





句子匹配 无监督
重点 (Top highlight)
TL; DR (TL;DR)
To date, models learn fixed size representation of sentences, typically with some form of supervision, which are then used for sentence similarity or other downstream tasks. Examples of this are Google’s Universal sentence encoder (2018) and Sentence transformers (2019). Supervised learning of fixed size representations tends to outperform unsupervised creation of sentence representations, with few exceptions such as a recently published work (SBERT-WK, June 2020) in which fixed sentence representations are created by an information content-driven weighted average of word vectors extracted from different layers of a BERT model (there have been similar prior approaches of pooling of word vectors across layers that have not comparatively performed well in tasks, however).
迄今为止,模型通常使用某种形式的监督来学习句子的固定大小表示形式,然后将其用于句子相似度或其他下游任务。 例如Google的通用句子编码器(2018)和句子转换器(2019) 。 固定大小表示形式的监督学习往往优于无监督的句子表示形式的创建,只有少数例外,例如最近出版的工作(SBERT-WK,2020年6月) ,其中通过信息内容驱动的单词向量加权平均值来创建固定句子表示形式从BERT模型的不同层中提取(已有类似的 跨字向量池合并的 现有方法 ,但是在任务中表现不佳)。
For the specific task of sentence similarity, an alternate simple approach described below represents a sentence as an unordered set of word representations, and uses the set as is, without converting it into a fixed size vector. The word representations are learned by BERT during pre-training/fine tuning without any labeled data. This simple set representation of a sentence, which apparently seems to be like a bag-of-words representation, performs almost as well as the models mentioned above for short sentences and even better than them qualitatively (needs to quantified with a full test) as sentence length increases. This is perhaps in part because, the words (“words” here is used for full words and subword tokens in BERT’s vocabulary) composing a sentence, all of which are drawn from BERT’s fixed-size vocabulary of 30,000 words and whose learned vectors are context insensitive (e.g. all senses of the word “cell” is collapsed into one vector), can still be used represent context sensitive aspects of a word by mapping those words to other words within the BERT’s vocabulary that captures their sense in a sentence — this mapping being accomplished by a BERT model with a Masked language model (MLM) head.
对于句子相似性的特定任务,下面介绍的另一种简单方法是将句子表示为单词表示的无序集合,并按原样使用该集合,而无需将其转换为固定大小的向量。 BERT在预训练/微调期间学习了单词表示形式,没有任何标记数据。 这个句子的简单集合表示形式,看起来似乎像一个词袋表示形式,其表现几乎与上述短句模型一样好,并且在质量上甚至优于它们(需要通过全面测试进行量化) ,句子长度增加。 这可能部分是因为单词(此处的“单词”用于BERT词汇中的完整单词和子单词标记)构成了一个句子,所有这些单词均来自BERT的30,000个固定大小的词汇,并且其学习的向量是上下文不敏感的(例如,单词“ cell”的所有含义都折叠成一个向量) ,仍然可以通过将这些单词映射到BERT词汇表中的其他单词(在句子中捕获其含义)来表示单词的上下文相关方面。由带有蒙版语言模型(MLM)头的BERT模型完成。
The advantages of this approach are
这种方法的优点是
- we avoid the need for labeled data unlike the two supervised models mentioned above. 与上面提到的两个监督模型不同,我们避免了标记数据的需求。
The representation quality for sentence similarity tasks does not degenerate with sentence length — a limitation we observe with both Universal sentence encoder, sentence transformer (figures below show a qualitative comparison) and the unsupervised model - SBERT-WK
句子相似性任务的表示质量不会随着句子的长度而降低-我们在通用句子编码器,句子转换器(以下图显示了定性比较)和无监督模型-SBERT-WK上都观察到的局限性
Representing a sentence as words enables interpreting the results of a sentence similarity task — useful property models learning fixed representations are generally deficient in. For instance, the sorted list of sentences similar to an input sentence (within the distribution tail where we can harvest similar sentences), in all the models mentioned above, would often contain at least few sentences, where the semantic relationship to the input sentence is not obvious at all, even if there was one.
将句子表示为单词可以解释句子相似性任务的结果-学习固定表示形式的有用属性模型通常不足。例如,类似于输入句子的句子排序列表(在分布尾巴中,我们可以收获相似的句子) ) ,在上述所有模型中,通常都会包含至少几个句子,即使输入的句子与输入句子之间的语义关系一点也不明显。
The simplicity of this approach not only enables us perform similarity tasks without labeled data, but also serve as a baseline performance to benchmark future models that output fixed size sentence representations and can potentially outperform this simple approach.
这种方法的简单性不仅使我们能够在没有标签数据的情况下执行相似性任务,而且还可以作为基准性能来对将来的模型进行基准测试,这些模型可以输出固定大小的句子表示形式,并且有可能胜过这种简单的方法。
参考实施细节 (Reference implementation details)
As examined in an earlier post, BERT’s raw embeddings capture distinct and separable information about any word, either standalone or in the context of a sentence (using BERT MLM head), in terms of words and subwords in its fixed size vocabulary. This is used to create a sentence signature composed of a subset of these words for sentence similarity tasks.
正如先前文章中所检查的那样 ,BERT的原始嵌入以固定大小的词汇表中的单词和子单词的形式捕获关于任何单词的不同且可分离的信息,无论是独立单词还是句子上下文(使用BERT MLM头) 。 这用于创建由这些单词的子集组成的句子签名,用于句子相似性任务。

