





This essay is written for machine learning researchers and neuroscientists (some jargons in both fields will be used). Though it is not intended to be a comprehensive review of literature, we will take a tour through a selection of classic work and new results from a range of topics, in an attempt to develop the following thesis:
本文是为机器学习研究人员和神经科学家撰写的(在这两个领域都将使用一些专业术语)。 尽管不打算对文学进行全面的回顾,但我们将通过一系列经典作品和一系列主题的新成果进行导览,以期提出以下论文:
Just like the fruitful interaction between representation learning and perceptual/cognitive neurophysiology, a similar synergy exists between transfer/continual learning, efficient deep learning and developmental neurobiology.
就像表征学习和知觉/认知神经生理学之间富有成果的相互作用一样,转移/继续学习,有效的深度学习和发育神经生物学之间也存在着类似的协同作用。
Hopefully it would inspire the reader in one way or two, or at the very least, kill some boredom during a global pandemic.
希望它能以一种或两种方式激发读者,或者至少在全球性大流行中消除读者的无聊。
We are going to touch on the following topics through the lens of large language models:
我们将通过大型语言模型来探讨以下主题:
- How do overparameterized deep neural nets generalize? 超参数化的深度神经网络如何推广?
- How does transfer learning help generalization? 转移学习如何帮助推广?
- How do we make deep learning computationally efficient in practice? 我们如何在实践中提高深度学习的计算效率?
In tackling these questions, how might deep learning research benefit and benefit from scientific studies of the developing and aging brain?
在解决这些问题时,怎么可能深学研究中获益 ,并受益于发展中国家和大脑老化的科学研究?
哲学序言 (A philosophical preamble)
Before we start, it is prudent to say a few words about the brain metaphor, to clarify this author’s position on the issue as it often arises central at debates.
在开始之前,请谨慎地谈论一下大脑的隐喻 ,以阐明作者在该问题上的立场,因为它经常在辩论中占据中心地位。
The confluence of deep learning and neuroscience arguably took place as early as the conception of artificial neural nets, because artificial neurons abstract characteristic behaviors of biological ones [1]. However, the drastically different learning mechanisms and disparities in the kinds of intelligent functions erected a formidable barrier in between the two standing tall for decades. The success of modern deep learning in recent years rekindled another trend of integration, bearing new fruits. In addition to designing AI systems inspired by the brain (e.g. [2]), deep neural nets have recently been proposed to serve as a useful model system to understand how the brain works (e.g. [3]). The benefits are mutual. Progress is being made in reconciliation of the learning mechanisms [4] but, in more than one significant aspect, the intelligence gap obstinately remain [5, 6].
深度学习和神经科学的融合可以说最早发生在人工神经网络的概念上,因为人工神经元抽象了生物神经网络的特征行为[ 1 ]。 但是,数十年来,在站立和站立之间,智能功能的完全不同的学习机制和差异在两者之间建立了巨大的障碍。 近年来,现代深度学习的成功重燃了融合的另一趋势,并取得了新成果。 除了设计受大脑启发的AI系统(例如[ 2 ])外,最近还提出了深度神经网络作为一种有用的模型系统,以了解大脑的工作原理(例如[ 3 ])。 利益是共同的。 进展在学习机制[和解正在取得4 ],但,在一个以上的显著方面,智能间隙硬是留[ 5 , 6 ]。
Now, for a deep learning researcher or practitioner looking at this mixed landscape today, is a brain analogy helpful or misleading? It is of course simple to give an answer based on faith, and there are large numbers of believers on both sides. But for now let us not pick a side by belief. Instead, let us evaluate each analogy in its unique context entirely by its practical ramifications: scientifically, it is helpful only if it makes experimentally verifiable/falsifiable predictions, and for engineering, it is useful only if it generates candidate features that can be subject to solid benchmarking. As such, for all brain analogies we are going to raise in the rest of this essay, however appropriate or farfetched they might seem, we shall look past any prior principles and strive to articulate hypotheses that can guide future scientific and engineering work in practice, either within or beyond the limits of these pages.
