







【OCR】【专题系列】四、基于RCNN-CTC的不定长文本识别
目录
一、论文阅读
在上篇博客《【OCR】基于图像分类的定长文本识别》中,通过图像像素分类的方法实现固定图片的识别方法。本篇主要是针对OCR经典论文《An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition》代码复现和实验结果分析。
论文的网络结构如下图所示:
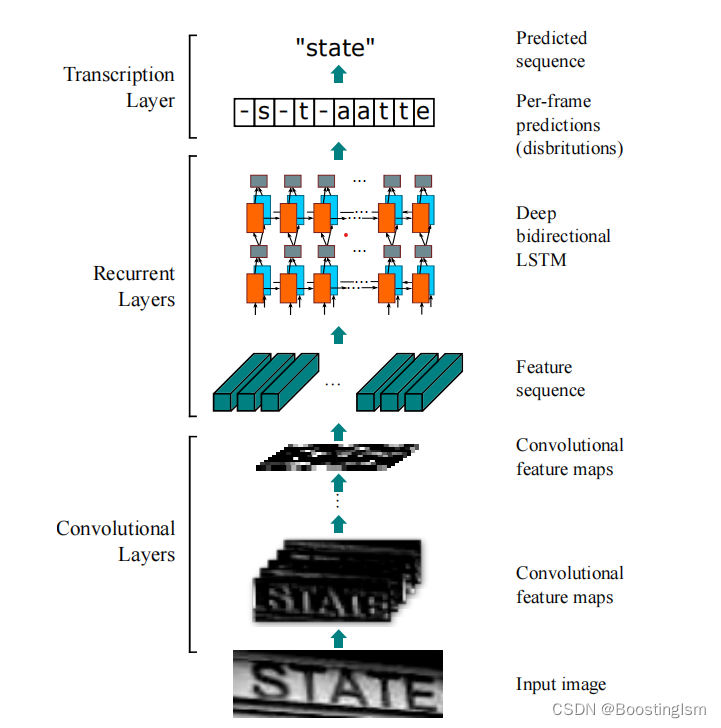
图1 CRNN-CTC网络结构图
网络结构主要包括CNN和BiLSTM两部分构成,CNN主要用于图像特征信息提取,BiLSTM连接语义信息,最后通过CTCLoss损失用于约束不定长文本连续的错误识别。在开源代码的基础上,本文针对自己已有数据集复现了代码、做了小规模实验,局部测试了模型效果。
二、代码实现
本文代码结构承接上文,模型结构通过Model类完成,数据通过MyDataset类+collate_fn完成,相关配置通过configs完成配置。在模型定义中通过pytorch实现CRNN-CTC的模型,损失函数采用torch.nn.ctcloss,所用词表可通过字符串按顺序构建。下述为代码实现,修改对应配置项即可跑通复现实验。
from torch.utils.data import Dataset
from torch import nn as nn
import torchvision.transforms as T
import torch.nn.functional as F
from torch.utils.data import DataLoader
import os
import torch
from PIL import Image
from tqdm import tqdm
import numpy as np
class configs():
def __init__(self):
#Data
self.data_dir = './captcha_datasets'
self.train_dir = 'train-data'
self.valid_dir = 'valid-data'
self.test_dir = 'test-data-1'
self.save_model_dir = 'models_ocr'
self.get_lexicon_dir = './lbl2id_map.txt'
self.img_transform = T.Compose([
T.Resize((32, 100)),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# self.lexicon = self.get_lexicon(lexicon_name=self.get_lexicon_dir)
self.lexicon = "0123456789"+"_"
self.all_chars = {v: k for k, v in enumerate(self.lexicon)}
self.all_nums = {v: k for v, k in enumerate(self.lexicon)}
self.class_num = len(self.lexicon)
self.label_word_length = 4
#train
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
self.batch_size = 64
self.epoch = 31
self.save_model_fre_epoch = 1
self.nh = 128 # 隐层数量
self.istrain = True
self.istest = True
def get_lexicon(self,lexicon_name):
'''
#获取词表 lbl2id_map.txt',词表格式如下
#0\t0\n
#a\t1\n
#...