For instance, consider the longer sentence below, “Connan went to prison cell with a cellphone to draw blood cell samples from inmates”. The tokenized version of this maps this sentence to BERT’s vocabulary of ~30,000 tokens (bert-large-cased). With the exception of two input terms “Connan” and “cellphone”, the rest are all one-to-one mappings. The key point here being the tokenized version of input can be used to find corresponding learned vectors in BERT’s vocabulary.
例如,考虑下面较长的句子: “康南用手机去监狱牢房从囚犯那里抽取血细胞样本” 。 此标记的版本将这句话映射到BERT的词汇表〜30,000个标记(bert-large-cased) 。 除了两个输入项“ Connan”和“手机”外,其余都是一对一的映射。 此处的关键点是输入的标记化版本,可用于在BERT词汇表中查找相应的学习向量。

These token vectors when passed through BERT’s model (MLM head) get transformed to vectors that represent context sensitive meaning of those words. This is best illustrated by examining the word “cell” used in the above sentence. The top 3 neighbors (this choice is arbitrary — we can pick top k neighbors so long as they are from the distribution tail) of the word “cell” map to different words in BERT’s vocabulary once they pass through the model. The “cell” representing prison has the meaning of a room, whereas the “cell” used in cellphone context captures the notion of a car. The meaning of the word “cell” in biological context has the notion of biological cell (the fifth neighbor not shown is tissue). In essence, even though the meaning of the word “cell” changes with context, we can still find corresponding vectors capturing its context sensitive sense in BERT’s learned vocabulary. Given this, we can use the vectors for the tokenized text as well as the top k neighbors for each token after it passes through BERT model (MLM head) to be the signature of this sentence.
这些令牌向量在通过BERT模型(MLM头)传递时,将转换为表示这些单词的上下文相关含义的向量。 最好通过检查以上句子中使用的“单元”一词来说明。 一旦通过模型,“单元”一词的前3个邻居(此选择是任意的,只要它们来自分布尾部 , 我们就可以选择k个邻居)映射到BERT词汇表中的其他单词。 代表监狱的“牢房”具有房间的含义,而手机上下文中使用的“牢房”则捕捉到了汽车的概念。 生物学语境中“细胞”一词的含义具有生物学细胞的概念(未显示的第五个邻居是 组织 )。 从本质上讲,即使“单元”一词的含义随上下文而改变,我们仍然可以在BERT的学习词汇中找到捕获其上下文敏感意义的相应向量。 鉴于此,我们可以将标记令牌文本的向量以及每个令牌经过BERT模型(MLM头)作为该句子的签名后,使用每个令牌的前k个邻居。
When picking the top k neighbors, single character tokens such as punctuation that show up as predictions are ignored. We can safely do this so long as the tail has sufficient tokens to choose from, which is indeed the case in practice.
选择前k个邻居时,将忽略出现在预测中的标点符号之类的单字符标记。 只要尾巴有足够的令牌可供选择,我们就可以安全地这样做,实际上的确如此。
In essence, given a sentence of length N, assuming the tokenized version is of length M, the signature for the sentence would M*(1 + k), where k is the number of top neighbors we pick after passing the sentence through BERT. The signature of the sentence would be a matrix with M*(1+k) rows and D columns, where D is the dimension (1024 for bert-large-cased).
从本质上讲,给定一个长度为N的句子,假设标记化版本的长度为M,则该句子的签名将为M *(1 + k),其中k是在将该句子通过BERT之后我们选择的顶级邻居的数量。 句子的签名将是一个具有M *(1 + k)行和D列的矩阵,其中D是维度(对于bert-large-cased是1024) 。
计算句子相似度分数的步骤 (Steps to compute sentence similarity score)
Once the signature of a sentence is computed as described above, we can compute the similarity score between two sentences as shown below in the prototype/reference implementation
一旦如上所述计算了句子的签名,我们就可以计算出两个句子之间的相似度得分,如下所示在原型/参考实现中

