







/****************************************************************/
/* 学习是合作和分享式的!
/* Author:Atlas Email:wdzxl198@163.com
/* 转载请注明本文出处:
* http://blog.csdn.net/wdzxl198/article/details/9178099
/****************************************************************/
上期内容回顾:
C++内存管理学习笔记(6)
3 内存泄漏 3.1 引入-一个内存泄漏的解决方案 3.2 如何对付内存泄漏 3.3 浅谈c++内存泄漏及检测工具
3.3.3 检测内粗泄漏的工具介绍
在《C/C++内存泄漏及检测》一文中,作者简单的介绍了下在Windows、Linux下面的内存检测。这里我将大致内容引用过来,增加对内存管理中内存泄漏部分的理解。目前笔者主要是在Linux下作一些开发应用,所主要说明在linux平台下的方式,其实这不同平台下原理相同形式不同而已。
首先,来看一个简单的内存泄漏例子,虽然最后函数结束会被释放掉,如果此时while(1),则内存会耗尽
1: #include <stdlib.h>
2: #include <iostream>
3:
4: usingnamespacestd;
5:
6: void GetMemory(char*p, intnum)
7: {
8: p = (char*)malloc(sizeof(char) * num);//使用new也能够检测出来
9: }
10: int main(intargc,char** argv)
11: {
12: char *str = NULL;
13: GetMemory(str, 100);
14: cout<<"Memory leak test!"<<endl;
15: //如果main中存在while循环调用GetMemory
16: //那么问题将变得很严重
17: //while(1){GetMemory(...);}
18: return 0;
19: }
Linux平台下,原理理大致如下:要在分配内存和释放内存时分别做好记录,程序结束时对比分配内存和释放内存的记录就可以确定是不是有内存泄漏。此处作者推荐了linux下mtrace工具,以及另外一个非常强大的工具valgrind,

如上图所示知道:
==6118== 100 bytes in 1 blocks are definitely lost in loss record 1 of 1
==6118== at 0x4024F20: malloc (vg_replace_malloc.c:236)
==6118== by 0x8048724: GetMemory(char*, int) (in /home/netsky/workspace/a.out)
==6118== by 0x804874E: main (in /home/netsky/workspace/a.out)
是在main中调用了GetMemory导致的内存泄漏,GetMemory中是调用了malloc导致泄漏了100字节的内存。
Things to notice:
• There is a lot of information in each error message; read it carefully.
• The 6118 is the process ID; it’s usually unimportant.
• The first line ("Heap Summary") tells you what kind of error it is.
• Below the first line is a stack trace telling you where the problem occurred. Stack traces can get quite large, and be confusing, especially if you are using the C++ STL. Reading them from the bottom up can help.
• The code addresses (eg. 0x4024F20) are usually unimportant, but occasionally crucial for tracking down weirder bugs.The stack trace tells you where the leaked memory was allocated. Memcheck cannot tell you why the memory leaked, unfortunately. (Ignore the "vg_replace_malloc.c", that’s an implementation detail.) There are several kinds of leaks; the two most important categories are:
• "definitely lost": your program is leaking memory -- fix it!