#z\t63\n
:param lexicons_name:
:return:
'''
lexicons = open(lexicon_name, 'r', encoding='utf-8').readlines()
lexicons_str = ''.join(word[0].split('\t')[0] for word in lexicons)
return lexicons_str
cfg = configs()
#model define
class BidirectionalLSTM(nn.Module):
def __init__(self, nIn, nHidden, nOut):
super(BidirectionalLSTM, self).__init__()
self.rnn = nn.LSTM(nIn, nHidden, bidirectional=True)
self.embedding = nn.Linear(nHidden * 2, nOut)
def forward(self, input):
recurrent, _ = self.rnn(input)
T, b, h = recurrent.size()
t_rec = recurrent.view(T * b, h)
output = self.embedding(t_rec) # [T * b, nOut]
output = output.view(T, b, -1)
return output
class Model(nn.Module):
def __init__(self, imgH, nc, nclass, nh, n_rnn=2, leakyRelu=False):
super(Model, self).__init__()
assert imgH % 16 == 0, 'imgH has to be a multiple of 16'
ks = [3, 3, 3, 3, 3, 3, 2]
ps = [1, 1, 1, 1, 1, 1, 0]
ss = [1, 1, 1, 1, 1, 1, 1]
nm = [64, 128, 256, 256, 512, 512, 512]
cnn = nn.Sequential()
def convRelu(i, batchNormalization=False):
nIn = nc if i == 0 else nm[i - 1]
nOut = nm[i]
cnn.add_module('conv{0}'.format(i),
nn.Conv2d(nIn, nOut, ks[i], ss[i], ps[i]))
if batchNormalization:
cnn.add_module('batchnorm{0}'.format(i), nn.BatchNorm2d(nOut))
if leakyRelu:
cnn.add_module('relu{0}'.format(i),
nn.LeakyReLU(0.2, inplace=True))
else:
cnn.add_module('relu{0}'.format(i), nn.ReLU(True))
convRelu(0)
cnn.add_module('pooling{0}'.format(0), nn.MaxPool2d(2, 2)) # 64x16x64
convRelu(1)
cnn.add_module('pooling{0}'.format(1), nn.MaxPool2d(2, 2)) # 128x8x32
convRelu(2, True)
convRelu(3)
cnn.add_module('pooling{0}'.format(2),
nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # 256x4x16
convRelu(4, True)
convRelu(5)
cnn.add_module('pooling{0}'.format(3),
nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # 512x2x16
convRelu(6, True) # 512x1x16
self.cnn = cnn
self.rnn = nn.Sequential(
BidirectionalLSTM(512, nh, nh),
BidirectionalLSTM(nh, nh, nclass))
def forward(self, input):
# conv features
conv = self.cnn(input)
b, c, h, w = conv.size()
assert h == 1, "the height of conv must be 1"
conv = conv.squeeze(2)
conv = conv.permute(2, 0, 1) # [w, b, c]
# rnn features
output = self.rnn(conv)
# add log_softmax to converge output
output = F.log_softmax(output, dim=2)
output_lengths = torch.full(size=(output.size(1),), fill_value=output.size(0), dtype=torch.long,
device=cfg.device)
return output, output_lengths
def backward_hook(self, module, grad_input, grad_output):
for g in grad_input:
g[g != g] = 0 # replace all nan/inf in gradients to zero
#dataset define
class MyDataset(Dataset):
def __init__(self, path: str, transform=None, ):
if transform == None:
self.transform = T.Compose(
[
T.ToTensor()
])
else:
self.transform = transform
self.path = path
self.picture_list = list(os.walk(self.path))[0][-1]
def __len__(self):
return len(self.picture_list)
def __getitem__(self, item):
"""
:param item: ID
:return: (图片,标签)
"""
picture_path_list = self._load_picture()
img = Image.open(picture_path_list[item]).convert("RGB")
img = self.transform(img)
label = os.path.splitext(self.picture_list[item])[0].split("_")[1]
label = [[cfg.all_chars[i]] for i in label]
label = torch.as_tensor(label, dtype=torch.int64)
return img, label
def _load_picture(self):
return [self.path + '/' + i for i in self.picture_list]
def collate_fn(batch):
sequence_lengths = []
max_width, max_height = 0, 0
for image, label in batch:
if image.size(1) > max_height:
max_height = image.size(1)
if image.size(2) > max_width:
max_width = image.size(2)
sequence_lengths.append(label.size(0))
seq_lengths = torch.LongTensor(sequence_lengths)
seq_tensor = torch.zeros(seq_lengths.size(0), seq_lengths.max()).long()
img_tensor = torch.zeros(seq_lengths.size(0), 3, max_height, max_width)
for idx, (image, label) in enumerate(batch):
seq_tensor[idx, :label.size(0)] = torch.squeeze(label)
img_tensor[idx, :, :image.size(1), :image.size(2)] = image
return img_tensor, seq_tensor, seq_lengths
class ocr():
def train(self):
model = Model(imgH = 32,nc = 3, nclass = cfg.class_num, nh = cfg.nh)
model = model.to(cfg.device)
criterion = torch.nn.CTCLoss(blank=cfg.class_num - 1, zero_infinity=True)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
model.train()
# train dataset
train_dataset = MyDataset(os.path.join(cfg.data_dir, cfg.train_dir),
