





 本文探讨了强化学习在游戏行业中的应用,通过介绍如何利用这种人工智能技术来改进游戏角色的行为和玩家体验。
本文探讨了强化学习在游戏行业中的应用,通过介绍如何利用这种人工智能技术来改进游戏角色的行为和玩家体验。
强化学习在游戏中的作用
Microsoft made an amazing history in machine learning (ML) and artificial intelligence (AI). They proudly announced the preview of Reinforcement Learning (RL) on Azure Machine Learning at Build 2020. Microsoft applies ML to improve many of their products and services, such us for the suggestions made in Office services.
微软在机器学习(ML)和人工智能(AI)方面创造了惊人的历史。 他们自豪地宣布在Build 2020上发布Azure机器学习上的强化学习(RL)预览。Microsoft应用ML改进了他们的许多产品和服务,例如Office服务方面的建议。
那么,什么是强化学习? (So, what is reinforcement learning?)
Reinforcement learning is a machine learning paradigm which trains the policy of the agent, so that it can make a sequence of decisions. The aim of the agent is to output actions according to the observation it makes about its environment. These actions then lead to more observations and rewards. Training involves numerous trial-and-error runs as the agent interacts with the environment, and in each iteration, it is able to improve the policy.
强化学习是一种机器学习范式,它训练代理的策略,以便它可以做出一系列决策。 代理的目的是根据对环境的观察来输出动作。 这些行动将导致更多的观察和回报。 当代理与环境交互时,培训涉及大量的反复试验,并且每次迭代都可以改进策略。
This learning approach became very popular in the recent years, since these agents perform complex tasks really well thanks to RL, causing real breakthroughs in the field. There are many use cases in the world, which uses this technology, in the areas such as robotics, chemistry and a lot more; but the focus of this article is game development.
近年来,这种学习方法变得非常流行,这归功于RL,这些代理可以很好地执行复杂的任务,从而在该领域带来了真正的突破。 世界上有很多使用这种技术的用例,例如机器人技术,化学技术等等。 但是本文的重点是游戏开发 。
In the context of video games, the agent that takes actions or performs a behavior is the game agent. Think of a character or a bot in a game, it has to understand the state of the game, where are the players, then based on this observation, it should make a decision based on the situation of the game. In RL, decisions are driven by rewards, which in a game could be provided as a high score, or a new level for reaching a specific goal. The cool thing about a gaming situation is that the policy of the agent is trained under the pressure of the game. For example, it could learn what to do when it’s being attacked, or how to behave in order to reach a specific goal.
在视频游戏的上下文中,采取行动或执行行为的代理是游戏代理。 考虑游戏中的角色或机器人,它必须了解游戏的状态,玩家在哪里,然后基于此观察,应根据游戏的情况做出决定。 在RL中,决策由奖励决定,奖励在游戏中可以作为高分提供,也可以提供给达到特定目标的新水平。 关于游戏情况的最酷的事情是,在游戏的压力下训练了代理的策略。 例如,它可以了解受到攻击时的处理方式,或如何行为以达到特定目标。
Azure机器学习中的强化学习 (Reinforcement Learning in Azure Machine Learning)
Microsoft Research worked together with Ninja Theory to explore new possibilities of RL in gaming. Project Paidia has been announced on the 3rd of August at Game Stack Live, and the state-of-the-art AI agents used Bleeding Edge as a research environment.
微软研究院与忍者理论一起探索了RL在游戏中的新可能性。 Project Paidia已于8月3日在Game Stack Live上宣布,而最先进的AI代理商将Bleeding Edge用作研究环境。
The aim of the research is not to build an agent that is able to beat humans (just like the famous chess agent), but to provide game developers tools to make them able to apply RL while building exciting games for their players.
该研究的目的不是要构建能够击败人类的代理(就像著名的国际象棋代理一样 ),而是要为游戏开发人员提供工具,使他们能够在为玩家构建令人兴奋的游戏时应用RL。
If you are ready to get started with RL in gaming, check out the sample notebooks to train an agent, for example, to navigate a lava maze in Minecraft using Azure Machine Learning.