• "probably lost": your program is leaking memory, unless you’re doing funny things with pointers (such as moving
them to point to the middle of a heap block)
另外,其他的一些工具,比如微软的内存泄漏检查工具,我没有用过,在官网上看到了介绍,感觉还是不错的,Visual Leak Detector is a free, robust, open-source memory leak detection system for Visual C++.(Visual Leak Detector for Visual C++ 2008/2010/2012),他的code project在http://www.codeproject.com/Articles/9815/Visual-Leak-Detector-Enhanced-Memory-Leak-Detectio;
3.4 关于内存回收这件事
内存回收是确保内存不泄露的有效机制。
(1)三种内存对象的分析
栈对象的优势是在适当的时候自动生成,又在适当的时候自动销毁,不需要程序员操心;而且栈对象的创建速度一般较堆对象快,因为分配堆对象时,会调用operator new操作,operator new会采用某种内存空间搜索算法,而该搜索过程可能是很费时间的,产生栈对象则没有这么麻烦,它仅仅需要移动栈顶指针就可以了。但是要注意的是,通常栈空间容量比较小,一般是1MB~2MB,所以体积比较大的对象不适合在栈中分配。特别要注意递归函数中最好不要使用栈对象,因为随着递归调用深度的增加,所需的栈空间也会线性增加,当所需栈空间不够时,便会导致栈溢出,这样就会产生运行时错误。
堆对象,其产生时刻和销毁时刻都要程序员精确定义,也就是说,程序员对堆对象的生命具有完全的控制权。我们常常需要这样的对象,比如,我们需要创建一个对象,能够被多个函数所访问,但是又不想使其成为全局的,那么这个时候创建一个堆对象无疑是良好的选择,然后在各个函数之间传递这个堆对象的指针,便可以实现对该对象的共享。另外,相比于栈空间,堆的容量要大得多。实际上,当物理内存不够时,如果这时还需要生成新的堆对象,通常不会产生运行时错误,而是系统会使用虚拟内存来扩展实际的物理内存。
接下来看看static对象:
首先是全局对象。全局对象为类间通信和函数间通信提供了一种最简单的方式,虽然这种方式并不优雅。一般而言,在完全的面向对象语言中,是不存在全局对象的,比如C#,因为全局对象意味着不安全和高耦合,在程序中过多地使用全局对象将大大降低程序的健壮性、稳定性、可维护性和可复用性。C++也完全可以剔除全局对象,但是最终没有,我想原因之一是为了兼容C。
其次是类的静态成员,上面已经提到,基类及其派生类的所有对象都共享这个静态成员对象,所以当需要在这些class之间或这些class objects之间进行数据共享或通信时,这样的静态成员无疑是很好的选择。
