保证每次运行任务区间分配的一致:
parallel_deterministic_reduce#include <iostream> #include <tbb/parallel_reduce.h> #include <tbb/blocked_range.h> #include <vector> #include <cmath> int main() { size_t n = 1<<26; float res = tbb::parallel_deterministic_reduce(tbb::blocked_range<size_t>(0, n), (float)0, [&] (tbb::blocked_range<size_t> r, float local_res) { for (size_t i = r.begin(); i < r.end(); i++) { local_res += std::sin(i); } return local_res; }, [] (float x, float y) { return x + y; }); std::cout << res << std::endl; return 0; } -
并行缩并的额外好处:能避免浮点误差,例如求平均值
#include <iostream> #include <tbb/parallel_reduce.h> #include <tbb/blocked_range.h> #include <vector> #include <cmath> int main() { size_t n = 1<<26; std::vector<float> a(n); for (size_t i = 0; i < n; i++) { a[i] = 10.f + std::sin(i); } float serial_avg = 0; for (size_t i = 0; i < n; i++) { serial_avg += a[i]; } serial_avg /= n; std::cout << serial_avg << std::endl; //串行当数据很多时候会有浮点数大加小精度损失 float parallel_avg = tbb::parallel_reduce(tbb::blocked_range<size_t>(0, n), (float)0, [&] (tbb::blocked_range<size_t> r, float local_avg) { for (size_t i = r.begin(); i < r.end(); i++) { local_avg += a[i]; } return local_avg; }, [] (float x, float y) { return x + y; }) / n; std::cout << parallel_avg << std::endl; return 0; } -
扫描(scan)
扫描和缩并差不多,只不过他会把求和的中间结果存到数组里去
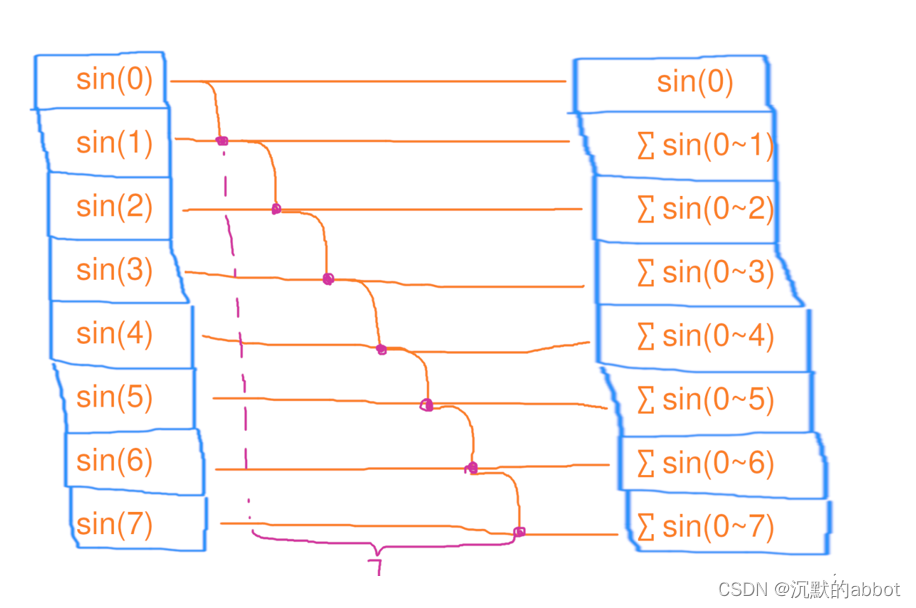
1个线程,依次处理8个元素的扫描,花了7秒用电量:1*7=7度电
总用时:1*7=7秒
#include <iostream> #include <vector> #include <cmath> int main() { size_t n = 1<<26; std::vector<float> a(n); float res = 0; for (size_t i = 0; i < n; i++) { res += std::sin(i); a[i] = res; } std::cout << a[n / 2] << std::endl; std::cout << res << std::endl; return 0; }结论:串行扫描的时间复杂度为 O(n),工作复杂度为 O(n)。
-
并行扫描
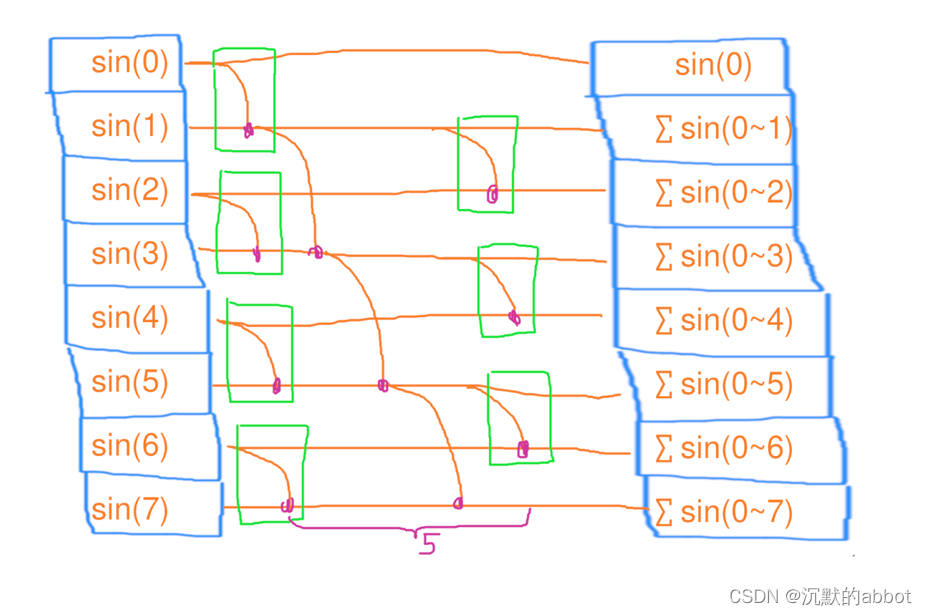
第一步、4个线程,每人处理2个元素的缩并,花了1秒第二步、1个线程,独自处理3个元素的缩并,花了3秒
第三步、3个线程,每人处理2个元素的缩并,花了1秒
用电量:41+13+3*1=10度电
总用时:1+3+1=5秒
#include <iostream> #include <tbb/task_group.h> #include <vector> #include <cmath> int main() { size_t n = 1<<26; std::vector<float> a(n); float res = 0; size_t maxt = 4; tbb::task_group tg1; std::vector<float> tmp_res(maxt); for (size_t t = 0; t < maxt; t++) { size_t beg = t * n / maxt; size_t end = std::min(n, (t + 1) * n / maxt); tg1.run([&, t, beg, end] { float local_res = 0; for (size_t i = beg; i < end; i++) { local_res += std::sin(i); } tmp_res[t] = local_res; }); } tg1.wait(); for (size_t t = 0; t < maxt; t++) { tmp_res[t] += res; res = tmp_res[t]; } tbb::task_group tg2; for (size_t t = 1; t < maxt; t++) { size_t beg = t * n / maxt - 1; size_t end = std::min(n, (t + 1) * n / maxt) - 1; tg2.run([&, t, beg, end] { float local_res = tmp_res[t]; for (size_t i = beg; i < end; i++) { local_res += std::sin(i); a[i] = local_res; } }); } tg2.wait(); std::cout << a[n / 2] << std::endl; std::cout << res << std::endl; return 0; }结论:并行扫描的时间复杂度为 O(n/c+c),工作复杂度为 O(n+c),其中 n 是元素个数
-
改进的并行扫描(GPU)

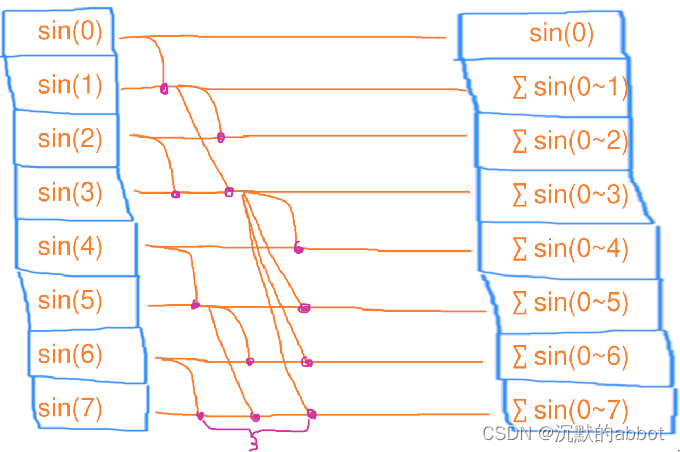
核心思想:在上一个例子中串行加的部分也去递归的并行加。
第一步、4个线程,每个处理2个元素的扫描,花了1秒
第二步、4个线程,每个处理2个元素的扫描,花了1秒
第三步、4个线程,每个处理2个元素的扫描,花了1秒
用电量:3*4=12度电
总用时:1*3=3秒
结论:改进后的并行扫描的时间复杂度为 O(logn),工作复杂度为 O(nlogn)。
可见,并行后虽然降低了时间复杂度,但是以提升工作复杂度为代价!
