





 本文介绍了ACL 2020会议上关于自然语言处理中知识图谱的重要研究,探讨了如何利用知识图谱提升机器理解和处理自然语言的能力。
本文介绍了ACL 2020会议上关于自然语言处理中知识图谱的重要研究,探讨了如何利用知识图谱提升机器理解和处理自然语言的能力。
acl自然语言处理
重点 (Top highlight)
This post commemorates the first anniversary of the series where we examine advancements in NLP and Graph ML powered by knowledge graphs! 🎂 1️⃣The feedback of the audience drives me to continue, so fasten your seatbelts (and maybe brew some ☕️): in this episode, we are looking at the KG-related ACL 2020 proceedings!
这篇文章纪念了该系列系列的一周年,在此系列中,我们将探讨由知识图支持的NLP和Graph ML的进步! ⃣1️⃣观众的反馈使我继续前进,因此请系紧安全带(甚至冲泡一些☕️):在这一集中,我们正在研究与KG相关的ACL 2020程序!
ACL 2020 went fully virtual this year and I can’t imagine how hard was it for the chairs to organize such an enormous event online catering for multiple time zones and 700+ accepted papers. Thanks to all involved as well as speakers and participants, the conference went smoothly given its size 👏
今年的ACL 2020完全虚拟化了,我无法想象主持人组织如此巨大的活动在线服务于多个时区和700多篇被接受的论文有多么困难。 感谢所有与会人员以及发言人和与会人员,鉴于会议的规模👏会议顺利进行
So did something change in the KG & NLP field comparing to ACL 2019? Yes! I would summarize this year’s contribution as:
那么与ACL 2019相比,KG&NLP领域是否有所变化? 是! 我将今年的贡献总结为:
Knowledge graphs demonstrate better capabilities to reveal higher-order interdependencies in otherwise unstructured data
知识图展示了更好的功能,可以揭示非结构化数据中的高阶相互依赖关系
Today in our agenda:
今天在我们的议程中:
对结构化数据的问答 (Question Answering over Structured Data)
In this context, questions are sent against structured sources like SPARQL-based KGs or SQL databases (other query languages are not that prominent).This year, we can observe increasing efforts incorporating complex (also known as multi-hop) questions.
在这种情况下,问题是针对基于SPARQL的KG或SQL数据库(其他查询语言并不那么突出)之类的结构化源发送的。今年,我们可以看到越来越多的工作将复杂(也称为多跳)问题纳入其中。
For example, Saxena et al tackle the problem of complex KGQA coupling KG embeddings with a question embedding vector in their EmbedKGQA. 1️⃣ First, an underlying KG is embedded with some algorithm (the authors choose ComplEx), so that each entity and relation is associated with a specific vector. In some cases, the authors freeze them, or keep fine-tuning depending on the KG size. 2️⃣ The input question is encoded via RoBERTA ([CLS] token from the last layer) and passed through 4 FC layers (well, if you ask why exactly 4, I don’t have an answer, looks like a magic number 🧙♂️) that are supposed to project the question into the complex space. 3️⃣ The crucial part happens in scoring where the authors adopt the KG embeddings framework and build a triple (head entity, question, candidate entity). The scoring function is the same as in ComplEx. Here, the head is the main entity in the question, the question itself is considered a relation (might seem a bit stretched though), and candidate entities are either all entities in the KG (if small) or 2-hop subgraph around the head (when pruning is required). Yes, it does resemble a typical 1-N scoring mechanism used for training KGE algorithms. ✂️ A candidate space can be further pruned by computing and thresholding a dot product (h_q, h_r) between the question embedding h_q and each relation embedding h_r .