接着是静态局部对象,主要可用于保存该对象所在函数被屡次调用期间的中间状态,其中一个最显著的例子就是递归函数,我们都知道递归函数是自己调用自己的函数,如果在递归函数中定义一个nonstatic局部对象,那么当递归次数相当大时,所产生的开销也是巨大的。这是因为nonstatic局部对象是栈对象,每递归调用一次,就会产生一个这样的对象,每返回一次,就会释放这个对象,而且,这样的对象只局限于当前调用层,对于更深入的嵌套层和更浅露的外层,都是不可见的。每个层都有自己的局部对象和参数。
在递归函数设计中,可以使用static对象替代nonstatic局部对象(即栈对象),这不仅可以减少每次递归调用和返回时产生和释放nonstatic对象的开销,而且static对象还可以保存递归调用的中间状态,并且可为各个调用层所访问。
(2)垃圾回收的几个基本方法
本部分内容在《C/C++中几种经典的垃圾回收算法》一文中作者提出了几个垃圾回收的方式,分别是应用计数算法,标记-清除方法,标记-缩并方法
1.引用计数算法 --智能指针的使用
引用计数(Reference Counting)算法是每个对象计算指向它的指针的数量,当有一个指针指向自己时计数值加1;当删除一个指向自己的指针时,计数值减1,如果计数值减为0,说明已经不存在指向该对象的指针了,所以它可以被安全的销毁了。
引用计数算法的优点在于内存管理的开销分布于整个应用程序运行期间,非常的“平滑”,无需挂起应用程序的运行来做垃圾回收;而它的另外一个优势在于空间上的引用局部性比较好,当某个对象的引用计数值变为0时,系统无需访问位于堆中其他页面的单元,而后面我们将要看到的几种垃圾回收算法在回收前都回遍历所有的存活单元,这可能会引起换页(Paging)操作;最后引用计数算法提供了一种类似于栈分配的方式,废弃即回收,后面我们将要看到的几种垃圾回收算法在对象废弃后,都会存活一段时间,才会被回收。
引用计数算法有着诸多的优点,但它的缺点也是很明显的。首先能看到的一点是时间上的开销,每次在对象创建或者释放时,都要计算引用计数值,这会引起一些额外的开销;第二是空间上的开销,由于每个对象要保持自己被引用的数量,必须付出额外的空间来存放引用计数值;引用计数算法最大的缺点就在于它无法处理环形引用,如果成环的两个对象既不可达也无法回收,因为彼此之间互相引用,它们各自的计数值都不为0,这种情况对引用计数算法来说是无能为力的,而其他的垃圾回收算法却能很好的处理环形引用。
引用计数算法最著名的运用,莫过于微软的COM技术,大名鼎鼎的IUnknown接口:
1: interface IUnknown
2: {
3: virtual HRESULT _stdcall QueryInterface
4: (const IID& iid, void* * ppv) = 0;
5: virtual ULONG _stdcall AddRef() = 0;
6: virtual ULONG _stdcall Release() = 0;
7: }
其中的AddRef和Release就是用来让组件自己管理其生命周期,而客户程序只关心接口,而无须再去关心组件的生命周期,一个简单的使用示例如下:
1: int main()
2: {
3: IUnknown* pi = CreateInstance();
4:
5: IX* pix = NULL;
6: HRESULT hr = pi->QueryInterface(IID_IX, (void*)&pix);