更多细节,敬请期待GPU专题,我们会以CUDA为例详细探讨两全方案。
-
封装好了:
parallel_scanValue parallel_scan(const Range &range,const Value &identity,const Scan &scan, const ReverseJoin &reverse_join)#include <iostream> #include <tbb/parallel_scan.h> #include <tbb/blocked_range.h> #include <vector> #include <cmath> int main() { size_t n = 1<<26; std::vector<float> a(n); float res = tbb::parallel_scan(tbb::blocked_range<size_t>(0, n), (float)0, [&] (tbb::blocked_range<size_t> r, float local_res, auto is_final) { for (size_t i = r.begin(); i < r.end(); i++) { local_res += std::sin(i); if (is_final) { a[i] = local_res; } } return local_res; }, [] (float x, float y) { return x + y; }); std::cout << a[n / 2] << std::endl; std::cout << res << std::endl; return 0; }
性能测试
-
测试所花费时间:tbb::tick_count::now()
//ticktock.h #pragma once //#include <chrono> //#define TICK(x) auto bench_##x = std::chrono::steady_clock::now(); //#define TOCK(x) std::cout << #x ": " << std::chrono::duration_cast<std::chrono::duration<double>>(std::chrono::steady_clock::now() - bench_##x).count() << "s" << std::endl; #include <tbb/tick_count.h> #define TICK(x) auto bench_##x = tbb::tick_count::now(); #define TOCK(x) std::cout << #x ": " << (tbb::tick_count::now() - bench_##x).seconds() << "s" << std::endl; -
并行和串行的速度比较
串行:
#include <iostream> #include <vector> #include <cmath> #include "ticktock.h" int main() { size_t n = 1<<27; std::vector<float> a(n); TICK(for); // fill a with sin(i) for (size_t i = 0; i < a.size(); i++) { a[i] = std::sin(i); } TOCK(for); TICK(reduce); // calculate sum of a float res = 0; for (size_t i = 0; i < a.size(); i++) { res += a[i]; } TOCK(reduce); std::cout << res << std::endl; return 0; }for: 2.60738s reduce: 0.167612s 0.705693并行:
#include <iostream> #include <tbb/blocked_range.h> #include <tbb/parallel_reduce.h> #include <tbb/parallel_for.h> #include <vector> #include <cmath> #include "ticktock.h" int main() { size_t n = 1<<27; std::vector<float> a(n); TICK(for); // fill a with sin(i) tbb::parallel_for(tbb::blocked_range<size_t>(0, n), [&] (tbb::blocked_range<size_t> r) { for (size_t i = r.begin(); i < r.end(); i++) { a[i] = std::sin(i); } }); TOCK(for); TICK(reduce); // calculate sum of a float res = tbb::parallel_reduce(tbb::blocked_range<size_t>(0, n), (float)0, [&] (tbb::blocked_range<size_t> r, float local_res) { for (size_t i = r.begin(); i < r.end(); i++) { local_res += a[i]; } return local_res; }, [] (float x, float y) { return x + y; }); TOCK(reduce); //这里打印是假装res被使用了,让编译器不要把这个优化掉。 std::cout << res << std::endl; return 0; }for: 0.435992s reduce: 0.0161827s 0.705874 -
评价
- 公式:加速比=串行用时÷并行用时
- 理想加速比应该是核心的数量。
- for 部分加速比为 5.98 倍。
- reduce 部分加速比为 10.36 倍。
- 电脑是 6 个物理核心,12 个逻辑核心。
- 似乎这里 reduce 的加速比是逻辑核心数量,而 for 的加速比是物理核心的数量?
- 剧透:因为本例中 reduce 是内存密集型,for 是计算密集型。
- 超线程对 reduce 这种只用了简单的加法,瓶颈在内存的算法起了作用。
- 而本例中 for 部分用了 std::sin,需要做大量数学运算,因此瓶颈在 ALU。
-
更专业的性能测试框架:
Google benchmark- 手动计算时间差有点太硬核了,而且只运行一次的结果可能不准确,最好是多次运行取平均值才行。
- 因此可以利用谷歌提供的benchmark这个框架。
只需将你要测试的代码放在他的for (auto _: bm)里面即可。他会自动决定要重复多少次,保证结果是准确的,同时不浪费太多时间。
#include <iostream> #include <vector> #include <cmath> #include <benchmark/benchmark.h> constexpr size_t n = 1<<27; std::vector<float> a(n); void BM_for(benchmark::State &bm) { for (auto _: bm) { // fill a with sin(i) for (size_t i = 0; i < a.size(); i++) { a[i] = std::sin(i); } } } BENCHMARK(BM_for); void BM_reduce(benchmark::State &bm) { for (auto _: bm) { // calculate sum of a float res = 0; for (size_t i = 0; i < a.size(); i++) { res += a[i]; } //这里是假装res被使用了,不要把这个优化掉。 benchmark::DoNotOptimize(res); } } BENCHMARK(BM_reduce); BENCHMARK_MAIN();BENCHMARK_MAIN 自动生成了一个 main 函数,从而生成一个可执行文件供你运行。运行后会得到测试的结果打印在终端上。
他还接受一些命令行参数来控制测试的输出格式为 csv 等等,你可以调用 --help 查看更多用法。
-
CMake 中使用benchmark:find_package
cmake_minimum_required(VERSION 3.10) set(CMAKE_CXX_STANDARD 17) set(CMAKE_BUILD_TYPE Release) project(main LANGUAGES CXX) add_executable(main main.cpp) #find_package(OpenMP REQUIRED) #target_link_libraries(main PUBLIC OpenMP::OpenMP_CXX) find_package(TBB REQUIRED) target_link_libraries(main PUBLIC TBB::tbb) find_package(benchmark REQUIRED) target_link_libraries(main PUBLIC benchmark::benchmark) -
CMake 中使用benchmark:作为子模块
cmake_minimum_required(VERSION 3.10) set(CMAKE_CXX_STANDARD 17) set(CMAKE_BUILD_TYPE Release) project(main LANGUAGES CXX) add_executable(main main.cpp) #find_package(OpenMP REQUIRED) #target_link_libraries(main PUBLIC OpenMP::OpenMP_CXX) find_package(TBB REQUIRED) target_link_libraries(main PUBLIC TBB::tbb) set(BENCHMARK_ENABLE_TESTING OFF CACHE BOOL "Turn off the fking test!") add_subdirectory(benchmark) target_link_libraries(main PUBLIC benchmark)
任务域与嵌套
-
任务域:
tbb::task_arena#include <iostream> #include <tbb/parallel_for.h> #include <tbb/task_arena.h> #include <vector> #include <cmath> int main() { size_t n = 1<<26; std::vector<float> a(n); tbb::task_arena ta; ta.execute([&] { tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t i) { a[i] = std::sin(i); }); }); return 0; } -
任务域:指定使用4个线程
#include <iostream> #include <tbb/parallel_for.h> #include <tbb/task_arena.h> #include <vector> #include <cmath> int main() { size_t n = 1<<26; std::vector<float> a(n); tbb::task_arena ta(4); ta.execute([&] { tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t i) { a[i] = std::sin(i); }); }); return 0; } -
嵌套 for 循环
#include <iostream> #include <tbb/parallel_for.h> #include <vector> #include <cmath> int main() { size_t n = 1<<13; std::vector<float> a(n * n); tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t i) { tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t j) { a[i * n + j] = std::sin(i) * std::sin(j); }); }); return 0; } -
嵌套 for 循环:死锁问题
#include <iostream> #include <tbb/parallel_for.h> #include <vector> #include <cmath> #include <mutex> int main() { size_t n = 1<<13; std::vector<float> a(n * n); std::mutex mtx; tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t i) { std::lock_guard lck(mtx); tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t j) { a[i * n + j] = std::sin(i) * std::sin(j); }); }); return 0; } -
死锁问题的原因
因为 TBB 用了工作窃取法来分配任务:当一个线程 t1 做完自己队列里全部的工作时,会从另一个工作中线程 t2 的队列里取出任务,以免 t1 闲置浪费时间。
因此内部 for 循环有可能“窃取”到另一个外部 for 循环的任务,从而导致 mutex 被重复上锁。
-
解决1:用标准库的递归锁
std::recursive_mutex#include <iostream> #include <tbb/parallel_for.h> #include <vector> #include <cmath> #include <mutex> int main() { size_t n = 1<<13; std::vector<float> a(n * n); std::recursive_mutex mtx; tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t i) { std::lock_guard lck(mtx); tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t j) { a[i * n + j] = std::sin(i) * std::sin(j); }); }); return 0; } -
解决2:创建另一个任务域,这样不同域之间就不会窃取工作
#include <iostream> #include <tbb/parallel_for.h> #include <tbb/task_arena.h> #include <vector> #include <cmath> #include <mutex> int main() { size_t n = 1<<13; std::vector<float> a(n * n); std::mutex mtx; tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t i) { std::lock_guard lck(mtx); tbb::task_arena ta; ta.execute([&] { tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t j) { a[i * n + j] = std::sin(i) * std::sin(j); }); }); }); return 0; } -
解决3:同一个任务域,但用 isolate 隔离,禁止其内部的工作被窃取(推荐)
#include <iostream> #include <tbb/parallel_for.h> #include <tbb/task_arena.h> #include <vector> #include <cmath> #include <mutex> int main() { size_t n = 1<<13; std::vector<float> a(n * n); std::mutex mtx; tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t i) { std::lock_guard lck(mtx); tbb::this_task_arena::isolate([&] { tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t j) { a[i * n + j] = std::sin(i) * std::sin(j); }); }); }); return 0; }
任务分配
-
并行:如何均匀分配任务到每个线程?