例如, Saxena等人解决了将KG嵌入与EmbedKGQA中的问题嵌入向量耦合的复杂KGQA问题。 1️⃣首先,底层的KG嵌入了一些算法(作者选择ComplEx ),因此每个实体和关系都与特定的向量相关联。 在某些情况下,作者会冻结它们,或者根据KG的大小进行微调。 2️⃣输入的问题通过RoBERTA(来自最后一层的[CLS]令牌)进行编码,并经过4个FC层(嗯,如果您问为什么恰好4,我没有答案,看起来像一个魔术数字),以便将问题投射到复杂的空间中。 3️⃣关键部分发生在评分中,作者采用KG嵌入框架并构建了一个三元组 (头部实体,问题,候选实体) 。 评分功能与ComplEx中的相同。 在这里,头是问题中的主要实体,问题本身被认为是一种关系(虽然看起来可能有点延伸),而候选实体要么是KG中的所有实体(如果很小),要么是头周围的两跳子图(需要修剪时)。 是的,它确实类似于用于训练KGE算法的典型1-N评分机制。 computing️可以通过计算和嵌入问题嵌入h_q与每个关系嵌入h_r之间的点积(h_q, h_r)来进一步修剪候选空间。
🧪 In the experiments performed over MetaQA and WebQuestionsSP, the authors probe an additional scenario of an incomplete KG randomly removing 50% of the edges, so that the system has to learn to infer such missing links. In the full scenario, EmbedKGQA performs on par with PullNet (slightly better on 3-hop questions) and 10–40% better in absolute Hits@1 scores compared to baselines when not using additional text to augment the KG. 👏 Still, it is interesting to check how EmbedKGQA would process questions that require aggregations or have several grounded entities 🤔.
over在MetaQA和WebQuestionsSP上进行的实验中,作者探究了另外一种情况,即不完整的KG随机删除了50%的边缘,因此系统必须学会推断出此类缺失的链接。 在整个情况下, EmbedKGQA的性能与PullNet相当(在3跳问题上略胜一筹),并且在不使用其他文本来增加KG的情况下,其绝对Hits @ 1分数要比基线高10-40%。 👏不过,检查EmbedKGQA如何处理需要汇总或具有多个扎根实体的问题还是很有趣的。

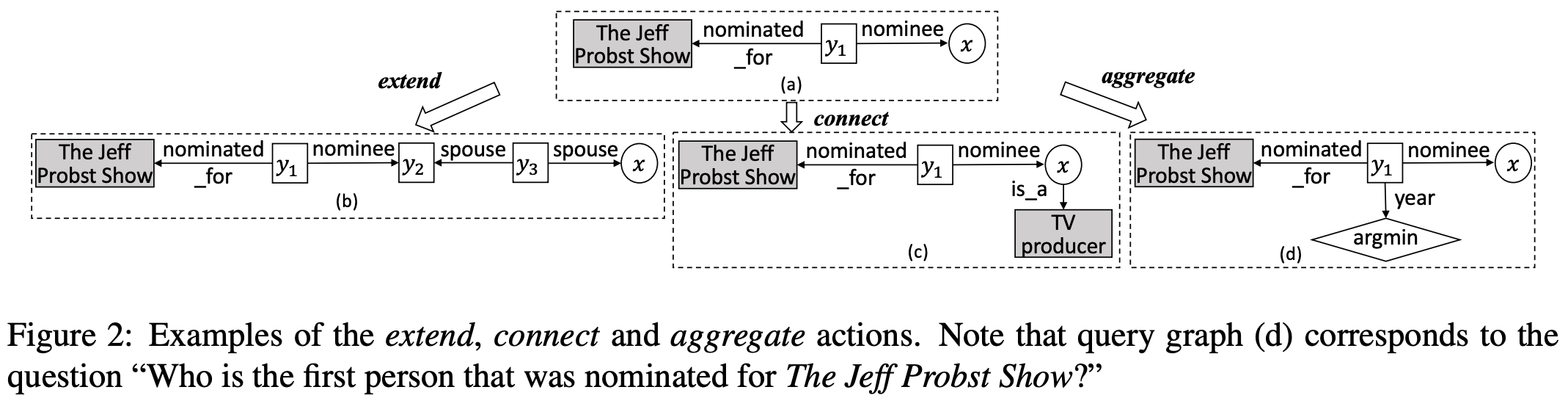
Somewhat on the other side of the spectrum, Lan et al propose to use iterative an RL-based query generation approach (KG embeddings-free 😉 ). Based on the topic entity (obtained via some entity linker, the authors resort to Google KG API for linking to Freebase), there is a set of 3 operations, namely, extend, connect, and aggregate that are applied to the seed entity building a query pattern. Naturally, the operations allow for complex multi-hop patterns with min/max aggregations. 🔦 At each step, the authors use beam search to keep K best patterns and rank them by deriving a 7d feature vector followed by a feed-forward net with a softmax. 🤨 You’d ask: “Wait, but where is BERT? Everybody’s using BERT now!”. Well, no panic, here you go: the surface forms of entities and relations participating in a query graph are linearized, concatenated with the input question and fed into BERT to get a [CLS] representation of the last layer (which is one of 7d features).