现在,对于当今研究这种混杂格局的深度学习研究人员或从业者而言,大脑类比是有用还是令人误解的 ? 根据信仰给出答案当然很简单,双方都有大量信徒。 但是现在,让我们不要一意孤行。 取而代之的是,让我们通过其实际后果完全在其独特的上下文中评估每个类比: 科学地讲 ,仅当它做出实验上可验证/可证伪的预测 时才有用 ; 对于工程学 ,它仅在生成可以接受的候选特征时才有用。可靠的标杆管理 。 因此,对于本文中余下的所有大脑类比,无论它们看起来多么恰当或牵强,我们都将提出,我们将超越任何先前的原则,并努力阐明可以指导实践中的未来科学和工程工作的假设,在这些页面的限制之内或之外。
工作类比 (The working analogy)
What do we usually think of a deep neural net when likening it to the brain?
当将深层神经网络比作大脑时,我们通常会怎么看?
For most, the network architecture maps to the gross anatomy of brain areas (such as in a sensory pathway) and their interconnections, i.e. the connectome, units map to neurons or cell assemblies, and connection weights to synaptic strengths. As such, neurophysiology carries out the computation of model inference.
对于大多数人来说,网络体系结构映射到大脑区域的总体解剖结构(例如在感觉途径中)及其相互连接,即连接组,单元映射到神经元或细胞装配体,连接权重映射到突触强度。 这样,神经生理学进行模型推断的计算。
Learning of deep neural nets typically takes place given a pre-defined network architecture, in the form of optimizing an objective function over a training dataset. (A major difficulty lies in the biological plausibility of artificial learning algorithms, a topic we do not touch in this article — here we simply accept the similarity of function despite the differences in mechanism.) Thus, the data-driven learning by optimization is similar to experience-based neural development, i.e. nurture, whereas network architecture, and to a large degree initialization and some hyperprameters as well, are genetically programmed as a result of evolution, i.e. nature.
深度神经网络的学习通常是在给定预定义的网络体系结构的情况下进行的,其形式是在训练数据集上优化目标函数。 (一个主要的困难在于人工学习算法的生物学合理性,这是我们在本文中未涉及的主题,尽管机制有所不同,但在这里我们仅接受功能的相似性。)因此,通过优化进行数据驱动的学习是相似的基于经验的神经发展,即培育 ,而网络架构以及很大程度上的初始化以及一些超性能,都是通过进化(即自然)进行遗传编程的。
Remark: It should be noted that modern deep net architectures, either implicitly engineered by hand or explicitly optimized through neural architecture search (NAS) [7], are also a consequence of data-driven optimization, engendering the inductive bias — the free lunch is paid for by all the unfit that failed to survive natural selection.
备注 :应该指出的是,现代的深层网络架构,无论是通过手工进行隐式设计,还是通过神经架构搜索(NAS)[ 7 ]进行 显式优化 ,都是数据驱动优化的结果,产生了归纳式偏差-免费午餐是由所有未能通过自然选择幸存的不健康所支付。
Thanks to the rapid growth of data and computing power, the decade of 2010s saw a Cambrian explosion of deep neural net species, spreading rapidly across the world of machine learning.
由于数据和计算能力的快速增长,2010年代的十年间发生了寒武纪深层神经网络物种的爆炸式增长,在整个机器学习世界中Swift传播。
伯爵学 (BERTology)
The plot thickens as the evolution of modern deep learning produces a cluster of new species in the past two years. They thrive in the continent of natural language understanding (NLU), on fertile deltas of mighty rivers carrying immense computing power, such as the Google and the Microsoft. These remarkable creatures share some key commonalities: they all feature a canonical cortical microcircuitry called the transformer [8], have rapidly increasing brain volumes setting historic records (e.g. [9, 10, 11]) and are often scientifically named after one of the Muppets. But the most prominent common trait of these species crucial to their evolutionary success is the capability of transfer learning.
在过去两年中,随着现代深度学习的发展产生了一系列新物种,该图变得越来越厚。 它们在自然语言理解(NLU)大陆上蓬勃发展,这些地区蕴藏着强大的河水,这些河水蕴藏着巨大的计算能力,例如Google和Microsoft。 这些显着的生物分享一些关键共性:它们都配备了经典的皮质微型电路称为变压器 [ 8 ],已Swift增加大脑体积的设置历史记录(例如[ 9 , 10 , 11 ]),并经常科学的提线木偶的名字命名。 但是这些物种对进化成功至关重要的最突出的共性是转移学习的能力。
What does this mean? Well, these creatures have a two-stage neural development: a lengthy, self-supervised larval stage called pre-training followed by a fast, supervised maturation stage called fine-tuning. During self-supervised pre-training, huge corpora of unlabeled text are presented to the subject, who plays with itself by optimizing certain objectives very much similar to solving language quizzes given to human kids, such as completing sentences, filling in missing words, telling logical procession of sentences, and spotting grammatical errors. Then during fine-tuning, a well pre-trained subject can quickly learn to perform a particular language understanding task by supervised training.