-
对于并行计算,通常都是 CPU 有几个核心就开几个线程,因为我们只要同时执行就行了嘛。
-
比如 cornell box 这个例子里,我们把图片均匀等分为四块处理。然而发现4号线程所在的块,由于在犄角旮旯里光线反弹的次数多,算得比其他块的慢,而有的块却算得快。但是因为木桶原理,最后花的时间由最慢的那个线程决定,因此变成1分30秒了,多出来的30秒里1号和2号核心在闲置着,因为任务简单已经算完了,只有4号核心一个人在处理额外的光线。

-
-
解决1:线程数量超过CPU核心数量,让系统调度保证各个核心始终饱和
因此,最好不是按照图像大小均匀等分,而是按照工作量大小均匀等分。然而工作量大小我们没办法提前知道……怎么办?
最简单的办法:只需要让线程数量超过CPU核心数量,这时操作系统会自动启用时间片轮换调度,轮流执行每个线程。
比如这里分配了16个线程,但是只有4个处理器核心。那么就会先执行1,2,3,4号线程,一段时间后自动切换到5,6,7,8线程。当一个线程退出时候,系统就不会再调度到他上去了,从而保证每个核心始终有事可做。
-
解决2:线程数量不变,但是用一个队列分发和认领任务
但是线程数量太多会造成调度的 overhead。
所以另一种解法是:我们仍是分配4个线程,但还是把图像切分为16份,作为一个“任务”推送到全局队列里去。每个线程空闲时会不断地从那个队列里取出数据,即“认领任务”。然后执行,执行完毕后才去认领下一个任务,从而即使每个任务工作量不一也能自动适应。
这种技术又称为线程池(thread pool),避免了线程需要保存上下文的开销。但是需要我们管理一个任务队列,而且要是线程安全的队列。
-
解决3:每个线程一个任务队列,做完本职工作后可以认领其他线程的任务
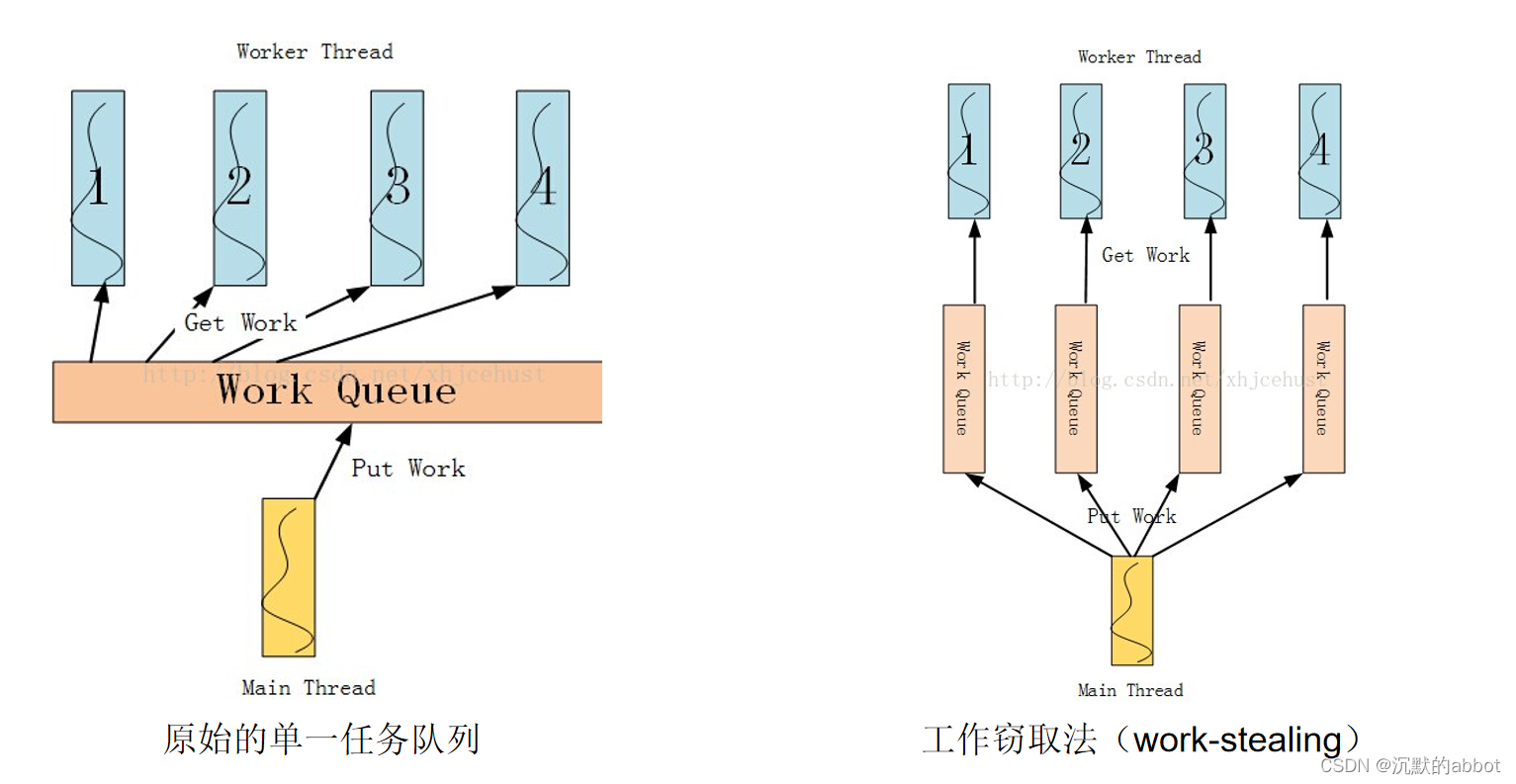
-
解决4:随机分配法(通过哈希函数或线性函数)
然而队列的实现较复杂且需要同步机制,还是有一定的 overhead,因此另一种神奇的解法是:
我们仍是分配4个线程,但还是把图像切分为16份。然后规定每一份按照 xy 轴坐标位置编号,比如 (1,3) 等。
把 (x,y) 那一份,分配给 (x + y * 3) % 4 号线程。这样总体来看每个线程分到的块的位置是随机的,从而由于正太分布数量越大方差越小的特点,每个线程分到的总工作量大概率是均匀的。
GPU 上称为网格跨步循环(grid-stride loop)。
-
tbb::static_partitioner,平均把任务分配给线程#include <iostream> #include <tbb/parallel_for.h> #include <vector> #include <cmath> #include <thread> #include "ticktock.h" #include "mtprint.h" int main() { size_t n = 32; tbb::task_arena ta(4); ta.execute([&] { tbb::parallel_for(tbb::blocked_range<size_t>(0, n), [&] (tbb::blocked_range<size_t> r) { mtprint("thread", tbb::this_task_arena::current_thread_index(), "size", r.size()); std::this_thread::sleep_for(std::chrono::milliseconds(400)); }, tbb::static_partitioner{}); }); return 0; }创建了 4 个线程 4 个任务,每个任务包含 8 个元素:
thread 0 size 8 thread 1 size 8 thread 2 size 8 thread 3 size 8tbb::static_partitioner用于循环体内任务耗时不均匀的情况效果不好,会有木桶效应。 -
指定区间的粒度后的任务分配:
tbb::static_partitioner#include <iostream> #include <tbb/parallel_for.h> #include <vector> #include <cmath> #include <thread> #include "ticktock.h" #include "mtprint.h" int main() { size_t n = 32; tbb::task_arena ta(4); ta.execute([&] { tbb::parallel_for(tbb::blocked_range<size_t>(0, n, 16), [&] (tbb::blocked_range<size_t> r) { mtprint("thread", tbb::this_task_arena::current_thread_index(), "size", r.size()); std::this_thread::sleep_for(std::chrono::milliseconds(400)); }, tbb::static_partitioner{}); }); return 0; }创建了 2 个线程 2 个任务,每个任务包含 16 个元素:
thread 0 size 16 thread 1 size 16 -
tbb::simple_partitioner#include <iostream> #include <tbb/parallel_for.h> #include <vector> #include <cmath> #include <thread> #include "ticktock.h" #include "mtprint.h" int main() { size_t n = 32; TICK(for); tbb::task_arena ta(4); ta.execute([&] { tbb::parallel_for(tbb::blocked_range<size_t>(0, n), [&] (tbb::blocked_range<size_t> r) { for (size_t i = r.begin(); i < r.end(); i++) { mtprint("thread", tbb::this_task_arena::current_thread_index(), "size", r.size(), "begin", r.begin()); std::this_thread::sleep_for(std::chrono::milliseconds(i * 10)); } }, tbb::simple_partitioner{}); }); TOCK(for); return 0; }创建了 4 个线程 32 个任务,每个任务包含 1 个元素,通过轮换的方式让每个线程去执行任务。
-
指定区间的粒度后的任务分配:
tbb::simple_partitioner#include <iostream> #include <tbb/parallel_for.h> #include <vector> #include <cmath> #include <thread> #include "ticktock.h" #include "mtprint.h" int main() { size_t n = 32; TICK(for); tbb::task_arena ta(4); ta.execute([&] { tbb::parallel_for(tbb::blocked_range<size_t>(0, n, 4), [&] (tbb::blocked_range<size_t> r) { for (size_t i = r.begin(); i < r.end(); i++) { mtprint("thread", tbb::this_task_arena::current_thread_index(), "size", r.size(), "begin", r.begin()); std::this_thread::sleep_for(std::chrono::milliseconds(i * 10)); } }, tbb::simple_partitioner{}); }); TOCK(for); return 0; }创建了 4 个线程 8 个任务,每个任务包含 4 个元素
-
默认的方式:
tbb::auto_partitioner#include <iostream> #include <tbb/parallel_for.h> #include <vector> #include <cmath> #include <thread> #include "ticktock.h" #include "mtprint.h" int main() { size_t n = 32; tbb::task_arena ta(4); ta.execute([&] { tbb::parallel_for(tbb::blocked_range<size_t>(0, n), [&] (tbb::blocked_range<size_t> r) { mtprint("thread", tbb::this_task_arena::current_thread_index(), "size", r.size()); std::this_thread::sleep_for(std::chrono::milliseconds(400)); }, tbb::auto_partitioner{}); }); return 0; }自动根据 lambda 中函数的执行时间判断采用何种分配方法。
-
比较
tbb::static_partitioner用于循环体内任务耗时不均匀的情况效果不好,会有木桶效应。tbb::simple_partitioner用于循环体不均匀的情况效果很好。 -
tbb::affinity_partitioner记录历史,下次根据经验自动负载均衡#include <iostream> #include <tbb/parallel_for.h> #include <vector> #include <cmath> #include <thread> #include "ticktock.h" #include "mtprint.h" int main() { size_t n = 32; tbb::task_arena ta(4); ta.execute([&] { tbb::affinity_partitioner affinity; for (int t = 0; t < 10; t++) { TICK(for); tbb::parallel_for(tbb::blocked_range<size_t>(0, n), [&] (tbb::blocked_range<size_t> r) { for (size_t i = r.begin(); i < r.end(); i++) { for (volatile int j = 0; j < i * 1000; j++); } }, affinity); TOCK(for); } }); return 0; } -
