







【OCR】【专题系列】五、基于Encoder-Decoder的文本识别
目录
一、论文阅读
OCR识别技术在流程上,可以分为:1.CNN抽取图像特征;2.RNN/BiLSTM组合上下文信息特征;3.对齐标签目标函数产生Loss训练整个网络。见下图所示:
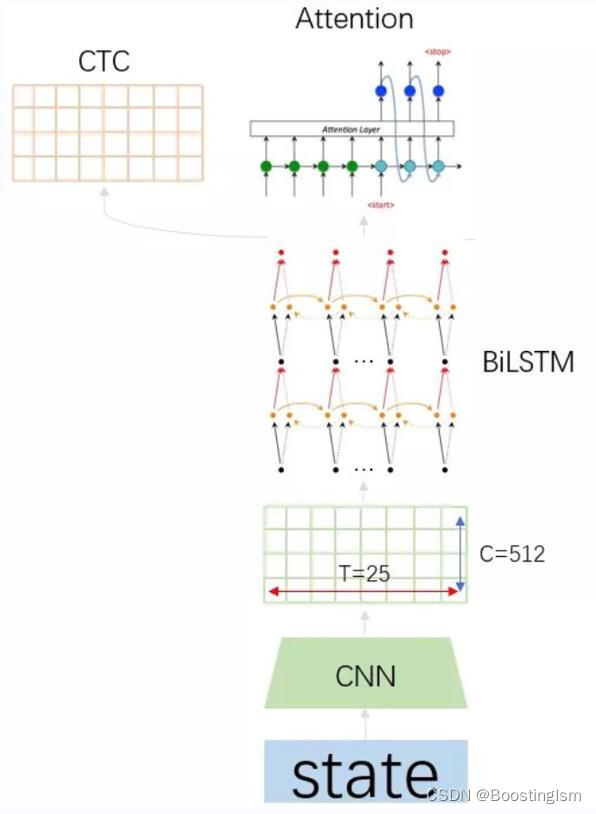
在上述流程中,步骤1可以通过ResNet/VGG等图像处理结构来对CNN网络结构进行替换;在步骤2中可通过RNN/Transformer/Bert等时序文本网络结构来替换BiLSTM的网络结构;然而文字识别区别一般的任务最重要的是步骤3目标函数的选择和实现。在我博客OCR系列代码中,讲解并实现了基于CTC的文本对齐方法《【OCR】基于RCNN-CTC的不定长文本识别》。接下来将讲解并实现基于Encoder-Attention-Decoder的方式对齐不定长文本识别任务。
原文链接为:《Robust Scene Text Recognition with Automatic Rectification》
文章讲述了通过编码阶段用于特征抽取,包括:ConvNet和BiLSTM共同实现特征抽取;在解码阶段通过加入Attention结构将编码阶段所有时序特征全部用于解码推理。网络结构如下图所示:

可从上图看出,Encoder部分采用ConvNet+BiLSTM,Decoder部分仅采用Attention推理。
特别的:CTC对齐采用的是定义max_length,然后通过CTC的原理,再对max_length维的特征缩减实现文本的对齐;Encoder-Attention-Decoder对齐方式是通过定义<EOS>标志符,若在训练时遇到<EOS>标识符就立即停止。
根据上述原理,本文实现了基于Encoder-Attention-Decoder的代码如下,代码结构与之前OCR系列文章一致。
二、代码实现
说明:在config类里面,train_list为训练集路径及对应标签描述的txt、eval_list为验证集路径及对应标签描述的txt、test_img_paths为存放待推理图像文件夹路径。
对应的train_list.txt的组织结构如下图,文件路径+空格+标签+"\n",eval_list格式保持一致。
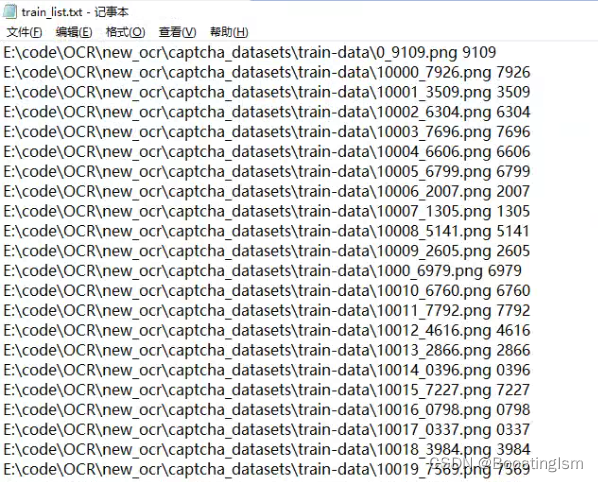
save_model_dir为模型保存的地址,test_encoder_path和test_decoder_path为推理时读取模型的地址。然后istrain和istest用于控制训练和推理。修改好对应参数即可训练和推理。
import os
import random
import numpy as np
from PIL import Image
import cv2
import torch
import torch.utils.data
import torch.backends.cudnn as cudnn
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as T
from torch.autograd import Variable