这是什么意思? 好吧,这些生物具有两个阶段的神经发育:一个漫长的,自我监督的幼虫阶段,称为预训练,然后是一个快速,监督的成熟阶段,称为微调 。 在自我监督的预训练过程中,会向主体展示大量未标记的文本,主体通过优化某些目标来自己玩耍,这与解决人类小孩子的语言测验非常相似,例如完成句子,填写遗漏的单词,句子的逻辑处理,并发现语法错误。 然后,在进行微调时,受过良好训练的主体可以通过监督训练快速学习执行特定的语言理解任务。
Transfer learning’s sweeping conquest of the land of NLU was marked by the advent of bidirectional encoder representations from transformers (BERT) [12]. BERT and its variants have advanced the state-of-the-art by a considerable margin. Their remarkable success piqued tremendous interest in the inner workings of these models, creating the study of “BERTology” (see review [13]). Not unlike neurobiologists, BERTologists stick electrodes into the model brain to record activities for interpretation of the neural code (i.e. activations and attention patterns), make targeted lesions of brain areas (i.e. encoding layers and attention heads) to understand their functions, and study how experiences in early development (i.e. pre-training objectives) contribute to mature behavior (i.e. good performance in NLU tasks).
转移学习对NLU土地的全面征服以变压器(BERT)[ 12 ]的双向编码器表示的出现为标志。 BERT及其变体已将先进技术大大提高了。 他们的非凡成就引起了人们对这些模型的内部运作的极大兴趣,从而创造了“ BERTology”的研究(见评论[ 13 ])。 与神经生物学家不同,BERTologists将电极插入模型大脑以记录用于解释神经代码的活动(即激活和注意模式),对脑区域进行有针对性的损伤(即编码层和注意头)以了解其功能,并研究如何早期开发的经验(即培训前的目标)有助于成熟的行为(即,在NLU任务中表现良好)。
网络压缩 (Network compression)
Meanwhile, in the world of deep learning, multi-stage development (like transfer learning) happens in more animal kingdoms than one. Particularly, in production, one often needs to compress a trained huge neural net into a compact one for efficient deployment.
同时,在深度学习的世界中,多阶段发展(如迁移学习)发生在动物王国中而不是一个。 特别是在生产中,经常需要将经过训练的庞大神经网络压缩为紧凑的神经网络,以进行有效部署。
The practice of network compression derives from one of the very puzzling properties of deep neural nets: overparameterization helps not only generalization but optimization as well. That is to say, training a small network is often not only worse than training a large one (if one can afford to do so of course) [14], but also worse than compressing a trained large one to the same small size. In practice, compression can be realized by sparsification (pruning), distillation, etc.
网络压缩的实践源于深层神经网络的一个令人费解的特性之一: 过度参数化不仅有助于泛化,而且还可以优化 。 也就是说,训练一个小型网络通常不仅比训练一个大型网络(当然,如果一个人负担得起的话)更糟糕[ 14 ],而且比将一个训练过的大型网络压缩到相同的小尺寸还差。 在实践中,压缩可以通过稀疏(修剪),蒸馏等来实现。
Remark: It is worth noting that the phenomenon of best sparse network arising from optimizing and then compressing a dense one (see e.g. [15, 16]) is very much like the developing brain, in which over-produced connections are gradually pruned [17].
备注: 这是值得注意的是,最好的稀疏网络的现象从优化所产生的,然后压缩的致密一个(例如参见[ 15 , 16 ])的非常像显影脑,其中在产生的连接逐渐修剪[ 17 ]。
The type of multi-stage development in model compression, however, is very different from transfer learning. The two stages of transfer learning see the same model being optimized for different objectives, whereas in model compression, the original model morphs into a different one in order to retain optimality for a same objective. If the former resembles maturation to acquire new skills, then the latter is more like graceful aging without losing already learned skills.
但是,模型压缩中的多阶段开发类型与传递学习有很大不同。 转移学习的两个阶段看到,同一模型针对不同的目标进行了优化,而在模型压缩中,原始模型会演变为不同的模型,以保持同一目标的最优性。 如果前者看起来像是要获得新技能的成熟,那么后者就更像优美的衰老而又不会失去已经学习的技能。
学习权重与学习结构的对立? (Learning weights vs. learning structures: a duality?)