When computing the similarity of an input sentence with a known set of sentences (e.g. document titles), the pairwise scores computed above is used to compute a relative score of closeness of the input sentence to all sentences in the known set.
当计算输入句子与一组已知句子(例如,文档标题)的相似度时,上面计算的成对分数用于计算输入句子与该已知集合中所有句子的接近度的相对分数。
The weighting function in the score computation above is based on the occurrence frequency of terms in a reference corpus. Essentially the contribution of cosine similarity between word pairs created from two sentence signatures is weighted by the importance of that score to the similarity computation as a function of the occurrences of those terms in a reference corpus. This ensures glue words like “the”, “of” that occur in a sentence contribute less than words that truly capture meaning. The relative lengths of the sentence pairs are also factored in the score computation to ensure short sentences pick longer sentences that are similar as opposed to the other way around. This is particularly useful when using this approach for document search where sentences in the document are converted to sentence signatures.
以上得分计算中的加权函数是基于参考语料库中术语的出现频率。 本质上,由两个句子签名创建的单词对之间的余弦相似度的贡献是根据该分数对相似度计算的重要性进行加权的,该分数是这些术语在参考语料库中的出现的函数。 这确保了句子中出现的诸如“ the”,“ of”之类的胶粘词的贡献少于真正捕捉含义的单词。 句子对的相对长度也计入分数计算中,以确保短句子选择更长的句子,而相反,相反。 当使用此方法进行文档搜索时,此功能特别有用,其中文档中的句子被转换为句子签名。
句子相似度任务中模型表现的定性比较 (A qualitative comparison of model performance in sentence similarity task)
Two sets of sentences characterizing short (average sentence length 8 words) and long sentences (average sentence length 51 words) are used to qualitatively compare the three models (Universal sentence encoder- USE, sentence transformer, and SBERT-WK) with the similarity computation approach described above.
使用两组分别描述短句(平均句子长度为8个单词)和长句(平均句子长度为51个单词)的句子来定性比较这三种模型(通用句子编码器USE,句子转换器和SBERT-WK)与相似度计算上述方法。
The short sentence set is largely composed of test sentences showcased by USE and sentence transformers in their publications.
短句集主要由USE和句子转换器在其出版物中展示的测试句子组成。
The long sentence set is extracted from Fasttext data where humans have labeled sentences into 14 categories. These categories are not strict categories — a sentence could potentially belong to multiple categories in some cases. Also, some of the test sentences are multiple sentences — almost representing a mini paragraph.
长句子集是从Fasttext数据中提取的,其中人类将句子标记为14类。 这些类别不是严格的类别-在某些情况下一个句子可能属于多个类别。 另外,一些测试句子是多个句子-几乎代表一个迷你段落。
Three sentences belonging to a single cluster/category are used to represent a group, with a total of 42 sentences belonging to 14 clusters (with the caveat mentioned earlier about the longer sentences set having some sentences belonging to multiple clusters). Few clusters from both these tests are shown below.
属于单个聚类/类别的三个句子用于表示一个组,共有42个句子属于14个聚类(前面提到的关于较长句子集的警告有一些属于多个聚类的句子) 。 这两个测试中很少有群集显示如下。