tbb::simple_partitioner粒度为 1 太细了,效果不好,最好手动修改一下粒度#include <iostream> #include <tbb/parallel_for.h> #include <vector> #include <cmath> #include <thread> #include "ticktock.h" #include "mtprint.h" int main() { size_t n = 1<<26; std::vector<float> a(n); TICK(for); tbb::task_arena ta(4); ta.execute([&] { auto numprocs = tbb::this_task_arena::max_concurrency(); // 4 tbb::parallel_for(tbb::blocked_range<size_t>(0, n, n / (2 * numprocs)), [&] (tbb::blocked_range<size_t> r) { for (size_t i = r.begin(); i < r.end(); i++) { a[i] = std::sin(i); } }, tbb::simple_partitioner{}); }); TOCK(for); return 0; }此时使用默认的
tbb::auto_partitioner自动判断合适的粒度,效果也不错 -
一个
simple_partitioner比auto_partitioner好的例子:矩阵转置// simple_partitioner #include <iostream> #include <tbb/parallel_for.h> #include <tbb/blocked_range2d.h> #include <vector> #include <cmath> #include <thread> #include "ticktock.h" #include "mtprint.h" int main() { size_t n = 1<<14; std::vector<float> a(n * n); std::vector<float> b(n * n); TICK(transpose); size_t grain = 16; tbb::parallel_for(tbb::blocked_range2d<size_t>(0, n, grain, 0, n, grain), [&] (tbb::blocked_range2d<size_t> r) { for (size_t i = r.cols().begin(); i < r.cols().end(); i++) { for (size_t j = r.rows().begin(); j < r.rows().end(); j++) { b[i * n + j] = a[j * n + i]; } } }, tbb::simple_partitioner{}); TOCK(transpose); return 0; }transpose: 0.698496
// auto_partitioner #include <iostream> #include <tbb/parallel_for.h> #include <tbb/blocked_range2d.h> #include <vector> #include <cmath> #include <thread> #include "ticktock.h" #include "mtprint.h" int main() { size_t n = 1<<14; std::vector<float> a(n * n); std::vector<float> b(n * n); TICK(transpose); tbb::parallel_for(tbb::blocked_range2d<size_t>(0, n, 0, n), [&] (tbb::blocked_range2d<size_t> r) { for (size_t i = r.cols().begin(); i < r.cols().end(); i++) { for (size_t j = r.rows().begin(); j < r.rows().end(); j++) { b[i * n + j] = a[j * n + i]; } } }); TOCK(transpose); return 0; }transpose: 0.211069s
原因:
tbb::simple_partitioner能够按照给定的粒度大小(grain)将矩阵进行分块。块内部小区域按照常规的两层循环访问以便矢量化,块外部大区域则以类似 Z 字型的曲线遍历,这样能保证每次访问的数据在地址上比较靠近,并且都是最近访问过的,从而已经在缓存里可以直接读写,避免了从主内存读写的超高延迟。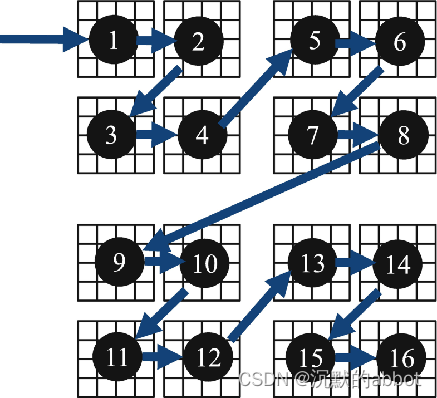
并发容器
-
std::vector扩容时会移动元素#include <iostream> #include <vector> #include <cmath> int main() { size_t n = 1<<10; std::vector<float> a; std::vector<float *> pa(n); for (size_t i = 0; i < n; i++) { a.push_back(std::sin(i)); pa[i] = &a.back(); } for (size_t i = 0; i < n; i++) { std::cout << (&a[i] == pa[i]) << ' '; } std::cout << std::endl; return 0; }会导致指针和迭代器失效;
reserve 预留足够的 capacity,一定程度上避免该问题。
-
不连续的
tbb::concurrent_vectorstd::vector造成指针失效的根本原因在于他必须保证内存是连续的,从而不得不在扩容时移动元素。因此可以用
tbb::concurrent_vector,他不保证元素在内存中是连续的。换来的优点是 push_back 进去的元素,扩容时不需要移动位置,从而指针和迭代器不会失效。同时他的 push_back 会额外返回一个迭代器(iterator),指向刚刚插入的对象。
#include <iostream> #include <vector> #include <tbb/concurrent_vector.h> #include <cmath> int main() { size_t n = 1<<10; tbb::concurrent_vector<float> a; std::vector<float *> pa(n); for (size_t i = 0; i < n; i++) { auto it = a.push_back(std::sin(i)); pa[i] = &*it; } for (size_t i = 0; i < n; i++) { std::cout << (&a[i] == pa[i]) << ' '; } std::cout << std::endl; return 0; } -
tbb::concurrent_vector::grow_by一次性扩容一定大小push_back 一次只能推入一个元素。
而 grow_by(n) 则可以一次扩充 n 个元素。他同样是返回一个迭代器(iterator),之后可以通过迭代器的 ++ 运算符依次访问连续的 n 个元素,* 运算符访问当前指向的元素。
#include <iostream> #include <tbb/concurrent_vector.h> #include <cmath> int main() { size_t n = 1<<10; tbb::concurrent_vector<float> a; for (size_t i = 0; i < n; i++) { auto it = a.grow_by(2); *it++ = std::cos(i); *it++ = std::sin(i); } std::cout << a.size() << std::endl; return 0; } -
可安全地被多线程并发访问
除了内存不连续、指针和迭代器不失效的特点,tbb::concurrent_vector 还是一个多线程安全的容器,能够被多个线程同时并发地 grow_by 或 push_back 而不出错。
而 std::vector 只有只读的 .size() 和 [] 运算符是安全的,且不能和写入的 push_back 等一起用,否则需要用读写锁保护。
#include <iostream> #include <tbb/concurrent_vector.h> #include <tbb/parallel_for.h> #include <cmath> int main() { size_t n = 1<<10; tbb::concurrent_vector<float> a; tbb::parallel_for((size_t)0, (size_t)n, [&] (size_t i) { auto it = a.grow_by(2); *it++ = std::cos(i); *it++ = std::sin(i); }); std::cout << a.size() << std::endl; return 0; } -
不建议通过索引随机访问
因为 tbb::concurrent_vector 内存不连续的特点,通过索引访问,比通过迭代器访问的效率低一些。
因此不推荐像 a[i] 这样通过索引随机访问其中的元素,*(it + i) 这样需要迭代器跨步访问的也不推荐。
-
推荐通过迭代器顺序访问
最好的方式是用 begin() 和 end() 的迭代器区间,按顺序访问。
#include <iostream> #include <tbb/concurrent_vector.h> #include <tbb/parallel_for.h> #include <cmath> int main() { size_t n = 1<<10; tbb::concurrent_vector<float> a(n); for (auto it = a.begin(); it != a.end(); ++it) { *it += 1.0f; } std::cout << a[1] << std::endl; return 0; } -
parallel_for也支持迭代器冷知识:
tbb::blocked_range的参数不一定是 size_t,也可以是迭代器表示的区间。这样 lambda 体内 r 的 begin 和 end 也会返回
tbb::concurrent_vector的迭代器类型。第一个
tbb::blocked_range尖括号里的类型可以省略是因为 C++17 的 CTAD 特性。第二个则是用了 decltype 自动推导,也可以 (auto r),这里写具体类型仅为教学目的。#include <iostream> #include <tbb/concurrent_vector.h> #include <tbb/parallel_for.h> #include <cmath> int main() { size_t n = 1<<10; tbb::concurrent_vector<float> a(n); tbb::parallel_for(tbb::blocked_range(a.begin(), a.end()), [&] (tbb::blocked_range<decltype(a.begin())> r) { for (auto it = r.begin(); it != r.end(); ++it) { *it += 1.0f; } }); std::cout << a[1] << std::endl; return 0; } -
TBB里面的其他并发容器