When a network is compressed, its structure often undergoes changes. It could mean either the network architecture (e.g. in the case of distillation) or parameter sparseness (e.g. in the case of pruning). These structural changes are usually imposed by heuristics or regularizers that constrain the otherwise already effective optimization.
当网络被压缩时,其结构通常会发生变化。 它可能意味着网络体系结构 (例如在蒸馏的情况下)或参数稀疏 (例如在修剪的情况下)。 这些结构性变化通常是由启发式或正则化方法强加的,它们会限制原本已经有效的优化。
But can structure rise above being merely an efficiency constraint and become an effective means for learning? An increasing number of emerging studies seem to suggest so.
但是, 结构能否超越仅仅是效率约束,而成为学习的有效手段? 越来越多的新兴研究似乎表明了这一点。
One intriguing case is weight-agnostic networks [18]. These jellyfish-like creatures do not have to learn during their lifespan, but still are extremely well adapted to their ecological niches, because evolution did all the heavy lifting in choosing an effective brain structure for them.
一种有趣的情况是与重量无关的网络[ 18 ]。 这些类似水母的生物在其一生中不必学习,但仍非常适应其生态位,因为进化为他们选择了有效的大脑结构带来了沉重的负担。
Even with a fixed architecture chosen by nature, learning sparse structure can still be as effective as learning synaptic weights. Recently, Ramanujan et al. [19] managed to find sparsified versions of initialized convolutional nets which, if made wide and deep enough, generalize no worse than dense ones undergoing weight training. Theoretical investigations also suggest that sparsification of random weights can be just as effective as optimizing parameters if the model is sufficiently overparameterized [20, 21].
即使使用自然选择的固定架构, 学习稀疏结构仍然可以像学习突触权重一样有效 。 最近,Ramanujan等人。 [ 19 ]设法找到了初始卷积网的稀疏版本,如果使卷积网足够宽和足够深,其推广效果一般不比进行重量训练的密集卷积网差。 理论研究也表明随机权的那稀疏可就像模型充分overparameterized优化参数,如有效[ 20 , 21 ]。
Thus, in the grossly overparameterized regime of modern deep learning, we have in sheath a doubled-edged sword: optimization of weights and of structure. This is reminiscent of both synaptic and structural plasticity as mechanisms underlying biological learning and memory (e.g. see [22, 23]).
因此,在现代深度学习的严重过分参数化的体制中,我们拥有一把双刃剑: 权重和结构的优化。 这使人想起既突触和结构可塑性生物学习和记忆基本机制(例如,参见[ 22 , 23 ])。
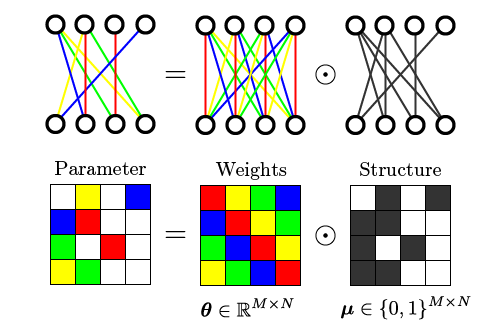
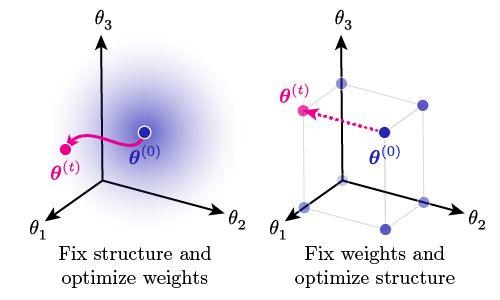
Remark: A formal way of describing parameter sparseness is through the formulation of a parameter mask (Figure 1). Learning can be realized either by optimization of continuous weights within a fixed structure, or by optimization of discrete structure given a fixed set of weights (Figure 2).
备注 :描述参数稀疏性的正式方法是通过制定参数掩码(图1)。 学习可以通过优化固定结构内的连续权重来实现,也可以通过优化给定固定权重集的离散结构来实现(图2)。
通过稀疏进行微调 (Fine-tuning by sparsification)
Now that structure, just like weights, can be optimized for learning, can this mechanism be used to make transfer learning better?
现在,可以像权重一样优化该结构以进行学习,可以使用这种机制来使转移学习更好吗?
Yes, it can indeed. Recently, Radiya-Dixit & Wang [24] made BERT pick up this new gene and evolve to something new. They showed that BERT can be effectively fine-tuned by sparsification of pre-trained weights without changing their values, as demonstrated systematically with the General Language Understanding Evaluation (GLUE) tasks [25].