7: if(SUCCEEDED(hr))
8: {
9: pix->DoSomething();
10: pix->Release();
11: }
12:
13: pi->Release();
14: }
上面的客户程序在CreateInstance中已经调用过AddRef,所以无需再次调用,而在使用完接口后调用Release,这样组件自己维护的计数值将会改变。下面代码给出一个简单的实现AddRef和Release示例:
1: ULONG _stdcall AddRef()
2: {
3: return ++ m_cRef;
4: }
5:
6: ULONG _stdcall Release()
7: {
8: if(--m_cRef == 0)
9: {
10: delete this;
11: return 0;
12: }
13: return m_cRef;
14: }
在编程语言Python中,使用也是引用计数算法,当对象的引用计数值为0时,将会调用__del__函数,至于为什么Python要选用引用计数算法,据我看过的一篇文章里面说,由于Python作为脚本语言,经常要与C/C++这些语言交互,而使用引用计数算法可以避免改变对象在内存中的位置,而Python为了解决环形引用问题,也引入gc模块,所以本质上Python的GC的方案是混合引用计数和跟踪(后面要讲的三个算法)两种垃圾回收机制。
2.标记-清除算法
标记-清除(Mark-Sweep)算法依赖于对所有存活对象进行一次全局遍历来确定哪些对象可以回收,遍历的过程从根出发,找到所有可达对象,除此之外,其它不可达的对象就是垃圾对象,可被回收。整个过程分为两个阶段:标记阶段找到所有存活对象;清除阶段清除所有垃圾对象。
标记阶段
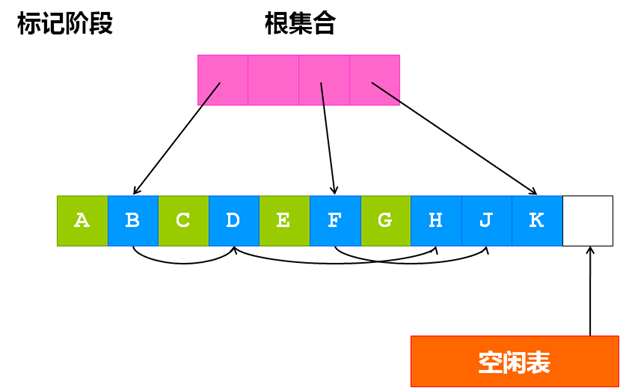
清除阶段
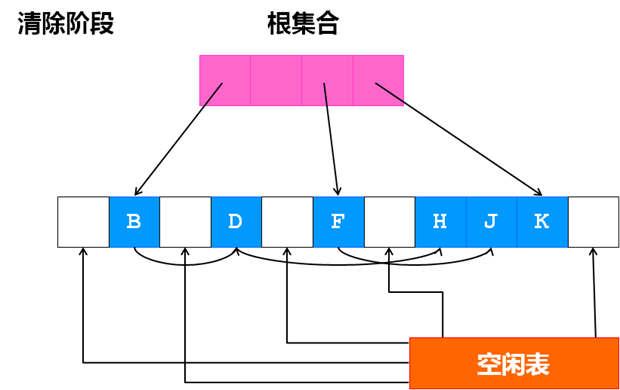
相比较引用计数算法,标记-清除算法可以非常自然的处理环形引用问题,另外在创建对象和销毁对象时时少了操作引用计数值的开销。它的缺点在于标记-清除算法是一种“停止-启动”算法,在垃圾回收器运行过程中,应用程序必须暂时停止,所以对于标记-清除算法的研究如何减少它的停顿时间,而分代式垃圾收集器就是为了减少它的停顿时间,后面会说到。另外,标记-清除算法在标记阶段需要遍历所有的存活对象,会造成一定的开销,在清除阶段,清除垃圾对象后会造成大量的内存碎片。
3.标记-缩并算法
标记-缩并算法是为了解决内存碎片问题而产生的一种算法。它的整个过程可以描述为:标记所有的存活对象;通过重新调整存活对象位置来缩并对象图;更新指向被移动了位置的对象的指针。
标记阶段:
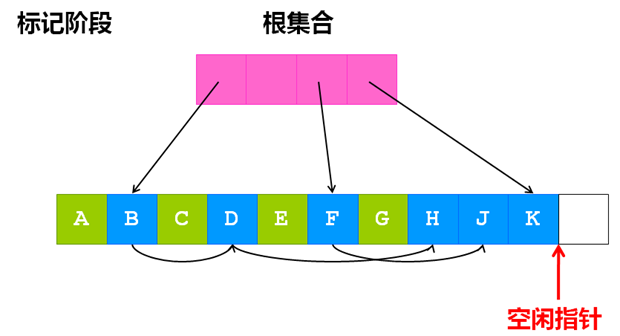
清除阶段:
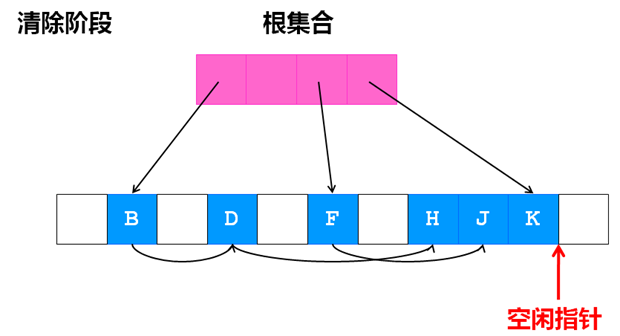
标记-压缩算法最大的难点在于如何选择所使用的压缩算法,如果压缩算法选择不好,将会导致极大的程序性能问题,如导致Cache命中率低等。一般来说,根据压缩后对象的位置不同,压缩算法可以分为以下三种:
1. 任意:移动对象时不考虑它们原来的次序,也不考虑它们之间是否有互相引用的关系。