在频谱的另一端, Lan等 建议使用迭代的基于RL的查询生成方法(无KG嵌入😉)。 基于主题实体(通过某些实体链接器获得,作者使用Google KG API链接到Freebase),存在3个操作集,即extend , connect和aggregate ,它们应用于种子实体,以构建一个查询模式。 自然地,这些操作允许具有最小/最大聚合的复杂多跳模式。 🔦在每个步骤中,作者都使用波束搜索来保持K个最佳模式,并通过推导7d特征向量和带有softmax的前馈网络来对它们进行排序。 🤨您会问:“等等,但是BERT在哪里? 现在每个人都在使用BERT!”。 好吧,您不必担心,这里走了:将参与查询图的实体和关系的表面形式线性化,与输入问题连接起来,并输入到BERT中,以获取最后一层的[CLS]表示(这是7d之一)特征)。
🌡 The authors evaluate the approach on ComplexWebQuestions, WebQuestionsSP, and ComplexQuestions (looks a bit tailored to Freebase, isn’t it?), and find a noticeable improvement over the baselines. Further ablations show the importance of the 3 chosen operators. And here is the cliffhanger: it is a short paper! 👀 I would recommend this paper as a good example of a short paper that conveys the main idea, shows experiments, and demonstrates the validity of the approach with ablations 👍
🌡作者评估了ComplexWebQuestions,WebQuestionsSP和ComplexQuestions(看起来有点适合Freebase,不是吗?)上的方法,并且发现在基线上有明显的改进。 进一步消融显示了选择的3个运算符的重要性。 这是悬念:这是一篇简短的论文! 👀我建议将本文作为简短论文的一个很好的例子,该论文传达了主要思想,展示了实验并通过消融证明了该方法的有效性👍
📑 Structured QA also includes semantic parsing over SQL tables, and many new complex datasets drive the research in SQLandia.
📑结构化QA还包括对SQL表的语义解析,许多新的复杂数据集推动了SQLandia的研究。

Among others, I’d outline Wang et al and their RAT-SQL (relation-aware transformer, no 🐀) where they define explicit edges between columns and tables to encode the database schema. The authors also define an initial schema and value linking to obtain candidate columns and tables. Further, columns, tables, and question tokens are jointly passed through modified self-attention layers. ➡️ Finally, the tree-structured decoder builds an SQL query. RAT-SQL shows drastic improvements in Spider with bigger gains when using BERT for initial embeddings of tokens 📈
在其他文章中,我概述了Wang等人及其RAT-SQL(关系感知转换器,无🐀),其中他们在列和表之间定义了显式边缘以对数据库模式进行编码。 作者还定义了初始模式和值链接以获得候选列和表。 此外,列,表和问题标记共同通过修改后的自我注意层传递。 ➡️最后,树形结构的解码器构建了一个SQL查询。 使用BERT初始嵌入令牌时,RAT-SQL显示了Spider的巨大改进,并获得了更大的收益📈

Often, interacting with a semantic parsing system you’d want to fix small problems on the fly, or point 🔴 the parser at its mistake. Elgohary et al tackle this exact problem and propose SPLASH, a dataset for correcting SQL parses with natural language feedback. The correction scenario is different from conversational text2SQL tasks, so even recent SOTA models like EditSQL exhibit a large gap in the correction task compared to human annotators, i.e., 25% against 81%. That’s quite a gap 👀. Along the same dimension, Zeng et al develop Photon which is fully-fledged text-to-SQL system capable of performing some query correction as well 😉