In general,
一般来说,
- All four models perform well qualitatively on the small sentence test. We can see light shades of 3x3 cells along the diagonal below for all models. 在小句子测试中,所有四个模型在质量上都表现良好。 我们可以看到以下所有对角线的3x3单元的阴影。
- There is a visible degradation of performance on the larger test for both USE and sentence transformers. There are about 3 light colored 3x3 grids along the diagonal as opposed to the expected 14 grids. SBERT-WK appears to have more 3x3 grids along the diagonal although they are not distinct from the rest of the cells in the heat map. Also, the overall brightness of the heat map increases for SBERT-WK from short to long sentences, indicative of the fact the distribution tail of similarity measure between sentences is not distinct for the long sentence case. USE and sentence transformers, in contrast, preserve the distinction of the tail for both short and long sentences but have fewer 3x3 grids in the tail. 对于USE和句子转换器来说,在较大的测试中性能明显下降。 沿对角线大约有3个浅色3x3网格,与预期的14个网格相反。 SBERT-WK似乎在对角线上有更多的3x3网格,尽管它们与热图中的其他单元格没有区别。 同样,对于SBERT-WK,从短句子到长句子,热图的总体亮度会增加,这表明在长句子情况下句子之间相似性度量的分布尾部并不明显。 相比之下,USE和句子转换器在短句子和长句子中都保留了尾部的区别,但尾部的3x3网格较少。



