





blender
We have been looking into Facebook’s open-sourced conversational offering, Blender Bot.
我们一直在研究Facebook的开源对话产品Blender Bot。
In Part-1 we went over in detail about the DataSets used in the pre-training and fine-tuning of it and the failure cases as well as limitations of Blender.
在第1部分中,我们详细介绍了用于数据集的预训练和微调中使用的数据集以及失败案例以及Blender的局限性。
And in Part-2 we studied the more generic problem setting of “Multi-Sentence Scoring”, the Transformer architectures used for such a task and learnt about the Poly-Encoders in particular — which will be used to provide the encoder representations in Blender.
在第2部分中,我们研究了“多句子评分”的更通用的问题设置,用于此任务的Transformer体系结构,并特别了解了Poly-Encoders —将用于在Blender中提供编码器表示。
In this 3rd and final part, we return from our respite with Poly-Encoders, back to Blender. We shall go over the different Model Architectures, their respective training objectives, the Evaluation methods and performance of Blender in comparison to Meena.
在第3部分(也是最后一部分)中,我们从使用Poly-Encoders的暂缓中返回到Blender。 与Meena相比,我们将介绍不同的模型体系结构,它们各自的培训目标,Blender的评估方法和性能。
模型架构: (Model Architectures:)
The paper (Ref.[2]) discusses several variations of models, that vary in multiple factors (we’ll later discuss more on the perturbations involved). But at a high level, there are 3 different model architectures discussed.
论文(参考文献[2])讨论了模型的几种变化,这些变化在多个因素中变化(我们稍后将讨论所涉及的扰动)。 但在较高级别上,讨论了3种不同的模型架构。
- Retriever 寻回犬
- Generator 发电机
- Retrieve & Refine 检索和细化
1.检索器: (1. Retriever:)
Given a dialogue history (context) as input, retrieval systems select the next dialogue utterance by scoring a large set of candidate responses and output the highest scoring one. This is the exact same setting that we saw in the Multi-Sentence Scoring task using a Poly-Encoder, in Part-2 of this series. Two variations of the models are developed: with 256M and 622M parameters. The training objective here is to effectively rank the candidate responses. This is done by minimizing the Cross-Entropy loss, whose logits are given as:
给定对话历史记录(上下文)作为输入,检索系统将通过对大量候选响应进行评分来选择下一个对话话语,并输出评分最高的一个。 这与本系列第2部分中使用Poly-Encoder的Multi-Sentence评分任务中看到的设置完全相同。 该模型的两个变体被开发出来:具有256M和622M参数。 这里的培训目标是对候选答案进行有效排名。 这是通过最小化交叉熵损失来完成的,其对数为:

where each ‘s’ is a score between the context embedding and one of the candidate responses’ embedding. The score can be a standard dot product similarity score between the context and candidate label encoder representations (when projected onto a common vector space), or more generally any non-linear function. Score can be given as:
其中每个“ s”是上下文嵌入和候选响应之一嵌入之间的分数。 分数可以是上下文和候选标签编码器表示形式(当投影到公共向量空间上时)之间的标准点积相似性分数,或更一般地是任何非线性函数。 分数可以表示为:

The encoder representations of the context and candidate response are obtained using a Poly-Encoder — that undergoes 3 types of Attention mechanisms: 1) Self-Attention among the token embeddings of the Input context, 2) Learn ‘m’ codes by performing Self-Attention between the codes and the outputs of the previous Self-Attention, 3) Self-Attention between candidate embedding and ‘m’ global learned features. (Read Part-2 for an in-depth explanation).
上下文和候选响应的编码器表示是使用Poly-Encoder进行的,它经历了3种类型的注意力机制:1)输入上下文的令牌嵌入中的自我注意; 2)通过执行自我-学习“ m”代码代码与先前自我注意的输出之间的注意,3)候选嵌入和“ m”个全局学习特征之间的自我注意。 (有关详细说明,请参阅第2部分)。
2.发电机: (2. Generator:)
Here we use a standard Seq2Seq Transformer (Decoder) architecture to generate responses rather than retrieve them from a fixed set of candidates. Three variations of the model are developed with: 90M, 2.7B and 9.4B parameters.
在这里,我们使用标准的Seq2Seq变压器(Decoder)体系结构来生成响应,而不是从固定的候选集中检索响应。 使用以下参数开发了该模型的三个变体:90M,2.7B和9.4B参数。
最大似然估计: (Maximum Likelihood Estimation:)
The training objective here is Maximum Likelihood Estimation — that is to minimize the negative log likelihood.