是的,的确可以。 最近,Radiya-Dixit&Wang [ 24 ]使BERT挑选了这个新基因并进化为新的东西。 他们表明,可以通过对预训练权重进行稀疏化而有效地对BERT进行微调,而无需更改其值,如通用语言理解评估(GLUE)任务系统地演示的那样[ 25 ]。

Remark: Note that similar fine-tuning by sparsification has been succesffully applied to computer vision, e.g. [26]. Also take note of existing work sparsifying BERT during pre-training [27].
备注 :请注意,通过稀疏化进行的类似微调已成功应用于计算机视觉,例如[ 26 ]。 还要注意在预培训期间使BERT变得稀疏的现有工作[ 27 ]。
Fine-tuning by sparsification has favorable practical implications. On the one hand, pre-trained parameter values remain the same in learning multiple tasks, reducing task-specific parameter storage to only a binary mask; on the other hand, sparsification compresses the model, potentially obviates many “multiply-by-zero-and-accumulate” operations with proper hardware acceleration. One stone kills two birds.
通过稀疏性进行微调具有良好的实际意义 。 一方面,在学习多个任务时,预训练的参数值保持不变,从而将特定于任务的参数存储减少为仅二进制掩码。 另一方面,稀疏化压缩了模型,并通过适当的硬件加速消除了许多“乘以零并累加”的操作。 一块石头杀死两只鸟。
Beyond the practical benefits, however, the possibility of fine-tuning by sparsification brought about a few new opportunities towards a deeper understanding of language pre-training and its potential connections to the biological brain. Let us take a look of them in the next sections.
但是,除了实际的好处之外,通过稀疏进行微调的可能性还带来了一些新的机会,可以更深入地了解语言预训练及其与生物大脑的潜在联系。 让我们在下一部分中对其进行研究。
中奖彩票 (Winning tickets of a different lottery)
First we study the nature of language pre-training from the perspective of optimization.
首先,我们从优化的角度研究语言预训练的本质。
It seems that language pre-training meta-learns a good initialization for learning downstream NLU tasks. As Hao et al. [28] recently showed, pre-trained BERT weights have good task-specific optima that are closer and flatter in loss landscape. This means pre-training makes fine-tuning easier, and the fine-tuned solutions generalize better.
似乎语言预训练元学习为学习下游NLU任务提供了很好的初始化。 如郝等。 [ 28 ]最近表明,预训练的BERT权重具有良好的针对特定任务的最优值,在损失情况下更紧密,更平坦。 这意味着预训练使微调变得更加容易,并且微调的解决方案可以更好地推广。
Similarly, pre-training also makes discovery of fine-tuned sparse subnetworks easier [24]. As such, interestingly, pre-trained language models have all the key properties of a “winning lottery ticket” as formulated by Frankle and Carbin [29], but of exactly the complementary kind given the duality of optimizing weights vs. structure (Figures 3, 4):
同样,预训练也使发现微调的稀疏子网络更加容易[ 24 ]。 因此,有趣的是,经过预先训练的语言模型具有Frankle和Carbin [ 29 ]提出的“中奖彩票”的所有关键属性,但是由于优化了权重与结构的双重性,因此它是互补的 (图3)。 ,4):
The Frankle-Carbin winning ticket is a specific sparse structure that facilitates weight optimization. It is sensitive to weight initialization [29]. It is potentially transferable across vision tasks [30].
Frankle-Carbin中奖彩票是一种特殊的稀疏结构 , 有助于优化重量 。 它对权重初始化很敏感 [ 29 ]。 它可能在视觉任务之间转移 [ 30 ]。
A pre-trained language model is a specific set of weights that facilitates structural optimization. It is sensitive to structural initialization [24]. It is transferable across NLU tasks [24].
预先训练的语言模型是一组特定的权重 ,可以促进结构优化 。 它对结构初始化很敏感 [ 24 ]。 它可以在NLU任务之间转移 [ 24 ]。

Remark: Note that the “winning ticket” property of pre-trained BERT is different from the wide-and-deep regime as in [19]. It remains an open question whether large transformer-based language models, if made sufficiently wide and deep (bound to be astronomically large provided their already huge sizes), might be effectively fine-tuned from random initializations without pre-training.
