







ES学习笔记
目录
文章目录
ES基本介绍
1. 引言&简介

1.在海量数据执行搜索功能时,如果使用MySql效率太低
2.如果将关键字输入的不准确,一样可以搜索到想到的数据
3.将搜索关键字,以红色字体展示
ES时一个使用java语言并且级域Lucene编写的搜索引擎框架,它提供了分布式的全文搜索功能,他还提供了一个统一的级域RESFUL分格的web接口,官方客户端也对多种语言都提供了相应的api
Lucene:Lucene本身就是一个搜索引擎的提层。
分布式:ES主要时为了突出他的横向扩展能力。
全文检索:将一段词语进行分词,并且将分出的单个词语统一的放到一个分词库中,在搜索时,根据关键字去分词库中检索,找到匹配内容。(倒排索引)
RSETFUL风格的web接口:操作ES很简单,只需要发送一个http请求,并且根据请求方式的不同,携带参数的同时,执行相应的功能
应用广泛:Github,WIKI,GoldMan用ES每天维护奖金10TB数据。
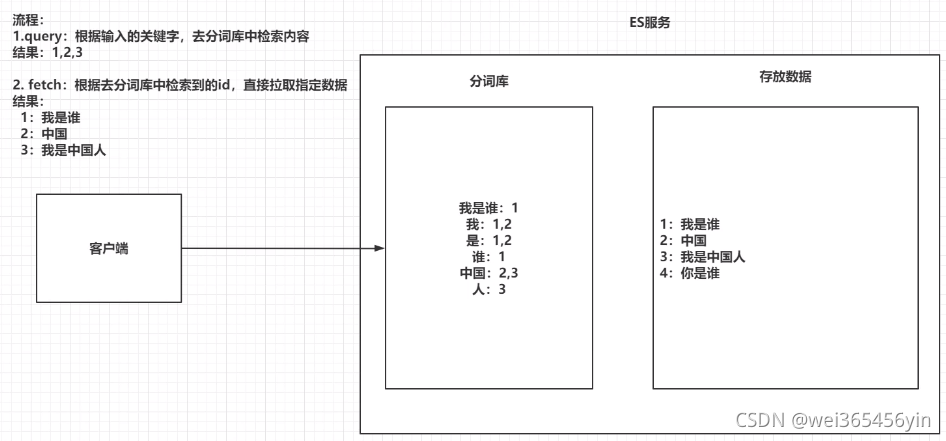
2. 倒排索引
- 将存放的数据,以一定的方式进行分词,并且将分词的内容存放到宇哥单独的分词库中。
- 当用户去查询数据时,会将用户查询的关键字进行分词。
- 然后去分词库中匹配内容,最终得到数据的id标识。
- 根据id标识去存放数据的位置拉去到指定的数据。、
ES的索引基本操作
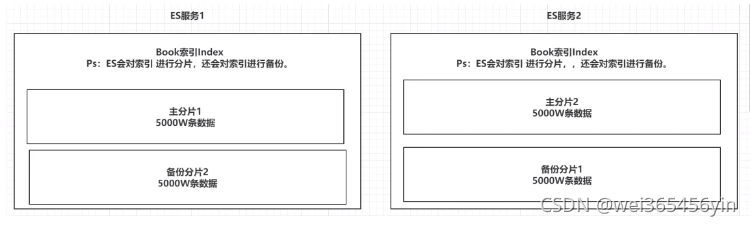
1. 索引结构介绍
索引类型特点 :ES会对索引进行分片,并且备份
ES服务中,可以创建多个索引。
每一个索引默认被分成5片存储
每一个分片都会存在至少一个备份分片
备份分片不会帮助检索数据,当ES检索压力特别大,备份分片才会帮助检索数据
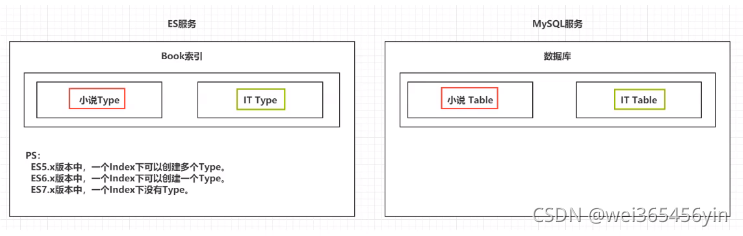
1.2 类型Type
一个索引下,可以创建多个类型。
ps:根据版本不同,类型的创建也不同
- ES5.x版本中,一个index下可以创建多个Type
- ES6.x版本中,一个index下可以创建一个Type
- ES7.x版本中,一个index下没有Type
1.1 索引index
1.3 类型文档
一个类型下,可以有多个文档,这个文档就类似于MySql表中的多行数据。

1.4 Field类型
一个文档中们可以包含多个属性,可以包含多个属性。类似于mysql表中一行数据存在多个列。

2. 操作ES的RESTFUL语法
GET请求:
http://ip:port/index 查询索引信息
http://ip:port/index/type/doc_id:查询指定的文档信息
POST请求:
http://ip:port/index/type/_search 查询,可以在请求体中添加json字符串来代表查询条件
http://ip:port/index/type/doc_id/_update 修改文档,在请求体中指定json字符串代表修改的具体信息
PUT请求:
http://ip:port/index 创建一个索引,需要在请求体中指定索引的信息,类型,结构
http://ip:port/index/type/_mappings 代表创建索引时,指定索引文档存储的属性的信息
DELETE请求:
http://ip:port/index 删除跑路
http://ip:port/index/type/doc_id 删除指定的文档
3. 索引的操作
3.1 创建一个索引
#创建一个索引
PUT /person
{
"settings":{
"number_of_shards":5,
"number_of_replicas":1
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rwG5FucO-1638260761715)(ES%E5%9F%BA%E6%9C%AC%E6%93%8D%E4%BD%9C%E7%AC%94%E8%AE%B0.assets/%E4%BC%81%E4%B8%9A%E5%BE%AE%E4%BF%A1%E6%88%AA%E5%9B%BE_16381016537465.png)]
3.2 查看索引信息
GET /person
3.3 删除索引
DELTE /person
3.4 ES中Field可以指定的类型
常用类型介绍
string:
- text:一把被用于全文检索,将当前field进行分词
- keyword:当前field不会被分词
