







好久没写博客啦。年底不是很忙,就把平常自己积累的东西放到博客上吧。和大家共享学习下。
quartz框架是大家常用的 定时任务框架。而定时任务在分布式异步系统中,是常用的主动轮询的手段。认清它底层怎么运行,确实是重要的事情。个人认为quartz框架就两个核心一、是如何将 CronExpression(克隆表达式) 解析,并且得知下一次要运行的时间。 二、quartz是如何在准确的时间内调用预定义的job和trigger。本博客先说明阐述下问题二。
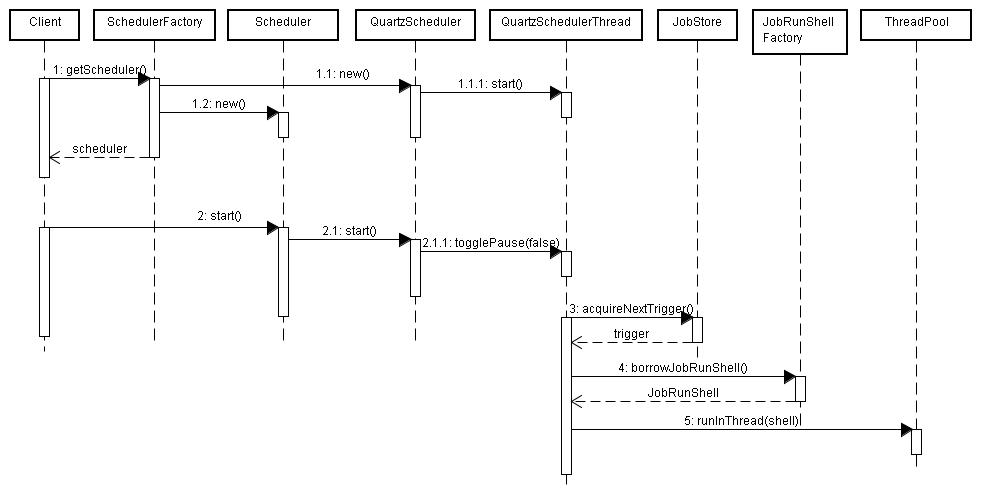
先看下这个序列图(http://blog.csdn.net/cutesource/article/details/4965520 从这个博客里摘来的,省的自己再画一下)。整个调用的过程其实很简单。其中scheduler 是对外公布的接口。quartzScheduler 是quartz框架的核心,主要是实现了对外的接口 scheduler。QuartzScedulerThread是本博客想说的重中之重。它是quartz的主线程(核心线程)。专门用来获取将要执行的触发器。 jobStore 是存放了quartz框架中注册了了的 trigger 和job。一般用 的是 RAMJobStore(基于内存的)。jobRunShell可以理解成实现了runnable的对象,可以理解为它对 job做了一层代理,同时拥有jobExecutionContext(job执行的上下文环境).ThreadPool不用多说,线程池,专门用来执行job的.