import collections
import collections.abc
cudnn.benchmark = True
class configs():
def __init__(self):
#Data
self.train_list = r'E:\code\OCR\crnn_seq2seq_ocr_pytorch-master\data\train_list.txt'
self.eval_list = r'E:\code\OCR\crnn_seq2seq_ocr_pytorch-master\data\valid_list.txt'
self.img_height = 32
self.img_width = 280
self.save_model_dir = 'seq_models'
self.get_lexicon_dir = './lbl2id_map.txt'
# self.lexicon = self.get_lexicon(lexicon_name=self.get_lexicon_dir)
self.lexicon = "0123456789"
self.all_chars = {v: k for k, v in enumerate(self.lexicon)}
self.all_nums = {v: k for v, k in enumerate(self.lexicon)}
self.class_num = len(self.lexicon)+2
self.label_word_length = 4
self.random_sample = True #是否数据随机
self.teaching_forcing_prob = 0.5
#train
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
self.batch_size = 64
self.epoch = 31
self.save_model_fre_epoch = 1
self.hidden_size = 256 # 隐层数量
self.learning_rate = 0.0001
self.encoder = ''
self.decoder = ''
self.max_width = 71 #最长字长
#test/infer
self.test_img_paths = r'E:\code\OCR\new_ocr\captcha_datasets\test-data-1'
self.test_encoder_path = r'E:\code\OCR\crnn_seq2seq_ocr_pytorch-master\model\encoder_30.pth'
self.test_decoder_path = r'E:\code\OCR\crnn_seq2seq_ocr_pytorch-master\model\decoder_30.pth'
self.istrain = False
self.istest = True
def get_lexicon(self,lexicon_name):
'''
#获取词表 lbl2id_map.txt',词表格式如下
#0\t0\n
#a\t1\n
#...
