





机器学习 神经网络 神经元
Neural networks are, with no doubt, the most popular machine learning technique that is used nowadays. So, I think it is worth understanding how they actually learn.
毫无疑问,神经网络是当今使用最广泛的机器学习技术。 因此,我认为值得了解他们的实际学习方式。
To do so, let us first take a look at the image below:
为此,让我们首先看下图:

If we represent the input and output values of each layer as vectors, the weights as matrices, and biases as vectors, then we get the above-flattened view of a neural network which is just a sequence of vector function applications. That is, functions that take vectors as input, do some transformation on them, and they output other vectors. In the image above, each line represents a function, which can be either a matrix multiplication plus a bias vector, or an activation function. And the circles represent the vectors on which these functions operate.
如果我们将每一层的输入和输出值表示为矢量,将权重表示为矩阵,将偏差表示为矢量,那么我们得到的上述神经网络视图只是矢量函数应用的序列而已。 即,将向量作为输入的函数,对其进行一些转换,然后输出其他向量。 在上图中,每条线代表一个函数,该函数可以是矩阵乘法加偏置矢量,也可以是激活函数。 圆圈代表这些函数所作用的向量。
For example, we start with the input vector, then we feed it into the first function, which computes linear combinations of its components, then we obtain another vector as output. This last vector we feed as input to the activation function, and so on until we get to the last function in our sequence. The output of this last function will be the predicted value of our network.
例如,我们从输入向量开始,然后将其输入第一个函数,该函数计算其分量的线性组合,然后获得另一个向量作为输出。 我们将最后一个向量作为激活函数的输入,依此类推,直到获得序列中的最后一个函数。 最后一个函数的输出将是我们网络的预测值。
We have discussed so far how a neural network gets its output, which we are interested in, it just passes its input vector through a sequence of functions. But these functions depend on some parameters: the weights and biases.
到目前为止,我们已经讨论了神经网络如何获取其感兴趣的输出,它只是将其输入向量通过一系列函数传递。 但是这些功能取决于一些参数:权重和偏差。
How do we actually learn those parameters in order to obtain good predictions?
我们实际上如何学习这些参数以获得良好的预测?
Well, let us recall what a neural network actually is: it is just a function, a big function composed of smaller ones that are applied in sequence. This function has a set of parameters that, because at first, we have no idea what they should be, we just initialize them randomly. So, at first, our network will give us just random values. How we can improve them? Before attempting to improve them we first need a way of evaluating the performance of our network. How we are supposed to improve the performance of our model if we do not have a way to measure how good or how bad is it doing?
好吧,让我们回想一下神经网络实际上是什么:它只是一个函数,是由按顺序应用的较小函数组成的大函数。 这个函数有一组参数,因为起初我们不知道它们应该是什么,我们只是随机地初始化它们。 因此,起初,我们的网络将只给我们随机值。 我们如何改善它们? 在尝试改进它们之前,我们首先需要一种评估网络性能的方法。 如果我们没有办法衡量模型的优劣,应该如何改善模型的性能?
For that, we need to come up with a function that takes as input the predictions of our network and the true labels in our dataset, and to give us a number which represents the performance of our network. Then we can turn the learning problem into an optimization problem of finding the minimum or maximum of this function. In the machine learning community, this function usually measures how bad our predictions are, hence it is named a loss function. And our problem is to find the parameters of our network that minimizes this loss function.
为此,我们需要提出一个函数,该函数将网络的预测和数据集中的真实标签作为输入,并提供一个代表网络性能的数字。 然后, 我们可以将学习问题转化为寻找该函数的最小值或最大值的优化问题 。 在机器学习社区中,该函数通常衡量我们的预测有多糟糕,因此被称为损失函数 。 我们的问题是找到使该损耗函数最小化的网络参数。
随机梯度下降 (Stochastic gradient descent)
You may be familiar with the problem of finding the minimum of a function from your calculus class. There you usually take the gradient of your function, set it equal to 0, find all the solutions (also called critical points), and then choose among them the one that gives your function the smallest value. And that is the global minimum. Can we do the same thing in minimizing our loss function? Not really. The problem is that the loss function of a neural network is not as nice and compact as those you usually find in calculus textbooks. It is an extremely complicated function with thousands, hundreds of thousands, or even millions of parameters. It may be even impossible to find a closed-form solution to this problem. This problem is usually approached by iterative methods, methods that do not try to find a direct solution, but instead, they start with a random solution and try to improve it a little bit in each iteration. Eventually, after a large number of iterations, we will get a rather good solution.
您可能对从演算类中找到函数最小值的问题很熟悉。 通常在该处获取函数的梯度,将其设置为0,找到所有解(也称为临界点),然后在其中选择使函数具有最小值的梯度。 这是全球最低要求。 我们可以在最小化损失函数方面做同样的事情吗? 并不是的。 问题在于神经网络的损失函数不如微积分教科书中通常所见的那么好和紧凑。 它是具有数千,数十万甚至数百万个参数的极其复杂的功能。 甚至不可能找到对此问题的封闭式解决方案。 这个问题通常是通过迭代方法解决的,这些方法不尝试寻找直接解决方案,而是以随机解决方案开始,并尝试在每次迭代中对其进行一些改进。 最终,经过大量的迭代,我们将获得一个很好的解决方案。
One such iterative method is gradient descent. As you may know, the gradient of a function gives us the direction of the steepest ascent, and if we take the negative of the gradient it will give us the direction of the steepest descent, that is the direction in which we can get the fastest towards a minimum. So, at each iteration, also called an epoch, we compute the gradient of the loss function and subtract it (multiplied by a factor called learning rate) from the old parameters to get the new parameters of our network.
一种这样的迭代方法是梯度下降 。 如您所知,函数的梯度为我们提供了最陡的上升方向,如果我们取梯度的负值,它将为我们提供最陡的下降方向,即我们可以最快得到的方向走向最小。 因此,在每次迭代(也称为历元)时,我们都会计算损失函数的梯度,并从旧参数中减去(乘以称为学习率的因子)以获得网络的新参数。