这里的训练目标是最大似然估计-即最大程度地降低对数对数可能性。
The Likelihood models the overall sequence probability distribution. The objective as given in the paper (Ref.[2]):
似然模型对总体序列概率分布进行建模。 该文件中给出的目标(参考文献[2]):

where the likelihood is the probability of generating the token y_t at the time step ‘t’ given the input context ‘x’ and the tokens that were generated up to the time step ‘t’ (y_<t). The gold next utterance ‘y’ refers to the ground-truth next utterance provided by humans, given the context.
其中,可能性是在给定输入上下文“ x ”的情况下,在时间步长“ t”处生成令牌y_t的概率,以及在时间步长“ t”之前生成的令牌的概率(y_ <t)。 下一语的金语“ y ”是指在给定上下文的情况下人类提供的真实的下一语语。
不喜欢 (Un-Likelihood:)
In addition to maximizing the likelihood of getting the ground-truth token ‘y’ at time step ‘t’, here, we also try to minimize the probability of getting certain negative candidate tokens at that time step. This is called the Un-Likelihood objective and it helps decrease the occurrences of tokens (or n-grams) that are repeated. The Un-likelihood objective as given in the paper (Ref.[2]):
除了使在时间步长“ t”获得地面真实令牌“ y”的可能性最大化之外,这里,我们还尝试最小化在该时间步长获得某些否定候选令牌的可能性。 这称为非喜好目标,它有助于减少重复出现的标记(或n-gram)的出现。 该论文给出的不可能性目标(参考文献[2]):

But how can we get the set of negative candidates at every time step ‘t’? Either we can maintain a static list of negative candidates (frequent n-grams generated by the model) and use the same at every time step. Or the more acceptable solution is where we keep the n-gram distribution of the tokens generated by the model at every time step. From this, whenever an n-gram count is greater than the corresponding n-gram count observed from the gold responses (that is, frequent n-grams used by humans), then we add that n-gram to the set of negative candidates maintained at that time step.
但是,如何在每个“ t”步获得否定候选集? 我们可以维护一个否定候选者的静态列表(该模型生成的频繁n-gram),并在每个时间步使用相同的列表。 或者更可接受的解决方案是,我们在每个时间步长保持模型生成的令牌的n元语法分布。 据此,每当一个n-gram计数大于从黄金React中观察到的相应n-gram计数(即人类频繁使用的n-gram)时,我们便将该n-gram添加到所维护的否定候选集中在那个时候。
解码:波束搜索: (Decoding: Beam Search:)
At the time of inferencing, the model has to select the best next response from among the available hypotheses, given an input context. This is called “Decoding”. The output (next response) is generated as a probability distribution over all the tokens of the vocabulary. Instead of taking the highest probability token at each time step (which is nothing but the “Greedy Search”), we can try to get the partial sentence that maximizes the joint probability up to that instant.
在进行推断时,给定输入上下文,模型必须从可用假设中选择最佳的下一个响应。 这称为“解码”。 输出(下一个响应)被生成为词汇表所有标记上的概率分布。 与其在每个时间步上获得最高概率标记(这只是“贪婪搜索”而已),我们可以尝试获得在该瞬间使联合概率最大化的部分句子。
- In “Beam Search”, at each time step ‘t’, keep in memory, a list of top k partially formed hypotheses — whose joint probability is the maximum up to that time step. 在“ Beam Search”中,在每个时间步“ t”处,记忆列表中前k个部分形成的假设的列表-联合概率是该时间步之前的最大值。
- Then at time t, append each token in the vocabulary to each of the top k hypotheses. 然后在时间t,将词汇表中的每个标记附加到前k个假设中。
- Compute the new joint probability. 计算新的联合概率。
- Can also normalize the score by the length of the sequence formed so far up to time t. 也可以通过到目前为止直到时间t为止形成的序列的长度对分数进行归一化。
- Rank the hypothesis based on the joint probability score and then select the top k from among the new set of hypothesis. The remaining hypotheses are discarded. 根据联合概率评分对假设进行排序,然后从新的假设集合中选择前k个。 其余的假设将被丢弃。
- In order to enforce a stopping condition, the <EOS> (End Of Sentence) token is also included in the vocabulary. So the procedure can be stopped when enough number of <EOS> tokens are reached. 为了强制停止条件,词汇表中还包含了<EOS>(句子结束)令牌。 因此,当达到足够数量的<EOS>令牌时,可以停止该过程。
However, beam search heuristic has traditionally resulted in generating shorter responses — than actual human responses — therefore tend to be dull and less engaging. So we introduce a minimum length constraint — such that the <EOS> token will not be generated until we have partial hypotheses that satisfy a minimum length. This forces the model to generate long responses. Even though longer responses are considered more engaging (during human evaluation), they are also prone to more errors. So the minimal response length is a trade-off.