#z\t63\n
:param lexicons_name:
:return:
'''
lexicons = open(lexicon_name, 'r', encoding='utf-8').readlines()
lexicons_str = ''.join(word[0].split('\t')[0] for word in lexicons)
return lexicons_str
cfg = configs()
#数据
class TextLineDataset(torch.utils.data.Dataset):
def __init__(self, text_line_file=None, transform=None, target_transform=None):
self.text_line_file = text_line_file
with open(text_line_file) as fp:
self.lines = fp.readlines()
self.nSamples = len(self.lines)
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return self.nSamples
def __getitem__(self, index):
assert index <= len(self), 'index range error'
line_splits = self.lines[index].strip().split()
img_path = line_splits[0]
try:
if 'train' in self.text_line_file:
img = Image.open(img_path).convert('RGB')
else:
img = Image.open(img_path).convert('RGB')
except IOError:
print('Corrupted image for %d' % index)
return self[index + 1]
if self.transform is not None:
img = self.transform(img)
label = line_splits[1]
if self.target_transform is not None:
label = self.target_transform(label)
return (img, label)
class ResizeNormalize(object):
def __init__(self, img_width, img_height):
self.img_width = img_width
self.img_height = img_height
self.toTensor = T.ToTensor()
def __call__(self, img):
img = np.array(img)
h, w, c = img.shape
height = self.img_height
width = int(w * height / h)
if width >= self.img_width:
img = cv2.resize(img, (self.img_width, self.img_height))
else:
img = cv2.resize(img, (width, height))
img_pad = np.zeros((self.img_height, self.img_width, c), dtype=img.dtype)
img_pad[:height, :width, :] = img
img = img_pad
img = Image.fromarray(img)
img = self.toTensor(img)
img.sub_(0.5).div_(0.5)
return img
class RandomSequentialSampler(torch.utils.data.sampler.Sampler):
def __init__(self, data_source, batch_size):
self.num_samples = len(data_source)
self.batch_size = batch_size
def __iter__(self):
n_batches = len(self) // self.batch_size
tail = len(self) % self.batch_size
index = torch.LongTensor(len(self)).fill_(0)
for i in range(n_batches):
random_start = random.randint(0, len(self) - self.batch_size)
batch_index = random_start + torch.arange(0, self.batch_size)
index[i * self.batch_size:(i + 1) * self.batch_size] = batch_index
# deal with tail
if tail:
random_start = random.randint(0, len(self) - self.batch_size)
tail_index = random_start + torch.arange(0, tail)
index[(i + 1) * self.batch_size:] = tail_index
return iter(index)
def __len__(self):
return self.num_samples
class AlignCollate(object):
def __init__(self, img_height=32, img_width=100):
self.img_height = img_height
self.img_width = img_width
self.transform = ResizeNormalize(img_width=self.img_width, img_height=self.img_height)
def __call__(self, batch):
images, labels = zip(*batch)
images = [self.transform(image) for image in images]
images = torch.cat([t.unsqueeze(0) for t in images], 0)
return images, labels
def load_data(v, data):
with torch.no_grad():
v.resize_(data.size()).copy_(data)
SOS_TOKEN = 0 # special token for start of sentence
EOS_TOKEN = 1 # special token for end of sentence
class ConvertBetweenStringAndLabel(object):
"""Convert between str and label.
NOTE:
Insert `EOS` to the alphabet for attention.
Args:
alphabet (str): set of the possible characters.
ignore_case (bool, default=True): whether or not to ignore all of the case.
"""
def __init__(self, alphabet):
self.alphabet = alphabet
self.dict = {}
self.dict['SOS_TOKEN'] = SOS_TOKEN
self.dict['EOS_TOKEN'] = EOS_TOKEN
for i, item in enumerate(self.alphabet):
self.dict[item] = i + 2
def encode(self, text):
"""
Args:
text (str or list of str): texts to convert.
Returns:
torch.IntTensor targets:max_length × batch_size
"""
if isinstance(text, str):
text = [self.dict[item] if item in self.dict else 2 for item in text]
elif isinstance(text, collections.abc.Iterable):
text = [self.encode(s) for s in text]
max_length = max([len(x) for x in text])
nb = len(text)
targets = torch.ones(nb, max_length + 2) * 2
for i in range(nb):
targets[i][0] = 0
targets[i][1:len(text[i]) + 1] = text[i]
targets[i][len(text[i]) + 1] = 1
text = targets.transpose(0, 1).contiguous()
text = text.long()
return torch.LongTensor(text)
def decode(self, t):
"""Decode encoded texts back into strs.
Args:
torch.IntTensor [length_0 + length_1 + ... length_{n - 1}]: encoded texts.
torch.IntTensor [n]: length of each text.
Raises:
AssertionError: when the texts and its length does not match.
Returns:
text (str or list of str): texts to convert.
