





行人重识别和行人检测的区别
by Laura Liis Metshvat, Heidi Korp, Anna Székely, Andrzej Lippa
劳拉·里斯·梅特什瓦特(Laura Liis Metshvat),海蒂·科普(Heidi Korp),安娜·塞克莉(AnnaSzékely),安德烈·里帕(Andrzej Lippa)
介绍 (Introduction)
The rising tendency of robotization has increased the number of challenges when creating AI applications, and the weight of responsibility on the shoulders of those who train the algorithms grows permanently. One of the most current fields that gives a wide and exciting area of research is self-driving cars. The general importance of the topic can be seen by the momentous discussion that arises not only in the field of AI, but also in the field of philosophy and social sciences around self-driving cars. The source of the outstanding interest is the fact that even though we can reduce the number of accidents caused by human error by using algorithms. However, in the cases of unavoidable accidents the algorithm has to decide whom to save and who will be the victim. Due to this issue the precision and reliability of those algorithms which lead the self-driving cars is literally deadly important.
越来越多的机器人化趋势在创建AI应用程序时增加了挑战数量,并且训练算法的人的责任越来越重。 自动驾驶汽车是当前引起广泛而令人兴奋的研究领域的领域之一。 不仅在AI领域,而且在无人驾驶汽车周围的哲学和社会科学领域都进行了重要的讨论,可以看出该主题的一般重要性。 引起人们极大兴趣的事实是,即使我们可以通过使用算法来减少人为错误导致的事故数量。 但是,在不可避免的事故情况下,算法必须决定要保存谁以及谁将成为受害者。 由于这个问题,导致自动驾驶汽车的那些算法的精确性和可靠性至关重要。
Since most of the fatal accidents happen when pedestrians cross the road [1]unexpectedly or unattentively, the importance of algorithms that deal with pedestrian path prediction is not only relevant in the field of self-driving cars, but can be highly useful in alerting systems, which help raise the driver’s attention to the crossing pedestrian. These algorithms are already in use eg. Collision Warning with Full Auto Break and Pedestrian Detection system. [1]–[3]
由于大多数致命事故都是在行人意外或不经意地过马路时发生的[1],因此处理行人路径预测的算法的重要性不仅与自动驾驶汽车领域有关,而且在警报系统中也非常有用,这有助于提高驾驶员对过路行人的注意。 这些算法已经在使用中。 带有自动停车和行人检测系统的碰撞警告。 [1] – [3]
Determining whether the pedestrian is going to step onto the road and cross it or not is a highly challenging problem due to the dynamic nature of pedestrians (quick changes in direction and velocity), thus it is not possible to make high accuracy predictions before the preceding 1–2 seconds of the potential crossing. Furthermore, the task is even more complicated since as little as 30 cm can make the difference whether the pedestrian is on the car’s way or not. Thus an algorithm not only needs to perform a high accuracy prediction during the shortest possible time, but the spatial precision is needed to be highly accurate [2]–[4].
由于行人的动态特性(方向和速度的快速变化),确定行人是否要踏上道路并过马路是一个极具挑战性的问题,因此无法在之前进行准确的预测电位交叉的1–2秒。 此外,该任务甚至更加复杂,因为无论行人是否在汽车上,只有30 cm的距离都会有所不同。 因此,算法不仅需要在尽可能短的时间内执行高精度的预测,而且空间精度需要高度精确[2] – [4]。
Due to the challenging and influential nature of the above discussed problem, our aim is to improve the current state-of-the-art solution using neural networks. First, we are going to review the previous works related to the topic and present the existing methods which have been used for pedestrian path prediction. In the later chapters we will present the parameters we will be targeting to improve and describe the model and dataset we will be using to solve the problem.
由于上述问题具有挑战性和影响力,我们的目标是使用神经网络来改进当前的最新解决方案。 首先,我们将回顾与该主题相关的先前工作,并介绍已用于行人路径预测的现有方法。 在后面的章节中,我们将介绍我们将要改进和描述的模型参数以及用于解决问题的模型和数据集。
相关作品 (Related works)
Different models use different features of the pictures or videos to predict, whether the pedestrian is going to cross or not. Most of these models measure the pedestrian’s distance from the vehicle, the pedestrian’s distance from the curbstone, or the distance from the egolane (the lane on which the vehicle moves). Most of the models also investigate the measurement of the pedestrian’s velocity. For predicting the pedestrian’s motion, a very common and widely used tool is the Kalman filter. The Kalman filter is used in many disciplines, including physics, econometrics or engineering for describing dynamic systems. The Kalman filter makes it possible to determine the body’s position, acceleration, and velocity, thus it is widely applied for traffic detection problems [2], [3].