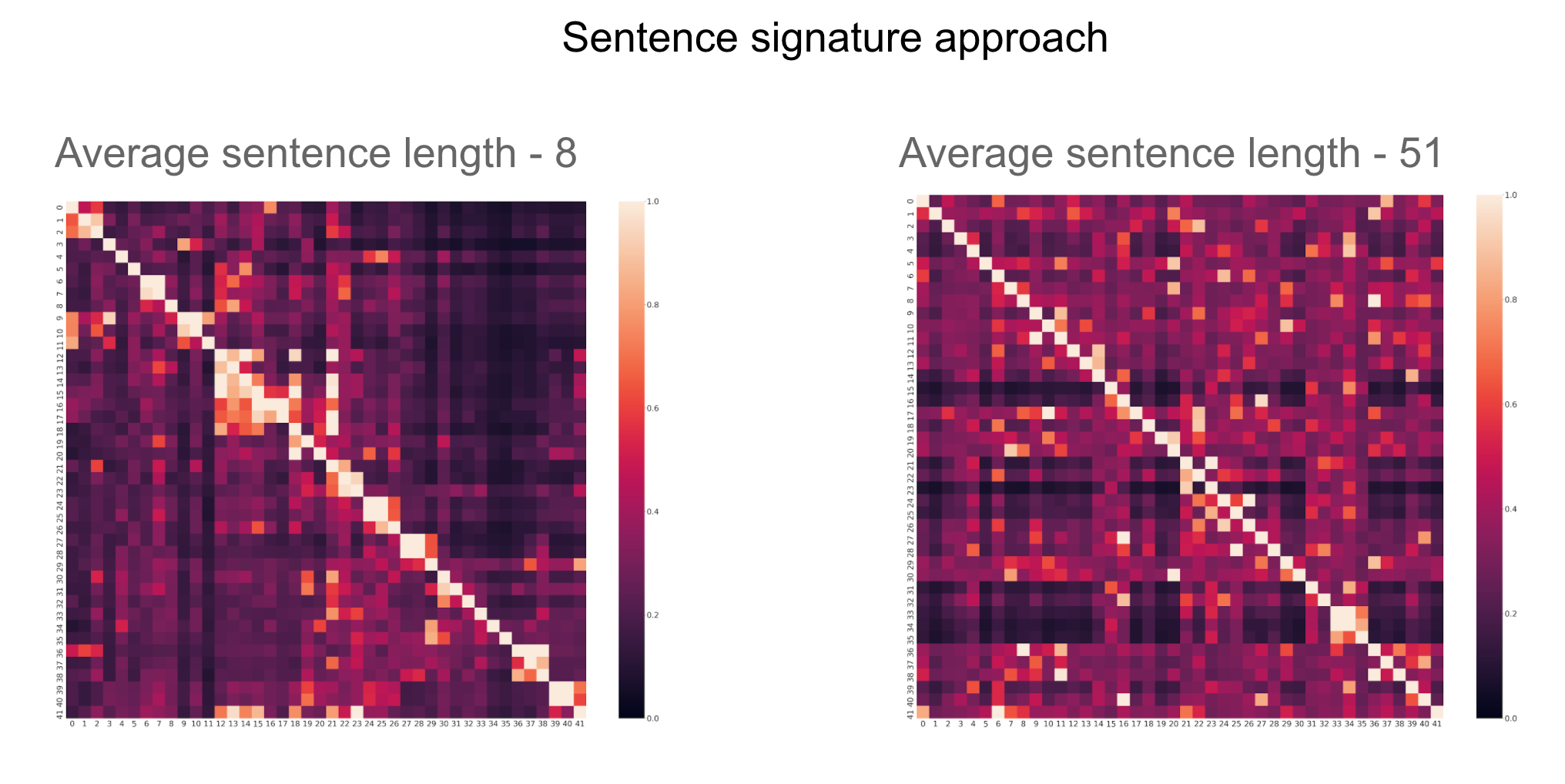
A few unique aspects of the sentence signature approach in contrast to the other three models
与其他三个模型相比,句子签名方法的一些独特方面
- the heat map is not symmetric, unlike the others. This is simply a consequence of the asymmetric score computation described earlier. 与其他地图不同,热图不是对称的。 这仅仅是先前描述的不对称分数计算的结果。
There are a lot of light spots away from the diagonal, particularly in the long sentence test — which is noticeably absent in all the other models. This is in part because these clusters have sentences that could belong to multiple clusters. There is also some degree of false close matches, in part because of the semantic spread of terms capturing context sense in Figure 3. A large k would increase spread (in addition to impacting performance given matrix size increase), while a small k may not sufficiently disambiguate — the choice of k is a tradeoff. However, unlike the other models, we can examine the causal reason for these light patches (done in the additional notes section) in terms of the dominant descriptors that contribute to the score. This is a distinct advantage this approach has over other models whose results are largely opaque.
在对角线上有很多光点,特别是在长句子测试中,在所有其他模型中均不存在。 部分原因是这些聚类具有可能属于多个聚类的句子。 假匹配也存在一定程度,部分是由于图3中捕获上下文意义的术语的语义扩展。大k会增加扩展(除了在矩阵大小增加的情况下影响性能),而小k可能不会充分消除歧义-k的选择是一个折衷。 但是,与其他模型不同,我们可以根据有助于得分的主导描述符来检查这些轻补丁的因果原因(在附加注释部分中完成) 。 这是该方法相对于其他模型(其结果在很大程度上不透明)具有的明显优势。
A quantitative comparison of models on a benchmark test set for sentence similarity task remains to be done.
对于句子相似性任务,需要在基准测试集上对模型进行定量比较。
局限性 (Limitations)
Some of the limitations are
一些限制是
this approach barely performs as well as the other models for short sentences. It outperforms (in the qualitative test) only when sentence length increases.
这种方法的效果几乎不及其他短句模型。 跑赢大市 (在定性测试中) 仅当句子长度增加时。
this approach does not lend itself as-is for tasks other than sentence similarity, although context sensitive signatures of individual tokens can be used for tagging tasks like unsupervised NER.
尽管单个标记的上下文相关签名可以用于标记诸如无监督NER之类的任务,但这种方法不会像句子相似性那样适合其他任务。
- this approach is prone to having false positives just like any other models, though they could be weeded out given the explanatory descriptors mentioned above. 与其他模型一样,这种方法很容易产生误报,尽管鉴于上述解释性描述符,它们可能会被淘汰。
最后的想法 (Final thoughts)
One of the untapped potential of transformer based models like BERT is the fixed set of learned vectors representing its vocabulary. Though these vectors are no different in spirit from word vectors learned by models like word2vec, these models have two distinct advantages
基于变压器的模型(例如BERT)的未开发潜力之一是代表其词汇的固定学习向量集合。 尽管这些向量在本质上与诸如word2vec之类的模型学习的词向量没有什么不同,但这些模型具有两个明显的优势
Fixed size instead of variable size vocabulary. the size of vocabulary is fixed and is left for us to choose (we just need to pre-train model with a vocabulary of our choice) enabling it to serve as a fixed reference base — something word2vec like models lack.
固定大小而不是可变大小的词汇表 。 词汇表的大小是固定的,留给我们选择(我们只需要使用选择的词汇表对模型进行预训练即可)就可以将其用作固定的参考基础,而word2vec之类的模型则缺乏这种基础。
Capturing sentence context. Mapping context-sensitive vectors back to vectors in BERT’s vocabulary using an MLM head model enables us to capture the context sensitive meanings of words based on the sentence context they appear in.
捕获句子上下文。 使用MLM头部模型将上下文相关的向量映射回BERT词汇表中的向量,使我们能够根据单词所处的句子上下文来捕获单词的上下文相关含义。
These two facts, enable even a bag of signature words that only indirectly captures sequence information using context sensitive words, to perform almost as well on short sentences, and even better on long sentences than other models.
这两个事实甚至使一袋签名单词仅使用上下文敏感单词间接捕获序列信息,在短句子上的表现几乎相同,甚至在长句子上也比其他模型更好。
Prototype reference implementation available on Github.
Github上提供了 原型参考实现 。
参考资料/相关工作 (References/Related work)
The three models used to qualitatively benchmark the current approach. All three have reference implementations on Github
这三个模型用于定性地对当前方法进行基准测试。 这三个都在Github上有参考实现
A baseline model for evaluating sentence embeddings(2016) using models like word2vec. This simple model outperformed sequence models (RNNS/LSTMs) in sentence similarity tasks.
使用word2vec等模型评估句子嵌入的基准模型 (2016)。 这个简单的模型在句子相似性任务中胜过序列模型(RNNS / LSTM) 。
补充笔记 (Additional notes)
The sentence pairs that led to light shaded cells away from the diagonal in the long sentence test ( ~51 words per sentence) is examined below. The figure below is a magnified version of Figure 10, right side heat map. The white colored cells are sentence pairs with a score of 1 (the score is a relative measure score unlike cosine distance measures where we would typically only have a score of 1 for two sentences that are verbatim the same sentence)
在下面的句子中,对导致长句测试中远离对角线的阴影单元格的句子对(每个句子约51个单词)进行了检查。 下图是图10右侧热图的放大图。 白色的单元格是分数为1的句子对(分数是相对度量分数,与余弦距离度量不同,在余弦距离度量中,我们通常只对两个句子中的逐个句子使用相同的分数)