如果您准备好在游戏中开始使用RL,请签出示例笔记本来训练代理,例如,使用Azure机器学习在Minecraft中浏览熔岩迷宫。

The goal of this agent is to reach the blue tiles while navigating through this maze by walking only on solid tiles. The agent might fall into the lava in which case it has to start it over. Since the maps are generated randomly, the agent also has to learn how to generalize and adapt.
该代理的目标是仅在实心砖上行走,从而在迷宫中导航时到达蓝色砖块。 该代理可能掉入熔岩中,在这种情况下,它必须重新开始。 由于地图是随机生成的,因此代理还必须学习如何概括和适应。
Let’s look into an example of how an agent can be trained with Azure Machine Learning in a simple gaming environment. The new RL support in Azure Machine Learning services provides scalability while training to CPU or GPU enabled virtual machines with ML compute clusters that can automatically provision, manage and scale these virtual machines. You can use Single Agent or Multi Agent RL for your training scenarios. You can use different gaming environments, for example, Open AI Gym. You can build your models with TensorFlow, and Pytorch deep learning frameworks and supports ONNX too. You can also track your experiments and monitor the runs. Azure provides numerous AI solutions to build, run and grow your games. Accelerate your games with AI and ML to provide more realistic worlds and challenges.
让我们看一个示例,该示例说明如何在简单的游戏环境中使用Azure机器学习训练代理。 Azure机器学习服务中新的RL支持提供了可伸缩性,同时训练了带有ML计算群集的可启用CPU或GPU的虚拟机,这些虚拟机可以自动配置,管理和扩展这些虚拟机。 您可以将Single Agent或Multi Agent RL用于您的训练方案。 您可以使用不同的游戏环境,例如Open AI Gym 。 您可以使用TensorFlow和Pytorch深度学习框架来构建模型,并且也支持ONNX 。 您还可以跟踪实验并监控运行情况。 Azure提供了许多AI解决方案来构建,运行和扩展您的游戏。 使用AI和ML加速您的游戏,以提供更多逼真的世界和挑战。
在多代理场景中进行培训 (Training in a Multi Agent scenario)
For this tutorial, we use the following situation: The blue circles are the agents, and they start spreading around and observe their environment while finding the landmarks, that are shown as black circles.
在本教程中,我们使用以下情况:蓝色圆圈是主体,它们开始四处散布并观察其周围环境,同时找到显示为黑色圆圈的地标。

They get rewarded if they find the landmarks without overlapping while spreading around. For this, we use Open AI Gym’s Particle environment within Azure Machine Learning. You will need an Azure subscription, a resource group and a machine learning workspace with a computation cluster in the resource group to follow this tutorial. A compute target should be generated at the workspace, so when your resource is deployed, launch the workspace from the overview of the resource. Go to the Compute menu and click New. Give it a name (I call it RLCompute) and set it to use GPU, and either STANDARD_NC6 or STANDARD_D2_V2 and then click Create.
如果他们发现地标而在周围散布时没有重叠,则会获得奖励。 为此,我们在Azure机器学习中使用Open AI Gym的粒子环境。 您将需要一个Azure订阅,一个资源组和一个在资源组中具有计算群集的机器学习工作区 ,才能遵循本教程。 应该在工作空间中生成一个计算目标,因此在部署资源时,请从资源的概述启动工作空间。 转到“ 计算”菜单,然后单击“ 新建” 。 给它起一个名字(我称其为RLCompute)并将其设置为使用GPU,并为其命名STANDARD_NC6或STANDARD_D2_V2,然后单击Create 。
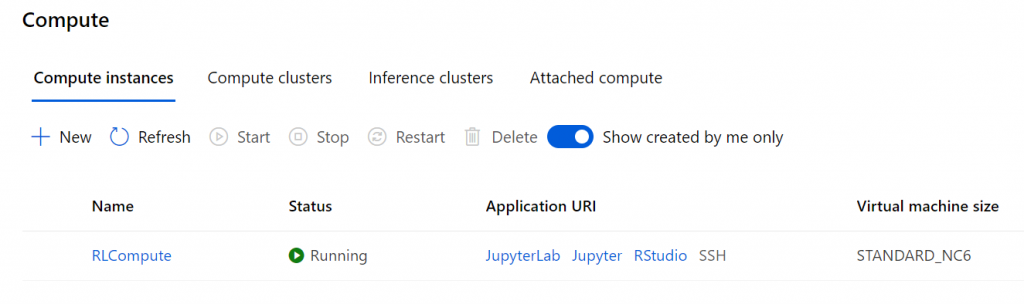
Now go to the Notebook menu, and create a files folder, and place there all the files that you can find in this GitHub folder. When you are ready, let’s move back to the main folder, open the notebook and let’s start coding! First you might want to update your environment.