备注 :请注意,预训练的BERT的“中奖票”属性不同于[19]中的宽广和深层机制。 大型的基于变换器的语言模型如果足够宽和足够深(如果已经足够大的话,必然会天文很大),是否可以在不进行预训练的情况下有效地从随机初始化中进行微调,这仍然是一个悬而未决的问题。
Though learning weights of a winning lottery ticket and searching for a subnetwork within pre-trained weights lead to the same outcome— a compact, sparse network that generalizes well, the biological plausibility of the two approaches are drastically different: finding a Frankle-Carbin ticket involves repeated rewinding in time and re-training, a process only possible across multiple biological generations if earlier states could be genetically encoded and then reproduced in the next generation so as to realize rewinding. But weight pre-training followed by structural sparsification are similar to development and aging, all within a single generation. Thus, dense pre-training and sparse fine-tuning might be a useful model for neural development.
尽管学习中奖彩票的权重并在预先训练的权重内搜索子网络会得出相同的结果-紧凑,稀疏的网络可以很好地泛化,但这两种方法的生物学可行性却截然不同:找到富兰克尔·卡宾票涉及到时间上的重复倒带和重新训练,如果较早的状态可以被遗传编码然后在下一代中再现以实现倒带,则该过程只有跨多个生物学世代才可能实现。 但是,对体重进行预训练,然后进行结构性稀疏化,都与一代人的发展和衰老相似。 因此,密集的预训练和稀疏的微调可能是神经发育的有用模型。
坚固性:来自不同结构的相同功能 (Robustness: same function from different structures)
Another uncanny similarity between BERT and the brain is its structural robustness.
BERT与大脑之间另一个不可思议的相似之处是其结构坚固性 。
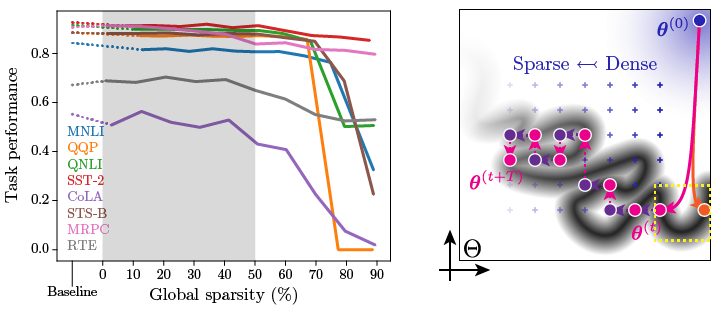
There seems to be an abundance of good subnetworks of pre-trained BERT at a wide range of sparsity levels [24]: a typical GLUE task can be learned by eliminating from just a few percent to over half of pre-trained weights, with good sparse solutions exist everywhere in between (Figure 5, left). This is reminiscent of structural plasticity at play in the maturing and aging brain — its acquired function remains the same while the underlying structure undergoes continuous changes over time. This is very different from the brittle point solutions by traditional engineering.
在广泛的稀疏性水平下,似乎有很多预训练的BERT的良好子网络[ 24 ]:可以通过将训练后的权重从百分之几减少到一半以上来学习典型的GLUE任务,稀疏解决方案之间存在无处不在(图5,左)。 这让人想起大脑在成熟和衰老过程中发挥的结构可塑性-它的获得的功能保持不变,而基础结构却随着时间不断变化。 这是由易碎的单点解决方案非常不同 传统工程。
This phenomenon stems primarily from overparameterization of deep neural nets. In the modern regime of gross overparameterization, optima in the loss landscape are typically high-dimensional continuous non-convex manifolds [31, 32]. This is strangely similar to biology, where identical network behavior can arise from vastly different underlying parameter configurations, forming a non-convex set in the parameter space, e.g. see [33].
这种现象主要源于深度神经网络的过度参数化。 在毛overparameterization的现代制度,最优的损失景观通常高维连续非凸歧管[ 31 , 32 ]。 这奇怪地类似于生物学,在生物学中,相同的网络行为可能源于完全不同的基础参数配置,从而在参数空间中形成了非凸集,例如,参见[ 33 ]。
Now comes the interesting part. Just like the life-long homeostatic adjustment in biology, a similar mechanism might support continual learning in overparameterized deep nets (illustrated in Figure 5, right): early-stage learning of dense connections finds a good solution manifold, along which an abundance of good sparse solutions exist; as the network ages, continual and gradual sparsification of the network can be quickly fine-tuned by structural plasticity (like the brain that maintains life-long plasticity).