Where θ (theta) represents a vector containing all the network’s parameters.
其中θ(theta)代表一个包含所有网络参数的向量。
In the standard gradient descent method, the gradient is computed considering the whole dataset. Usually, this is not desirable as it may be computationally expensive. In practice, the dataset is randomly divided into more chunks called batches, and an update is made for each one of these batches. This is called stochastic gradient descent.
在标准梯度下降方法中,考虑整个数据集来计算梯度。 通常,这是不希望的,因为它可能在计算上很昂贵。 在实践中,数据集被随机分为更多的块,称为批处理,并对这些批处理中的每一个进行更新。 这称为随机梯度下降 。
The above update rule considers at each step only the gradient evaluated at the current position. In this way, the trajectory of the point that moves on the surface of the loss function is sensitive to any perturbation. Sometimes we may want to make this trajectory more robust. For that, we use a concept inspired from physics: momentum. The idea is that when we do the update to also take into consideration previous updates, that accumulates into a variable Δθ. If more updates are done in the same direction, then we will go “faster” into that direction and will not change our trajectory by any small perturbation. Think about this like velocity.
上面的更新规则在每个步骤仅考虑在当前位置评估的梯度。 这样,在损失函数的表面上移动的点的轨迹对任何扰动都很敏感。 有时我们可能想使此轨迹更健壮。 为此,我们使用了一个受物理学启发的概念: 动量 。 这个想法是,当我们进行更新时还考虑到先前的更新时,会累积为变量Δθ。 如果在同一方向上进行更多更新,那么我们将“更快”地朝该方向前进,并且不会因任何小扰动而改变我们的轨迹。 考虑一下速度。
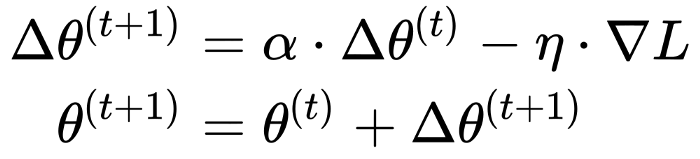
Where α is a non-negative factor that determines the contribution of past gradients. When it is 0, we simply do not use momentum.
其中α是一个非负因素,它决定了过去梯度的贡献。 当它为0时,我们根本不使用动量。
反向传播 (Backpropagation)
How do we actually compute the gradient? Recall that a neural network, and thus the loss function, is just a composition of functions. How we can compute partial derivatives of composite functions? Using chain rule. Let us look at the following image:
我们如何实际计算梯度? 回想一下,神经网络以及损失函数只是功能的组合。 我们如何计算复合函数的偏导数? 使用链式规则。 让我们看下图:

If we want to compute the partial derivatives of the loss w.r.t. (with respect to) the weights of the first layer: we take the derivative of the first linear combination w.r.t. the weights, then we multiply with the derivative of the next function (the activation function) w.r.t. the output from the previous function, and so on until we multiply with the derivative of the loss w.r.t. the last activation function. What if we want to compute the derivative w.r.t. the weights of the second layer? We have to do the same process, but this time we start with the derivative of the second linear combination function w.r.t. its weights, and after that, the rest of the terms that we have to multiply with were also present when we computed the derivative of the weights of the first layer. So, instead of computing these terms over and over again, we will go backward, hence the name backpropagation.
如果我们要计算损失wrt( 相对于 )第一层权重的偏导数:我们取权重的第一个线性组合的导数,然后乘以下一个函数的导数(激活函数)从前一个函数的输出,依此类推,直到将最后一个激活函数与损失的导数相乘。 如果我们想计算第二层权重的导数怎么办? 我们必须执行相同的过程,但是这次我们从第二个线性组合函数的导数及其权重开始,此后,当我们计算的导数时,还存在与我们相乘的其余项。第一层的权重。 因此,我们将向后走,而不是一遍又一遍地计算这些术语,因此命名为backpropagation 。
We will first start by computing the derivative of the loss w.r.t. the output of our network, and then propagate these derivatives backward towards the first layer by maintaining a running product of derivatives. Note that there are 2 kinds of derivatives that we take: one in which we compute the derivative of a function w.r.t. its input. These we multiply to our product of derivatives and have the purpose to keep track of the error of the network from its output to the current point in which we are in the algorithm. The second kind of derivatives are those that we take w.r.t. the parameters that we want to optimize. These we do not multiply with the rest of our product of derivatives, instead, we store them as part of the gradient that we will use later to update the parameters.
我们将首先从计算网络输出的损耗导数开始,然后通过维持导数的乘积来将这些导数向后传播到第一层。 请注意,我们采用2种导数:一种是通过函数的输入计算函数的导数。 我们将这些乘积乘以导数的乘积,目的是跟踪从网络输出到算法所处当前点的网络误差。 第二类导数是我们使用要优化的参数得到的那些。 我们不将它们与剩余的导数乘积相乘,而是将它们存储为渐变的一部分,稍后将用于更新参数。
So, while backpropagation, when we encounter functions that do not have learnable parameters (like activation functions) we take derivatives only of the first kind, just to propagate the errors backward. But, when we encounter functions that do have learnable parameters (like the linear combinations, we have there the weights and biases that we want to learn) we take derivatives of both kinds: the first one w.r.t. its input for error propagation, and the second one w.r.t. its weights and biases, and store them as part of the gradient. We do this process starting from the loss function and until we get to the first layer where we do not have any learnable parameters that we want to add to the gradient. This is the backpropagation algorithm.
因此,在反向传播中,当我们遇到没有可学习参数的函数(例如激活函数)时,我们仅采用第一类导数,只是将错误向后传播。 但是,当我们遇到确实具有可学习参数的函数时(例如线性组合,我们就有了要学习的权重和偏差),我们会同时使用两种类型的导数:第一个输入其错误传播输入,第二个输入一个权重和偏差,并将其存储为渐变的一部分。 我们从损失函数开始执行此过程,直到到达第一层,这里我们没有要添加到渐变的任何可学习的参数。 这是反向传播算法。
Softmax激活和交叉熵损失 (Softmax activation & Cross entropy loss)
A commonly used activation function for the last layer in a classification task is the softmax function.
分类任务中最后一层的常用激活函数是softmax函数。