不同的模型使用图片或视频的不同特征来预测行人是否会过马路。 这些模型大多数都测量行人到车辆的距离,行人到路缘石的距离或到egegane(车辆行驶的车道)的距离。 大多数模型还研究行人速度的测量。 为了预测行人的运动,卡尔曼滤波器是一种非常普遍且广泛使用的工具。 卡尔曼滤波器用于描述物理系统的许多学科,包括物理学,计量经济学或工程学。 卡尔曼滤波器可以确定人体的位置,加速度和速度,因此被广泛应用于交通检测问题[2],[3]。
The applicability of Kalman filter was so advantageous that multiple different version of it have been tried, eg. the Extended Kalman Filter or the interaction of different filters, which are specified for detecting different features of the motion (constant velocity, acceleration, turn, etc.). In literature, this method is referred to as IMM, which stands for InteractingMultiple Models. The popularity of Kalman filter also emerges from the relative low computational cost. [3]
卡尔曼滤波器的适用性是如此优越,以至于尝试了多种不同版本的滤波器。 扩展卡尔曼滤波器或不同滤波器的相互作用,这些滤波器用于检测运动的不同特征(恒定速度,加速度,转弯等)。 在文献中,此方法称为IMM,代表InteractingMultiple模型。 卡尔曼滤波器的普及也源于相对较低的计算成本。 [3]
Out of the mere motion of the pedestrian, various features can be used for predicting the upcoming actions. The usefulness of further features can be inferred by the fact that even a human’s ability to distinguish whether the pedestrian will cross decreases drastically if the pedestrian is not fully visible. In the dataset, this situation can be recreated by partially or fully masking the pedestrian in the picture and letting people see only a part of the body or the position of the pedestrian, eg. by the blank bounding box. [2], [4]A study from 2014 included the head position, which can imply whether the pedestrian has or hasn’t seen the car, consequently also alters the likelihoods of possible events.
除了行人的运动之外,各种功能都可以用于预测即将发生的动作。 可以通过以下事实来推断其他特征的有用性:即使在行人不完全可见的情况下,即使人类分辨行人是否会过马路的能力也会大大降低。 在数据集中,这种情况可以通过部分或完全遮盖图片中的行人并让人们仅看到身体的一部分或行人的位置来重新创建。 由空白的边界框。 [2],[4]从2014年开始的一项研究包括头部位置,这可能暗示行人是否看过汽车,因此也改变了可能发生的事件的可能性。
The interconnectedness of head position, motion and lateral position features can be seen on figure 1, where latent variables are in the non-shaded frames, which the model tries to estimate, while the observed (ground truth) variables are in the shaded frames. SV stands for “see the vehicle”, HSV stands for “has seen the vehicle”, AC stands for “at the curb”, SC stands for “situation is critical” (when both the pedestrian and the vehicle continue to move with their previous velocity), M stands for “movement” (can be standing or walking with different velocities), X is the prior belief about the position state (it is computed by the learnt parameters of the training data). The observed variable for SC is the Dmin, the minimum distance between the pedestrian and the vehicle, head orientation (HO) for seeing the vehicle. The observed position (Y) is the grand truth for the latent position (X). The distance to the curb (DTC) is the observed to the variable “at the curb” (AC). As it is shown in the graph, the predicted latent variables are depends on each other sequentially and the SV, SC and AC nodes also depend on their state in the previous time step. [5]
头部位置,运动和侧向位置特征的相互联系可以在图1中看出,其中潜在变量位于模型试图估计的非阴影帧中,而观察到的(地面真实情况)变量位于阴影帧中。 SV代表“看见车辆”,HSV代表“看到车辆”,AC代表“在路边”,SC代表“情况至关重要”(当行人和车辆都继续沿原路行驶时)速度),M代表“运动”(可以以不同的速度站立或行走),X是关于位置状态的先验信念(由训练数据的学习参数计算得出)。 SC的观察变量是Dmin,即行人与车辆之间的最小距离,以及用于观察车辆的头部方向(HO)。 观察位置(Y)是潜在位置(X)的普遍真理。 到路缘的距离(DTC)是变量“在路缘”(AC)的观测值。 如图所示,预测的潜在变量依次相互依赖,并且SV,SC和AC节点还取决于它们在前一个时间步中的状态。 [5]
Another study from 2014 includes even more variable in order to a more precise prediction. Bonnin [1]and her co-authors works with the following features:
2014年的另一项研究包括更多变量,以便进行更精确的预测。 Bonnin [1]和她的合著者具有以下功能:
1. Lateral distance between the pedestrian and the collision point, where the pedestrian and ego-vehicle will intersect
1.行人与碰撞点之间的横向距离,行人与自我车辆将相交
2. Time for the pedestrian to reach the collision point
2.行人到达碰撞点的时间