concurrent_lru_cache concurrent_unordered_map concurrent_unordered_set concurrent_map concurrent_set concurrent_queue concurrent_vector concurrent_hash_map concurrent_priority_queue
并行筛选
-
筛选(filter)
利用 vector 的 push_back 动态追加数据,筛选出所有大于 0 的 sin(i) 值。
#include <iostream> #include <vector> #include <cmath> #include "ticktock.h" int main() { size_t n = 1<<27; std::vector<float> a; TICK(filter); for (size_t i = 0; i < n; i++) { float val = std::sin(i); if (val > 0) { a.push_back(val); } } TOCK(filter); return 0; } -
并行筛选1
利用多线程安全的
concurrent_vector动态追加数据;
基本没有加速,猜想concurrent_vector内部可能用了简单粗暴的互斥量,只保证了安全,并不保证高效加速比:1.32 倍#include <iostream> #include <tbb/parallel_for.h> #include <tbb/concurrent_vector.h> #include <cmath> #include "ticktock.h" int main() { size_t n = 1<<27; tbb::concurrent_vector<float> a; TICK(filter); tbb::parallel_for(tbb::blocked_range<size_t>(0, n), [&] (tbb::blocked_range<size_t> r) { for (size_t i = r.begin(); i < r.end(); i++) { float val = std::sin(i); if (val > 0) { a.push_back(val); } } }); TOCK(filter); return 0; } -
并行筛选2
推到线程局部(thread-local)的 vector,最后一次性推入到 concurrent_vector;
可以避免频繁在 concurrent_vector 上产生锁竞争
加速比:5.55 倍
#include <iostream> #include <tbb/parallel_for.h> #include <tbb/concurrent_vector.h> #include <cmath> #include "ticktock.h" int main() { size_t n = 1<<27; tbb::concurrent_vector<float> a; TICK(filter); tbb::parallel_for(tbb::blocked_range<size_t>(0, n), [&] (tbb::blocked_range<size_t> r) { std::vector<float> local_a; for (size_t i = r.begin(); i < r.end(); i++) { float val = std::sin(i); if (val > 0) { local_a.push_back(val); } } auto it = a.grow_by(local_a.size()); for (size_t i = 0; i < local_a.size(); i++) { *it++ = local_a[i]; } }); TOCK(filter); return 0; } -
并行筛选3
线程局部的 vector 调用 reserve 预先分配一定内存,避免 push_back 反复扩容时的分段式增长;
同时利用标准库的 std::copy 模板简化了代码;
加速比:5.94 倍
#include <iostream> #include <tbb/parallel_for.h> #include <tbb/concurrent_vector.h> #include <cmath> #include "ticktock.h" int main() { size_t n = 1<<27; tbb::concurrent_vector<float> a; TICK(filter); tbb::parallel_for(tbb::blocked_range<size_t>(0, n), [&] (tbb::blocked_range<size_t> r) { std::vector<float> local_a; local_a.reserve(r.size()); for (size_t i = r.begin(); i < r.end(); i++) { float val = std::sin(i); if (val > 0) { local_a.push_back(val); } } auto it = a.grow_by(local_a.size()); std::copy(local_a.begin(), local_a.end(), it); }); TOCK(filter); return 0; } -
并行筛选4
如果需要筛选后的数据是连续的,即 a 是个 std::vector,这时就需要用 mutex 锁定,避免数据竞争。
加速比:4.92 倍
#include <iostream> #include <tbb/parallel_for.h> #include <vector> #include <cmath> #include <mutex> #include "ticktock.h" int main() { size_t n = 1<<27; std::vector<float> a; std::mutex mtx; TICK(filter); tbb::parallel_for(tbb::blocked_range<size_t>(0, n), [&] (tbb::blocked_range<size_t> r) { std::vector<float> local_a; local_a.reserve(r.size()); for (size_t i = r.begin(); i < r.end(); i++) { float val = std::sin(i); if (val > 0) { local_a.push_back(val); } } std::lock_guard lck(mtx); std::copy(local_a.begin(), local_a.end(), std::back_inserter(a)); }); TOCK(filter); return 0; } -
并行筛选5
先对 a 预留一定的内存,避免频繁扩容影响性能。
加速比:5.98 倍
#include <iostream> #include <tbb/parallel_for.h> #include <vector> #include <cmath> #include <mutex> #include "ticktock.h" int main() { size_t n = 1<<27; std::vector<float> a; std::mutex mtx; TICK(filter); a.reserve(n * 2 / 3); tbb::parallel_for(tbb::blocked_range<size_t>(0, n), [&] (tbb::blocked_range<size_t> r) { std::vector<float> local_a; local_a.reserve(r.size()); for (size_t i = r.begin(); i < r.end(); i++) { float val = std::sin(i); if (val > 0) { local_a.push_back(val); } } std::lock_guard lck(mtx); std::copy(local_a.begin(), local_a.end(), std::back_inserter(a)); }); TOCK(filter); return 0; } -
并行筛选6
使用
tbb::spin_mutex替代std::mutex。spin_mutex(基于硬件原子指令)会让 CPU 陷入循环等待,而不像 mutex(操作系统提供调度)会让线程进入休眠状态的等待。若上锁的区域较小,可以用轻量级的
spin_mutex。若上锁的区域很大,则循环等待只会浪费 CPU 时间。这里锁的区域是std::copy,比较大,所以spin_mutex效果不如 mutex 好。加速比:5.92 倍
#include <iostream> #include <tbb/parallel_for.h> #include <tbb/spin_mutex.h> #include <vector> #include <cmath> #include <mutex> #include "ticktock.h" int main() { size_t n = 1<<27; std::vector<float> a; tbb::spin_mutex mtx; TICK(filter); a.reserve(n * 2 / 3); tbb::parallel_for(tbb::blocked_range<size_t>(0, n), [&] (tbb::blocked_range<size_t> r) { std::vector<float> local_a; local_a.reserve(r.size()); for (size_t i = r.begin(); i < r.end(); i++) { float val = std::sin(i); if (val > 0) { local_a.push_back(val); } } std::lock_guard lck(mtx); std::copy(local_a.begin(), local_a.end(), std::back_inserter(a)); }); TOCK(filter); return 0; }还有
tbb::spin_rw_mutex对标std::shared_mutex。 -
并行筛选7
彻底避免了互斥量,完全通过预先准备好的大小,配合 atomic 递增索引批量写入。同时用 pod 模板类,使得 vector 的 resize 不会零初始化其中的值。
加速比:6.26 倍
