





Having recently graduated from a coding bootcamp, I’ve been deep into studying data structures and algorithms to better my fundamental knowledge. Linked lists are a relatively simple data structure, but is the basis for more complex data structures moving forward. This article will be discussing linked lists — their strengths, weaknesses, and how to implement them.
^ h AVING最近从编码集训毕业,我已经深入学习数据结构和算法改善自己的基础知识。 链表是一个相对简单的数据结构,但它是更复杂的数据结构向前发展的基础。 本文将讨论链接列表-它们的优点,缺点以及如何实现它们。
Data structures are, put simply, ways to organize, and hold data efficiently
简而言之,数据结构是有效组织和保存数据的方法
什么是数据结构? (What Are Data Structures?)
Data structures are, put simply, ways to organize, and hold data efficiently. These allow us to hold information so that we can access them for later — searching for a specific item, or sorting them to have a certain order or even managing large datasets. JavaScript has data structures that you’re likely very familiar with — arrays and objects. These are primitive data structures that are native to the language. Non-primitive data structures are data structures that are defined by the programmer. Examples include stacks, queues, trees, graphs, and hash tables.
简单来说,数据结构是有效组织和保存数据的方法。 这些使我们能够保存信息,以便我们以后可以访问它们-搜索特定项目,或对它们进行排序以具有特定顺序,甚至管理大型数据集。 JavaScript具有您可能非常熟悉的数据结构-数组和对象。 这些是语言固有的原始数据结构。 非原始数据结构是程序员定义的数据结构。 示例包括堆栈,队列,树,图和哈希表。
什么是链接列表? (What Are Linked Lists?)
A linked list is a linear data structure that holds elements in sequential order. Sound familiar? They’re similar to arrays but they’re not quite the same. Arrays are zero-indexed, meaning each index is mapped to a value, and the first element of the array starts at an index of 0. You can easily pull elements from the array, so long as you know the index.
链表是一个线性数据结构,按顺序保存元素。 听起来有点熟? 它们与数组相似,但并不完全相同。 数组是零索引的 ,这意味着每个索引都映射到一个值,并且数组的第一个元素从索引0开始。只要知道索引,就可以轻松地从数组中拉出元素。
On the other hand, a linked list consists of nodes that point to other nodes. Each node only knows itself and the next node. As a linear data structure, items are arranged in order. You could think about it as a train — each rail car is connected to the next rail car, and so on. Linked lists are not indexed, so you can’t access the 5th element directly. You’d have to start at the beginning, go to the next, and go to the next until you find the 5th element. The first node is called the head, and the last node is called the tail. There are various types of linked lists — singly linked list, doubly linked list, and circular linked list. For the sake of this article, I’ll be focusing on the singly linked list.
另一方面,链表由指向其他节点的节点组成。 每个节点只知道自己和下一个节点。 作为线性数据结构,项目按顺序排列。 您可以将其视为火车-每个有轨电车都连接到下一个有轨电车,依此类推。 链接列表未编制索引 ,因此您无法直接访问第5个元素。 您必须从头开始,转到下一个,然后再转到下一个,直到找到第5个元素。 第一个节点称为头,最后一个节点称为尾。 链表有多种类型-单链表,双链表和循环链表。 为了本文的方便,我将重点介绍单链列表。
Accessing elements throughout the array is easier, but that comes at a cost.
在整个数组中访问元素更加容易,但这要付出一定的代价。
为什么在数组上使用链接列表? (Why Use Linked Lists Over Arrays?)
You may be wondering — but why use this if I can access elements directly with arrays? This is true! Accessing elements throughout the array is easier, but that comes at a cost.
您可能想知道-但是如果我可以直接使用数组访问元素,为什么要使用它呢? 这是真的! 在整个数组中访问元素更加容易,但这要付出一定的代价。
Arrays are indexed — so whenever you need to remove an element from the beginning or middle, all the following indices need to be shifted. This is also true if you need to insert an element — all following elements need to be reindexed. When inserting or removing elements from a linked list, you don’t need to reindex — all it cares about are the node it points to.