一、定义完jobDetail 和 trigger 后调用scheduleJob方法代码实现如下。
public Date scheduleJob(SchedulingContext ctxt, JobDetail jobDetail,
Trigger trigger) throws SchedulerException {
validateState(); //判定是否schedule是否关闭了
if (jobDetail == null) {
throw new SchedulerException("JobDetail cannot be null",
SchedulerException.ERR_CLIENT_ERROR);
}
if (trigger == null) {
throw new SchedulerException("Trigger cannot be null",
SchedulerException.ERR_CLIENT_ERROR);
}
jobDetail.validate(); //判断name、group、jobClass是否是
if (trigger.getJobName() == null) {
trigger.setJobName(jobDetail.getName());
trigger.setJobGroup(jobDetail.getGroup());
} else if (trigger.getJobName() != null
&& !trigger.getJobName().equals(jobDetail.getName())) {
throw new SchedulerException(
"Trigger does not reference given job!",
SchedulerException.ERR_CLIENT_ERROR);
} else if (trigger.getJobGroup() != null
&& !trigger.getJobGroup().equals(jobDetail.getGroup())) {
throw new SchedulerException(
"Trigger does not reference given job!",
SchedulerException.ERR_CLIENT_ERROR);
}
trigger.validate();
Calendar cal = null;
if (trigger.getCalendarName() != null) {
cal = resources.getJobStore().retrieveCalendar(ctxt,
trigger.getCalendarName());
}
Date ft = trigger.computeFirstFireTime(cal);
if (ft == null) {
throw new SchedulerException(
"Based on configured schedule, the given trigger will never fire.",
SchedulerException.ERR_CLIENT_ERROR);
}
resources.getJobStore().storeJobAndTrigger(ctxt, jobDetail, trigger);
notifySchedulerListenersJobAdded(jobDetail); //jobAdd事件
notifySchedulerThread(trigger.getNextFireTime().getTime());
notifySchedulerListenersSchduled(trigger);
return ft;
}这个方法就做了两件事情
1、验证jobDetail 和 trigger是否可行
2、在jobStore中注册加入 jobDetail 和 trigger。同时触发了 jobAdd事件(通知在schdler上注册了SchedulerListeners的监听者)。
到此可以理解为配置ok了。当我调用 scheduler.start()方法后,表象上定时任务就启动了。其实真实实现如下。
二、我们直接看QuartzSchedulerThread的run方法吧。
2.1、线程是如何开始的
public void run() {
boolean lastAcquireFailed = false;
while (!halted.get()) {
try {
// check if we're supposed to pause...
synchronized (sigLock) {
while (paused && !halted.get()) { //这里有个paused ,就是专门等我们调用start方法后,才会变成false,要不然一直循环wait.
try {
// wait until togglePause(false) is called...
sigLock.wait(1000L);
} catch (InterruptedException ignore) {
}
}
if (halted.get()) {
break;
}
}
代码块1:<span style="font-family: Arial, Helvetica, sans-serif;">从jobStore中获取下一个要执行的trigger,没有的话返回null.</span>同时会判定是否是misfired。也就是说是否是错过了执行时间,这里会有一个补偿机制。
代码块3:创建 JobRunShell 对象,传入jobDetail信息.
代码块4:将jobRunShell放入线程池中执行。
}循环执行一次,只会找到一个trigger。如果没有找到,整个线程会wait(最大闲置时间)。其中这个最大闲置时间是算出来的。
代码块1:
try {
trigger = qsRsrcs.getJobStore().acquireNextTrigger(
ctxt, now + idleWaitTime); //这个方法是关键。
lastAcquireFailed = false;
} catch (JobPersistenceException jpe) {
if(!lastAcquireFailed) {
qs.notifySchedulerListenersError(
"An error occured while scanning for the next trigger to fire.",
jpe);
}
lastAcquireFailed = true;
} catch (RuntimeException e) {
if(!lastAcquireFailed) {
getLog().error("quartzSchedulerThreadLoop: RuntimeException "
+e.getMessage(), e);
}
lastAcquireFailed = true;
}其中acquireNexTrigger主要是从JobStore中获取下一个将要执行的trigger的。获取的方式其实很简单。jobStore 中有个 TreeSet<TriggerComparator> timeTriggers属性存储了所有的trigger(特别要注意,它实现了Comparator这个接口。 按照trigger的nextFireTime就近原则排序了,当时就是忽略了这一点就一直不理解为什么每次只拿第一个)。每次从第一个拿。
while (tw == null) {
try {
tw = (TriggerWrapper) timeTriggers.first();
} catch (java.util.NoSuchElementException nsee) {
return null;
}
if (tw == null) {
return null;
}
if (tw.trigger.getNextFireTime() == null) {
timeTriggers.remove(tw);
tw = null;
continue;
}
timeTriggers.remove(tw);
if (applyMisfire(tw)) { //这个misFire判定和补偿机制
if (tw.trigger.getNextFireTime() != null) {
timeTriggers.add(tw);
}
tw = null;
continue;
}这里 只有当 if(tw.trigger.getNextFireTime().getTime() <= noLaterThan) 时候,才算找到真正下一个要执行的 trigger。 其中noLaterThan= now + idleWaitTime。可以理解成当前时间加上最大空闲时间,也就是当前系统默认的最大容忍时间,超过这个时间的话,就等到下一次再来取这个trigger.