//pod.h #pragma once #include <new> #include <utility> template <class T> struct pod { private: T m_t; public: pod() {} pod(pod &&p) : m_t(std::move(p.m_t)) {} pod(pod const &p) : m_t(p.m_t) {} pod &operator=(pod &&p) { m_t = std::move(p.m_t); return *this; } pod &operator=(pod const &p) { m_t = p.m_t; return *this; } pod(T &&t) : m_t(std::move(t)) {} pod(T const &t) : m_t(t) {} pod &operator=(T &&t) { m_t = std::move(t); return *this; } pod &operator=(T const &t) { m_t = t; return *this; } operator T const &() const { return m_t; } operator T &() { return m_t; } T const &get() const { return m_t; } T &get() { return m_t; } template <class ...Ts> pod &emplace(Ts &&...ts) { ::new (&m_t) T(std::forward<Ts>(ts)...); return *this; } void destroy() { m_t.~T(); } };#include <iostream> #include <tbb/parallel_for.h> #include <vector> #include <cmath> #include <atomic> #include "ticktock.h" #include "pod.h" int main() { size_t n = 1<<27; std::vector<pod<float>> a; std::atomic<size_t> a_size = 0; TICK(filter); a.resize(n); tbb::parallel_for(tbb::blocked_range<size_t>(0, n), [&] (tbb::blocked_range<size_t> r) { std::vector<pod<float>> local_a(r.size()); size_t lasize = 0; for (size_t i = r.begin(); i < r.end(); i++) { float val = std::sin(i); if (val > 0) { local_a[lasize++] = val; } } size_t base = a_size.fetch_add(lasize); for (size_t i = 0; i < lasize; i++) { a[base + i] = local_a[i]; } }); a.resize(a_size); TOCK(filter); return 0; } -
并行筛选8(不推荐)
用 std::vector 作为 parallel_reduce 的元素类型,通过合并得出最终结果,也是可以的。很直观,可惜加速效果不好。
加速比:2.04 倍
#include <iostream> #include <tbb/parallel_reduce.h> #include <tbb/blocked_range.h> #include <cmath> #include "ticktock.h" int main() { size_t n = 1<<27; TICK(filter); tbb::parallel_reduce(tbb::blocked_range<size_t>(0, n), std::vector<float>{}, [&] (tbb::blocked_range<size_t> r, std::vector<float> local_a) { local_a.reserve(local_a.size() + r.size()); for (size_t i = r.begin(); i < r.end(); i++) { float val = std::sin(i); if (val > 0) { local_a.push_back(val); } } return local_a; }, [] (std::vector<float> a, std::vector<float> const &b) { std::copy(b.begin(), b.end(), std::back_inserter(a)); return a; }); TOCK(filter); return 0; } -
并行筛选9(用于GPU)
线程粒度很细,核心数量很多的 GPU,往往没办法用 concurrent_vector 和 thread-local vector。或是你需要保证筛选前后顺序不变。这时要把筛选分为三步:
一、算出每个元素需要往 vector 推送数据的数量(本例中只有 0 和 1 两种可能)
二、对刚刚算出的数据进行并行扫描(scan),得出每个 i 要写入的索引。
三、再次对每个元素并行 for 循环,根据刚刚生成写入的索引,依次写入数据。
加速比:4.50 倍(考虑到这里 ind 只有 0 和 1,应该大有优化空间)
#include <iostream> #include <tbb/parallel_for.h> #include <tbb/parallel_scan.h> #include <cmath> #include "ticktock.h" #include "pod.h" int main() { size_t n = 1<<27; TICK(filter); TICK(init); std::vector<pod<float>> a(n); tbb::parallel_for(tbb::blocked_range<size_t>(0, n), [&] (tbb::blocked_range<size_t> r) { for (size_t i = r.begin(); i < r.end(); i++) { a[i] = std::sin(i); } }); TOCK(init); TICK(scan); std::vector<pod<size_t>> ind(n + 1); ind[0] = 0; tbb::parallel_scan(tbb::blocked_range<size_t>(0, n), (size_t)0, [&] (tbb::blocked_range<size_t> r, size_t sum, auto is_final) { for (auto i = r.begin(); i < r.end(); i++) { sum += a[i] > 0 ? 1 : 0; if (is_final) ind[i + 1] = sum; } return sum; }, [] (size_t x, size_t y) { return x + y; }); TOCK(scan); TICK(fill); std::vector<pod<float>> b(ind.back()); tbb::parallel_for(tbb::blocked_range<size_t>(0, n), [&] (tbb::blocked_range<size_t> r) { for (size_t i = r.begin(); i < r.end(); i++) { if (a[i] > 0) b[ind[i]] = a[i]; } }); TOCK(fill); TOCK(filter); return 0; }
分治和排序
-
斐波那契数列的递归写法
#include <iostream> #include <cstdlib> #include <cmath> #include "ticktock.h" int fib(int n) { if (n < 2) return n; int first = fib(n - 1); int second = fib(n - 2); return first + second; } int main() { TICK(fib); std::cout << fib(39) << std::endl; TOCK(fib); return 0; }fib:0.454915s
-
并行写法
#include <iostream> #include <cstdlib> #include <cmath> #include "ticktock.h" #include <tbb/parallel_invoke.h> int fib(int n) { if (n < 2) return n; int first, second; tbb::parallel_invoke([&] { first = fib(n - 1); }, [&] { second = fib(n - 2); }); return first + second; } int main() { TICK(fib); std::cout << fib(39) << std::endl; TOCK(fib); return 0; }fib: 2.64342s
反而变慢了。
-
任务划分得够细时,转为串行,缓解tbb调度大量任务所造成的负担(scheduling overhead)
#include <iostream> #include <cstdlib> #include <cmath> #include "ticktock.h" #include <tbb/parallel_invoke.h> int serial_fib(int n) { if (n < 2) return n; int first = serial_fib(n - 1); int second = serial_fib(n - 2); return first + second; } int fib(int n) { if (n < 29) return serial_fib(n); int first, second; tbb::parallel_invoke([&] { first = fib(n - 1); }, [&] { second = fib(n - 2); }); return first + second; } int main() { TICK(fib); std::cout << fib(39) << std::endl; TOCK(fib); return 0; }fib: 0.026544s
-
标准库提供的排序
#include <iostream> #include <cstdlib> #include <vector> #include <cmath> #include <algorithm> #include "ticktock.h" int main() { size_t n = 1<<24; std::vector<int> arr(n); //生成随机数 std::generate(arr.begin(), arr.end(), std::rand); TICK(std_sort); std::sort(arr.begin(), arr.end(), std::less<int>{}); TOCK(std_sort); return 0; } -
快速排序