通常,与语义解析系统进行交互时,您会想立即解决一些小问题,或者将解析器误认为是错误的。 Elgohary等人解决了这个确切的问题,并提出了SPLASH ,这是一个使用自然语言反馈来纠正SQL解析的数据集。 纠正方案与对话性text2SQL任务不同,因此与人工注释者相比,即使是最近的SOTA模型(如EditSQL)在纠正任务中也显示出很大的差距,即25%对81%。 那是一个很大的差距 。 沿着相同的维度, Zeng等人开发了Photon , Photon是成熟的文本到SQL系统,能够执行一些查询校正。
KG嵌入:双曲和超关系 (KG Embeddings: Hyperbolic and Hyper-relational)
Hyperbolic spaces are among recent hot topics in ML. Refraining from 🤯, in simpler terms, in a hyperbolic space 🔮 (thanks to its properties) you can represent hierarchies and tree-like structures more efficiently and at the same time use fewer dimensions!
双曲空间是ML中最近的热门话题。 简单地说,在双曲空间🔮中(由于其属性)避免使用🤯,您可以更有效地表示层次结构和树状结构,同时使用更少的尺寸!

With that motivation, Chami et al propose AttH, a hyperbolic KG embedding algorithm that uses rotations, reflections, and translations to model logical and hierarchical patterns in the KG. Att comes from the hyperbolic attention that is applied to rotated and reflected vectors. 🎩The trick to bypass shaky Riemannian optimization is to use tangent spaces, to which every point of the d-dimensional Poincare ball can be mapped. In this obviously non-trivial setup, each relation is associated not only to one vector, but also to the parameters that describe relation-specific reflections and rotations. Still, in real-world KGs R << V , so the overhead is not that big.
出于这种动机, Chami等人提出了AttH ,这是一种双曲KG嵌入算法,该算法使用旋转,反射和平移对KG中的逻辑和分层模式进行建模。 Att来自应用于旋转和反射矢量的双曲线注意。 bypass绕过不稳定的黎曼优化的技巧是使用切线空间,可以将d维Poincare球的每个点映射到该切线空间。 在这种显然不平凡的设置中,每个关系不仅与一个矢量关联,而且还与描述关系特定的反射和旋转的参数关联。 尽管如此,在现实世界中,KGs R << V ,所以开销并不是那么大。
⚖️ In the experiments, AttH performs especially well on WN18RR and Yago 3–10 that exhibit some hierarchical structure, with lesser margins on FB15k-237. More importantly, just 32-dimensional AttH shows huge margins compared to 32-d models in real and complex planes. Moreover, 32-d scores are just 0.02–0.03 MRR points smaller than SOTA 500-d embedding models on WN18RR and FB15k-237. Ablation studies demonstrate the importance of having learnable curvatures whereas its closest match, MurP, has them fixed.