3. Time for the ego-vehicle to reach the collision point minus time for the pedestrian to reach the collision point (difference in time to reach the collision point)
3.自我车辆到达碰撞点的时间减去行人到达碰撞点的时间(到达碰撞点的时间差)
4. Lateral distance between the pedestrian and the curbstone
4.行人与路缘石之间的横向距离
5. Time for the pedestrian to reach the curbstone
5.行人到达路缘的时间
6. Time for the pedestrian to reach the egolane
6.行人到达egolane的时间
7. Moving direction as the angle between the pedestrian and the road (global orientation)
7.移动方向为行人与道路之间的角度(全局方向)
8. Pedestrian moving toward the road parallel or away to it (is facing the road)
8.行人朝平行或远离道路的方向行驶(面向道路)
9. Moving direction as the angle between the pedestrian and the ego vehicle (relative orientation)
9.移动方向为行人与自我车辆之间的角度(相对方向)
10. Lateral distance between the vehicle and the egolane
10.车辆与异戊烷之间的横向距离
11. Lateral distance between the pedestrian and the zebra crossing
11.行人与斑马线之间的横向距离
12. Time for the pedestrian to reach the zebra crossing
12.行人到达斑马线的时间
The main contribution of Bonnin’s model to the state of the art is to distinguish between zebra and non-zebra environments, since the road crossing has a much higher probability in the proximity of zebras, than other road sections, thus the prediction can be much precise when the algorithm first detect the environment. The results shows that distinguishing in the environment can improve accuracy and enhance the time horizon for which the model is able to give reliable prediction.
Bonnin模型对最新技术的主要贡献是区分斑马和非斑马环境,因为与其他路段相比,在斑马附近道路交叉的可能性更高,因此预测可以更加精确该算法何时首次检测到环境。 结果表明,在环境中进行区分可以提高准确性,并增强模型能够提供可靠预测的时间范围。
Keller and Gavrial also introduced some novel approach how to outperform the basic Kalman filter-baesd and IMM (Interacting Multiple Models) models. They have worked with augmented visual filters, like optical or scene flow (see in figure 2) and tried to include into the measures the prediction error which emerge from the motion of the ego vehicle. They have applied two new models to compare with the Kalman filter and IMM. Both of the novel models based on nonlinearity in comparison with the Kalman filters, and in both cases augmented visual features has been applied. The fist one was a first-order model, based on Gaussian process dynamics model (GDPM), while the second was a higher order model, with probabilistic hierarchical trajectory matching (PHTM). The researchers found that both the GPDM and PHTM models outperformed the previous KF and IMM models by deciding the pedestrian’s position accurately and giving a precise estimation for the action with a greater time horizon. [2]
凯勒(Keller)和加夫里亚尔(Gavrial)还介绍了一些新颖的方法,以胜过基本的卡尔曼滤波器基模型和IMM(交互多模型)模型。 他们与增强型视觉过滤器(如光学或场景流)一起工作(参见图2),并试图将因自走运动引起的预测误差纳入测量范围。 他们应用了两个新模型来与卡尔曼滤波器和IMM进行比较。 与卡尔曼滤波器相比,这两种新颖的模型均基于非线性,并且在两种情况下均已应用了增强的视觉特征。 第一个是基于高斯过程动力学模型(GDPM)的一阶模型,而第二个是具有概率层次轨迹匹配(PHTM)的高阶模型。 研究人员发现,GPDM和PHTM模型均能准确地确定行人的位置,并在更长的时间范围内对动作进行精确估算,从而优于以前的KF和IMM模型。 [2]

It is also worth to mention that one of the most challenging point of pedestrian path prediction to train the models to detect and predict different motions (eg. stopping and walking) thus numerous studies the researchers train different models to capture the different motions, eg. [2]trained one model on pictures where pedestrians are walking, while another model has been trained for stopping pedestrians. Bonnien and her co-authors had face a similar problem which complexity also emerged from the high number of features (the above listed 12). Thus to be able to combine the features (which includes numerous motions and positions of pedestrians) the researchers have used a learning classifier,in the form of a single layer perceptron. [1]
