





机器学习算法应用
definition:
定义:
Machine Learning is the science of programming computers so they can learn from data.
机器学习是对计算机编程的科学,因此它们可以从数据中学习 。
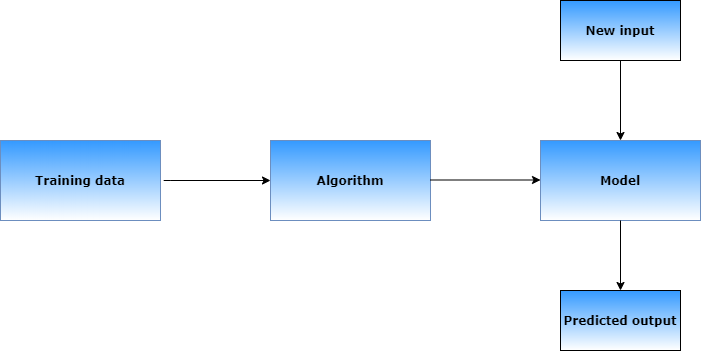
We provide training data to the system then we pass this data through an algorithm which creates a model now the new input(test data) is passed through the model which in turn gives predicted output so basically the model is trained using this training data.
我们向系统提供训练数据,然后通过算法将数据传递给算法,该算法现在会创建模型,新的输入(测试数据)会通过模型传递,而模型又会提供预测的输出,因此基本上使用此训练数据对模型进行了训练。
The model is a mathematical representation of a real-world process. Suppose we take an example of the general equation of a straight line y=mx+c, so here y is the output of the machine learning model and x is the input variable which the user will be providing m and c are the parameters which will be obtained by training the model.
该模型是现实过程的数学表示。 假设我们以直线y = mx + c的一般方程为例,因此这里y是机器学习模型的输出,x是用户将要提供的输入变量,而c是将要提供的参数通过训练模型获得
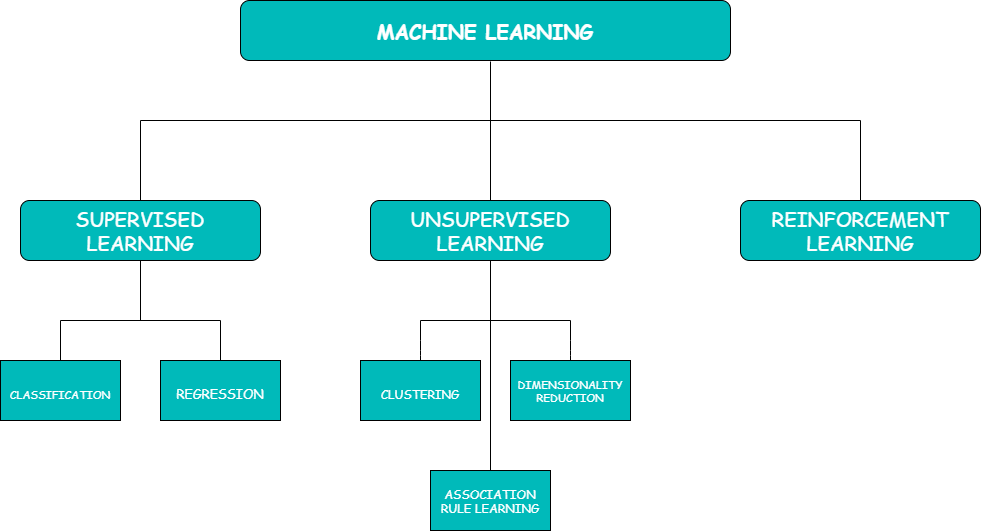
Types of Machine Learning:
机器学习的类型:
There are mainly three types
主要有三种
- Supervised Learning 监督学习
- Unsupervised Learning 无监督学习
- Reinforcement Learning 强化学习
监督学习 (Supervised Learning)
Here the algorithm takes both input and output of those data and trains the model. The model makes predictions based on the given data and the output is corrected by training data. This process continues until the algorithm achieves an acceptable level of performance.
在这里,算法同时获取这些数据的输入和输出,并训练模型。 该模型根据给定的数据进行预测,并通过训练数据对输出进行校正。 这个过程一直持续到算法达到可接受的性能水平。
The supervised learning is of two categories:
监督学习分为两类:
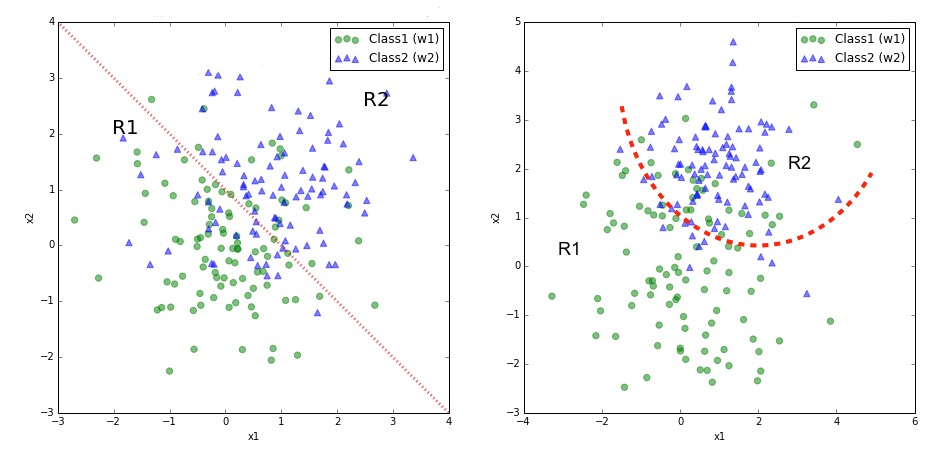
Classification:
分类:
When the output variable is categorical or discrete it is considered a classification problem
当输出变量是分类变量或离散变量时,则视为分类问题
Some cases where classification is used: To find whether an email received is spam or not, handwriting recognition.
使用分类的某些情况:要识别收到的电子邮件是否为垃圾邮件,请手写识别。
Regression:
回归:
When the output variable is continuous it is considered a regression problem.
当输出变量为连续变量时,将其视为回归问题。
Regression is used in predicting housing prices, predict rainfall using different atmospheric parameters like temperature.
回归用于预测房价,使用不同的大气参数(例如温度)来预测降雨。
Some important supervised learning algorithms are:
一些重要的监督学习算法是:
- K-nearest neighbours K近邻
- Linear Regression 线性回归
- Logistic Regression 逻辑回归
- SVM( Support Vector Machine ) 支持向量机
- Decision Tree and Random Forests 决策树和随机森林
