







归并排序(Merge sort,合并排序)是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
一 归并操作
基本思想
归并操作(merge),指的是将两个已经排序的序列合并成一个序列的操作,归并排序算法依赖归并操作。
归并操作的过程如下:
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
- 重复步骤3直到某一指针达到序列尾
- 将另一序列剩下的所有元素直接复制到合并序列尾
归并操作算法实现(c/c++)
void Merge(SeqList R,int low,int m,int high)
{//将两个有序的子文件R[low..m)和R[m+1..high]归并成一个有序的子文件R[low..high]
int i=low,j=m+1,p=0; //置初始值
RecType *R1; //R1是局部向量,若p定义为此类型指针速度更快
R1=(ReeType *)malloc((high-low+1)*sizeof(RecType));
if(! R1) //申请空间失败
Error("Insufficient memory available!");
while(i<=m&&j<=high) //两子文件非空时取其小者输出到R1[p]上
R1[p++]=(R[i].key<=R[j].key)?R[i++]:R[j++];
while(i<=m) //若第1个子文件非空,则复制剩余记录到R1中
R1[p++]=R[i++];
while(j<=high) //若第2个子文件非空,则复制剩余记录到R1中
R1[p++]=R[j++];
for(p=0,i=low;i<=high;p++,i++)
R[i]=R1[p];//归并完成后将结果复制回R[low..high]
} //Merge
二 归并排序
归并排序是基于归并操作的排序算法,有多路归并排序、两路归并排序 , 可用于内排序,也可以用于外排序
两路归并排序
基本思路
设两个有序的子文件(相当于输入堆)放在同一向量中相邻的位置上:R[low..m],R[m+1..high],先将它们合并到一个局部的暂存向量R1(相当于输出堆)中,待合并完成后将R1复制回R[low..high]中。
(1)合并过程
合并过程中,设置i,j和p三个指针,其初值分别指向这三个记录区的起始位置。合并时依次比较R[i]和R[j]的关键字,取关键字较小的记录复制到R1[p]中,然后将被复制记录的指针i或j加1,以及指向复制位置的指针p加1。
重复这一过程直至两个输入的子文件有一个已全部复制完毕(不妨称其为空),此时将另一非空的子文件中剩余记录依次复制到R1中即可。
(2)动态申请R1
实现时,R1是动态申请的,因为申请的空间可能很大,故须加入申请空间是否成功的处理。
算法实现
自底向上的方法
(1) 自底向上的基本思想
自底向上的基本思想是:第1趟归并排序时,将待排序的文件R[1..n]看作是n个长度为1的有序子文件,将这些子文件两两归并,若n为偶数,则得到![]() 个长度为2的有序子文件;若n为奇数,则最后一个子文件轮空(不参与归并)。故本趟归并完成后,前
个长度为2的有序子文件;若n为奇数,则最后一个子文件轮空(不参与归并)。故本趟归并完成后,前![]() 个有序子文件长度为2,但最后一个子文件长度仍为1;第2趟归并则是将第1趟归并所得到的
个有序子文件长度为2,但最后一个子文件长度仍为1;第2趟归并则是将第1趟归并所得到的![]() 个有序的子文件两两归并,如此反复,直到最后得到一个长度为n的有序文件为止。
个有序的子文件两两归并,如此反复,直到最后得到一个长度为n的有序文件为止。
上述的每次归并操作,均是将两个有序的子文件合并成一个有序的子文件,故称其为"二路归并排序"。类似地有k(k>2)路归并排序。
(2) 二路归并排序的算法演示
【参见动画演示】
(3) 一趟归并算法
分析:
在某趟归并中,设各子文件长度为length(最后一个子文件的长度可能小于length),则归并前R[1..n]中共有![]() 个有序的子文件:
个有序的子文件:
R[1..length],[length+1..2length],…,![]() 。
。
注意:
