









1.什么是HBase
1.HBase是面向列式存储的分布式的NoSql数据库;
2.HBase底层是基于HDFS实现的,集群是通过Zookeeper管理的;
3.海量存储,快速访问。
2.什么是RowKey
RowKey与关系型数据库中的主键相似,HBase 使用 RowKey 来唯一标识某行的数据。
3.RowKey的设计原则
业务
需要满足实时查询需求
散列
避免热点数据,使数据集中在一个Region上,查询速率低。
设计的RowKey应均匀分布在各个HBase节点上。如RowKey是按系统时间戳的方式递增,RowKey的第一部分如果是时间戳的话,将造成所有新数据都在一个RegionServer堆积的热点现象,也就是通常说的Region热点问题,热点发生在大量的client直接访问集中在个别RegionServer上(访问可能是读、写或者其他操作),导致单个RegionServer机器自身负载过高,引起性能下降甚至Region不可用,常见的是发生jvm full gc或者显示Region too busy异常情况。
唯一
必须保证RowKey的唯一性,由于在HBase中数据存储是Key-Value形式。
若向HBase中同一张表插入相同RowKey的数据,则原先存在的数据会被新的数据覆盖
长度
RowKey的长度不宜过长,不宜超过16个字节,目前操作系统都是64位系统,内存8字节对齐,控制在16字节,8字节的整数倍利用了操作系统的最佳特性,hbase将部分数据加载到内存当中,如果rowkey过长,内存的有效利用率就会下降。
- 一是HBase的持久化文件HFile是按照KeyValue存储的,如果RowKey过长,比如说500个字节,1000万列数据,光是RowKey就要占用500*1000万=50亿个字节,将近1G数据,极大影响了HFile的存储效率。
- 二是缓存MemStore缓存部分数据到内存中,如果RowKey字段过长,内存的有效利用率会降低,系统无法缓存更多的数据,降低检索效率。目前操作系统都是64位系统,内存8字节对齐,控制在16字节,8字节的整数倍利用了操作系统的最佳特性。
- 不仅RowKey的长度是越短越好,而且列簇名、列名等尽量使用短名字,因为HBase属于列式数据库,这些名字都是会写入到HBase的持久化文件HFile中去,过长的RowKey、列簇、列名都会导致整体的存储量成倍增加。
3.1 散列原则的RowKey设计方法
预分区的设计
可以按照需要设计预分区的数量,预分区可以增加数据读写效率,使得读写负载均衡,防止数据倾斜,同时方便集群容灾调度region,并优化Map数量。
基于HBase的存储结构,每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。
分区规则创建
文件分区
创建splits.txt文件内容如下:
cd /export/servers/
vim splits.txt编辑内容:
aaaa
bbbb
cccc
dddd然后执行:
hbase(main):004:0> create 'staff3','partition2',
SPLITS_FILE => '/export/servers/splits.txt'手动指定
hbase(main):001:0> create 'staff','info','partition1',
SPLITS => ['1000','2000','3000','4000']使用16进制算法生成预分区
hbase(main):003:0> create 'staff2','info','partition2',
{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}样例结果:
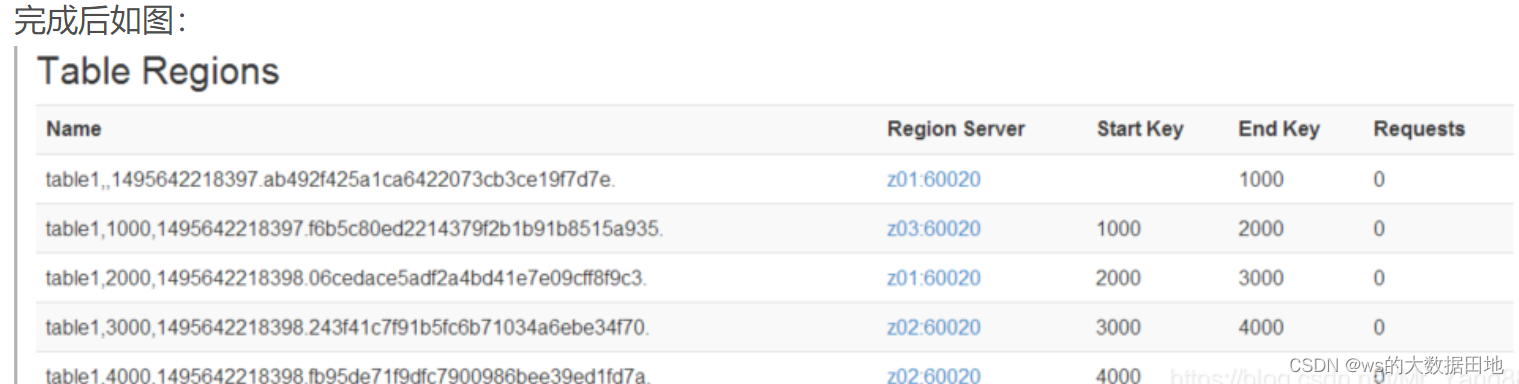
Salt加盐