现在转到Notebook菜单,创建一个文件文件夹,然后在GitHub文件夹中放置所有可以找到的文件 。 准备就绪后,让我们回到主文件夹,打开笔记本并开始编码! 首先,您可能要更新您的环境。
# We recommend updating pip to the latest version.
!pip install --upgrade pip
# Update matplotlib for plotting charts
!pip install --upgrade matplotlib
# Update Azure Machine Learning SDK to the latest version
!pip install --upgrade azureml-sdk
# For Jupyter notebook widget used in samples
!pip install --upgrade azureml-widgets
# For Tensorboard used in samples
!pip install --upgrade azureml-tensorboard
# Install Azure Machine Learning Reinforcement Learning SDK
!pip install --upgrade azureml-contrib-reinforcementlearningLet’s return the Azure Machine Learning SDK version, it is quite handy in case you need to do some debugging.
让我们返回Azure机器学习SDK版本,在需要进行一些调试的情况下非常方便。
import azureml.core
print('Azure Machine Learning SDK Version: ', azureml.core.VERSION)It is a good idea to define which Azure tenant you want to use, so specify it with the use of the following code.
最好定义要使用的Azure租户,因此请使用以下代码进行指定。
from azureml.core.authentication import InteractiveLoginAuthentication
InteractiveLoginAuthentication(force=False, tenant_id='<tenant_id>', cloud=None)You can figure out your tenant id at the Azure Portal. Go to Azure Active Directory, and there you can find it at the Tenant information box. Now it is time to connect to the workspace that is just created. You can use a configuration, or you can specify it by defining the name of the workspace, the subscription id and the name of the resource group where you put the workspace and the compute target. You can find the subscription id at the Azure Portal, if you go to Subscriptions.
您可以在Azure门户中找到您的租户ID。 转到Azure Active Directory ,然后在“ 租户信息”框中找到它。 现在是时候连接到刚刚创建的工作空间了。 您可以使用配置,也可以通过定义工作空间的名称,订阅ID和放置工作空间以及计算目标的资源组的名称来指定配置。 如果转到“ 订阅” ,则可以在Azure门户上找到订阅ID。
from azureml.core import Workspace# ws = Workspace.from_config()ws = Workspace.get(name="<workspace name>",
subscription_id='<subscription_id>',
resource_group='<name of resource group>')print(ws.name, ws.location, ws.resource_group, sep=' | ')If the connection was successful, it will return the details of the workspace. The next step is to create a new experiment which will enable us to monitor the run.
如果连接成功,它将返回工作空间的详细信息。 下一步是创建一个新实验,使我们能够监视运行情况。
from azureml.core import Experiment
exp = Experiment(workspace=ws, name='particle-multiagent')Now we also create a cluster where the training is going to run. You can always change this code to use an existing cluster. In this code we also need a compute target for the Ray head, which is now a Standard D3 (CPU), which is why it is good enough to use 1 as maximum node.