数组已建立索引 -因此,当您需要从开头或中间删除元素时,以下所有索引都需要移位。 如果您需要插入一个元素,则也是如此-所有后续元素都需要重新索引。 从链接列表中插入或删除元素时,您无需重新索引-它关心的只是它指向的节点。
实施单链接列表 (Implementing a Singly Linked List)
There are various types of linked lists — singly, doubly, and circular. Singly linked lists are what we will be focusing on today. Singly linked lists are a type of linked list where each node has a value and a pointer to the next node (null if it’s the tail node). Doubly linked lists, on the other hand, have an additional pointer to the previous node. Circular linked lists are where the tail node points back to the head node.
链表有多种类型-单,双和循环。 单链列表是我们今天要关注的重点。 单链表是链表的一种,其中每个节点都有一个值和一个指向下一个节点的指针(如果是尾节点则为null)。 另一方面,双链表还有一个指向前一个节点的指针。 循环链表是尾节点指向头节点的位置。
Note: If you‘re a visual learner, VisuAlgo is a great place to play around and see the data structure go through changes.
注意:如果您是视觉学习者, VisuAlgo 是一个很好的玩耍的地方,可以看到数据结构不断变化。
If you want to skip ahead for the complete code: checkout this GitHub gist.
如果您想跳过完整的代码,请查看此GitHub gist 。
创建一个节点 (Creating a Node)
class Node {
constructor(val) {
this.val = val;
this.next = null;
}
}创建SinglyLinkedList类 (Create SinglyLinkedList Class)
We’ll begin by building a class called SinglyLinkedList and give it a basis for the head, tail, and the length of the list.
我们将从构建一个名为SinglyLinkedList的类开始,并为它提供列表的头,尾和长度的基础。
class SinglyLinkedList {
constructor() {
this.head = null;
this.tail = null;
this.length = 0;
}
}将节点添加到末端 (Adding Node to the End)
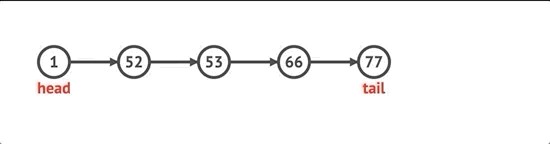
For adding a node to the end, we’ll check if there is a head already declared on the list. If not, set the head and tail to be the newly created node. If there already is a head property, set the next property on the tail to the new node, and the tail to be the new node. We’ll increment length by 1.
为了将节点添加到末尾,我们将检查列表上是否已经声明了一个头。 如果不是,则将头和尾设置为新创建的节点。 如果已经有头属性,则将尾部的下一个属性设置为新节点,并将尾部设置为新节点。 我们将长度增加1。
push(val) {
var newNode = new Node(val)
if (!this.head) {
this.head = newNode
this.tail = newNode
} else {
this.tail.next = newNode
this.tail = newNode
}
this.length++;
return this;
}最终删除节点 (Removing Node at the End)
For removing a node at the end, we must first check if there are no nodes in the list. If there are nodes, then we have to loop through the list until we reach the tail. We’ll set the next property of the second to last node to be null, set the tail to the second to last node, decrement the length by 1, and return the value of the removed node.
为了最后删除一个节点,我们必须首先检查列表中是否没有节点。 如果有节点,那么我们必须遍历列表直到到达尾部。 我们将倒数第二个节点的next属性设置为null,将拖尾设置为倒数第二个节点,将长度减1,然后返回删除的节点的值。
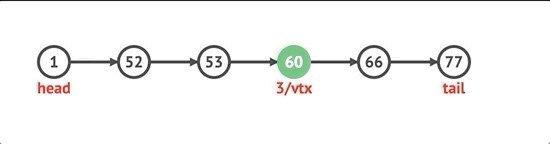
pop() {
if (!this.head) return undefined;
var current = this.head
var newTail = current
while (current.next) {
newTail = current
current = current.next;
}
this.tail = newTail;
this.tail.next = null;
this.length--;
if (this.length === 0) {
this.head = null;
this.tail = null;
}
return current;
}从一开始就删除节点 (Removing Node from the Beginning)
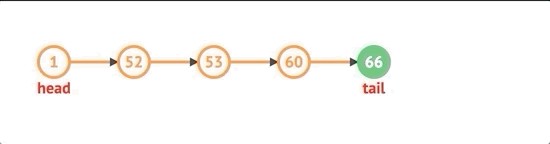
To remove the node from the beginning, we check if there are nodes in the list. We’ll store the current head property in a variable, and set the head to be the current head’s next node. Decrement the length by 1 and return the value of the node removed.