调用归并操作将相邻的一对子文件进行归并时,必须对子文件的个数可能是奇数、以及最后一个子文件的长度小于length这两种特殊情况进行特殊处理:
① 若子文件个数为奇数,则最后一个子文件无须和其它子文件归并(即本趟轮空);
② 若子文件个数为偶数,则要注意最后一对子文件中后一子文件的区间上界是n。
具体实现算法:
void MergePass(SeqList R,int length)
{ //对R[1..n]做一趟归并排序
int i;
for(i=1;i+2*length-1<=n;i=i+2*length)
Merge(R,i,i+length-1,i+2*length-1);
//归并长度为length的两个相邻子文件
if(i+length-1<n) //尚有两个子文件,其中后一个长度小于length
Merge(R,i,i+length-1,n); //归并最后两个子文件
//注意:若i≤n且i+length-1≥n时,则剩余一个子文件轮空,无须归并
} //MergePass
(4)二路归并排序算法
void MergeSort(SeqList R)
{//采用自底向上的方法,对R[1..n]进行二路归并排序
int length;
for(1ength=1;length<n;length*=2) //做 趟归并
MergePass(R,length); //有序段长度≥n时终止
}
注意:
自底向上的归并排序算法虽然效率较高,但可读性较差。
自顶向下的方法
采用分治法进行自顶向下的算法设计,形式更为简洁。
(1)分治法的三个步骤
设归并排序的当前区间是R[low..high],分治法的三个步骤是:
①分解:将当前区间一分为二,即求分裂点
![]()
②求解:递归地对两个子区间R[low..mid]和R[mid+1..high]进行归并排序;
③组合:将已排序的两个子区间R[low..mid]和R[mid+1..high]归并为一个有序的区间R[low..high]。
递归的终结条件:子区间长度为1(一个记录自然有序)。
(2)具体算法
void MergeSortDC(SeqList R,int low,int high)
{//用分治法对R[low..high]进行二路归并排序
int mid;
if(low<high){//区间长度大于1
mid=(low+high)/2; //分解
MergeSortDC(R,low,mid); //递归地对R[low..mid]排序
MergeSortDC(R,mid+1,high); //递归地对R[mid+1..high]排序
Merge(R,low,mid,high); //组合,将两个有序区归并为一个有序区
}
}//MergeSortDC
(3)算法MergeSortDC的执行过程
算法MergeSortDC的执行过程如下图所示的递归树。
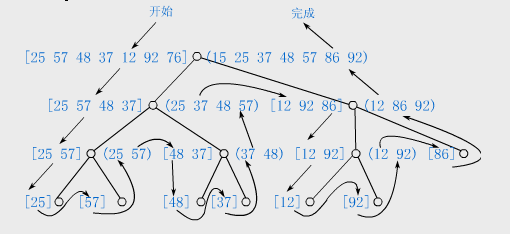
归并排序示例: 自顶向下的二路归并的执行过程
三 算法整体过程演示
一个归并排序的例子:对一个随机点的链表进行排序:

四 算法性能分析
1、稳定性
归并排序是一种稳定的排序。
2、存储结构要求
可用顺序存储结构。也易于在链表上实现。
3、时间复杂度
对长度为n的文件,需进行![]() 趟二路归并,每趟归并的时间为O(n),故其时间复杂度无论是在最好情况下还是在最坏情况下均是O(nlgn)。
趟二路归并,每趟归并的时间为O(n),故其时间复杂度无论是在最好情况下还是在最坏情况下均是O(nlgn)。
4、空间复杂度
需要一个辅助向量来暂存两有序子文件归并的结果,故其辅助空间复杂度为O(n),显然它不是就地排序。
五 参考文献
1. 两路归并:http://student.zjzk.cn/course_ware/data_structure/web/paixu/paixu8.5.1.3.htm;
2. 维基百科:http://zh.wikipedia.org/wiki/%E5%BD%92%E5%B9%B6%E6%8E%92%E5%BA%8F;
3. 算法导论















 2275
2275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