然而,传统上,波束搜索试探法产生的响应比实际的人类响应短,因此趋于乏味且不那么吸引人。 因此,我们引入了最小长度约束 -直到只有满足最小长度的部分假设时,才会生成<EOS>令牌。 这迫使模型产生较长的响应。 尽管较长的响应被认为更具吸引力(在人工评估过程中),但它们也容易出错。 因此,最小响应长度是一个折衷。
Another improvement that can be done in Beam Search is n-gram beam blocking. If a hypothesis in a beam contains more than 1 occurrence of an n-gram => that hypothesis is discarded. This is done to avoid repetition of sub-sequences or n-gram sequences.
波束搜索中可以完成的另一项改进是n-gram波束阻塞 。 如果波束中的假设包含一个n-gram的出现次数大于1,则该假设被丢弃。 这样做是为了避免子序列或n-gram序列的重复。
3.检索和优化: (3. Retrieve & Refine:)
The Retriever model gets the next response from a limited set of candidate responses and uses only the Input Context as its knowledge. The Generator model has no limitations on the candidate responses, but still no additional knowledge is used other than the context, in order to generate the next response. In the third alternative, external knowledge is incorporated into the model giving rise to => Retrieval before Generation.
检索模型从一组有限的候选响应中获取下一个响应,并且仅使用输入上下文作为其知识。 生成器模型对候选响应没有任何限制,但是除了上下文以外,没有其他知识可用于生成下一个响应。 在第三种选择中,将外部知识合并到模型中,从而在生成之前进行=> 检索 。
对话框检索: (Dialog Retrieval:)
For a given Input Context, the Retrieval system (Poly-Encoder) gets the most probable next response from a fixed set of candidate responses. This is marked as “Retrieved Next Response” in the animation above. In the “Retriever” model, we stop at this point. But here, the response is appended to the Input Context via a separator and this combined sequence is fed as input to the Generator (Decoder block). The decoder generates a response for the given input sequence. The purpose of doing this is to improve the quality of responses that the generator could produce. Remember that the Candidate Labels are human generated responses. And even though the “Retrieved Next Response” need not be the same as the “golden response” for a given input context, we can assume that a good retriever will pick a candidate that closely aligns with the golden response. And human responses are generally considered to be more engaging than decoder generated responses. And the purpose here is for the Decoder to somehow learn when to simply use the “Retrieved Next Response” directly, without making any effort to generate anything on its own; and when to ignore the retrieved response and generate one based only on the context. And if the Decoder is able to learn this association it will be able to generate more human-like responses.
对于给定的输入上下文,检索系统(Poly-Encoder)从固定的一组候选响应中获取最可能的下一个响应。 在上面的动画中,这被标记为“检索到的下一个响应”。 在“检索器”模型中,我们到此为止。 但是在这里,响应通过分隔符附加到输入上下文中,并将此组合序列作为输入提供给生成器(解码器块)。 解码器生成给定输入序列的响应。 这样做的目的是提高发生器可能产生的响应的质量。 请记住,候选标签是人工生成的响应。 即使对于给定的输入上下文,“检索到的下一个响应”不必与“黄金响应”相同,但我们可以假设一个好的检索者会选择一个与黄金响应紧密匹配的候选对象。 人们通常认为,人的React比解码器生成的React更具吸引力。 此处的目的是让解码器以某种方式学习何时直接使用“检索的下一个响应”,而无需花费任何精力自行生成任何内容; 以及何时忽略检索到的响应并仅基于上下文生成响应。 而且,如果解码器能够学习这种关联,那么它将能够生成更多类似人类的响应。
Training Objective: alpha — blending: The ideal learning for the Decoder would be to simply use the retrieved response when it’s good and ignore it when it’s not. But in reality, more often than not, the Decoder would choose to ignore the retrieved next response and generate on its own. This is attributed to the fact alluded in the previous paragraph: the lack of understanding of the relationship between the retrieved response and the golden (human) response given the input context. To mitigate this, we do “alpha — blending”, where the retrieved next response is replaced with the golden response “alpha” % of the time. This is nothing but the more generic idea of “Teacher Forcing”.