The softmax function transforms its input vector into a probability distribution. If you look above you can see that the elements of the softmax’s output vector have the properties that they are all positive, and their sum is 1. When we use softmax activation we create in the last layer as many nodes as the number of classes in our dataset, and the softmax activation will give us a probability distribution over the possible classes. So, the output of the network will give us the probability that the input vector belongs to each one of the possible classes, and we choose the class that has the highest probability and reports that as the prediction of our network.
softmax函数将其输入向量转换为概率分布。 如果您在上面看,您会看到softmax的输出向量的元素具有全部为正的属性,其总和为1。当我们使用softmax激活时,我们在最后一层创建的节点数与其中的类数相同。我们的数据集,以及softmax激活将为我们提供可能类别上的概率分布。 因此,网络的输出将为我们提供输入向量属于每种可能类别的概率,并且我们选择具有最高概率的类别并将其报告为网络的预测。
When softmax is used as activation of the output layer, we usually use as loss function the cross-entropy loss. The cross-entropy loss measures how similar are 2 probability distributions. We can represent the true label of our input x as a probability distribution: one in which we have a probability of 1 for the true class label and 0 for the other class labels. This representation of labels is also called one-hot encoding. Then we use cross-entropy to measure how close is the predicted probability distribution of our network to the true one.
当将softmax用作输出层的激活时,我们通常将交叉熵损耗用作损耗函数。 交叉熵损失衡量2个概率分布的相似程度。 我们可以将输入x的真实标签表示为概率分布:其中一个真实类别标签的概率为1,其他类别标签的概率为0。 标签的这种表示方式也称为一次性编码。 然后,我们使用交叉熵来衡量我们的网络的预测概率分布与真实网络的接近程度。

Where y is the one-hot encoding of the true label, y hat is the predicted probability distribution, and yi, yi hat are elements of those vectors.
其中y是真实标签的单次编码,y hat是预测的概率分布,yi和yi hat是这些向量的元素。
If the predicted probability distribution is close to the one-hot encoding of the true labels, then the loss would be close to 0. Otherwise, if they are hugely different, the loss can potentially grow to infinity.
如果预测的概率分布接近真实标签的单次编码,则损失将接近0。否则,如果它们相差很大,则损失可能会增长到无穷大。
均方误差损失 (Mean squared error loss)
The softmax activation and cross-entropy loss are mainly for classification tasks, but neural networks can easily be adapted to regression tasks by just using an appropriate loss function and activation in the last layer. For example, if instead of class labels as ground truth, we have a list of numbers that we want to approximate we can use mean squared error (MSE for short) loss. Usually, when we use MSE loss, we use the identity activation (that is, f(x) = x) in the last layer.
softmax激活和交叉熵损失主要用于分类任务,但是仅在最后一层使用适当的损失函数和激活,神经网络就可以轻松地适应回归任务。 例如,如果不是将类标签作为基本事实,而是要列出近似的数字,则可以使用均方误差(简称MSE)损失。 通常,当我们使用MSE损失时,我们在最后一层使用身份激活(即f(x)= x)。
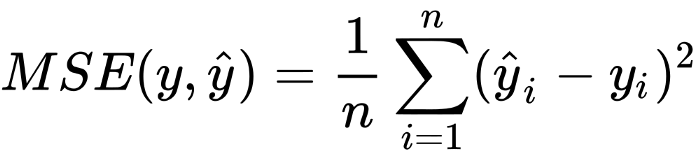
To conclude, the learning process of a neural network is nothing more than just an optimization problem: we want to find the parameters that minimize a loss function. But that is not an easy task, there are whole books written about optimization techniques. And, besides optimization, there also arise problems about which neural network architecture to choose for a given task.
总而言之,神经网络的学习过程无非是一个优化问题:我们想找到使损失函数最小的参数。 但这并不是一件容易的事,整本书中都有关于优化技术的文章。 并且,除了优化之外,还会出现关于为给定任务选择哪种神经网络体系结构的问题。
I hope you found this article useful and thanks for reading!
希望本文对您有所帮助,并感谢您的阅读!
翻译自: https://medium.com/towards-artificial-intelligence/how-do-neural-networks-learn-61686d2aea20
机器学习 神经网络 神经元















 3444
3444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