数值类型
- long:
- integer:
- short:
- byte:
- double:
- float:
- half:
- half_float:精度比float小一半
- scaled_float:根据一个long和scaled来表达一个浮点型,log-345,scaled-1000->345
时间类型
- date类型:针对时间类型指定具体的格式
二进制类型:
- binary类型暂时支持Base64 encode string
范围类型
- long_range: 赋值时,无需指定具体的内容,只需要存储一个范围即可,指定 gt 、get lt 、lte
- integer_range: 同上。
- double_range: 同上。
- float_range: 同上。
- date_range: 同上。
- ip_range: 同上。
经纬度类型
- geo_range:用来存储经纬度,比如我们点外卖的时候,选择离我最近。
IP类型
- ip:可以存储IPV4或者IPV6
其他参数部分如可下可以参考官网https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html
字段数据类型[编辑]
每个字段都有一个字段数据类型或字段类型。此类型指示字段包含的数据类型(例如字符串或布尔值)及其预期用途。例如,您可以将字符串索引到
text和keyword字段。然而,text字段值被分析用于全文搜索,而keyword字符串则保持原样用于过滤和排序。字段类型按系列分组。同一族中的类型支持相同的搜索功能,但可能具有不同的空间使用或性能特征。
目前,唯一类型的家庭
keyword,它由以下部分组成keyword,constant_keyword和wildcard字段类型。其他类型系列只有一个字段类型。例如,boolean类型系列由一种字段类型组成:boolean。常见类型
编码为 Base64 字符串的二进制值。
true和false价值观。
[关键词]
关键字家庭,其中包括
keyword,constant_keyword,和wildcard。[数字]
用于表示金额的 数字类型,例如
long和double。日期
日期类型,包括[
date]和 [date_nanos]。[
alias]为现有字段定义别名。
对象和关系类型[编辑]
[
object]一个 JSON 对象。
[
flattened]整个 JSON 对象作为单个字段值。
[
nested]一个 JSON 对象,保留其子字段之间的关系。
[
join]为同一索引中的文档定义父/子关系。
结构化数据类型[编辑]
[范围]
范围类型,例如
long_range,double_range,date_range,和ip_range。[
ip]IPv4 和 IPv6 地址。
[
version]软件版本。支持语义版本控制 优先规则。
[
murmur3]计算并存储值的哈希值。
聚合数据类型[编辑]
[
aggregate_metric_double]预先聚合的指标值。
[
histogram]直方图形式的预聚合数值。
文本搜索类型[编辑]
[
text领域]文本系列,包括
text和match_only_text。经过分析的非结构化文本。[
annotated-text]包含特殊标记的文本。用于识别命名实体。
[
completion]用于自动完成建议。
[
search_as_you_type]
text-like type 用于按您类型完成。[
token_count]文本中标记的计数。
文档排序类型[编辑]
记录浮点值的密集向量。
记录浮点值的稀疏向量。
记录数字特征以在查询时提高命中率。
[
rank_features]记录数字特征以在查询时提高命中率。
空间数据类型[编辑]
其他类型[编辑]
以Query DSL编写的索引查询。
3.5 创建索引并指定结构
#创建所索引,指定数据结构
PUT /book #索引名称
{
"settings":{
"number_of_shards":5, #分片数
"number_of_replices":1 #备份数
},
"mappings":{
#类型type
"novel":{
#文档存储的类型field
"properties":{
#field属性名
"name":{
"type":"text",
#指定分词器
"analyzer":"ik_max_word",
#指定当前Field可以被作为查询条件
"index":true,
#是否需要额外存储