要从头开始删除节点,我们检查列表中是否有节点。 我们将当前head属性存储在变量中,并将head设置为当前head的下一个节点。 将长度减1,然后返回删除的节点的值。
shift() {
if (!this.head) return undefined
var oldHead = this.head;
this.head = oldHead.next;
this.length--
if (this.length===0) {
this.head = null;
this.tail = null;
}
return oldHead
}将节点添加到开头 (Add Node to the Beginning)
To add a node to the beginning, we first create the node and check if there is a head property on the list. If so, set the next property of the newly created node to the current head, set head to the new node, and increment the length.
要将节点添加到开头,我们首先创建该节点并检查列表中是否有head属性。 如果是这样,请将新创建的节点的下一个属性设置为当前头,将头设置为新节点,然后增加长度。
unshift(val) {
var newNode = new Node(val)
if (!this.head) {
this.head = newNode;
this.tail = newNode;
} else {
newNode.next = this.head;
this.head = newNode;
}
this.length++
return this
}根据位置获取节点 (Get Node Based on Position)
To access a node based on its position in the list, we’ll first check if the index is a value index. After, we’ll loop through the list, while keeping a counter variable. Once the counter variable matches the index, we’ll return the found node
要基于节点在列表中的位置访问节点,我们将首先检查索引是否为值索引。 之后,我们将遍历该列表,同时保留一个计数器变量。 一旦计数器变量与索引匹配,我们将返回找到的节点
get(idx) {
if (idx < 0 || idx >= this.length) return null
var counter = 0;
var current = this.head
while (counter !== idx) {
current = current.next;
counter++;
}
return current;
}更改节点值 (Change Value of Node)
To change a node’s based on its position, we first find the node, using the get method and set the value to the new value.
要根据其位置更改节点的位置,我们首先使用get方法查找该节点并将其值设置为新值。
set(idx, val) {
var foundNode = this.get(idx)
if (foundNode) {
foundNode.val = val
return true;
}
return false;
}插入一个节点(在中间) (Insert a Node (in the middle))
To insert a node, we first check the index. If it’s equal to 0, we use our unshift method, if it’s equal to the length, we push it onto the list. Otherwise, we’ll get the before node by using the get method at one less than the index. Essentially, we need to keep track of the node before and after the selected index to ensure our pointers are directed toward the correct node.
要插入一个节点,我们首先检查索引。 如果等于0,则使用unshift方法;如果等于长度,则将其推入列表。 否则,我们将通过使用get方法(比索引少一号)来获得before节点。 本质上,我们需要跟踪所选索引之前和之后的节点,以确保我们的指针指向正确的节点。
insert(idx, val) {
if (idx < 0 || idx > this.length) return false;
if (idx === 0) {
this.unshift(val)
return true;
};
if (idx === this.length) {
this.push(val);
return true;
};
var newNode = new Node(val);
var beforeNode = this.get(idx-1);
var afterNode = beforeNode.next;
beforeNode.next = newNode;
newNode.next = afterNode;
this.length++;
return true;
}根据位置删除节点 (Remove a Node Based on Position)
To remove a node based on position, we’ll use our get method again, and use the same principle that we used for inserting a node. By keeping track of the node previous to the chosen index, we can maneuver our pointers.