还值得一提的是,行人路径预测中最具挑战性的点之一是训练模型以检测和预测不同的运动(例如,停止和行走),因此众多研究人员研究了不同的模型来捕获例如不同的运动。 [2]在行人走路的图片上训练了一个模型,而对另一个模型进行了训练以阻止行人。 Bonnien和她的合著者也遇到了类似的问题,复杂性也源于众多功能(上面列出的12个功能)。 因此,为了能够组合特征(包括行人的许多动作和位置),研究人员使用了学习分类器,其形式为单层感知器。 [1]
数据集 (Datasets)
JAAD dataset
JAAD数据集
In our project, we are experimenting with the Joint Attention in Autonomous Driving (JAAD) dataset introduced by Iuliia Kotseruba, Amir Rasouli and John K. Tsotsos. The aim of the dataset is to capture the behavioral variability of traffic participants and the joint attention that must occur between drivers and pedestrians, cyclists and other drivers. In the dataset, many different weather conditions, geographical locations, traffic and demographics of people are presented. The ground truth of the dataset contains information about the location of participants as bounding boxes, the physical conditions such as lighting and speed and the behavior of the parties involved. [6]
在我们的项目中,我们正在试验由Iuliia Kotseruba,Amir Rasouli和John K. Tsotsos引入的自动驾驶联合注意(JAAD)数据集。 该数据集的目的是捕获交通参与者的行为变异性以及驾驶员与行人,骑自行车的人和其他驾驶员之间必须引起的共同注意。 在数据集中,显示了许多不同的天气状况,地理位置,交通和人口统计数据。 数据集的基本事实包含以下信息:参与者(作为边界框)的位置,物理条件(如光照和速度)以及参与方的行为。 [6]
This dataset is used in many works related to predicting pedestrian behavior as the dataset represents a variety of scenarios involving pedestrians and other drivers. Most of the data is collected in urban areas, where people are waiting at the designed crossings. There are samples of people of different ages, carrying heavy objects or walking with children and pets. The data is described using bounding boxes and textual annotations. [6]
该数据集用于与预测行人行为有关的许多工作,因为该数据集代表了涉及行人和其他驾驶员的各种场景。 大部分数据收集在市区,那里的人们正等待设计的过境点。 样本中有不同年龄的人,他们背着重物或带着孩子和宠物散步。 使用边界框和文本注释描述数据。 [6]
PIE dataset
PIE数据集
PIE is stands for Pedestrian Intention Estimation. The researchers who created the PIE dataset did it because they believed that it is possible to improve the model performance by predicting the human intention instead of relying barely on the motion data. The critic for the motion based approach is that the action already need to be started in order to predict the outcome. The pedestrian need to start already the motion for road crossing to being able a motion based model to make an accurate prediction. Thus the developers of PIE suggest to combine the motion based approach with an intention based approach. By this approach and by the new PIE dataset the researchers in 2019 achieved 79% precision which had outperformed state-of-the-art by 26% [7].
PIE代表行人意图估算。 创建PIE数据集的研究人员之所以这样做,是因为他们认为可以通过预测人类的意图而不是仅仅依靠运动数据来提高模型的性能。 基于运动的方法的批评者认为,为了预测结果,已经需要开始采取行动。 行人需要已经开始过马路的运动才能能够基于运动的模型做出准确的预测。 因此,PIE的开发人员建议将基于运动的方法与基于意图的方法结合起来。 通过这种方法和新的PIE数据集,研究人员在2019年实现了79%的精确度,比最新技术高出26%[7]。
The dataset is contains 10 minutes long videos which has been taken from the vehicle. The annotation which goes with the data contains information about the bounding boxes, the pedestrian’s action (“walking”, “standing”, “looking”, “not looking”, “crossing”, “not crossing”, “crossing”). Furthermore, spatial information is also included (like traffic light, signs, zebra crossings, road boundaries). Based on the GPS data accurate speed and heading orientation data is generated. The novelty of PIE dataset compared to JAAD is also the accurate vehicle information, spatial street features information (lights, signs, ets) and the pedestrian intention data [7].
数据集包含从车辆拍摄的10分钟长的视频。 数据附带的注释包含有关边界框,行人的动作(“行走”,“站立”,“看”,“不看”,“横穿”,“不横穿”,“横穿”)的信息。 此外,还包括空间信息(如交通信号灯,标志,斑马线,道路边界)。 根据GPS数据,可以生成准确的速度和航向方向数据。 与JAAD相比,PIE数据集的新颖性还在于准确的车辆信息,空间街道特征信息(灯,标志,ets)和行人意图数据[7]。
The grand truth for the pedestrian intention (does he/she want to cross?) had been collected by showing the video for human subjects who needed to decide at given time steps of the video whether the pedestrian wants to cross or not [7].