In️在实验中, AttH在表现出某些层次结构的WN18RR和Yago 3-10上表现尤其出色,而在FB15k-237上的余量较小。 更重要的是,与真实和复杂平面中的32维模型相比,只有32维 AttH才显示出巨大的余量。 此外,32-d分数仅比WN18RR和FB15k-237上的SOTA 500-d嵌入模型小0.02-0.03 MRR点。 消融研究表明,具有可学习的曲率非常重要,而最接近的匹配值MurP可以解决这些问题。

Another growing trend in graph representation learning is to go beyond simple KGs consisting of triples and learn representations for more complex, hyper-relational KGs (as coined in the work by Rosso et al), when every triple might have a set of key-value attribute pairs that give fine-grained details on the validity of the triple in various contexts. In fact, Wikidata adopts the hyper-relational model in its Wikidata Statement Model where attributes are called qualifiers. It’s important not to mix the model with n-ary facts (that generate redundant predicates) and hypergraphs. That is, if you work with Wikidata only on the triple level, you lose a good half of the content 😃
图表示学习的另一个增长趋势是超越由三元组组成的简单KG,并学习更复杂, 超关系型 KG(如Rosso等人的工作所创造)的表示,当每个三元组都可能具有一组关键值时属性对,可在各种情况下提供有关三元组有效性的详细信息。 实际上,Wikidata在其Wikidata语句模型中采用了超关系模型,其中属性称为限定符 。 重要的是不要将模型与n元事实(生成冗余谓词)和超图混合使用。 也就是说,如果仅在三层级别上使用Wikidata,则会损失一半的内容😃
Guan et al do not want to lose a good half of Wikidata and propose NeuInfer, an approach for learning embeddings of hyper-relational KGs (their previous work, NaLP, was more suited to n-ary facts).
Guan等人不想丢掉Wikidata的大部分内容 , 而是建议使用NeuInfer (一种用于学习超关系型KG的嵌入方法)(他们以前的工作NaLP更适合n元事实)。

The idea of NeuInfer is to compute a validity and compatibility score of a hyper-relational fact (cf the illustration). First, (h,r,t) embeddings are fed into a fully-connected net (FCN) to estimate the likelihood of this triple (validity). Second, for each key-value pair a quintuple (h,r,t,k,v) is constructed and passed through another set of FCNs. Having m pairs, m vectors are min-pooled and the result represents the compatibility score, i.e., how well those qualifiers live with the main triple. Finally, the authors use a weighted sum of two scores to get the final score.
NeuInfer的想法是计算超关系事实的有效性和兼容性得分(参见插图)。 首先,将(h,r,t)嵌入内容馈送到完全连接的网络(FCN)中,以估计此三元组的可能性(有效性)。 其次,对于每个键值对(h,r,t,k,v)构造一个五元组(h,r,t,k,v)并通过另一组FCN。 有m个对, m个向量被最小化,结果表示相容性分数,即那些限定词与主三元组的相处程度。 最后,作者使用两个分数的加权总和得出最终分数。
The authors evaluate NeuInfer on standard benchmarks JF17K (extracted from Freebase) and WikiPeople (from Wikidata) and report significant improvement in JF17K compared to NaLP when predicting heads, tails, and attribute values. 📈 I would encourage the authors to compare their numbers with HINGE (from Rosso et al) as both approaches are conceptually similar.
作者在标准基准测试评估NeuInfer JF17K(从游离碱提取)和WikiPeople(来自维基数据)和报告预测的头,尾,和属性值时JF17K显著的改善相比NALP。 📈我鼓励作者将他们的数字与HINGE(来自Rosso等人 )进行比较,因为这两种方法在概念上都是相似的。
💡 And now we need to talk. We need to talk about reproducibility of KG embedding algorithms published even at top conferences like ACL 2019. Sun, Vashishth, Sanyal et al find that several recent KGE models that reported SOTA results (drastically better than existing baselines) suffer from test set leakages, or have unusually many zeroified neurons after ReLU activations scoring valid triples ☢️. Further, they show that their performance metric scores (like Hits@K and MRR) depend on the position of the valid triple among sampled negatives (which should not happen, actually). On the other hand, existing strong baselines perform exactly the same despite any position. The take-away message is to use the evaluation protocol that places a valid triple at a random position among negatives.