要基于位置删除节点,我们将再次使用get方法,并使用与插入节点相同的原理。 通过跟踪所选索引之前的节点,我们可以操纵指针。
remove(idx) {
if (idx < 0 || idx > this.length) return undefined;
if (idx === this.length-1) {
this.pop()
}
if (idx === 0) {
this.shift()
}
var prevNode = this.get(idx-1)
var removeNode = prevNode.next
prevNode.next = removeNode.next
this.length--;
return removeNode;
}To see the complete code: checkout this GitHub gist.
要查看完整的代码,请查看GitHub gist 。
链表的优点 (Strengths of Linked Lists)
The benefit of using a linked list is the ability to quickly insert and remove elements. Because linked lists aren’t indexed, inserting elements is relatively quick and easy.
使用链接列表的好处是能够快速插入和删除元素。 由于未对链表进行索引,因此插入元素相对较快且容易。
Adding to the end of the linked list simply requires the old tail to point to the new node, and the tail to be set to the new node. Adding to the beginning of the linked list is the same premise, but the new node points to the old head, and the head is set to the new node. Fundamentally same actions, so insertion is O(1).
添加到链表的末尾仅需要将旧尾部指向新节点,并将尾部设置为新节点。 添加到链表的开头是相同的前提,但是新节点指向旧的头部,并且头部设置为新节点。 动作基本相同,因此插入值为O(1)。
Note: Inserting in the middle of a linked list, requires searching through to find your node (O(N)) and then inserting the node (O(1)).
注意:要插入链表的中间,需要进行搜索以找到您的节点(O(N)),然后插入该节点(O(1))。
Removing a node from the linked list can be easy… but also not. This depends on where. Removing a node from the beginning of the list is simple — the node after the old head becomes the new head, and we set the next pointer of the old head to null. Removing from the end is trickier because this requires going through the whole list and stopping at the node before the tail node. Worst-case O(N), and best case O(1).
从链表中删除一个节点很容易,但并非如此。 这取决于哪里。 从列表的开头删除节点很简单-旧头之后的节点变为新头,我们将旧头的下一个指针设置为null。 从末尾删除比较麻烦,因为这需要遍历整个列表并在尾节点之前的节点处停止。 最差情况O(N)和最佳情况O(1)。
链表的弱点 (Weaknesses of Linked Lists)
Weaknesses of a linked list are caused by its lack of reindexing. Because you cannot access elements directly, it makes searching and accessing elements harder.
链表的弱点是由于缺少重新索引。 由于您不能直接访问元素,因此使搜索和访问元素变得更加困难。
Searching & Accessing a node in a linked list requires starting at the beginning of the list and following the trail of breadcrumbs down the list. If we’re searching for the node at the end of the list, we will have to go through the whole linked list, effectively making time complexity O(N). As the list grows, the number of operations grows. An array allows random access — so it takes constant time to access an element.
搜索和访问链接列表中的节点需要从列表的开头开始,然后沿着面包屑的路径沿着列表向下。 如果要搜索列表末尾的节点,则必须遍历整个链接列表,从而使时间复杂度为O(N)。 随着列表的增加,操作的数量也会增加。 数组允许随机访问-因此访问元素需要花费固定的时间。
而已! (That’s it!)
Linked lists are great alternatives to arrays when insertion and deletion at the beginning are key actions. Arrays are indexed, while linked lists are not. Linked lists are also the foundational data structure that stacks and queues are built off of, which I will be discussing in a later article. If you made it all the way here, kudos to you and I hope you learned a little nugget along with your programming journey!
当开始时插入和删除是关键操作时,链表是数组的理想选择。 数组已建立索引,而链表未建立索引。 链接列表也是构建堆栈和队列的基础数据结构,我将在以后的文章中进行讨论。 如果您在这里一路走好,对您感到很荣幸,希望您在编程过程中学到了一点点知识!
翻译自: https://medium.com/@joanna_lin/so-tell-me-about-linked-lists-4d1335334d4a















 4749
4749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}