





算法偏见是什么
After the end of the Second World War, the Nuremberg trials laid bare the atrocities conducted in medical research by the Nazis. In the aftermath of the trials, the medical sciences established a set of rules — The Nuremberg Code — to control future experiments involving human subjects. The Nuremberg Code has influenced medical codes of ethics around the world, as has the exposure of experiments that had failed to follow it even three decades later, such as the infamous Tuskegee syphilis experiment.
第二次世界大战结束后,纽伦堡的审判揭露了纳粹在医学研究中进行的暴行。 在试验之后,医学界建立了一套规则-《纽伦堡守则》,以控制未来涉及人类受试者的实验。 纽伦堡守则(Nuremberg Code)影响了世界各地的医学道德守则,甚至在三十年后仍未遵循该守则的实验的曝光,例如臭名昭著的塔斯基吉梅毒实验 。
The direct negative impact of AI experiments and applications on users isn’t quite as inhumane as that of the Tuskegee and Nazi experimentations, but in the face of an overwhelming and growing body of evidence of algorithms being biased against certain demographic cohorts, it is important that a dialogue takes place sooner or later. AI systems can be biased based on who builds them, the way they are developed, and how they’re eventually deployed. This is known as algorithmic bias.
AI实验和应用程序对用户的直接负面影响并不像Tuskegee和Nazi实验那样不人道,但是面对越来越多的越来越多的证据表明算法偏向某些人口统计群体,这一点很重要对话迟早会发生。 人工智能系统可能会根据谁构建它们,它们的开发方式以及最终部署方式而产生偏差。 这称为算法偏差。
While the data sciences have not developed a Nuremberg Code of their own yet, the social implications of research in artificial intelligence are starting to be addressed in some curricula. But even as the debates are starting to sprout up, what is still lacking is a discipline-wide discussion to grapple with questions of how to tackle societal and historical inequities that are reinforced by AI algorithms.
尽管数据科学尚未制定自己的《纽伦堡守则》,但在某些课程中已开始研究人工智能研究的社会意义。 但是,即使辩论开始兴起,仍然缺乏针对整个学科的讨论,以解决如何解决由AI算法强化的社会和历史不平等问题。
We are flawed creatures. Every single decision we make involves a certain kind of bias. However, algorithms haven’t proven to be much better. Ideally, we would want our algorithms to make better-informed decisions devoid of biases so as to ensure better social justice, i.e., equal opportunities for individuals and groups (such as minorities) within society to access resources, have their voices heard, and be represented in society.
我们是有缺陷的生物。 我们做出的每个决定都带有某种偏见。 但是,尚未证明算法会更好。 理想情况下,我们希望我们的算法做出无偏见的明智决策,以确保更好的社会公正性,即社会中的个人和群体(例如少数民族)获得资源,听到自己的声音并保持沉默的平等机会。代表社会。
When these algorithms do the job of amplifying racial, social and gender inequality, instead of alleviating it; it becomes necessary to take stock of the ethical ramifications and potential malevolence of the technology.
当这些算法完成放大种族,社会和性别不平等的工作,而不是减轻它时; 有必要盘点该技术的道德后果和潜在的恶意。
This essay was motivated by two flashpoints : the racial inequality discussion that is now raging on worldwide, and Yann LeCun’s altercation with Timnit Gebru on Twitter which was caused due to a disagreement over a downsampled image of Barack Obama (left) that was depixelated to a picture of a white man (right) by a face upsampling machine learning (ML) model.
本文的出发点有两个:种族不平等的讨论现在在全球范围内进行,以及Yann LeCun与Twitter上的Timnit Gebru发生争执,这是由于对Barack Obama(左)的降采样图像的不同意见所致,该图像被去像素化为像素。脸部向上采样机器学习(ML)模型拍摄的白人(右)图片。
The (rather explosive) argument was sparked by this tweet by LeCun where he says that the resulting face was that of a white man because of a bias in data that trained the algorithm. Gebru responded sharply that the harms of ML systems cannot be reduced to biased data.
LeCun的这条推文引发了(颇具爆炸性的)争论,他说,由于训练该算法的数据存在偏差,最终的面Kong是白人。 Gebru敏锐地回答说,机器学习系统的危害无法减少到有偏见的数据上。
In most baseline ML algorithms, the model fits better to the attributes that that occur most frequently across various data points. For example, if you were to design an AI recruiting tool to review the résumés of applicants for a software engineering position, you would first need to train it with a dataset of past candidates which contains details like “experience”, “qualifications”, “degree(s) held”, “past projects” etc. For every datapoint, the algorithm of the hiring tool would need a decision or a “label”, so as to “learn” how to make a decision for a given applicant by observing patterns in their résumé.