transform=cfg.img_transform) # 训练路径以及transform
train_loader = DataLoader(dataset=train_dataset, batch_size=cfg.batch_size, shuffle=True,drop_last=True,num_workers=0, collate_fn=collate_fn)
for epoch in range(cfg.epoch):
bar = tqdm(enumerate(train_loader,0))
loss_sum = []
total = 0
correct = 0
for idx, (images, labels,label_lengths) in bar:
images, labels, label_lengths = images.to(cfg.device), \
labels.to(cfg.device), \
label_lengths.to(cfg.device)
optimizer.zero_grad()
outputs, output_lengths = model(images)
loss = criterion(outputs, labels, output_lengths, label_lengths)
loss.backward()
optimizer.step()
loss_sum.append(loss.item())
c, t = self.calculat_train_acc(outputs, labels, label_lengths)
correct +=c
total += t
bar.set_description("epcoh:{} idx:{},loss:{:.6f},acc:{:.6f}".format(epoch, idx, np.mean(loss_sum),100 * correct / total))
if epoch%cfg.save_model_fre_epoch ==0:
torch.save(model.state_dict(), os.path.join(cfg.save_model_dir,"epoch_"+str(epoch)+'.pkl'), _use_new_zipfile_serialization=True) # 模型保存
torch.save(optimizer.state_dict(), os.path.join(cfg.save_model_dir,"epoch_"+str(epoch)+"_opti"+'.pkl'), _use_new_zipfile_serialization=True) # 优化器保存
def infer(self):
for modelname in os.listdir(cfg.save_model_dir):
#model define
train_weights_path = os.path.join(cfg.save_model_dir, modelname)
train_weights_dict = torch.load(train_weights_path)
model = Model(imgH=32, nc=3, nclass=cfg.class_num, nh=cfg.nh)
model.load_state_dict(train_weights_dict, strict=True)
model = model.to(cfg.device)
model.eval()
#test dataset
test_dataset = MyDataset(os.path.join(cfg.data_dir, cfg.test_dir), transform=cfg.img_transform) # 训练路径以及transform
test_loader = DataLoader(dataset=test_dataset, batch_size=1, shuffle=False, collate_fn=collate_fn)
total = 0
correct = 0
results = []
for idx,(images, labels,label_lengths) in enumerate(test_loader,0):
labels = torch.squeeze(labels).to(cfg.device)
with torch.no_grad():
predicts,output_lengths = model(images.to(cfg.device))
c, t, result = self.calculat_infer_acc(predicts, labels, label_lengths)
correct += c
total += t
results.append(result)
print("model name: "+modelname+'\t'+"|| acc: "+str(correct / total)+'\n')
# 计算训练准确率
def calculat_train_acc(self,output, target, target_lengths):
output = torch.argmax(output, dim=-1)
output = output.permute(1, 0)
correct_num = 0
for predict, label, label_length in zip(output, target, target_lengths):
predict = torch.unique_consecutive(predict)
predict = predict[predict != (cfg.class_num - 1)]
if (predict.size()[0] == label_length.item()
and (predict == label[:label_length.item()]).all()):
correct_num += 1
return correct_num, target.size(0)
#计算推理准确率
def calculat_infer_acc(self,output, target, target_lengths):
output = torch.argmax(output, dim=-1)
output = output.permute(1, 0)
correct_num = 0
total_num = 0
predict_list = []
for predict, label, label_length in zip(output, target, target_lengths):
total_num +=1
predict = torch.unique_consecutive(predict)
predict = predict[predict != (cfg.class_num - 1)]
predict_list = predict.cpu().tolist()
label_list = target.cpu().tolist()
if predict_list == label_list:
correct_num += 1
if predict_list == []:
predict_str = '____'
else:
predict_str = ''.join([cfg.all_nums[s] for s in predict_list])
label_str = ''.join([cfg.all_nums[s] for s in label_list])
return correct_num, total_num,','.join([predict_str,label_str])
if __name__ == '__main__':
myocr = ocr()
if cfg.istrain == True:
myocr.train()
if cfg.istest == True:
myocr.infer()三、结果讨论
本文采用captcha_datasets数据集作为实验数据集,训练集:验证集:测试集=25000:10000:10000,图片内容主要是数字验证码。在本次实验中采用30次迭代测试模型效果,train-ctcloss、train-acc、test-acc效果如下表所示
| epoch | loss | train-acc | val/test-acc |
| 1 | 2.772569 | 0 | 0 |
| 2 | 0.957933 | 0.45997596 | 0.7438 |
| 3 | 0.038466 | 0.96987179 | 0.9706 |
| 4 | 0.018337 | 0.984375 | 0.9653 |
| 5 | 0.01449 | 0.98766026 | 0.9836 |
| 10 | 0.008008 | 0.99246795 | 0.9714 |
| 15 | 0.002388 | 0.99759615 | 0.9941 |
| 20 | 0.004845 | 0.99583333 | 0.9952 |
| 25 | 0.001462 | 0.99863782 | 0.9867 |
| 30 | 0.003154 | 0.99767628 | 0.9949 |
部分识别效果图展示:

图 识别效果实例图
由上述的训练过程可以看出,ctcloss在5次迭代后就有了较好的识别效果。原因是数据量较小、数据质量较单一,可以期待在更大数据集上的识别效果。

















 7104
7104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