#include <iostream> #include <cstdlib> #include <vector> #include <cmath> #include <algorithm> #include "ticktock.h" template <class T> void quick_sort(T *data, size_t size) { if (size < 1) return; size_t mid = std::hash<size_t>{}(size); mid ^= std::hash<void *>{}(static_cast<void *>(data)); mid %= size; std::swap(data[0], data[mid]); T pivot = data[0]; size_t left = 0, right = size - 1; while (left < right) { while (left < right && !(data[right] < pivot)) right--; if (left < right) data[left++] = data[right]; while (left < right && data[left] < pivot) left++; if (left < right) data[right--] = data[left]; } data[left] = pivot; quick_sort(data, left); quick_sort(data + left + 1, size - left - 1); } int main() { size_t n = 1<<24; std::vector<int> arr(n); std::generate(arr.begin(), arr.end(), std::rand); TICK(quick_sort); quick_sort(arr.data(), arr.size()); TOCK(quick_sort); return 0; } -
并行的快速排序
#include <iostream> #include <cstdlib> #include <vector> #include <cmath> #include <algorithm> #include <tbb/parallel_invoke.h> #include "ticktock.h" template <class T> void quick_sort(T *data, size_t size) { if (size < 1) return; size_t mid = std::hash<size_t>{}(size); mid ^= std::hash<void *>{}(static_cast<void *>(data)); mid %= size; std::swap(data[0], data[mid]); T pivot = data[0]; size_t left = 0, right = size - 1; while (left < right) { while (left < right && !(data[right] < pivot)) right--; if (left < right) data[left++] = data[right]; while (left < right && data[left] < pivot) left++; if (left < right) data[right--] = data[left]; } data[left] = pivot; tbb::parallel_invoke([&] { quick_sort(data, left); }, [&] { quick_sort(data + left + 1, size - left - 1); }); } int main() { size_t n = 1<<24; std::vector<int> arr(n); std::generate(arr.begin(), arr.end(), std::rand); TICK(parallel_sort); quick_sort(arr.data(), arr.size()); TOCK(parallel_sort); return 0; }比标准库提供的快速排序还好。
-
改进:数据足够小时,开始用标准库串行的排序
#include <iostream> #include <cstdlib> #include <vector> #include <cmath> #include <algorithm> #include <tbb/parallel_invoke.h> #include "ticktock.h" template <class T> void quick_sort(T *data, size_t size) { if (size < 1) return; if (size < (1<<16)) { std::sort(data, data + size, std::less<T>{}); return; } size_t mid = std::hash<size_t>{}(size); mid ^= std::hash<void *>{}(static_cast<void *>(data)); mid %= size; std::swap(data[0], data[mid]); T pivot = data[0]; size_t left = 0, right = size - 1; while (left < right) { while (left < right && !(data[right] < pivot)) right--; if (left < right) data[left++] = data[right]; while (left < right && data[left] < pivot) left++; if (left < right) data[right--] = data[left]; } data[left] = pivot; tbb::parallel_invoke([&] { quick_sort(data, left); }, [&] { quick_sort(data + left + 1, size - left - 1); }); } int main() { size_t n = 1<<24; std::vector<int> arr(n); std::generate(arr.begin(), arr.end(), std::rand); TICK(better_parallel_sort); quick_sort(arr.data(), arr.size()); TOCK(better_parallel_sort); return 0; } -
封装好了:tbb::parallel_sort
(和标准库串行的 std::sort)加速比:4.80 倍
#include <iostream> #include <cstdlib> #include <vector> #include <cmath> #include <algorithm> #include <tbb/parallel_sort.h> #include "ticktock.h" int main() { size_t n = 1<<24; std::vector<int> arr(n); std::generate(arr.begin(), arr.end(), std::rand); TICK(tbb_parallel_sort); tbb::parallel_sort(arr.begin(), arr.end(), std::less<int>{}); TOCK(tbb_parallel_sort); return 0; } -
重新认识改进的并行缩并
之前提到“改进后的并行缩并”,也是一种分治法的思想:大问题一分为二变成小问题,分派到各个CPU核心上,问题足够小时直接串行求解。
他也可以通过 parallel_invoke 分治来实现
#include <iostream> #include <cstdlib> #include <vector> #include <cmath> #include <algorithm> #include <tbb/parallel_invoke.h> #include "ticktock.h" #include <numeric> template <class T> T quick_reduce(T *data, size_t size) { if (size < (1<<16)) { return std::reduce(data, data + size); } T sum1, sum2; size_t mid = size / 2; tbb::parallel_invoke([&] { sum1 = quick_reduce(data, mid); }, [&] { sum2 = quick_reduce(data + mid, size - mid); }); return sum1 + sum2; } int main() { size_t n = 1<<25; std::vector<int> arr(n); std::generate(arr.begin(), arr.end(), std::rand); TICK(quick_reduce); int sum = quick_reduce(arr.data(), arr.size()); TOCK(quick_reduce); printf("%d\n", sum); return 0; }
流水线并行
-
案例,批量处理数据
#include <iostream> #include <cstdlib> #include <vector> #include <cmath> #include "ticktock.h" struct Data { std::vector<float> arr; Data() { arr.resize(std::rand() % 100 * 500 + 10000); for (int i = 0; i < arr.size(); i++) { arr[i] = std::rand() * (1.f / (float)RAND_MAX); } } void step1() { for (int i = 0; i < arr.size(); i++) { arr[i] += 3.14f; } } void step2() { std::vector<float> tmp(arr.size()); for (int i = 1; i < arr.size() - 1; i++) { tmp[i] = arr[i - 1] + arr[i] + arr[i + 1]; } std::swap(tmp, arr); } void step3() { for (int i = 0; i < arr.size(); i++) { arr[i] = std::sqrt(std::abs(arr[i])); } } void step4() { std::vector<float> tmp(arr.size()); for (int i = 1; i < arr.size() - 1; i++) { tmp[i] = arr[i - 1] - 2 * arr[i] + arr[i + 1]; } std::swap(tmp, arr); } }; int main() { size_t n = 1<<12; std::vector<Data> dats(n); TICK(process); for (auto &dat: dats) { dat.step1(); dat.step2(); dat.step3(); dat.step4(); } TOCK(process); return 0; } -
简单粗暴的并行
int main() { size_t n = 1<<11; std::vector<Data> dats(n); TICK(process); tbb::parallel_for_each(dats.begin(), dats.end(), [&] (Data &dat) { dat.step1(); dat.step2(); dat.step3(); dat.step4(); }); TOCK(process); return 0; }加速比:3.16 倍
很不理想,为什么?