现在,我们还创建了一个要运行培训的集群 。 您始终可以更改此代码以使用现有集群。 在此代码中,我们还需要雷头的计算目标,现在是标准D3(CPU),这就是为什么使用1作为最大节点就足够了。
from azureml.core.compute import AmlCompute, ComputeTargetcpu_cluster_name = 'cpu-cl-d3'if cpu_cluster_name in ws.compute_targets:
cpu_cluster = ws.compute_targets[cpu_cluster_name]
if cpu_cluster and type(cpu_cluster) is AmlCompute:
if cpu_cluster.provisioning_state == 'Succeeded':
print('Found existing compute target for {}. Using it.'.format(cpu_cluster_name))
else:
raise Exception('Found existing compute target for {} '.format(cpu_cluster_name)
+ 'but it is in state {}'.format(cpu_cluster.provisioning_state))
else:
print('Creating a new compute target for {}...'.format(cpu_cluster_name))
provisioning_config = AmlCompute.provisioning_configuration(
vm_size='STANDARD_D3',
min_nodes=0,
max_nodes=1) cpu_cluster = ComputeTarget.create(ws, cpu_cluster_name, provisioning_config)
cpu_cluster.wait_for_completion(show_output=True, min_node_count=None, timeout_in_minutes=20)
print('Cluster created.')The good thing about this cluster is that it will scale down when it is not used. You are welcome to increase the nodes if you plan to run more than one experiments on this cluster. When the cluster is ready to use, this code will return the Cluster created message. We are going to use a customized Docker image where all the necessary software and Python packages are installed. The configuration for the training run is defined with the Environment class. Since we also want videos as results about the different runs of the particles, we need to set the interpreter_path too.
关于此群集的好处是,当不使用群集时,它将按比例缩小。 如果计划在此群集上运行多个实验,欢迎增加节点。 准备使用群集时,此代码将返回“ 群集创建”消息。 我们将使用定制的Docker映像,其中安装了所有必需的软件和Python软件包。 训练运行的配置是通过Environment类定义的。 由于我们还希望将视频作为有关粒子不同运行的结果,因此我们也需要设置interpreter_path。
import os
from azureml.core import Environment
cpu_particle_env = Environment(name='particle-cpu')cpu_particle_env.docker.enabled = True
cpu_particle_env.docker.base_image = 'akdmsft/particle-cpu'
cpu_particle_env.python.interpreter_path = 'xvfb-run -s "-screen 0 640x480x16 -ac +extension GLX +render" python'max_train_time = os.environ.get('AML_MAX_TRAIN_TIME_SECONDS', 2 * 60 * 60)
cpu_particle_env.environment_variables['AML_MAX_TRAIN_TIME_SECONDS'] = str(max_train_time)
cpu_particle_env.python.user_managed_dependencies = TrueFor training, we are going to use the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) algorithm, and as the name suggests, it will be able to train many agents in the same time. If the training runs over 3 hours, it will automatically stop, similarly if a -400 reward is given. We have to initialize ReinforcementLearningEstimator with different parameters that are necessary for the training.
对于培训,我们将使用多代理深度确定性策略梯度(MADDPG)算法,顾名思义,它将能够同时训练许多代理。 如果训练进行了3个小时,它将自动停止,如果给予-400奖励,则类似。 我们必须使用培训所需的不同参数来初始化ReinforcementLearningEstimator 。
from azureml.contrib.train.rl import ReinforcementLearningEstimator
from azureml.widgets import RunDetailsestimator = ReinforcementLearningEstimator(
source_directory='files',
entry_script='particle_train.py',
script_params={
'--scenario': 'simple_spread',
'--final-reward': -400
},
compute_target=cpu_cluster,
environment=cpu_particle_env,
max_run_duration_seconds=3 * 60 * 60
)train_run = exp.submit(config=estimator)RunDetails(train_run).show()You are welcome to change the final reward parameter, when it is reached by the agent, the training is over. The -400 returns with a pretty good result, but if you want it to be better, training might take longer. Finally, we also want to see some more information about the experiment while it’s running, and a button is available to navigate you to the run details.