now现在我们需要谈谈。 我们需要讨论甚至在ACL 2019之类的顶级会议上发布的KG嵌入算法的可再现性。Sun,Vashishth,Sanyal等人发现,报告了SOTA结果(明显优于现有基准)的几个最近的KGE模型都遭受测试集泄漏或在ReLU激活后获得有效三元组☢️的情况下,异常神经元的数量很多。 此外,他们还表明,他们的绩效指标得分(如Hits @ K和MRR)取决于有效三元组在抽样阴性中的位置(实际上不应该发生这种情况)。 另一方面,尽管有任何位置,现有的强基准仍然表现完全相同。 要点是要使用评估协议,该协议将有效的三元组放置在底片中的任意位置。

[start of a shameless self-promotion 😊] Well, our team also has something to say about this issue: in our new paper “Bringing Light Into the Dark: A Large-scale Evaluation of Knowledge Graph Embedding Models Under a Unified Framework” we performed 65K+ experiments and spent 21K+ GPU hours evaluating 19 models spanning from RESCAL first published in 2011 to the late 2019’s RotatE and TuckER, 5 loss functions, various training strategies with/without negative sampling, and many more hyper-parameters that turn out to be important to consider. We are also releasing the best found hyperparameters for all the models for you folks and our beloved community 🤗. In addition, we are releasing PyKEEN 1.0, a PyTorch library for training and benchmarking KG embeddings models! [end of the self-promotion]
[无耻自我提升的开始start]好吧,我们的团队对此问题也有话要说:在我们的新论文“将光明带入黑暗:统一框架下的知识图嵌入模型的大规模评估” 我们进行了65K +次实验,并花费了21K + GPU小时,评估了从2011年首次发布的RESCAL到2019年末的RotatE和TuckER的19种模型,5种损失函数,带有/不带有负采样的各种训练策略以及更多的超参数重要的考虑。 我们还将为您和我们心爱的社区releasing为所有模型发布最佳发现的超参数。 此外,我们还将发布PyKEEN 1.0 ,这是一个用于训练和基准化KG嵌入模型的PyTorch库! [自我推广结束]
🔥 Several other works I’d encourage you to read thoroughly: Sachan studies the problem of compression of KG entity embeddings by discretization, e.g., “Barack Obama” instead of a 200d float32 vector would be encoded as “2–1–3–3” and “Michelle Obama” as “2–1–3–2”.
I我鼓励您仔细阅读其他几本著作: Sachan研究了通过离散化压缩 KG实体嵌入的问题,例如,“ Barack Obama”而不是200d float32向量将被编码为“ 2-1–3–3” ”和“米歇尔·奥巴马(Michelle Obama)”表示为“ 2-1–3–2”。

That is, you only need a D-long vector of K values (here, D=4, K=3). For discretization, tempered softmax is found to work better. And as a reverse function from the KD code back to N-dimensional vector of floats the author suggests using a simple Bi-LSTM. Experimental results are astonishing 👀 — compression rates for FB15k-237 and WN18RR reach 100–1000x with a negligible (max 2% MRR) performance drop and computation overhead at inference time (when a KD code has to be decoded back). 🤔 I suggest we all sit down for a minute and re-think our KGE pipelines (especially in production scenarios). For example, 200d embeddings of 78M Wikidata entities obtained via PyTorch-BigGraph require 👉 110 GB 👈 of space. Just imagine what would be possible with a gentle 100x compression 😏.
也就是说,您只需要一个K值的D长向量(此处D = 4,K = 3)。 对于离散化,发现回火的softmax效果更好。 作为从KD代码返回到float的N维向量的逆函数,作者建议使用简单的Bi-LSTM。 实验结果令人惊讶-FB15k-237和WN18RR的压缩率达到100-1000x ,性能下降可忽略不计(最大2%MRR),并且推理时的计算开销(当必须解码回KD码时)。 🤔我建议大家休息一会儿,然后重新考虑我们的KGE管道(尤其是在生产场景中)。 例如,通过PyTorch-BigGraph获得的78M Wikidata实体的200d嵌入需要👉110 GB的空间。 试想一下,轻柔的100倍压缩😏会发生什么。
➕ There is also a lineup of works that improve popular KGE models:* Tang et al generalize RotatE from 2D rotations to high-dimensional spaces with orthogonal relation transforms which works better for 1-N and N-N relations.* Xu et al generalize bilinear models to multi-linear by chunking dense vectors in K parts. It is then shown that if K=1 the approach is equal to DistMult, if K=2 the approach reduces to ComplEx and HolE, and the authors experiment with K=4 and K=8.* Xie et al extend ConvE by replacing standard conv filters with those from the Inception network famous in the Computer Vision domain.* Nguyen et al apply a self-attention style encoder and a CNN decoder for triple classification and search personalization tasks.