"""
texts = list(self.dict.keys())[list(self.dict.values()).index(t)]
return texts
converter = ConvertBetweenStringAndLabel(cfg.lexicon)
#模型
class CNN(nn.Module):
def __init__(self, channel_size):
super(CNN, self).__init__()
self.cnn = nn.Sequential(
nn.Conv2d(channel_size, 64, 3, 1, 1), nn.ReLU(True), nn.MaxPool2d(2, 2),
nn.Conv2d(64, 128, 3, 1, 1), nn.ReLU(True), nn.MaxPool2d(2, 2),
nn.Conv2d(128, 256, 3, 1, 1), nn.BatchNorm2d(256), nn.ReLU(True),
nn.Conv2d(256, 256, 3, 1, 1), nn.ReLU(True), nn.MaxPool2d((2,2), (2,1), (0,1)),
nn.Conv2d(256, 512, 3, 1, 1), nn.BatchNorm2d(512), nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), nn.ReLU(True), nn.MaxPool2d((2,2), (2,1), (0,1)),
nn.Conv2d(512, 512, 2, 1, 0), nn.BatchNorm2d(512), nn.ReLU(True))
def forward(self, input):
# [n, channel_size, 32, 280] -> [n, 512, 1, 71]
conv = self.cnn(input)
return conv
class BidirectionalLSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(BidirectionalLSTM, self).__init__()
self.rnn = nn.LSTM(input_size, hidden_size, bidirectional=True)
self.embedding = nn.Linear(hidden_size * 2, output_size)
def forward(self, input):
recurrent, _ = self.rnn(input)
T, b, h = recurrent.size()
t_rec = recurrent.view(T * b, h)
output = self.embedding(t_rec) # [T * b, output_size]
output = output.view(T, b, -1)
return output
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=71):
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input)
embedded = self.dropout(embedded)
attn_weights = F.softmax(self.attn(torch.cat((embedded, hidden[0]), 1)), dim=1)
attn_applied = torch.bmm(attn_weights.unsqueeze(1), encoder_outputs.permute(1, 0, 2))
output = torch.cat((embedded, attn_applied.squeeze(1)), 1)
output = self.attn_combine(output).unsqueeze(0)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]), dim=1)
return output, hidden, attn_weights
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=cfg.device)
class Encoder(nn.Module):
def __init__(self, channel_size, hidden_size):
super(Encoder, self).__init__()
self.cnn = CNN(channel_size)
self.rnn = nn.Sequential(
BidirectionalLSTM(512, hidden_size, hidden_size),
BidirectionalLSTM(hidden_size, hidden_size, hidden_size))
def forward(self, input):
# conv features
conv = self.cnn(input)
b, c, h, w = conv.size()
assert h == 1, "the height of conv must be 1"
# rnn feature
conv = conv.squeeze(2) # [b, c, 1, w] -> [b, c, w]
conv = conv.permute(2, 0, 1) # [b, c, w] -> [w, b, c]
output = self.rnn(conv)
return output
class Decoder(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=71):
super(Decoder, self).__init__()
self.hidden_size = hidden_size
self.decoder = AttnDecoderRNN(hidden_size, output_size, dropout_p, max_length)
def forward(self, input, hidden, encoder_outputs):
return self.decoder(input, hidden, encoder_outputs)
def initHidden(self, batch_size):
result = Variable(torch.zeros(1, batch_size, self.hidden_size))
return result
#utils 功能函数
#模型初始化
def weights_init(model):