在大多数基线ML算法中,模型更适合各种数据点上最频繁出现的属性。 例如,如果您要设计一个AI招聘工具来审查软件工程职位申请人的履历,则首先需要使用过去候选人的数据集对其进行培训,其中包含“经验”,“资格”,“对于每个数据点,招聘工具的算法将需要一个决定或一个“标签”,以便通过观察来“学习”如何为给定的申请人做出决定简历中的样式。
For an industry where the gender disparity in representation is large, it is reasonable to assume that a large majority of the data points will be male applicants. And this collective imbalance in the data ends up being interpreted by the algorithm as a useful pattern in the data rather than undesirable noise which is to be ignored. Consequently, it teaches itself that male candidates are more preferable than female candidates.
对于代表性别上的巨大差异的行业,可以合理假设大多数数据点是男性申请人。 并且,数据中的这种集体失衡最终被算法解释为数据中的有用模式,而不是被忽略的不希望有的噪声。 因此,它自称男性候选人比女性候选人更可取。
I wish that this was merely an imaginary, exaggerated example that I used to prove my point. It is not.
我希望这只是我用来证明我观点的一个虚构的,夸张的例子。 它不是。
LeCun wasn’t wrong in his assessment because in the case of that specific model, training the model on a dataset that contains faces of black people (as opposed to one that contains mainly white faces) would not have given rise to an output as absurd as that. But the upside of the godfather of modern AI getting dragged into a spat (albeit unfairly) has meant that more researchers will now be aware of the implications of their research.
LeCun的评估没有错,因为在特定模型的情况下,在包含黑人面Kong(而不是主要包含白人面Kong)的数据集上训练模型不会产生荒谬的结果这样。 但是现代AI教父的优势被拖进了争吵中(尽管这是不公平的),这意味着更多的研究人员现在将意识到他们研究的意义。
The misunderstanding clearly seems to emanate from the interpretation of the word “bias” — which in any discussion about the social impact of ML/AI seems to get crushed under the burden of its own weight.
这种误解显然源于对“偏见”一词的解释,在对ML / AI的社会影响的任何讨论中,它似乎都在自身的负担下被压倒了。
As Sebastian Raschka puts it, “the term bias in ML is heavily overloaded”. It has multiple senses that can all be mistaken for each other.
正如塞巴斯蒂安·拉施卡(Sebastian Raschka)所说,“机器学习中的术语偏差严重超载”。 它具有多种感觉,而所有这些感觉都可能会相互误解。
(1) bias (as in mathematical bias unit) (2) “Fairness” bias (also called societal bias) (3) ML bias (also known as inductive bias, which is dependent on decisions taken to build the model.) (4) bias-variance decomposition of a loss function (5) Dataset bias (usually causing 2)
(1) 偏差 (以数学偏差为单位)(2)“公平” 偏差 (也称为社会偏差 )(3)ML 偏差 (也称为归纳偏差) ,取决于建立模型的决策。 (4)损失函数的偏差-方差分解(5)数据集偏差 (通常导致2)
I imagine that a lot of gaps in communication could be covered by just being a little more precise when we use these terms.
我认为,使用这些术语时,只要稍微精确一点就可以弥补沟通中的许多空白。
On a lighter note, never mind Obama, the model even depixelized a dog’s face to a caucasian man’s. It sure loves the white man.
轻松一点,不要介意奥巴马,该模型甚至将狗的脸去像素化为高加索人的脸 。 它肯定爱白人。
Learning algorithms have inductive biases going beyond the biases in data too, sure. But if the data has a little bias, it is amplified by these systems, thereby causing high biases to be learnt by the model. Simply put, creating a 100% non-biased dataset is practically impossible. Any dataset picked by humans is cherry-picked and non-exhaustive. Our social cognitive biases result in inadvertent cherry-picking of data. This biased data, when fed to a data-variant model (a model whose decisions are heavily influenced by the data it sees) encodes these societal, racial, gender, cultural and political biases and bakes them into the ML model.