在 rowkey前面加了一个随机前缀,使其不同于 rowkey之前的开头。前缀类型的分配数量应该与您希望使用数据分布到不同 region的数量一致。在加盐之后, rowkey将基于随机生成的前缀分布在各个 region上,以避免出现热点;但是由于均匀分布了,一个短扫描不能解决问题了。这是一种权衡,为了搭建成功的应用你需要做出选择。这是一个利用信息的位置来获得跨region分布的经典例子。
Hash或者Mod/MD5
目的都是散列数据,达到负载均衡,Hash和加盐区别在于前缀不是随机的,通过确定Hash,客户端可以重建完整的RowKey,直接通过get获取想要的行,也会造成全表扫描,此时会遍历所有region,耗时增加。
Reverse反转
针对固定长度的Rowkey反转后存储,这样可以使Rowkey中经常改变的部分放在最前面,可以有效的随机rowkey。例如手机号就可以使用反转。这样做的牺牲的Rowkey的有序性。
案例分析
TwiBase系统
1、背景
为了加深HBase基本概念的学习,参考HBase实战这本书实际动手做了这个例子。
2、需求
这是一个用户推特系统,用户登陆到系统,需要维护用户的基本信息,然后用户可以发帖和其他用户进行互动。用户之间可以相互关注,用户可以浏览关注用户的推文等等。
这是一个比较简单的推特系统,不考虑用户之间的私信,用户评论推特等功能。
3、概要设计
3.1表设计
首先需要设计三个表:用户表,推特表以及用户之间的关系表。
(1)用户表
用户表至少包含唯一的用户名,用户昵称,用户邮箱以及用户发帖数量,用一个列族存储。
创建用户表的语句是:
create 'users', 'info'
其中用户名用作rowkey,这样能够快速根据用户登陆ID查找到用户所有基本信息。
(2)推特表
推特表存储用户的发帖,至少包括用户名,发帖时间,以及发帖内容,用一个列族存储。
创建推特表的语句是:
create 'twits', 'twits'为了能够快速查找到指定用户的所有推文(登陆个人推特时显示),需要将同一个用户的所有推文都存储在一块,所以考虑将用户ID作为行键的第一部分,另外希望每个用户的推文按照时间有序,所以将时间戳作为行键的第二部分,但是这里有个问题,用户名是变长的,怎么知道行键中前面到哪儿是用户名呢,这个时候可以对用户名做MD5散列,将变长的用户名变为定长的散列值。
另外你希望用户显示自己的推文的时候按照时间顺序倒序排列,即读出来的推文时间新的排在前面,那么就需要利用一个小技巧,不存储真正的时间戳,而是存储倒序时间戳=Long.MAXVALUE -时间戳。所以表设计是这样的:
rowKey:MD5(用户A)+倒序时间戳#time:发帖时间,content:内容
(3)关系表
现在只有用户和推文功能,这明显不够,我们希望能够阅读其他人的推文,这就希望用户能够关注一些其他的用户。
问题:具体我们需要存储哪些关系呢?
- 用户A登陆,需要查看自己关注了谁,以及显示其关注的用户的推文,所以要存储用户A关注了谁?
- 用户A登陆,想要查看自己的粉丝,所以需要存储谁关注了用户A?
- 用户A登陆,访问用户B的推特,那么需要知道用户A有没有关注用户B?
一开始你可能会想这样设计表:
rowKey:用户A#1:用户B,2:用户C,3:用户D
rowKey:用户B#1:用户H,2:用户C
这样可以很轻松回答问题1和问题3.
但是问题2似乎很难回答,除非扫描整个表,以及每一行的所有列,否则找不出所有关注某个用户的人。
这个表设计还有一个大问题,就是当用户A关注用户B的时候,需要在用户A这一行加一列,但是我不知道现在加到哪一列了,即put数据的时候无法指定qualifier,你可能想到在每一行增加一列计数器来解决这个问题,即counter:x,但是不幸的是,HBase不支持事务操作,一旦多个客户端同时关注两个不同的用户,它们都需要取得计数器,然后插入新的一列,两个客户端很可能读到同一个计数器值,这样一个客户端的写入就会被另一个给覆盖,所以必须去掉计数器,可以用下面方式解决:
这样设计表:
rowKey:用户A#用户B:1,用户C:2,用户D:3
rowKey:用户B#用户H:1,用户C:2
到目前为止的设计还是没有高效的办法回答问题2.