# Official init from torch repo.
for m in model.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
#loss取平均
class Averager(object):
"""Compute average for `torch.Variable` and `torch.Tensor`. """
def __init__(self):
self.reset()
def add(self, v):
if isinstance(v, Variable):
count = v.data.numel()
v = v.data.sum()
elif isinstance(v, torch.Tensor):
count = v.numel()
v = v.sum()
self.n_count += count
self.sum += v
def reset(self):
self.n_count = 0
self.sum = 0
def val(self):
res = 0
if self.n_count != 0:
res = self.sum / float(self.n_count)
return res
class ocr():
def train(self):
# create train dataset
train_dataset = TextLineDataset(text_line_file=cfg.train_list, transform=None)
sampler = RandomSequentialSampler(train_dataset, cfg.batch_size)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=cfg.batch_size, shuffle=False, sampler=sampler, num_workers=4,
collate_fn=AlignCollate(img_height=cfg.img_height, img_width=cfg.img_width))
# create test dataset
test_dataset = TextLineDataset(text_line_file=cfg.eval_list,
transform=ResizeNormalize(img_width=cfg.img_width,
img_height=cfg.img_height))
test_loader = torch.utils.data.DataLoader(test_dataset, shuffle=False, batch_size=1,
num_workers=4)
# create crnn/seq2seq/attention network
encoder = Encoder(channel_size=3, hidden_size=cfg.hidden_size)
# for prediction of an indefinite long sequence
decoder = Decoder(hidden_size=cfg.hidden_size, output_size=cfg.class_num, dropout_p=0.1,
max_length=cfg.max_width)
encoder.apply(weights_init)
decoder.apply(weights_init)
# create input tensor
image = torch.FloatTensor(cfg.batch_size, 3, cfg.img_height, cfg.img_width)
text = torch.LongTensor(cfg.batch_size)
criterion = torch.nn.NLLLoss()
encoder.to(cfg.device)
decoder.to(cfg.device)
image = image.to(cfg.device)
text = text.to(cfg.device)
criterion = criterion.to(cfg.device)
# optimizer
encoder_optimizer = torch.optim.Adam(encoder.parameters(), lr=cfg.learning_rate, betas=(0.5, 0.999))
decoder_optimizer = torch.optim.Adam(decoder.parameters(), lr=cfg.learning_rate, betas=(0.5, 0.999))
# loss averager
loss_avg = Averager()
for epoch in range(cfg.epoch):
train_iter = iter(train_loader)
for i in range(len(train_loader)):
cpu_images, cpu_texts = train_iter.next()
batch_size = cpu_images.size(0)
for encoder_param, decoder_param in zip(encoder.parameters(), decoder.parameters()):
encoder_param.requires_grad = True
decoder_param.requires_grad = True
encoder.train()
decoder.train()
target_variable = converter.encode(cpu_texts)
load_data(image, cpu_images)
# CNN + BiLSTM
encoder_outputs = encoder(image)
target_variable = target_variable.cuda()
# start decoder for SOS_TOKEN
decoder_input = target_variable[SOS_TOKEN].cuda()
decoder_hidden = decoder.initHidden(batch_size).cuda()
loss = 0.0
teach_forcing = True if random.random() > cfg.teaching_forcing_prob else False
if teach_forcing:
for di in range(1, target_variable.shape[0]):
decoder_output, decoder_hidden, decoder_attention = decoder(decoder_input, decoder_hidden,
encoder_outputs)
loss += criterion(decoder_output, target_variable[di])
decoder_input = target_variable[di]
else:
for di in range(1, target_variable.shape[0]):
decoder_output, decoder_hidden, decoder_attention = decoder(decoder_input, decoder_hidden,
encoder_outputs)
loss += criterion(decoder_output, target_variable[di])
topv, topi = decoder_output.data.topk(1)
ni = topi.squeeze()
decoder_input = ni
encoder.zero_grad()
decoder.zero_grad()