2. 线性:尽可能的将原来的对象和它所指向的对象放在相邻位置上,这样可以达到更好的空间局部性。
3. 滑动:将对象“滑动”到堆的一端,把存活对象之间的自由单元“挤出去”,从而维持了分配时的原始次序。
4.节点拷贝算法
节点拷贝算法是把整个堆分成两个半区(From,To), GC的过程其实就是把存活对象从一个半区From拷贝到另外一个半区To的过程,而在下一次回收时,两个半区再互换角色。在移动结束后,再更新对象的指针引用,GC开始前的情形:
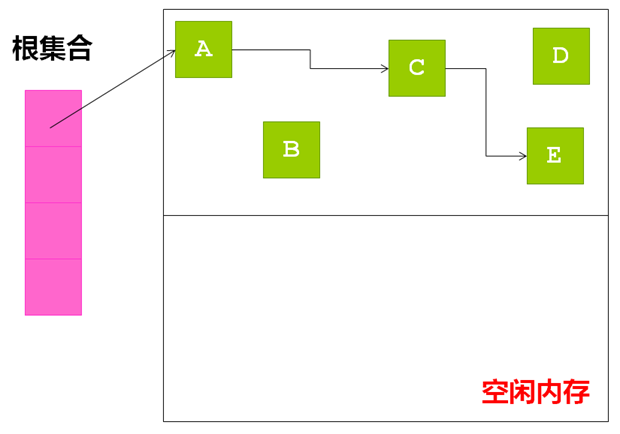
GC结束后的情形:
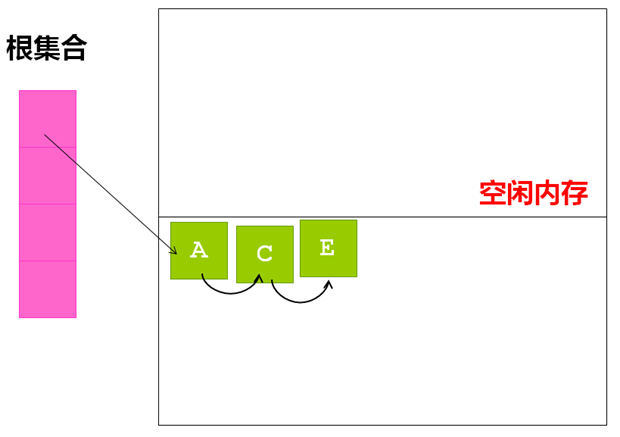
节点拷贝算法由于在拷贝过程中,就可以进行内存整理,所以不会再有内存碎片的问题,同时也不需要再专门做一次内存压缩。,而它最大的缺点在于需要双倍的空间。
本文总共介绍了四种经典的垃圾回收算法,其中后三种经常称之为跟踪垃圾回收,因为引用计数算法能够平滑的进行垃圾回收,而不会出现“停止”现象,经常出现于一些实时系统中,但它无法解决环形问题;而基于跟踪的垃圾回收机制,在每一次垃圾回收过程中,要遍历或者复制所有的存活对象,这是一个非常耗时的工作,一种好的解决方案就是对堆上的对象进行分区,对不同区域的对象使用不同的垃圾回收算法,分代式垃圾回收器正是其中一种,CLR和JVM中都采用了分代式垃圾回收机制,但它们在处理上又有些不同。
(3)真正的垃圾回收(garbage collector)-《再论C++之垃圾回收(GC)》
- C++并非不支持GC。GC是C++的可选组件,不是必需的。
- 这里是C++的GC相关代码以及文档:
- 评价:如果你的系统很单纯,采用这个是不错的主意。因为这意味着你的C++语言已经和Java、C#没有任何区别。但是请注意,这要求你的系统是纯粹的,也就是说:
- 你没有是使用第三方代码。或者,你的第三方代码中,内存也是托管的(通过GC创建出来的)。
- 小心与那些你无法取得源代码的DLL(例如,Win32 API/你购买的第三方组件)打交道。与C#一样,你需要小心,不要让你的程序出现Win32 API还在访问数据,而被GC回收的情形。不过这种情况在C++中比C#要好得多:毕竟在C++中,你对GC的控制能力远远强于C#。
- 特别地、如果你使用了COM,那么你将很痛苦:因为COM基于引用计数来管理对象生命周期,这意味着GC基本上对其无能为力。除非你像C#一样,为每个COM组件提供一个Wrapper。
补充:
- 由于GC依赖语言的自省(reflection)能力,而C++这方面的能力无疑相当得弱,因此C++中的GC是尴尬的。
- 请注意,GC是排他的,这意味着两个GC不能在一起工作。因此,除非C++标准规定了必须使用那个GC,不然托管的C++代码,存在着交流困难。
参考文献详见《c++内存管理学习纲要》
最近几天忙研究项目,所以没有及时发上来学习笔记。这是笔记最后一篇,但不限于此。
Edit by Atlas,
Time: 2013/6/20 09:35















 1388
1388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