很简单,循环体太大,每跑一遍指令缓存和数据缓存都会重新失效一遍。且每个核心都在读写不同地方的数据,不能很好的利用三级缓存,导致内存成为瓶颈。
-
拆分为四个 for,减轻指令缓存的压力
int main() { size_t n = 1<<11; std::vector<Data> dats(n); TICK(process); tbb::parallel_for_each(dats.begin(), dats.end(), [&] (Data &dat) { dat.step1(); }); tbb::parallel_for_each(dats.begin(), dats.end(), [&] (Data &dat) { dat.step2(); }); tbb::parallel_for_each(dats.begin(), dats.end(), [&] (Data &dat) { dat.step3(); }); tbb::parallel_for_each(dats.begin(), dats.end(), [&] (Data &dat) { dat.step4(); }); TOCK(process); return 0; }加速比:3.47 倍
解决了指令缓存失效问题,但是四次独立的for循环每次结束都需要同步,一定程度上妨碍了CPU发挥性能;而且每个step后依然写回了数组,数据缓存没法充分利用。
-
另辟蹊径:流水线并行
int main() { size_t n = 1<<11; std::vector<Data> dats(n); TICK(process); auto it = dats.begin(); tbb::parallel_pipeline(8 , tbb::make_filter<void, Data *>(tbb::filter_mode::serial_in_order, [&] (tbb::flow_control &fc) -> Data * { if (it == dats.end()) { fc.stop(); return nullptr; } return &*it++; }) , tbb::make_filter<Data *, Data *>(tbb::filter_mode::parallel, [&] (Data *dat) -> Data * { dat->step1(); return dat; }) , tbb::make_filter<Data *, Data *>(tbb::filter_mode::parallel, [&] (Data *dat) -> Data * { dat->step2(); return dat; }) , tbb::make_filter<Data *, Data *>(tbb::filter_mode::parallel, [&] (Data *dat) -> Data * { dat->step3(); return dat; }) , tbb::make_filter<Data *, void>(tbb::filter_mode::parallel, [&] (Data *dat) -> void { dat->step4(); }) ); TOCK(process); return 0; }加速比:6.73 倍
反直觉的并行方式,但是加速效果却很理想,为什么?
流水线模式下每个线程都只做自己的那个步骤(filter),从而对指令缓存更友好。且一个核心处理完的数据很快会被另一个核心用上,对三级缓存比较友好,也节省内存。
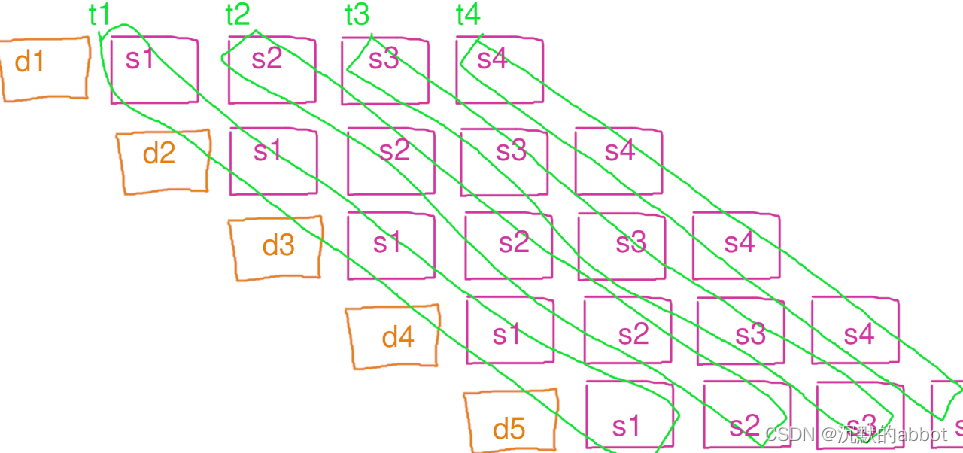
且 TBB 的流水线,其实比教科书上描述的传统流水线并行更加优化:
他在 t1 线程算完 d1 的 s1 时,会继续让 t1 负责算 d1 的 s2,这样 d1 的数据就是在二级缓存里,比调度到让 t2 算需要进入三级缓存更高效。而当 t2 的队列比较空时,又会让 t1 继续算 d2 的 s2,这样可以避免 t2 闲置浪费时间。总之就是会自动负载均衡非常智能,完全无需操心内部细节。
-
流水线并行:filter 参数
int main() { size_t n = 1<<11; std::vector<Data> dats(n); std::vector<float> result; TICK(process); auto it = dats.begin(); tbb::parallel_pipeline(8 , tbb::make_filter<void, Data *>(tbb::filter_mode::serial_in_order, [&] (tbb::flow_control &fc) -> Data * { if (it == dats.end()) { fc.stop(); return nullptr; } return &*it++; }) , tbb::make_filter<Data *, Data *>(tbb::filter_mode::parallel, [&] (Data *dat) -> Data * { dat->step1(); return dat; }) , tbb::make_filter<Data *, Data *>(tbb::filter_mode::parallel, [&] (Data *dat) -> Data * { dat->step2(); return dat; }) , tbb::make_filter<Data *, Data *>(tbb::filter_mode::parallel, [&] (Data *dat) -> Data * { dat->step3(); return dat; }) , tbb::make_filter<Data *, float>(tbb::filter_mode::parallel, [&] (Data *dat) -> float { float sum = std::reduce(dat->arr.begin(), dat->arr.end()); return sum; }) , tbb::make_filter<float, void>(tbb::filter_mode::serial_out_of_order, [&] (float sum) -> void { result.push_back(sum); }) ); TOCK(process); return 0; }- serial_in_order 表示当前步骤只允许串行执行,且执行的顺序必须一致。
- serial_out_of_order 表示只允许串行执行,但是顺序可以打乱。
- parallel 表示可以并行执行当前步骤,且顺序可以打乱。
- 每一个步骤(filter)的输入和返回类型都可以不一样。要求:流水线上一步的返回类型,必须和下一步的输入类型一致。且第一步的没有输入,最后一步没有返回,所以都为 void。
- TBB 支持嵌套的并行,因此流水线内部也可以调用
tbb::parallel_for进一步并行。
-
流水线的利弊

- 流水线式的并行,因为每个线程执行的指令之间往往没有关系,主要适用于各个核心可以独立工作的 CPU,GPU 上则有 stream 作为替代。
- 流水线额外的好处是可以指定一部分 filter 为串行的(如果他们没办法并行调用的话)而其他 filter 可以和他同时并行运行。这可以应对一些不方便并行,或者执行前后的数据有依赖,但是可以拆分成多个步骤(filter)的复杂业务。
- 还有好处是他无需先把数据全读到一个内存数组里,可以流式处理数据(on-fly),节省内存。
- 不过需要注意流水线每个步骤(filter)里的工作量最好足够大,否则无法掩盖调度overhead。
总结
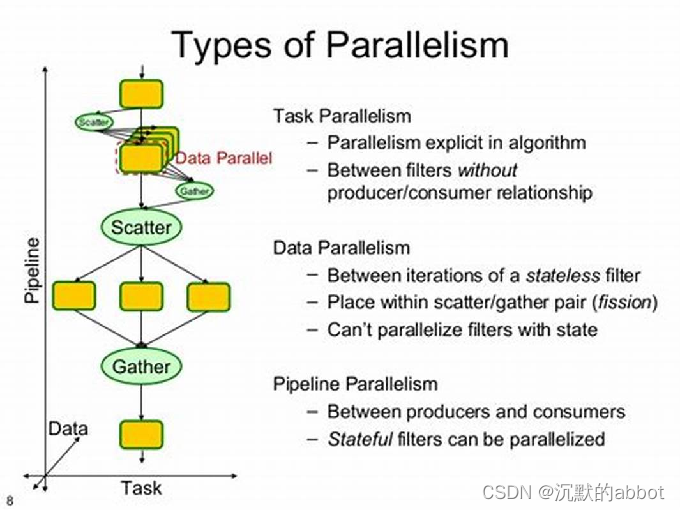
- 从串行到并行,从来就没有什么万能膏药。
- CPU上的并行尚且如此,何况GPU。
- 熟悉原理、反复实验,才能优化出好程序。
- 本文章仅入门,深入可以看 Pro TBB 这本书。
- 优化重点在于程序的瓶颈部分,不用在小细节上浪费精力。如果有个 O(n²) 的循环体,则只看他,并无视一旁的 O(n) 循环体。















 598
598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