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
loss_avg.add(loss)
if i % 10 == 0:
print(
'[Epoch {0}/{1}] [Batch {2}/{3}] Loss: {4}'.format(epoch, cfg.epoch, i, len(train_loader),
loss_avg.val()))
loss_avg.reset()
# save checkpoint
torch.save(encoder.state_dict(), '{0}/encoder_{1}.pth'.format(cfg.save_model_dir, epoch))
torch.save(decoder.state_dict(), '{0}/decoder_{1}.pth'.format(cfg.save_model_dir, epoch))
def infer(self):
encoder_name = cfg.test_encoder_path
decoder_name = cfg.test_decoder_path
correct = 0
transformer = ResizeNormalize(img_width=cfg.img_width, img_height=cfg.img_height)
for test_img_paths in os.listdir(cfg.test_img_paths):
test_img_path = os.path.join(cfg.test_img_paths, test_img_paths)
# image = Image.open(cfg.img_path).convert('RGB')
image = Image.open(test_img_path).convert('RGB')
image = transformer(image)
image = image.to(cfg.device)
image = image.view(1, *image.size())
image = torch.autograd.Variable(image)
encoder = Encoder(3, cfg.hidden_size)
# no dropout during inference
decoder = Decoder(cfg.hidden_size, cfg.class_num, dropout_p=0.0, max_length=cfg.max_width)
encoder = encoder.to(cfg.device)
decoder = decoder.to(cfg.device)
# encoder.load_state_dict(torch.load(cfg.encoder, map_location=map_location))
encoder.load_state_dict(torch.load(encoder_name, map_location='cuda'))
# print('loading pretrained encoder models from {}.'.format(encoder_name))
# decoder.load_state_dict(torch.load(cfg.decoder, map_location=map_location))
decoder.load_state_dict(torch.load(decoder_name, map_location='cuda'))
# print('loading pretrained decoder models from {}.'.format(decoder_name))
encoder.eval()
decoder.eval()
encoder_out = encoder(image)
max_length = 20
decoder_input = torch.zeros(1).long()
decoder_hidden = decoder.initHidden(1)
decoder_input = decoder_input.to(cfg.device)
decoder_hidden = decoder_hidden.to(cfg.device)
words, prob = self.seq2seq_decode(encoder_out, decoder, decoder_input, decoder_hidden, max_length)
# print('predict_string: {} => predict_probility: {}'.format(words, prob))
if words == test_img_paths.replace('.png', '').split('_')[1]:
correct += 1
print("model" + '\t' + "|| acc: " + str(correct / len(os.listdir(cfg.test_img_paths))) + '\n')
#解码推理
def seq2seq_decode(self,encoder_out, decoder, decoder_input, decoder_hidden, max_length):
decoded_words = []
prob = 1.0
for di in range(max_length):
decoder_output, decoder_hidden, decoder_attention = decoder(decoder_input, decoder_hidden, encoder_out)
probs = torch.exp(decoder_output)
_, topi = decoder_output.data.topk(1)
ni = topi.squeeze(1)
decoder_input = ni
prob *= probs[:, ni]
if ni == EOS_TOKEN:
break
else:
decoded_words.append(converter.decode(ni))
words = ''.join(decoded_words)
prob = prob.item()
return words, prob
if __name__ == '__main__':
myocr = ocr()
if cfg.istrain == True:
myocr.train()
if cfg.istest == True:
myocr.infer()三、结果讨论
本文对上述代码训练30个epoch测试效果,采用captcha_datasets数据集作为实验数据集,训练集:验证集:测试集=25000:10000:10000。图片内容主要是数字验证码。在本次实验中采用30次迭代测试模型效果,train-nll_loss、test-acc效果如下表所示。
| epoch | loss | val/test-acc |
| 1 | 8.233852386 | 0 |
| 5 | 4.418142796 | 0.12 |
| 10 | 0.334442675 | 0.94 |
| 15 | 0.315635592 | 0.97 |
| 20 | 0.058577325 | 0.99 |
| 25 | 0.074402176 | 0.98 |
| 30 | 0.059875246 | 0.97 |
部分识别效果图展示:

基于Encoder-Decoder结构在长文本类型效果因加入了注意力机制效果会较好,但是推理数据较CTC方案慢较多。因此也是一个速度与精度的balance。欢迎大家留言讨论,共同学习。

















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