培训目标:alpha-混合:解码器的理想学习方法是,在良好的情况下简单地使用检索到的响应,而在不好的情况下忽略它。 但是实际上,解码器通常会选择忽略检索到的下一个响应并自行生成。 这归因于上一段中提到的事实:在给定输入上下文的情况下,对检索到的响应与金色(人类)响应之间的关系缺乏了解。 为了缓解这种情况,我们进行了“ alpha-混合”,其中检索到的下一个响应被黄金响应“ alpha”%的时间所代替。 这不过是“教师强迫”的更笼统的想法。
知识检索: (Knowledge Retrieval:)
In this variant, an external knowledge base is used. An Information Retrieval (IR) System is built to store and retrieve the Wikipedia dump. A little aside on how the IR system works:
在此变体中,使用了外部知识库。 建立了一个信息检索(IR)系统来存储和检索Wikipedia转储。 关于IR系统的工作原理,有一点地方:
- The documents (Wikipedia articles in this case) are parsed and an inverted index is built that is of the form — {term: list of all documents in which the term appears}. 解析文档(在这种情况下为Wikipedia文章),并建立一个倒排索引,其格式为-{term:出现该术语的所有文档的列表}。
- The inverted index can be searched by the “Query” and the output is the list of documents that contain any of the query terms. 反向索引可以通过“查询”进行搜索,输出是包含任何查询词的文档列表。
- Then we rank the documents thus returned by finding the similarity between the query and the document, both represented in a common vector space — whose coordinates are the TF-IDF scores of the terms in the query/document. 然后,我们通过查找查询和文档之间的相似性来对由此返回的文档进行排名,这两者都在一个公共向量空间中表示-它们的坐标是查询/文档中术语的TF-IDF分数。
Back to our Knowledge Retrieval System, the Input Context is used as the “Query” into the IR System in order to retrieve the most suitable Knowledge Candidates (i.e. Wiki articles that are relevant to the context). These candidates and the context are fed to the Retrieval system (Poly-Encoder) to get the best candidate — that is the best piece of external knowledge, on which our dialog next response is going to be based. This knowledge candidate is then given as input to the Generator model, that generates the next response conditioned on the knowledge sentence.
回到我们的知识检索系统,输入上下文用作对IR系统的“查询”,以便检索最合适的知识候选者(即与该上下文相关的Wiki文章)。 这些候选者和上下文被馈送到Retrieval系统(Poly-Encoder)以获得最佳候选者-这是最好的外部知识,我们的对话下一个响应将基于此。 然后将此知识候选者作为输入提供给生成器模型,该生成器模型生成以知识句子为条件的下一个响应。
评估方法: (Evaluation Methods:)
自动评估: (Automatic Evaluation:)
Retrieval Models: The Retrieval models are fine-tuned on the crowd-sourced clean Data Sets that we talked about in Part-1, namely, ConvAI2, ED, Wizard of Wikipedia and BST. The evaluation metric reported is Hits@1/K (which is similar in principle to the Top@N classification metric), on the corresponding dataset’s validation data.