现在来了有趣的部分。 就像生物学中的终生稳态调整一样,类似的机制也可能支持在超参数化的深网中进行持续学习(如图5所示,右图):密集连接的早期学习找到了一个好的解决方案流形,沿着该流形,大量的存在稀疏解决方案; 随着网络的老化,可以通过结构可塑性(例如保持终生可塑性的大脑)快速微调网络的连续性和渐进性稀疏性。
From the neurobiological perspective, if one accepts the optimizational hypothesis [3], then the life-long plasticity must carry out some functional optimization continually during lifespan. Following this logic, neural developmental disorders that arise from this process going awry should essentially be optimizational diseases, with etiological characterizations such as bad initialization, unstable optimizer dynamics, etc.
从神经生物学的角度来看,如果一个人接受 优化假设 [ 3 ],则终生可塑性必须在寿命期间连续进行一些功能优化。 遵循这种逻辑,此过程出错会导致神经发育障碍,本质上应该是优化疾病 ,其病因学特征包括初始化错误,优化程序动力学不稳定等。
Whether the aforementioned hypothesis holds true for deep neural nets in general, and adequate for them to serve as a good model for neural development and pathophysiology, are open questions for future research.
上述假设是否普遍适用于深层神经网络,以及是否足以用作神经发育和病理生理学的良好模型,是未来研究的未解决问题。
BERT学到了多少? (How much did BERT learn?)
Finally, let us apply some neuroscientific thinking to BERTology.
最后,让我们将一些神经科学的思想应用于BERTology。
We ask the question: how much information is stored in pre-trained BERT parameters relevant for solving an NLU task? It is not an easy question to answer because sequential changes in parameter values during pre-training and during fine-tuning confound each other.
我们问一个问题:在解决NLU任务相关的预训练 BERT参数中存储了多少信息? 这不是一个容易回答的问题,因为在预训练和微调期间参数值的顺序变化会相互混淆。
This limitation is no longer there in the case of BERT fine-tuned by sparsification, where pre-training only learns weight values and fine-tuning only learns structure. To a biologist, it is always good news if two stages of development involve completely different physiological processes, in which case one of them can be used to study the other.
在通过稀疏性对BERT进行微调的情况下,此限制不再存在,在这种情况下,预训练仅学习重量值,而微调仅学习结构。 对于生物学家来说,如果两个发育阶段涉及完全不同的生理过程,这总是一个好消息,在这种情况下,其中一个可以用来研究另一个。
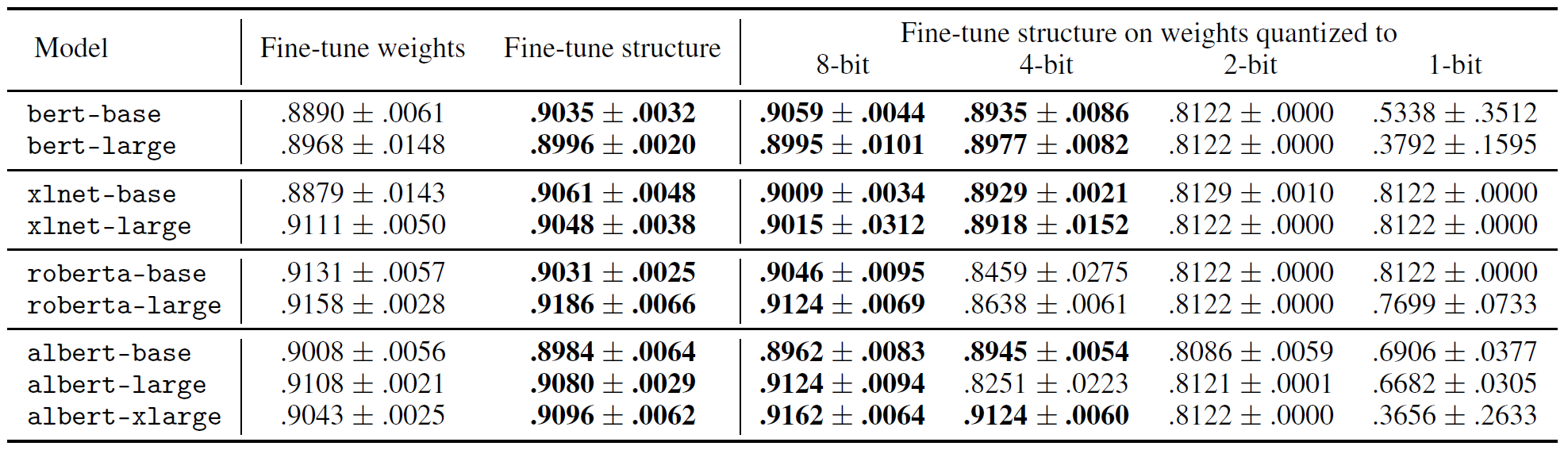
Now let us do exactly this. Let us perturb the pre-trained weight values and study the downstream consequences. For this experiment, we do not make physiological perturbations (such as lesioning attention heads), but a pharmacological one instead: systemic application of a substance that affects every single synapse in the entire brain. This drug is quantization. Table 1 summarizes some preliminary dose-responses: though BERT and related species have developed large brains, it seems knowledge learned during language pre-training might be described by just a few bits per synapse.