上面两种设计都是“宽表”的形式,现在可以考虑使用“高表”的形式。
rowKey:用户A+分隔符+用户B#1:用户B昵称即行键存储用户A关注用户B,我们将用户B的昵称放入qualifier可以节省再去用户表找用户B的昵称的时间,这是一种反规范化(de-nomalize)处理。
这样很容易就能想到这样一个设计:
rowKey:用户A+分隔符+关注+分隔符+用户B#1:用户B昵称
rowKey:用户A+分隔符+关注+分隔符+用户C#1:用户C昵称
rowKey:用户A+分隔符+被关注+分隔符+用户D#1:用户D昵称
rowKey:用户A+分隔符+被关注+分隔符+用户H#1:用户H昵称这样很容易就可以回答上面三个问题,分别是用户A关注了谁?用户A关注了用户B?谁关注了用户A。不过要注意,当查找用户A的粉丝列表时,往往不想把用户A关注了谁这些集合也返回给客户端,这个时候可以通过为扫描设置起始和停止键来做到。
这里需要再次优化,即使用MD5对用户名进行处理,得到定长的散列值,这样做有几个好处:
1 可以抛弃掉分隔符,为扫描操作计算起始和停止键更加容易。
2 行键长度统一,可以帮助你很好地预测读写性能。
3 MD5有助于数据更加均匀地分布在region上。
所以关系表设计再次修改为这样:
rowKey:MD5(用户A)+关注+MD5(用户B)#1:用户B的昵称
rowKey:MD5(用户A)+关注+MD5(用户C)#1:用户C的昵称
rowKey:MD5(用户A)+被关注+MD5(用户D)#1:用户D的昵称
rowKey:MD5(用户A)+被关注+MD5(用户H)#1:用户H的昵称
但是这样还不是最优的,之前已经说过了,当查找用户A的粉丝列表时,往往不想把用户A关注了谁这些集合也返回给客户端,虽然可以通过为扫描设置起始和停止键来做到,但是在region server上面仍然要将这些不关心的数据从硬盘上读出来,才会经过扫描过滤。
所以考虑将被关注和关注两种类型分开,分别建立一个表,这下最终的表设计就这样了:
关注表:
rowKey:MD5(用户A)+MD5(用户B)#1:用户B的昵称
rowKey:MD5(用户A)+MD5(用户C)#1:用户C的昵称
被关注表:
rowKey:MD5(用户A)+MD5(用户D)#1:用户D的昵称
rowKey:MD5(用户A)+MD5(用户H)#1:用户H的昵称创建关系表的命令是:
create'follows', 'f'
create'followedBy', 'f'
(4)推贴流表
进一步优化 —反规范化处理!
设计HBase表的一个关键概念叫做反规范化。
截止目前为止,我们已经维护了单个用户的关注用户列表,当用户登陆账户的时候,希望看到他关注的所有人的推特,你的应用会提取关注用户列表,然后到推特表中获取每一个被关注用户的推特,然后集合这些推特按照时间排序显示出来。
随着系统用户数量增长,用户关注的用户的数量增长,这个过程会花费很长的时间。
此外,如果一个用户被许多人关注,那么当他的所有粉丝登陆的时候,他的推特都会被访问,他的推特都是物理上存放在一起的,所以托管这个受欢迎的人的推特的region将会不断回应请求,这样就制造了一个读热点。
解决这个问题的办法就是为每一个用户维护一个推特流,一旦某一个人写了推特,就将这个内容写入到关注他的人的推特流里面。这就是反规范化。
概念介绍:规范化和反规范化
规范化是关系型数据库里面的概念,每种重复信息都会放进一个自己的表,这样有两个好处:当发生更新和删除的时候,不用担心更新指定的数据的所有副本;通过保存单一副本,而不是多个副本,减少了占用的存储空间。需要查询时,使用SQL语句里面的join子句就可以轻易连接这些数据。
反规范化是一个相反的概念,数据是重复的,存储在多个地方,因为你不需要开销很大的join操作,这时候查询数据更加容易和快速。
规范化为写操作进行了优化,在读取数据时付出了连接数据的开销。
反规范化为读操作进行了优化,在写入时付出写多个副本的开销。
所以,为了为每个用户维护一个推特流,我们建立一张新表(不打算为users表增加一个列族,因为users表的行键不是为了这个目的而优化的)。
推特流表创建的命令是:
create 'twitsStream', 'info'推特流表设计是这样的:
rowKey:MD5(用户A)+倒序时间戳#1:用户B的昵称,2:推贴内容
rowKey:MD5(用户A)+倒序时间戳#1:用户D的昵称,2:推贴内容
rowKey:MD5(用户A)+倒序时间戳#1:用户H的昵称,2:推贴内容















 2849
2849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