"store":false,
},
"auther":{
"type":"keyword"
},
"count":{
"type":"long"
},
"on-sale":{
"type":"date",
#时间类型项
"format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"descr":{
"type":"text",
"analyzer":"ik_max_word"
}
}
}
}
}
3.6 文档的操作
文档在ES服务中的唯一标识,’__index’,’__type ,id 三个内容为符合,锁定一个文档,操作时添加还是删除,还是修改
#自动生成文档id
POST /book/novel
{
"name": "盘龙",
"author":"我吃西红柿",
"on-sale":"2021-11-28",
"descr":"daskhjdlajskldj"
}
#手动指定id
POST /book/novel/1
{
"name": "盘龙",
"author":"我吃西红柿",
"on-sale":"2021-11-28",
"descr":"daskhjdlajskldj"
}
#修改文档,基于doc的方式
POST /book/novel/1/_update
{
"doc": {
#指定需要修改的field和对应的值
count:"123456"
}
}
#删除文档
DELETE /book/novel/1
ES各种基础查询
测试数据准备
索引:sms-logs-index
类型:sms-logs-type
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0GMoyxsN-1638260761717)(…/…/ADMINI~1/AppData/Local/Temp/%E4%BC%81%E4%B8%9A%E5%BE%AE%E4%BF%A1%E6%88%AA%E5%9B%BE_1638106230716.png)]
1. term和terms查询
term的查询代表是完全匹配查询,搜索之前不会对你搜索的关键字进行分词,对你的关键字去文档分词库中去匹配内容
POST /索引/_search
{
"form":0,
"size":5,
"query":{
"term":{
"province":{
"value":"北京"
}
}
}
}
- term的查询代表是完全匹配查询,搜索之前不会对你搜索的关键字进行分词,直接去分词路中匹配,找到相应文档内容。
- terms是在针对一个字段包含多个值的时候使用,类似于mysql的in
POST /索引/_search
{
"form":0,
"size":5,
"query":{
"term":{
"province":{
"北京",
"上海",
"深圳"
}
}
}
}
2. match查询
macth查询属于高层查询,会根据你查询的字段类型不一样,采用不同的查询方式。
match查询,实际底层是多个term查询,将term,查询的结果给你封装到了一起。
- 查询的是日期或者是数值的话,会将你基于的字符串查询内容转换为日期或者数值对待
- 如果查询的内容是一个不能被分词的内容(keyword),match查询不会对你指定的关键字分词。
- 如果查询的内容是一个可以被分词的内容(text),match会将你指定的查询的内容去分词,去分词库中匹配指定的内容。
2.1 match_all查询
查询全部内容,不指定任何查询条件。
POST /索引/_search
{
"query":{
"match_all":{
}
}
}
2.2 match查询
会进行分词查询,分成收货,安装,收等查询
POST /索引/_search
{
"query":{
"match":{
"smsContent":"收货安装"
}
}
}
2.3 布尔的match查询
#查询字段smsContent中既包括中国又包括健康的数据,Es默认取10条
POST /索引/_search
{
"query":{
"match":{
"smsContent":{
"query":"中国 健康",
"operator":"and" #这边还可以写 or
}
}
}
}
2.4 multi_match查询
match针对一个field做检索,multi_match针对多个field进行检索,多个field对应一个text。
#搜索这个关键字在指定字段列表中存在的数据
POST /索引/_search
{