代码块2:
if (trigger != null) {
now = System.currentTimeMillis();
long triggerTime = trigger.getNextFireTime().getTime();
long timeUntilTrigger = triggerTime - now;
while(timeUntilTrigger > 2) {
synchronized(sigLock) {
if(!isCandidateNewTimeEarlierWithinReason(triggerTime, false)) {
try {
// we could have blocked a long while
// on 'synchronize', so we must recompute
now = System.currentTimeMillis();
timeUntilTrigger = triggerTime - now;
if(timeUntilTrigger >= 1)
sigLock.wait(timeUntilTrigger);
} catch (InterruptedException ignore) {
}
}
}
if(releaseIfScheduleChangedSignificantly(trigger, triggerTime)) {
trigger = null;
break;
}
now = System.currentTimeMillis();
timeUntilTrigger = triggerTime - now;
}这段代码主要是说如果执行的时间和当前的时间相差2ms,就会wait到指定时间。去除提前执行的可能。
JobRunShell shell = null;
try {
shell = qsRsrcs.getJobRunShellFactory().borrowJobRunShell();
shell.initialize(qs, bndle);
} catch (SchedulerException se) {
try {
qsRsrcs.getJobStore().triggeredJobComplete(ctxt,
trigger, bndle.getJobDetail(), Trigger.INSTRUCTION_SET_ALL_JOB_TRIGGERS_ERROR);
} catch (SchedulerException se2) {
qs.notifySchedulerListenersError(
"An error occured while placing job's triggers in error state '"
+ trigger.getFullName() + "'", se2);
// db connection must have failed... keep retrying
// until it's up...
errorTriggerRetryLoop(bndle);
}
continue;
}这段代码主要是指 如何通过 JobRunShellFactory 来创建 JobRunShell 对象。borrowJobRunShell()这个方法准确的理解应该是,JobRunShellFactory 应该算一个对象池,可能是创建也可能是复用。但是源代码里都是new对象。估计名字取的有问题。
shell.initialize(qs, bndle); 这个方法就是初始化。qs 是指QuartzScheduler 对象,bndler 就是 TriggerFiredBundle 可以理解为代理了jobDetail .
代码3、
if (qsRsrcs.getThreadPool().runInThread(shell) == false) {
try {
getLog().error("ThreadPool.runInThread() return false!");
qsRsrcs.getJobStore().triggeredJobComplete(ctxt,
trigger, bndle.getJobDetail(), Trigger.INSTRUCTION_SET_ALL_JOB_TRIGGERS_ERROR);
} catch (SchedulerException se2) {
qs.notifySchedulerListenersError(
"An error occured while placing job's triggers in error state '"
+ trigger.getFullName() + "'", se2);
releaseTriggerRetryLoop(trigger);
}
}这段代码就第一句是核心,将JobRunShell 放入线程池中执行。执行的过程,我想就不用多说。由于这个run方法是同步的。所以不涉及到线程池中资源抢断的情况。我用的是SimpleThreadPool 。默认是 初始化10个core Thread。
综上,我觉得quartz中job调用基本就这么回事。其他的像各种Listeners.plugin之类的,就不赘述了。但是 还有一个CronExpression是怎么解析的,以及怎么算出每个trigger的下一次要执行的时间,就下个博客再写出来吧。















 2534
2534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