行人意图(他/她是否想过马路?)的主要真理是通过向人类对象显示视频来收集的,这些人需要在视频的给定时间步长上确定行人是否要过马路[7]。

解决方案 (Solutions)
与多层融合GRU(SF-GRU)堆叠 (Stacked with multilevel fusion GRU (SF-GRU))
After a lot of research and reading papers we came across a novel solution called stacked multilevel fusion GRU (SF-GRU) which seemed to have the best performance resulting in accuracy of 84%. We were also able to find the model’s code which we investigated thoroughly. The plan was to use it as the base model, however we were not able to get the model running even after being in contact with the authors.
经过大量研究和阅读论文,我们遇到了一种称为堆叠多级融合GRU(SF-GRU)的新颖解决方案,该解决方案似乎具有最佳性能,其准确度高达84%。 我们还能够找到我们进行了彻底调查的模型代码 。 计划将其用作基本模型,但是即使与作者联系,我们也无法使模型运行。
For predicting agents’ future actions often the history of their movements is used. Although the dynamic information is very important, the motion patterns only are not sufficient enough to make sense of pedestrian behaviour. There are multiple environmental factors, such as signals, road structures etc. that can affect the behaviour of a pedestrian.
为了预测特工的未来行动,经常使用他们的运动历史。 尽管动态信息非常重要,但是运动模式仅不足以使行人行为有意义 。 有多种环境因素 (例如信号,道路结构等) 会影响行人的行为 。
Architecture
建筑
This solution takes into account also the visual observations of the pedestrian itself and their surroundings. The model is defined as a binary classification problem predicting whether the pedestrian is going to cross or not while taking into consideration the observed context up to some certain time.
该解决方案还考虑了行人本身及其周围环境的视觉观察 。 该模型被定义为一个二进制分类问题,用于预测行人是否会过马路,同时要考虑到某些特定时间的观察环境。
The approach is relatively novel (published in 2019) and uses a stacked recurrent neural network (RNN) architecture. The data from different modalities is gradually fused in different layers. The arrangement of different data is important and affects the resulting accuracy. [8]
该方法相对新颖(于2019年发布),并使用了堆叠式递归神经网络(RNN)架构 。 来自不同模态的数据 逐渐融合到不同的层中 。 不同数据的排列很重要,并且会影响结果的准确性。 [8]

The prediction relies on sources of information: local context (visual features of the pedestrian and their surroundings), pedestrian pose, 2D bounding box locations and the speed of the ego-vehicle.
该预测依赖于信息源: 本地上下文 (行人及其周围环境的视觉特征), 行人姿势 , 2D边界框位置和自我车辆的速度 。
Local context: The pedestrian surroundings and appearance is used at every time step of the observation. This is done by cropping the frame image to the size of the 2D bounding box around the pedestrian. In order to capture the surroundings the bounding box is resized and made into a square so that the width of the scaled bounding box matches its height. This results in a wider viewing angle around the pedestrian and might include the people around, street, traffic signals etc. The pedestrian’s appearance is suppressed in the cropped surroundings image by changing the pixel values in the original bounding box coordinates to neutral gray. Both of these crops are processed with convolutional neural network that produces two feature vectors.
当地环境:在观察的每个时间步均使用行人环境和外观。 这是通过将帧图像裁剪为行人周围2D边界框的大小来完成的。 为了捕获周围环境,调整了包围盒的大小并使其成为正方形,以便缩放后的包围盒的宽度与其高度匹配。 这会导致行人周围更宽的视角,并且可能包括周围的人,街道,交通信号灯等。通过将原始边界框坐标中的像素值更改为中性灰色,可以在裁剪的周围环境图像中抑制行人的外观。 这两种农作物都经过卷积神经网络处理,产生两个特征向量。
Pedestrian pose: For each pedestrian 18 body joints coordinates are generated using a pose network. Each coordinate responds to a point in 2D space. The coordinates are normalized and concatenated into a 36D feature vector.
行人姿势:对于每个行人,使用姿势网络生成18个身体关节的坐标。 每个坐标都响应2D空间中的一个点。 坐标被归一化并连接到36D特征向量中。
2D bounding box locations: The bounding box coordinates are transformed into relative displacement from the initial position forming a vector, which could be interpreted as the pedestrian’s velocity at every time step.