"query":{
"multi_match":{
"query":"北京",
"fields":["province","smsContent"]
}
}
}
3. 其他查询
3.1 id查询
GET /sms-logs-index/sms-logs-type/1 #查询索引中id=1的数据
3.2 ids查询
根据多个id查询,类似mysql中的where id in (id1,id2,id3…)
POST /索引/_search
{
"query":{
"ids":{
"values":["1","2","3"]
}
}
}
3.3 prefix查询
前缀查询,可以通过一个关键字去指定一个filed的前缀,从而查询到指定的文档
#搜索指定字段中,包含前缀为途虎的数据,即like "途虎%"
POST /索引/_search
{
"query":{
"prefix":{
"cropNmae":{
"value":"途虎"
}
}
}
}
3.4 fuzzy查询
模糊查询,我们输入字符的大概,ES就可以根据输入的内容大概去查询一下数据结果
#搜索指定字段中,大概模糊查询盒马鲜生->盒马先生
POST /索引/_search
{
"query":{
"fuzzy":{
"cropNmae":{
"value":"盒马先生",
"prefix_length":3 #指定数值中前多少个字符是必须一摸一样的
}
}
}
}
3.5 wildcard查询
通配查询,和mysql中的like
#搜索指定字段中类中国开头的数据类似 like "中国%"
POST /索引/_search
{
"query":{
"wildcard":{
"cropNmae":{
"value":"中国*",
}
}
}
}
#搜索指定字段中类中国开头的只有4个字的数据
POST /索引/_search
{
"query":{
"wildcard":{
"cropNmae":{
"value":"中国??",
}
}
}
}
3.6 range查询
范围查询,只针对数值类型,对某一个字段进行大于或者小于的范围指定
#搜索指定字段值大于=5小于等于10的数据#gt 大于 gte 大于等于 lt:小于 lte:小于等于
POST /索引/_search
{
"query":{
"range":{
"fee":{
"gte":5,
"lte":10
}
}
}
}
3.7 regxp查询
正则查询,通过你编写的正则表达式去匹配内容
PS:preflx,wildcard和regexp查询效率相对比较低
#搜索指定字段为180开头,后八位为数字0-9的电话号码
POST /索引/_search
{
"query":{
"regexp":{
"mobile":"180[0-9]{8}"
}
}
}
3.8 深分页查询
ES对from+size是有限制的,from和size二者之和不能超过1w
原理:
ES查询数据的方式:
第一步现将用户指定的关键进行分词。
第二步将词汇去分词库中检索,得到多个文档id。
第三步中去各个分片中去拉去指定的数据。
第四步将数据根据score进行排序。
第五步根据from的值,将查询到数据舍弃一部分。
第六步返回结果、
srcollz在ES中查询数据的方式:
第一步先将用户指定的关键字进行分词。
第二步将词汇分词库中进行检索,得到多个文档id。
第三步将文档的id存放在一个ES的上下文中
第四步根据你指定的size去ES中指定的数据,拿完数据的文档id,会从上下文中移除
第五步如果需要下一页数据,直接去ES的上下文中,找后续内容
第六步循环第四步和第五步
#scorll
POST /索引/_search?scroll_id=1m
{
"query":{
"match_all":{}
},
size:2,
"sort":[
{
"fee":{
"order":"desc"
}
}
]
}
#根据scroll查询第二页数据
POST /索引/_search
{
"scroll_id":"111111111111dsadasdasdasdasd",#从from,size查询结果中拿去的scroll_id
"scroll":"1m",#指定scroll的缓存时间
}
#删除scroll在ES上下文的数据
DELETE
/_search/scroll/{scroll_id}
4. 复合查询
4.1 bool查询
复合过滤器,将你的多个查询条件,以一定的逻辑组和在一起
- must :所有条件,用must组和在一起,表示and的意思