现在,让我们确切地执行此操作。 让我们扰动预先训练的体重值并研究下游后果。 在本实验中,我们不进行生理扰动(例如使注意力集中的部位受损),而是进行药理学干预:系统性应用一种会影响整个大脑中每个突触的物质。 这种药物是量化的。 表1总结了一些初步的剂量React:尽管BERT和相关物种已发展出大脑,但似乎在语言预训练中学习的知识可能仅用每个突触的几位来描述。
In practice, this means that, since pre-trained weights do not change values during fine-tuning by sparsification, one might only need to store a low-precision integer version of all BERT parameters without any adverse consequences — a significant compression. The upshot: all you need is a quantized integer version of pre-trained parameters shared across all tasks, with a binary mask fine-tuned for each task.
实际上,这意味着,由于预训练的权重在通过稀疏化进行微调时不会更改值,因此可能只需要存储所有BERT参数的低精度整数版本,而不会产生任何不良后果-大幅压缩。 结果: 您需要的是在所有任务之间共享的预训练参数的量化整数版本,并为每个任务微调了二进制掩码 。
Remark: Note that existing work on quantization of BERT weights quantizes fine-tuned weights (e.g. Q-BERT [34]) instead of pre-trained weights.
备注 :请注意,有关BERT权重量化的现有工作是对微调的权重(例如Q-BERT [ 34 ]) 进行量化, 而不是预先训练的权重。
结语 (Epilogue)
Deep neural nets and the brain have obvious differences: at the lowest level, in learning algorithms, and at the highest level, in general intelligence. Nevertheless, profound similarities at intermediate levels have proven beneficial for the advancement of both deep learning and neuroscience.
深度神经网络和大脑有明显的区别:在最低级别的学习算法中,在最高级别的常规智能中。 然而,事实证明,中等水平的深层相似性对深度学习和神经科学的发展都是有益的。
For instance, perceptual and cognitive neurophysiology has already inspired effective deep network architectures which in turn make a useful model for understanding the brain. In this essay, we proposed another point of intersection: biological neural development might inspire efficient and robust optimization procedures which in turn serve as a useful model for maturation and aging of the brain.
例如,知觉和认知神经生理学已经激发了有效的深度网络架构 ,从而为理解大脑提供了有用的模型。 在本文中,我们提出了另一个交叉点:生物神经发育可能会激发出高效,鲁棒的优化程序 ,进而可以作为大脑成熟和老化的有用模型。
Remark: It should be noted that neural development in the context of traditional connectionism was proposed in the 1990s (e.g. see [35]).
备注 :应该指出的是,传统连接主义背景下的神经发展是在1990年代提出的(例如,参见[ 35 ]) 。
Specifically, we have reviewed some recent results on weight learning and structural learning as complementary means to optimization, and how they, in combination, realize efficient transfer learning in large language models.
具体来说,我们回顾了一些有关权重学习和结构学习的最新结果,这些结果是优化的补充手段,以及它们如何结合起来在大型语言模型中实现有效的转移学习。
As structural learning becomes increasingly important in deep learning, we shall see corresponding hardware accelerators emerge (e.g. Nvidia’s Ampère architecture supporting sparse weights [36]). This is likely to bring about a new wave of architectural diversification of specialized hardware — acceleration of structural learning requires smart data movement adapted to specific computations, a new frontier for exploration.
随着结构学习在深度学习中变得越来越重要,我们将看到相应的硬件加速器应运而生(例如,支持稀疏权重的Nvidia的Ampère体系结构[ 36 ])。 这可能会带来专用硬件的架构多样化的新潮流-加速结构学习需要结构适应特定计算的智能数据移动,这是探索的新领域。
翻译自: https://towardsdatascience.com/the-curious-case-of-developmental-bertology-d601ec52f69d


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