2D边界框位置:边界框坐标转换为相对于初始位置的相对位移,形成一个向量,该向量可以解释为每个时间步长的行人速度。
Speed of the ego-vehicle: Each time step the ego-vehicle’s speed is recorded. [8]
自我车辆的速度:每次记录自我车辆的速度。 [8]
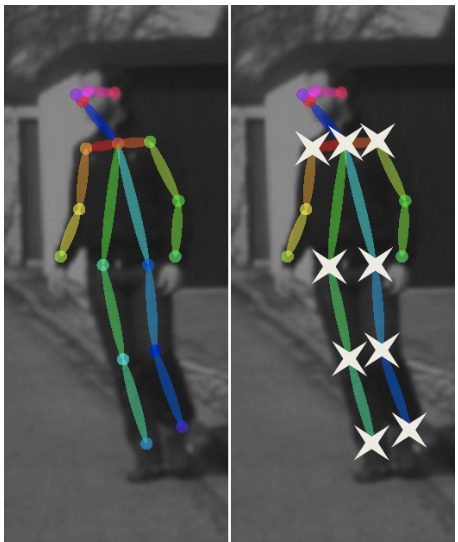
In order to joint model the sequence data the gated recurrent units (GRUs) are used. GRUs are simpler than Long Short Term Memory networks (LSTMs) and in this solution they achieve a similar performance.
为了对序列数据进行联合建模,使用了门控循环单元(GRU)。 GRU比长期短期内存网络(LSTM)更简单,并且在此解决方案中,它们达到了类似的性能。
The RNNs are used as they are able to learn temporal dependencies in sequence data. The temporal depth has been shown to benefit tasks that apply single layer RNNs for pointing coordinates in a space such as trajectory prediction. What is more, the spatial depth improves sequential data modeling in complex tasks, such as video sequence analysis, and could be increased by stacking multiple layers of RNNs on top of each other.
使用RNN是因为它们能够学习序列数据中的时间依赖性。 时间深度已被证明有益于应用单层RNN(例如轨迹预测)在空间中指向坐标的任务。 此外,空间深度可改善诸如视频序列分析之类的复杂任务中的顺序数据建模,并且可以通过将多个RNN彼此堆叠而增加。
The chosen approach uses stacked RNN architecture which gradually fuses features at every level based on their complexity. The visual features that benefit more from the spatial depth are fed to the network at the bottom levels and the dynamic features (speed, trajectories) at higher levels. [8]
选择的方法使用堆叠式RNN架构,该架构会根据其复杂性逐步融合各个级别的功能。 从空间深度中受益更多的视觉特征 在最底层被馈送到网络,在更高层次上被馈入 动态特征 (速度,轨迹)。 [8]
Implementation
实作
The model uses GRUs with 256 hidden units. In order to get the local context the pedestrian samples are cropped (using 2D bounding box annotations), resized to 224 and then padded with zeros to preserve the aspect ratio. For suppressing the pedestrians in the surrounding bounding box, the neutral gray RGB(128, 128, 128) is used. The local context images are first processed using convolutional network for classification and detection (VGG16) pretrained on ImageNet, which is followed by a pooling layer that generates a feature vector of size 512. For pedestrian poses the pose estimation network used is pretrained on the COCO dataset. For each pedestrian the network generates 18-joint poses. [8]
该模型使用具有256个隐藏单元的GRU 。 为了获得本地上下文,对行人样本进行裁剪(使用2D边界框注释),将其大小调整为224,然后用零填充以保留纵横比。 为了抑制周围边界框中的行人,使用了中性灰色RGB(128,128,128)。 首先使用在ImageNet上训练的用于分类和检测的卷积网络(VGG16)对本地上下文图像进行处理,然后通过合并层生成大小为512的特征向量。对于行人姿势,使用的姿势估计网络在COCO上进行了训练数据集。 网络为每个行人生成18个关节姿势。 [8]
The previously described context and pose features are precomputed. The model is trained using Adam optimizer with learning rate of 5*10−6 for 60 epochs with batch size of 32 and L2 regularization of 0.0001. Additionally the data is also augmented by horizontally flipping the images and sub-sampling the classes that are over-represented in order to equalize the number of crossing and non-crossing samples. [8]
前面所描述的内容和姿态功能 预先计算 。 使用Adam优化器对模型进行训练 ,其学习率为5个10-6的60个时期,批处理大小为32,L2正则化为0.0001。 另外, 还通过水平翻转图像并对子集进行过度采样来对数据进行增强 ,以使 交叉和非交叉样本的数量 相等 。 [8]
Evaluation
评价
Although one of the best datasets used in the field of predicting pedestrian behaviour is JAAD, it was not the most suitable one for this task. This is because more samples were needed together with more precise data about vehicles and longer sequences for making long-term predictions. Therefore, the pedestrian intention estimation (PIE) dataset was used. [8]
尽管在预测行人行为方面使用的最佳数据集之一是JAAD,但它并不是最适合此任务的数据集。 这是因为需要更多的样本以及有关车辆的更精确数据和更长的序列以进行长期预测。 因此, 行人意图估计( PIE 使用 )数据集 。 [8]
The performance of the proposed model SF-GRU was compared to 5 different models (single layer GRU, multi stream GRU, hierarchical GRU, stacked GRU). All the evaluations were done on observation sequences with duration of 0.5s (15 frames). The samples were selected with 2s time to event (TTE) as it should be the minimum time for the pedestrian to make the crossing decision. [8]