当然,学习算法的归纳偏差也要超出数据偏差。 但是,如果数据的偏差很小,则这些系统会对其进行放大,从而导致模型学习到较高的偏差。 简而言之,创建100%无偏的数据集实际上是不可能的。 人类选择的任何数据集都是精心挑选的,并非详尽无遗。 我们的社会认知偏见会导致疏忽地选择数据。 当将这种有偏见的数据馈送到数据变量模型(该模型的决策受到其所见数据的严重影响)时,这些偏见数据将对这些社会,种族,性别,文化和政治偏见进行编码,并将其放入ML模型中。
These problems are exacerbated, once they are applied to products. A couple of years ago, Jacky Alciné pointed out that the image recognition algorithms in Google Photos were classifying his black friends as “gorillas.” Google apologised for the blunder and assured to resolve the issue. However, instead of coming up with a proper solution, it simply blocked the algorithm from identifying gorillas at all.
一旦将这些问题应用于产品,这些问题就会加剧。 几年前,杰基·阿尔辛(JackyAlciné) 指出 , Google相册中的图像识别算法将他的黑人朋友归类为“大猩猩”。 Google为这一错误道歉,并保证解决此问题。 但是,它没有提出适当的解决方案,只是根本阻止了算法识别大猩猩。
It might seem surprising that a company of Google’s size was unable to come up with a solution to this. But this only goes to show that training an algorithm that is consistent and fair isn’t an easy proposition, not least when it is not trained and tested on a diverse set of categories that represent various demographic cohorts of the population proportionately.
一家Google规模的公司无法为此提出解决方案,这似乎令人惊讶。 但这仅表明,训练一致且公平的算法并非易事,尤其是在未对代表相应人口统计人群的多种类别进行训练和测试的情况下。
Another disastrous episode of facial recognition tech getting it terribly wrong came as recently as last week when a faulty facial recognition match led to a Michigan man’s arrest for a crime he did not commit. Recent studies by M.I.T. and the National Institute of Standards and Technology, or NIST, found that even though face recognition works well on white men, the results are not good enough for other demographics (the misidentification ratio can be more than 10 times worse), in part because of a lack of diversity in the images used to develop the underlying databases.
面部识别技术的另一场灾难性错误是在上周才发生的,当时一次错误的面部识别比赛导致密歇根州一名男子因未犯罪而被捕。 麻省理工学院和美国国家标准与技术研究院( NIST)的最新研究发现,即使面部识别在白人男性上效果很好,但对于其他人口统计而言,结果仍然不够好(误识别率可能会高出10倍以上),部分原因是用于开发基础数据库的图像缺乏多样性。
Problems of algorithmic bias are not limited to image/video tasks and they manifest themselves in language tasks too.
算法偏差问题不仅限于图像/视频任务,它们也表现在语言任务中。
Language is always “situated”, i.e., it depends on external references for its understanding and the receiver(s) must be in a position to resolve these references. This therefore means that the text used to train models carries latent information about the author and the situation, albeit to varying degrees.
语言总是“定位”的 ,即, 语言的理解取决于外部参考,并且接收者必须能够解决这些参考。 因此,这意味着用于训练模型的文本带有有关作者和情况的潜在信息,尽管程度不同。
Due to the situatedness of language, any language data set inevitably carries with it a demographic bias. For example, some speech to text transcription models tend to have higher error rates for African Americans, Arabs and South Asians as compared to Americans and Europeans. This is because the corpus that the speech recognition models are trained are dominated by utterances of people from western countries. This causes the system to be good at interpreting European and American accents but subpar at transcribing speech from other parts of the world.
由于语言的位置性,任何语言数据集都不可避免地会带来人口统计学偏差。 例如,与美国人和欧洲人相比,某些针对语音的文本转录模型对非裔美国人,阿拉伯人和南亚人来说具有较高的错误率。 这是因为训练语音识别模型的语料库被来自西方国家的人们的话语所支配。 这使得该系统擅长于解释欧洲和美国的口音,但在抄录来自世界其他地区的语音时表现不佳。
Another example in this space is the gender biases in existing word embeddings (which are learned through a neural networks) that show females having a higher association with “less-cerebral” occupations while males tend to be associated with purportedly “more-cerebral” or higher paying occupations.
该领域的另一个例子是现有单词嵌入中的性别偏见(通过神经网络学习),表明女性与“较少大脑”的职业有较高的关联,而男性往往与所谓“较大脑”的职业有关联。高薪职业。
In the table below, we see the gender bias scores associated with various occupations in the Universal Sentence Encoder embedding model. The occupations with positive scores are female-biased occupations and ones with negative scores are male-biased occupations.