The corresponding sentence pairs for the white squares away from the diagonal are shown below.
下面显示了远离对角线的白色正方形对应的句子对。

The highest contribution pairs from the sentence signatures three false sentence pairs are examined below. These offer insight into why these sentences matched and could serve as a means to filter sentence pairs.
下面检查来自句子签名的最高贡献对三个错误句子对。 这些提供了为什么这些句子匹配的见解,并且可以用作过滤句子对的手段。
The first sentence pair and its top matching descriptors in sentence signatures
句子签名中的第一对句子及其顶部匹配描述符

The second sentence pair and its top matching descriptors in sentence signatures. The reason for these sentences coming close is quite evident from the descriptor pairs— the concept of wings that is common to butterflies and the plane played a dominant role by several weak pairwise interactions adding up to a signal.
句子签名中的第二个句子对及其顶部匹配描述符。 这些句子接近的原因从描述符对中可以很明显地看出-蝴蝶和飞机共有的翅膀概念是由几个弱的成对相互作用加起来构成信号的主导作用。

In the last sentence pair, the pairs do not have as much explanatory value as in the previous one other than the fact, other than the fact that the pairs are not of much interest, to begin with.
在最后的句子对中,除了事实并非如此,对以外,这些对的解释价值不如前一个。

This article was manually imported from Quora https://qr.ae/pNKmJ7
本文是从Quora https://qr.ae/pNKmJ7 手动导入的
句子匹配 无监督















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