将拟议模型SF-GRU的性能与5种不同模型 (单层GRU,多流GRU,分层GRU,堆叠GRU)进行了比较。 所有评估都是在观察序列上进行的,持续时间为0.5秒 (15帧)。 选择样本的时间为事件发生时间 (TTE)为2秒,因为这应该是行人做出交叉决策的最短时间。 [8]
The proposed model SF-GRU performs better than the other tested models (single layer GRU, multi.stream GRU, hierarchical GRU, stacked GRU) on all the metrics except for recall. The single layer GRU results in better recall while decreasing the precision by 6%. What is more the results also indicate that no performance improvement is achievable by simply adding layers to the network or separating the processing of features with different modalities.[8]
所提出的模型SF-GRU 除 召回率 外 , 在所有指标上的 性能均优于其他测试模型(单层GRU,多流GRU,分层GRU,堆叠GRU)。 单层GRU可以提高召回率,同时降低6%的精度。 此外,结果还表明, 仅通过向网络添加层或分离具有不同模态的特征处理 就无法实现性能提升 。[8]

The performance of all algorithms degrades when the observation is done further before the actual event. The increased length of the observation time can provide more data but also add more noise.
当在实际事件之前进行 观察时,所有算法的性能都会降低 。 延长的观察时间可以提供更多数据,但也会增加噪声。

The table above indicates how different fusion strategies alter the performance. The table demonstrates how moving simpler features (for example speed) to the higher levels of the stack, improves the performance up to 9% on accuracy, 10% on recall and more than 15% on precision. This is probably due to the fact that more complex features benefit more from the spatial depth of the network and are fed to the network at the bottom levels and the simpler features (speed, trajectory coordinates) at higher levels. [8]
上表显示了不同的融合策略如何改变性能 。 该表展示了如何将更 简单的功能 (例如速度)移到更高的堆栈级别 ,我将性能提高了9% , 召回率提高了10%,将精度提高了15%以上 。 这可能是由于以下事实:更复杂的特征从网络的空间深度中受益更多,并在底层被馈送到网络,而在更高层被馈给更简单的特征(速度,轨迹坐标)。 [8]
Conclusion
结论
The SF-GRU model is a stacked RNN architecture that gradually, at different levels of processing, fuses together different features, such as vehicle dynamics, pedestrian appearance and their surroundings. The SF-GRU performs the best compared to other RNN architectures having the most optimal performance when more complex features are fed to the bottom layers and the simpler features at the higher layers of the network. [8]
SF-GRU模型是一个堆叠的RNN架构 ,在不同的处理级别逐渐将不同的功能融合在一起 ,例如车辆动力学 , 行人外观及其周围环境 。 所述SF-GRU执行与具有最优化的性能时, 更复杂的特征被馈送至底部层和简单的功能在网络的较高层的其他RNN架构最好的。 [8]
我们的解决方案 (Our solution)
In our experiment, we are analyzing the JAAD dataset and creating our own model. The preprocessing of the dataset can be divided into two tasks: processing of the video files and processing of the annotations.
在我们的实验中,我们正在分析JAAD数据集并创建我们自己的模型。 数据集的预处理可以分为两个任务:视频文件的处理和注释的处理。
The authors of the JAAD dataset have written a short script for splitting the video clips into sets of images. The images corresponding to one video clip are saved into the folder with the same name as the video. Each image name contains the ID of the frame, which can be later associated with corresponding frame annotation.
JAAD数据集的作者编写了一个简短的脚本,用于将视频剪辑拆分为图像集。 与一个视频剪辑对应的图像以与视频相同的名称保存到文件夹中。 每个图像名称都包含框架的ID,以后可以将其与相应的框架注释关联。
The annotation files are in the XML format and contain data about the bounding boxes, whether the pedestrian is crossing or not crossing and other related information, such as if the pedestrian is occluded or not. We are using the value of “crossing” tag as the label and a few other fields as features. [6]
注释文件为XML格式,并包含有关边界框的数据(无论行人是否正横过马路)以及其他相关信息,例如是否行人被闭塞。 我们将“ crossing”标签的值用作标签,并将其他几个字段用作要素。 [6]
After preprocessing both video clips and annotations, we are creating an object per frame that contains the image frame and related features. There is also a set of labels corresponding to the object in the training data. We are then using this data to train our model.