欢迎您更改最终奖励参数,当代理商达到此目标时,培训结束。 -400返回的效果很好,但是如果您希望它更好,则培训可能需要更长的时间。 最后,我们还希望在实验运行时看到有关该实验的更多信息,并且有一个按钮可以将您导航到运行细节。
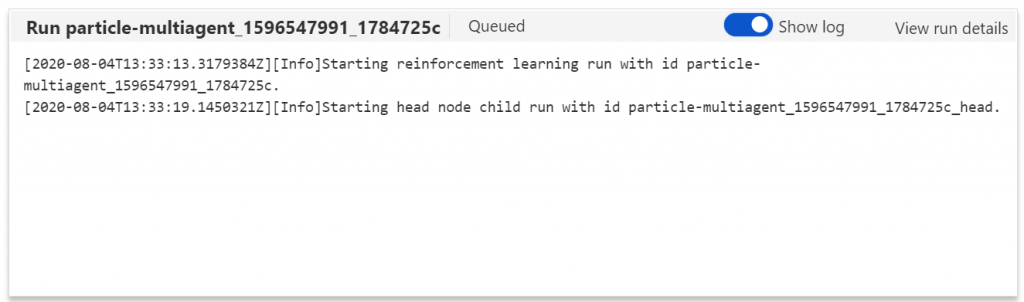
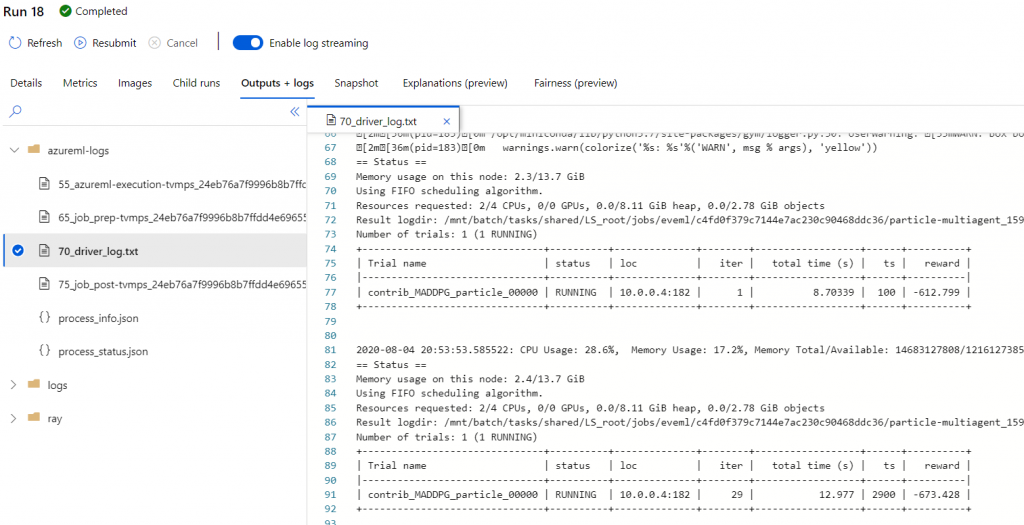
Go to the Child runs of the experiment, and choose the one that is running. If you navigate to the Outputs + Logs tab, you can find detailed logs about each trial in the driver log text file (azureml-logs folder).
转到实验的“ 子运行 ”,然后选择正在运行的那个。 如果导航至“ 输出+日志”选项卡,则可以在驱动程序日志文本文件(azureml-logs文件夹)中找到有关每个试用版的详细日志。
The generated videos are saved in the logs folder of the Outputs + Logs tab. You can download the videos from here, and take a look how the agents behave.
生成的视频保存在“输出+日志”选项卡的日志文件夹中。 您可以从此处下载视频,并查看代理的行为。
让我们监视训练过程 (Let’s monitor the training run)
Evaluation of a training is really important, and it is possible to reach videos about the different iterations. The code is going to download the generated videos and display it within the notebook.