- must_not:将must_out中的条件,全部都不能匹配,标识not的意思
- should:所有的条件,用should组在一起表示or的意思
#查询省份为武汉或者北京
#运营商不是联通
#smsContent中包含中国和平安
#bool查询
POST /索引/_search
{
"query":{
"bool":{
"should":[
{
"term":{
"province":{
"value":"北京"
}
}
},
{
"term":{
"province":{
"value":"武汉"
}
}
}
],
"must_not":[
"term":{
"opertorId":{
"value":"2"
}
}
],
"must":[
{
"match":{
"smsContent":"中国"
}
},{
"match":{
"smsContent":"平安"
}
}
]
}
}
}
4.2 boosting查询
boosting查询可以帮助我们去影响查询后的score
positive :只有匹配上positive的查询内容,才会被放到返回的结果集中
negative:如果匹配上的positive并且也匹配上了negative,就可以降低这样的文档score。
negative_boost:指定系数,必须小于1.0
关于查询时,分数是如何计算的:
- 搜索的关键字在文档中出现的频次越高,分数就越高
- 指定的文档内容越短,分数就越高
- 我们在搜索时,指定的关键字也会被分词,这个被分词的内容,被分词库匹配的个数越多,分数越高
#boosting查询 收货安装,指定某字段中包含王五,所有的系数乘0.5降低系数
POST /索引/_search
{
"query":{
"postitive":{#查询你匹配你的结果集
"match":{
"smsContent":"收货安装"
}.
"negative":{
“match”:{
"smsContent":"王五"
}
},
"negative_boost":0.5
}
}
}
5. filter查询
- query:根据你的查询条件,去计算文档的匹配度得到一个分数,并且根据分数进行排序,不会做缓存
- filter:根据你的查询条件去查询文档,不去计算分数,而且filter会对经常被过滤的数据进行缓存。
#filter查询
POST /索引名称/_search
{
"query":{
"bool":{
"filter":[
{
"term":{
"corpName":"盒马生鲜"
}
},
"range":{
"fee":{
"lte":5
}
}
]
}
}
}
6. 高亮查询
高亮查询局势你用户输入的关键字,以一定的特殊样式显示用户,让用户知道为什么这个结果被检索出 。
高亮展示的数据,本身就是文档中的一个field,单独将field高亮的形式返回给你 。
ES提供了一个highlight属性,和query同级别的。
- fragment_size:指定高亮数据展示多少字符回来
- pre_tags:指定前缀标签,举个列子
- post_tages:指定后缀标签,举个例子
- fileds:指定那个field以高亮形式展示
#高亮查询
POST /索引名称/_search
{
"query":{
"match":{
"smsContent":"盒马"
}
},
"highlight":{
"fields":{
"smsContent":{}
}
},
"pre_tags":"<font color='red'>",
"post_tags":"</font>",
"fragment_size":10
}
7. 聚合查询
ES的聚合查询和mysql的聚合查询类型,es的聚合查询相比mysql要强大的多,ES提供的统计数据的方式多种多样
#ES聚合查询的RESTFUL语法
POST /index/type/_search
{
"ages":{
"名字(agg)":{#这个是给你的聚合查询起一个名字
"agg_type":{#
"属性":"值"
}
}
}
}
7.1 去重计数查询
去重计数,即Cardinality,第一步先将返回文档中的一个指定的field进行去重,统计一共有多少条,类似 MySql中的groupBy,count(),或者distance
#去重计数 查询 指定省份 每个有几个 北京 上海 武汉 山西
POST /索引/_search
{
"aggs":{
"agg":{
"cardinality":{
"field":"province"
}
}
}
}
7.2 范围统计