在对视频剪辑和注释进行预处理之后,我们将为每个帧创建一个对象,其中包含图像帧和相关功能。 训练数据中还有一组与对象相对应的标签。 然后,我们将使用这些数据来训练我们的模型。
结果 (Results)
The first model we created is very simple: it has four layers which consist of one input layer and three dense layers. The first dense layer uses softmax activation function and the following two use RELU activation function. We are using binary cross entropy as the loss function, Adam optimizer, hidden layer size of 32 and from metrics we are using accuracy and binary accuracy.
我们创建的第一个模型非常简单:它有四层,分别由一个输入层和三个密集层组成。 第一个密集层使用softmax激活功能,接下来的两个使用RELU激活功能。 我们将二进制交叉熵用作损失函数, Adam优化器,32的隐藏层大小,并根据度量标准使用精度和二进制精度 。
To train our model, we are using images with corresponding annotations from 17 video clips, which makes 3960 images. The annotations consist of data about the pedestrian, such as if they are occluded or not, their hand gesture, are they looking or not, are they walking or not, are they nodding or not and their action and reaction. As labels, we are using the value of the tag “cross”, which indicates if the pedestrian in the image is crossing or not.
为了训练我们的模型,我们使用来自17个视频剪辑的具有相应注释的图像,从而生成3960张图像。 注释包括有关行人的数据,例如行人是否被遮挡,他们的手势,他们是否注视,他们是否走路,是否点头以及他们的行动和React。 作为标签,我们使用标签“ cross”的值,该值指示图像中的行人是否在交叉。
After training for 100 epochs, we get the loss, which is 2.5986, accuracy that has value 0.0604 and binary accuracy with value 0.6770. The value of the binary accuracy is so high compared to accuracy, because there are much more images with pedestrians who are not crossing compared to those who are. However, the model’s ability to recognize a crossing pedestrian is relatively low.
100个时代训练结束后,我们得到了具有价值0.0604和二进制精度值0.6770的损失 ,这是2.5986, 准确性 。 与精度相比, 二进制精度的价值是如此之高,因为与行人相比,未行人的图像更多。 但是,该模型识别过路行人的能力相对较低。
Future improvements
未来的改进
There are many steps that could be taken to improve the model. First, we should add more data and divide them into training, validation and test data. We could also use more layers in the model, particularly the GRU layer as it was used in the existing model we have been thoroughly investigating. There could be other hyperparameters used that would correspond to a two-class classification model. Also, the quality of the data can be improved by choosing different or additional tags, such as the locations of pedestrians’ bounding boxes. It would also help if there were an equal amount of images of pedestrians crossing and not crossing.
可以采取许多步骤来改进模型。 首先,我们应添加更多数据并将其分为训练,验证和测试数据。 我们还可以在模型中使用更多的层,尤其是在我们一直在深入研究的现有模型中使用的GRU层。 可能会使用其他与两类分类模型相对应的超参数。 同样,可以通过选择不同或附加的标签(例如行人边界框的位置)来提高数据质量。 如果有相同数量的行人横穿和不横穿的图像,也将有所帮助。
结论 (Conclusion)
In this project, we created a simple model using JAAD dataset to predict from camera images, whether the pedestrian is going to cross or not. At first, we wanted to use an existing model that had better results than other approaches we also took a look at. However, we were not able to get the model running as intended and thus decided to understand the problem better by creating a simple model ourselves. The resulting model needs further improvements, but from the results we got, we got a better understanding of the data and how it should be used to make the model effective. The topic about whether the pedestrian is going to cross or not in an area with both marked and not marked crossings is very important regarding the creation of autonomous vehicles. We are hoping that our work can be used in future works in a similar field.
在这个项目中,我们使用JAAD数据集创建了一个简单的模型,可以根据摄像机图像预测行人是否要过马路。 首先,我们希望使用一个现有模型,该模型的结果要比我们也研究过的其他方法更好。 但是,我们无法使模型按预期运行,因此决定通过自己创建一个简单模型来更好地理解问题。 生成的模型需要进一步改进,但是从我们得到的结果中,我们对数据以及如何使用数据以使模型有效有了更好的理解。 关于行人是否要在有明显标志和没有明显标志的交叉点的区域中交叉的话题,对于创建自动驾驶汽车非常重要。 我们希望我们的工作可以在类似领域的未来工作中使用。
翻译自: https://medium.com/@annaszkely/will-the-pedestrian-cross-64afe9c38d61
行人重识别和行人检测的区别















 2592
2592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