➕还有一系列可以改进流行的KGE模型的工作:* Tang等人使用正交关系变换将RotatE从2D旋转推广到高维空间,这对于1-N和NN关系更有效。* Xu等人对双线性模型进行了概括通过对K个部分中的密集向量进行分块,将其变为多线性。 然后表明,如果K = 1,则该方法等于DistMult ;如果K = 2,则该方法简化为ComplEx和HolE ,并且作者使用K = 4和K = 8进行实验。* Xie等人通过替换标准扩展了ConvE conv过滤器与计算机视觉领域中著名的Inception网络中的那些过滤器相比较。* Nguyen等人将自注意式编码器和CNN解码器用于三分类和搜索个性化任务。
数据文本NLG:准备变压器 (Data-to-text NLG: Prepare your Transformer)

As KGs (and structured data in general) become widely adopted in NLP, in 2020, we can observe a surge of natural language generation (NLG) approaches that take a set of RDF triples / an AMR graph / a set of table cells and produce a coherent human-readable text like description or question.
随着KG(以及一般的结构化数据)在NLP中被广泛采用,到2020年,我们可以观察到自然语言生成(NLG)方法的激增,这些方法采用一组RDF三元组/一个AMR图/一组表格单元并产生连贯的人类可读文本,例如描述或问题。
By the way, current RDF-to-text approaches are only evaluated on WebNLG 2017 data, but there is a new run of the challenge, WebNLG 2020! 🎉 If you are into NLG, be sure to participate 😉
顺便说一下,当前的RDF到文本的方法仅在WebNLG 2017数据上进行评估,但是又面临新的挑战, WebNLG 2020 ! 🎉如果您想参加NLG,请务必参加😉
Well, the NLG trend of the year is exhaustively summarized in one tweet:
好吧,今年的NLG趋势在一条推文中进行了详尽的总结:
Sophisticated planners and executors? Some structural alignment? NO 😅. Just spin up your favorite pre-trained LM.
复杂的计划者和执行者? 一些结构上的一致性? 不😅。 只需旋转您喜欢的预训练LM。
🤔 In fact, plugging in a pre-trained LM and feeding it a few examples indeed works. Chen et al demonstrate this phenomenon on tables coupled with the GPT-2 decoder. That is, table cells are first passed through a learnable LSTM encoder to get a hidden state for the copy mechanism. On the other hand, the text goes into GPT-2 with frozen weights. ✍️The copy mechanism on top helps to retain rare tokens from table cells. The experiments on WikiBio show that as few as 200 training examples are enough to generate texts much better than sophisticated strong baselines. Guess how many would GPT-3 need 😏
🤔实际上,插入预先训练的LM并提供一些示例确实可行。 Chen等人在与GPT-2解码器配合使用的桌上展示了这种现象。 也就是说,表单元格首先通过可学习的LSTM编码器传递,以获取复制机制的隐藏状态。 另一方面,文本以冻结的权重进入GPT-2。 ✍️顶部的复制机制有助于保留表格单元中的稀有令牌。 WikiBio上的实验表明,与复杂的基准相比,少至200个训练示例就足以生成更好的文本。 猜猜GPT-3需要多少😏


Continuing with tables, Chen et al build a new dataset, LogicNLG, that requires using additional logic on top of standard text generation. For example (cf the illustration), some comparative and counting operations are needed to include parts like “1 more gold medal” or “most gold medals” which make the text much more natural and lively 🌼. Baseline models for the dataset use pre-traind GPT-2 and BERT, but looks like there is still some room for LMs to improve.