检索模型:检索模型在我们在第1部分中讨论过的基于众包的干净数据集上进行了微调,这些数据集分别是ConvAI2,ED,Wikipedia向导和BST。 在相应数据集的验证数据上,报告的评估指标为Hits @ 1 / K(原则上与Top @ N分类指标相似)。

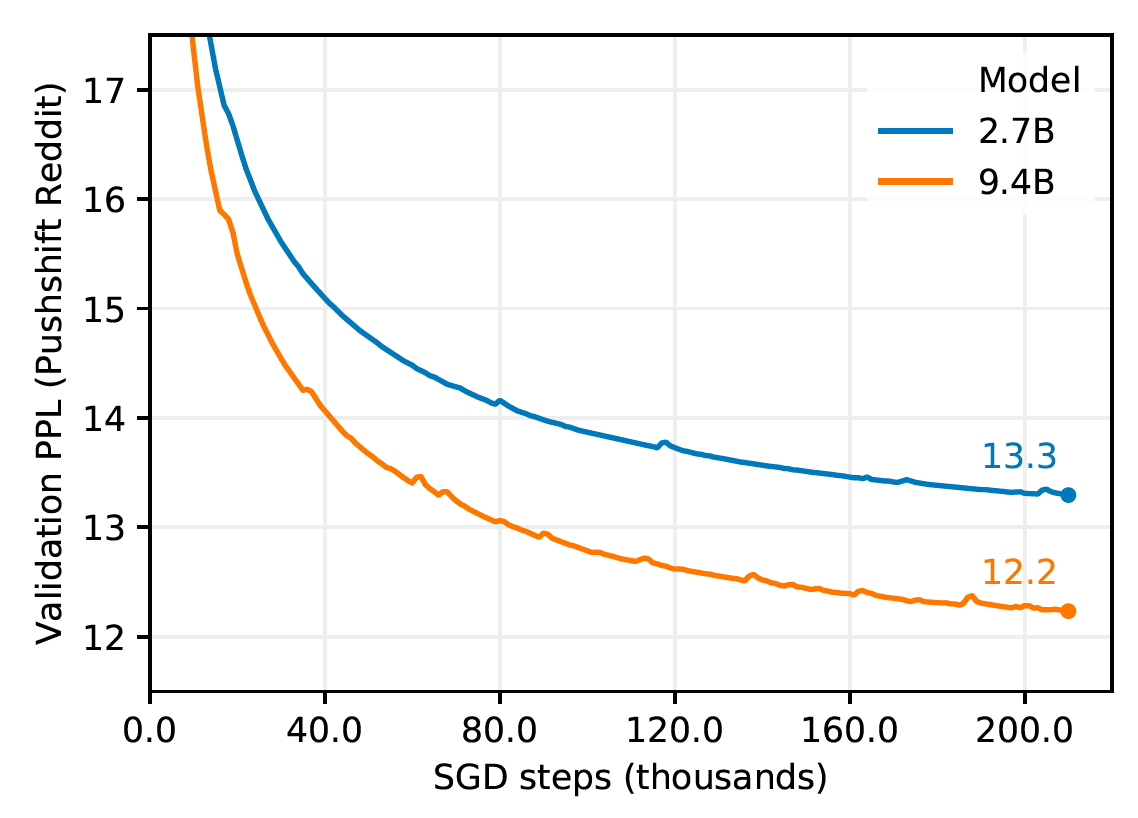
Generator Models: Here we measure the perplexity of the underlying language model. Perplexity measures the uncertainty of a language model. The lower the perplexity, the more confident the model is in generating the next token (character, subword, or word). Conceptually, perplexity represents the number of choices the model is trying to choose from when producing the next token. From the graph below, we see that the larger model achieves a better performance in fewer steps.
生成器模型:在这里,我们测量基础语言模型的复杂性。 困惑度衡量语言模型的不确定性。 困惑度越低,模型就越有信心生成下一个标记(字符,子词或单词)。 从概念上讲,困惑度表示模型在生成下一个令牌时试图从中进行选择的数量。 从下图可以看出,较大的模型以较少的步骤实现了更好的性能。
人工评估: (Human Evaluation:)
This kind of evaluation gives the leverage to arrive at comparisons between different versions of Blender as well as comparison between other chatbots in the field — as these chat logs are available in public domain for analysis purposes. Many different versions of Blender have been developed based on multiple factors like:
这种评估提供了杠杆作用,可用于在Blender的不同版本之间进行比较以及在该领域中其他聊天机器人之间进行比较-因为这些聊天日志可在公共领域中用于分析目的。 基于多种因素开发了Blender的许多不同版本,例如:
- Minimum beam length while using beam search in the generator models 在生成器模型中使用波束搜索时的最小波束长度
- Whether or not n-gram beam blocking is done 是否完成了n克光束遮挡
- Smaller vs larger models (in terms of number of parameters learnt) 较小模型与较大模型(根据学习的参数数量)
- Whether a persona context was given or no persona context was given (during fine-tuning) 是否提供了角色环境(微调期间)
- Using likelihood vs. combination of likelihood and unlikelihood 使用似然性与似然性和可能性的组合
- etc. 等等
Human evaluations were done for all kinds of variants and the detailed results are given in the paper (Ref.[2]), where you can go over them.
对各种变体进行了人工评估,并在论文中提供了详细的结果(参考文献[2]),您可以在其中进行介绍。
ACUTE Eval:
急性评估:
In this method, human evaluators are given pairs of complete conversations between a human and a chatbot. These conversations are generated by the 2 models/systems that are up for comparison. And the job of the evaluator is to compare the two dialogues and answer the following questions, as given in Ref.[2]:
在这种方法中,人类评估者可以在人类和聊天机器人之间获得一对完整的对话。 这些对话是由两个可供比较的模型/系统生成的。 评估者的工作是比较两种对话并回答参考文献[2]中给出的以下问题:
- Engagingness question: “Who would you prefer to talk to for a long conversation?” 参与性问题:“您想和谁进行长时间的交谈?”