- Neural Networks 神经网络
无监督学习 (Unsupervised Learning)
In Unsupervised learning, there is only input data and no corresponding output data and there is no “supervisor” to teach the algorithm, unlike the supervised learning. Here the algorithm is left on its own to find a pattern in the data and then it gives the output. In Unsupervised learning, we work with “unlabelled” data which means no extra effort is needed to convert that unlabelled data into machine-readable form hence we can work with the larger dataset.
与无监督学习不同,在无监督学习中,只有输入数据而没有相应的输出数据,并且没有“监督者”来教算法。 在这里,算法独自工作以在数据中查找模式,然后给出输出。 在无监督学习中,我们使用“未标记”数据,这意味着无需付出额外的努力即可将未标记数据转换为机器可读形式,因此我们可以使用更大的数据集。
Unsupervised learning is of two categories:
无监督学习分为两类:
Clustering:
聚类:
In this process, data is grouped based on the similarity of the data-points. Clustering is used for identifying cancer cells, it is used in google news.
在此过程中,将根据数据点的相似性对数据进行分组。 聚类用于识别癌细胞,它在Google新闻中使用。
Dimensionality Reduction:
降维:
Dimensionality reduction refers to techniques that reduce the number of input variables in a dataset. It helps in visualizing data
降维是指减少数据集中输入变量数量的技术。 它有助于可视化数据
Association Rule Learning:
关联规则学习:
The goal of Association Rule Learning is to dig into large amounts of data and discover interesting relations between data. It is used in data analysis.
关联规则学习的目的是挖掘大量数据并发现数据之间有趣的关系。 它用于数据分析。
Some important algorithms of unsupervised learning are:
无监督学习的一些重要算法是:
- Hierarchical Cluster Analysis (HCA) 层次聚类分析(HCA)
- k-Means k均值
- Principal Component Analysis (PCA) 主成分分析(PCA)
- Apriori 阿普里里
强化学习: (Reinforcement Learning:)
The learning system called an agent which observe the environment, select and perform actions, and get rewards or penalties in return. It must then learn by itself what is the best strategy, called a policy, to get the most reward over time. A policy defines what action the agent should choose when it is in a given situation. Here the learning takes place using the hit and trial method.
这种学习系统称为代理 ,负责观察环境,选择并执行动作,并获得回报或惩罚 。 然后,它必须自己了解什么是最好的策略(称为策略) ,以便随着时间的推移获得最大的回报。 策略定义了代理在给定情况下应选择的操作。 在这里,学习是使用点击和尝试方法进行的。
Reinforcement Learning is used in Robotics, games.
强化学习用于机器人技术,游戏中。

摘要: (Summary:)
翻译自: https://medium.com/swlh/machine-learning-definition-types-algorithms-applications-b58321dd6bc3
机器学习算法应用















 3077
3077











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