在下表中,我们看到了通用句子编码器嵌入模型中与各种职业相关的性别偏见得分。 得分为正的职业是女性偏向的职业,得分为负的职业是男性偏向的职业。
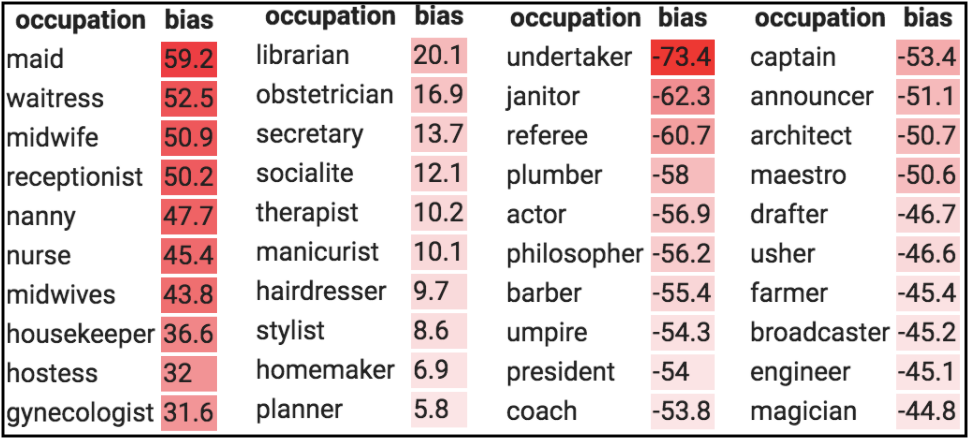
While it is easy for ML Researchers to hold their hands up and absolve themselves of all responsibility, it is imperative for them to acknowledge that they — knowingly or otherwise — build the base layer of AI products for a lot of companies that are devoid of AI expertise. These companies, without the knowledge of fine-tuning and tweaking models, use pre-trained models, as they are, put out on the internet by ML researchers (like GloVe, BERT, ResNet, YOLO etc).
虽然ML研究人员可以很轻松地举起双手并免除所有责任,但他们必须承认,无论有意或无意,他们都为许多没有AI的公司构建了AI产品的基础层专业知识。 这些公司不了解微调和调整模型,而是使用经过预先训练的模型,这些模型是由机器学习研究人员(例如GloVe,BERT,ResNet,YOLO等)发布在互联网上的。
Deploying these models without explicitly recalibrating them to account for demographic differences is perilous and can lead to issues of exclusion and overgeneralisation of people along the way. The buck stops with the researchers who must own up responsibility for the other side of the coin.
部署这些模型而没有明确地重新校准它们以解决人口统计学差异是危险的,并且可能会导致人们在此过程中被排斥和普遍化的问题。 研究人员必须承担起硬币另一面的责任。
It is also easy to blame the data and not the algorithm. (It reminds me of the Republican stance on the second amendment debate: “Guns don’t kill people, people kill people.”) Pinning the blame on just the data is irresponsible and akin to saying that the racist child isn’t racist because he was taught the racism by his racist father.
也很容易指责数据而不是算法。 (这使我想起了共和党在第二次修正案辩论中的立场:“枪不杀人,人杀人。”)将责任归咎于数据是不负责任的,类似于说种族儿童不是种族主义者,因为他的种族主义者父亲教他种族主义。
More than we need to improve the data, it is the algorithms that need to be made more robust, less sensitive and less prone to being biased by the data. This needs to be a responsibility for anyone who does research. In the meantime, de-bias the data.
不仅需要改善数据,还需要使算法更健壮,更不敏感并且更不容易受到数据偏差的影响。 这需要对任何从事研究的人负责。 同时,对数据进行反偏。
The guiding question for deployment of algorithms in the real world should always be “would a false answer be worse than no answer?”
在现实世界中部署算法的指导性问题应该始终是“错误的答案会比没有答案更糟糕?”
You can visit my page here. My Twitter handle is @IntrepidIndian.
您可以 在这里 访问我的页面 。 我的Twitter句柄是@ IntrepidIndian 。
翻译自: https://towardsdatascience.com/how-are-algorithms-biased-8449406aaa83
算法偏见是什么


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