- Humanness question: “Which speaker sounds more human?” 人性问题:“哪个说话者听起来更人性化?”
Self-Chat ACUTE Eval:
自聊天急性评估:
This is the same type of evaluation as above, except that the conversations evaluated are between 2 models, instead of a human and a model.
这与上面的评估类型相同,除了评估的对话是在两个模型之间进行的,而不是人与模型之间。
A sample conversation pair as presented for a human evaluator is given below:
为人类评估者提供的示例对话对如下:

比较: (Comparisons:)
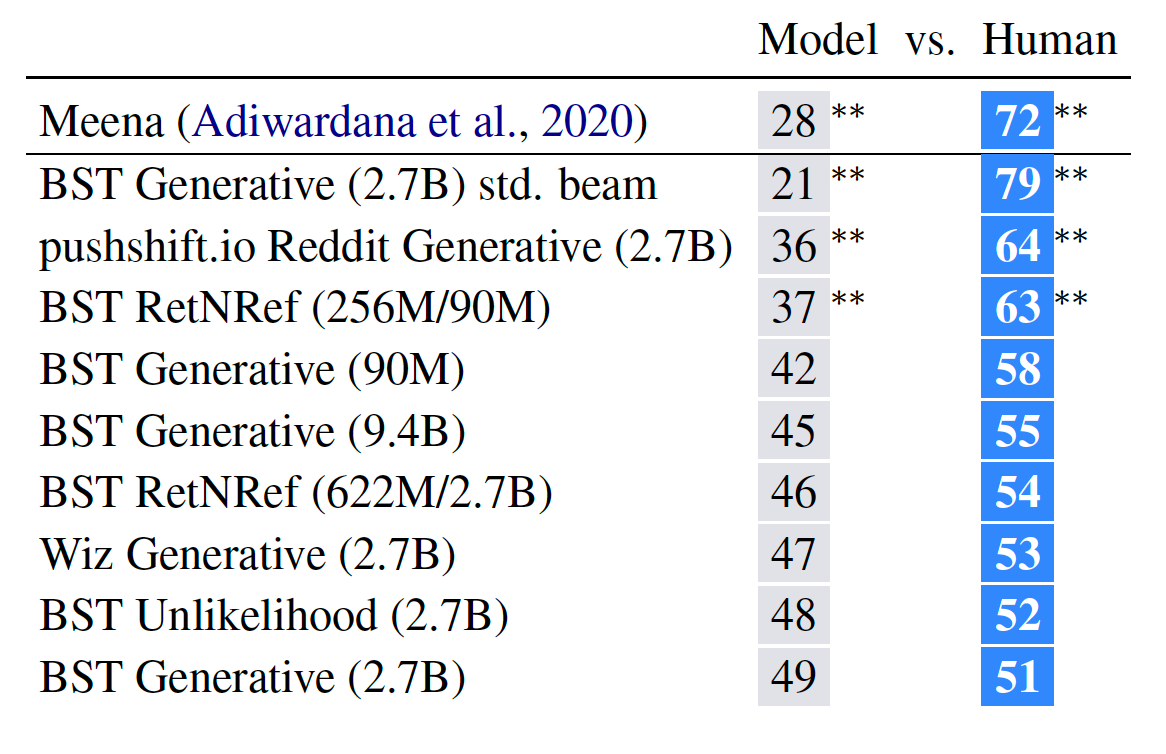
Finally, I’ll leave you with the human evaluation scores for Blender (and its variants) and Meena; as well as Blender and Humans — as reported in Ref.[2].
最后,我将为您提供Blender(及其变体)和Meena的人工评估分数; 以及Blender和Humans-如参考文献[2]中所述。
Blender诉Meena: (Blender v. Meena:)

Blender诉Human: (Blender v. Human:)
The Blender paper is quite long and packed with information and it becomes easy to get bogged down by the details. The purpose of writing this series of posts is, basically, to be able to think out loud — identify and make the individual concepts and pieces more understandable, all the while maintaining the bigger picture as well as the ability to zoom into the specifics if required.
Blender纸很长,并且充满信息,很容易被细节所困扰。 基本上,撰写这一系列文章的目的是能够大声思考-识别并使各个概念和片段更易于理解,同时保持更大的画面以及根据需要放大特定内容的能力。 。
翻译自: https://towardsdatascience.com/blender-bot-part-3-the-many-architectures-a6ebff0d75a6
blender















 5264
5264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