评估培训非常重要,并且可以观看有关不同迭代的视频。 该代码将下载生成的视频并将其显示在笔记本中。
from azureml.core import Dataset
from azureml.data.dataset_error_handling import DatasetValidationErrorfrom IPython.display import clear_output
from IPython.core.display import display, Videodatastore = ws.get_default_datastore()
path_prefix = './tmp_videos'def download_latest_training_video(run, video_checkpoint_counter):
run_artifacts_path = os.path.join('azureml', run.id)
try:
run_artifacts_ds = Dataset.File.from_files(datastore.path(os.path.join(run_artifacts_path, '**')))
except DatasetValidationError as e:
# This happens at the start of the run when there is no data available
# in the run's artifacts
return None, video_checkpoint_counter
video_files = [file for file in run_artifacts_ds.to_path() if file.endswith('.mp4')]
if len(video_files) == video_checkpoint_counter:
return None, video_checkpoint_counter
iteration_numbers = [int(vf[vf.rindex('video') + len('video') : vf.index('.mp4')]) for vf in video_files]
latest_video = next(vf for vf in video_files if vf.endswith('{num}.mp4'.format(num=max(iteration_numbers))))
latest_video = os.path.join(run_artifacts_path, os.path.normpath(latest_video[1:]))
datastore.download(
target_path=path_prefix,
prefix=latest_video.replace('\\', '/'),
show_progress=False)
return os.path.join(path_prefix, latest_video), len(video_files)
def render_video(vf):
clear_output(wait=True)
display(Video(data=vf, embed=True, html_attributes='loop autoplay width=50%'))import shutilterminal_statuses = ['Canceled', 'Completed', 'Failed']
video_checkpoint_counter = 0while head_run.get_status() not in terminal_statuses:
video_file, video_checkpoint_counter = download_latest_training_video(head_run, video_checkpoint_counter)
if video_file is not None:
render_video(video_file)
print('Displaying video number {}'.format(video_checkpoint_counter))
shutil.rmtree(path_prefix)
# Interrupting the kernel can take up to 15 seconds
# depending on when time.sleep started
time.sleep(15)
train_run.wait_for_completion()
print('The training run has reached a terminal status.')You should run this code right after you started the training in order to get the videos inline. Since these videos are generated about each run, it is really interesting to watch, how it improves! The shown video looks similarly like on this picture:
您应该在开始培训后立即运行此代码,以内嵌视频。 由于这些视频是针对每次运行生成的,因此观看和改进非常有趣! 所显示的视频在此图片上看起来类似:

We can also monitor the trials in runtime via Tensorboard. This code should output a URL where you can find the dashboards.
我们还可以通过Tensorboard监控运行时的试用情况。 此代码应输出一个URL,您可以在其中找到仪表板。
import time
from azureml.tensorboard import Tensorboardhead_run = Nonetimeout = 60
while timeout > 0 and head_run is None:
timeout -= 1
try:
head_run = next(r for r in train_run.get_children() if r.id.endswith('head'))
except StopIteration:
time.sleep(1)tb = Tensorboard([head_run])
tb.start()Click on the link, and after a few minutes you should be able to see the dashboard similarly like on this picture.
单击链接,几分钟后,您应该能够像在此图片上一样看到仪表板。

贡献 (Contribution)
The open source reinforcement learning tools welcome your contributions! Let us know if you have any issues, or feedback!
开源强化学习工具欢迎您的贡献! 让我们知道您是否有任何问题或反馈!
Github repo with RL sampleshttps://aka.ms/azureml-rl-notebooks
带有RL样本的Github回购https://aka.ms/azureml-rl-notebooks
资源和后续步骤 (Resources and next steps)
Blog article from //buildhttps://aka.ms/azureml-rl
// build https://aka.ms/ azureml-rl的博客文章
YouTube — AI Show with Keijihttps://aka.ms/azureml-rl-aishow
YouTube — Keiji的AI表演https://aka.ms/azureml-rl-aishow
Blog article about Paidiahttps://aka.ms/GSLAIblog
有关Paidia的博客文章https://aka.ms/GSLAIblog
Concept Documentationhttps://aka.ms/amlrl-doc
Katja //build video talking about RLhttps://channel9.msdn.com/Events/Build/2020/BDL205
Katja //构建有关RL的视频https://channel9.msdn.com/Events/Build/2020/BDL205
翻译自: https://medium.com/@evepardi/reinforcement-learning-in-gaming-583a42bc2a9b
强化学习在游戏中的作用















 1767
1767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