统计一定范围内出现的文档个数,比如针对某一个字段Field的值在0-100,100-200,200-300分别出现是多少。
范围统计可以针对普通的数值,针对时间类型,针对ip类型都可以做相应的统计。
range 、date_range、ip_range
#数值方式的统计,
POST /索引/_search
{
"aggs":{
"agg":{
"range"
"field":"fee",
"ranges":[
{
"to":5,
},
{
"from":5,#form有包含当前值的意思,to没有
"to":10
},{
"from":10
}
]
}
}
}
#时间统计
POST /索引/_search
{
"aggs":{
"date_range":{
"field":"createData",
"format":"yyyy",
"ranges":[
{
"to":2000
},
{
"from":2000
}
]
}
}
}
#ip方式的统计
POST /索引/_search
{
"aggs":{
"ip_range":{
"field":"ipAddr",
"ranges":[
{
"to":"10.126.2.9"
},{
"from":"10.126.2.9"
}
]
}
}
}
7.3 统计聚合查询
他可以帮你查询指定field的最大值,最小值、平均值、平方和、、、
使用:extended_stats
POST /索引/_search
{
"aggs":{
"agg":{
"extended_stats":{
"field":"fee"
}
}
}
}
7.4 地图经纬度搜索
ES提供了一个数据类型geo_point,这个类型就是用来存储经纬度的
创建一个带geo_point类型的索引,并添加测试数据
#创建索引 指定一个name,location经纬度地址
PUT /map{
"settings":{
"number_of_shards":5,
"number_of_replicas":1
},
"mappings":{
"map":{
"properties":{
"name":{
"type":"text"
},
"location":{
"type":"geo_point"
}
}
}
}
}
#添加索引
PUT /map/map/1
{
"name":"天安门",
"location":{
"lon":116.403681,
"lat":39.914492
}
}
7.4.1 ES的地图检索方式
geo_distance:直线距离检索方式
geo_bounding_box: 以2个点确定一个矩形,获取在矩形内的全部数据
geo_polygon:以多个点确定一个多边形,获取在多边形内的全部数据
7.4.2 基于RESTUFL实现地图检索
get_distance查询
#geo_distance的查询方式
POST /map/map/_search
{
"query":{
"geo_distance":{
"location":{ #确定一个点
"lon":116.433733,
"lat":39.908404,
}
"distance":3000, #确定半径
"distance_type":"arc" #指定形状为圆形
}
}
}
geo_bounding_box 2个点确定矩形数据
POST /map/map/_search
{
"query":{
"geo_bounding_box":{
"location":{
"top_left":{ #左上角点
"lon":116.433733,
"lat":39.908404,
},
"bottom_right":{#右下角点
"lon":116.433446,
"lat":39.908404,
}
}
}
}
}
geo_polygon 多边形连点搜索
POST /map/map/_search
{
"query":{
"geo_polygon":{
"location":{
"points":[
{#第一个点
"lon":116.433733,
"lat":39.908404,
},
{#第二个点
"lon":116.433446,
"lat":39.908404,
},
{ #第三个点
"lon":116.433446,
"lat":39.908404,
}
]
}
}
}
}














 586
586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