继续使用表, Chen等人构建了一个新的数据集LogicNLG ,它需要在标准文本生成的基础上使用其他逻辑。 例如(参见插图),需要进行一些比较和计数操作,以包括“多1枚金牌”或“多数金牌”之类的部分,这使文本更加自然和生动。 数据集的基线模型使用预先训练的GPT-2和BERT,但看起来LM仍有改善的空间。
In the graph-to-text domain, Song et al apply a slightly modified Transformer encoder that explicitly processes relation surface forms. The input is just a linearized graph (which you can build, say, with DFS). The decoder is kept intact though. 🎩 The key component of the approach is to add (along with the standard LM loss) two autoencoding losses that are designed to better capture structure of the verbalized graphs. The first loss reconstructs triple relations, whereas another reconstructs nodes and edge labels of linearized input graphs. 🧪 Experiments conducted on AMR and RDF graphs (WebNLG) suggest that just adding those two losses could yield about 2 BLEU points.
在图文转换领域, Song等 应用经过稍微修改的Transformer编码器,该编码器可显式处理关系曲面形式。 输入只是一个线性化的图(例如,您可以使用DFS进行构建)。 解码器仍然保持完整。 approach该方法的关键部分是(与标准LM损失一起)添加两个自动编码损失,这些损失旨在更好地捕获语言化图的结构。 第一个损失重建三元关系,而另一个损失重建线性化输入图的节点和边缘标签。 on在AMR和RDF图(WebNLG)上进行的实验表明,仅将这两个损失相加就可以产生大约2个BLEU点。


🗒 At this point I should make a small remark that everybody should stop using BLEU for evaluating NLG quality (one of the best ACL’20 paper nominees, I’d trust them). The organizers of WebNLG 2020 pretty much share this opinion as they officially measure chrF++ and BertScore in addition to the classic (or shall we say outdated?) metrics. Furhermore, here at ACL’20 a new metric, BLEURT, was proposed and shown to better correlate with human judgement. Let’s invest into those new evaluation metrics and let ol’ BLEU go for some rest 🏖
🗒现在,我要说一点, 每个人都应该停止使用BLEU来评估NLG的质量 (我相信他们是ACL'20最佳论文提名人之一)。 WebNLG 2020的组织者在正式测量chrF ++和BertScore以及经典(或者我们应该说过时?)指标之外,几乎分享了这一观点。 此外,在ACL'20上 ,人们提出了一种新的指标BLEURT ,该指标显示出与人类判断更好的关联。 让我们投资这些新的评估指标,让ol'BLEU休息一下吧🏖
🌳 Still, there is a vivid life in the world without (or at least not that much of) transformers! Applied to the graph-to-text task, Zhao et al propose DualEnc, an encoder-planner-decoder model. 1️⃣ First, the input graph is pre-processed to transform a relation into an explicit node. Hence, there are several induced labeled edges s->p, p->s, p->o, o->p. The graph is then encoded via R-GCN to obtain entity and relation embeddings. 2️⃣ The same graph is encoded through another R-GCN with additional features showing whether a relation has been used already or not. The plan is constructed in the following manner: while there are unvisited relations, softmax selects the most probable relation, the relation is then appended to the plan. Once the sequence is ready, it is extended with subjects and objects of the those relations. Finally, the resulting sequence is encoded via LSTM. Both graph encoding and plan encoding are fed into the decoder to generate the output.📏 The experiments show: 1) that DualEnc shows very good generalization on the unseen test set in plan building, 2) text generation quality outperforms straightly applied transformers, 3) great speedup of the planning stage, i.e., 2019 SOTA needs 250 seconds to solve one 7-triple instance, whereas DualEnc solves all 4928 examples in 10 seconds 🚀
🌳尽管如此,如果没有(或至少没有那么多)变压器,世界上仍然存在着生动的生活! Zhao等人将其应用于图形到文本的任务后,提出了DualEnc ,一种编码器-计划器-解码器模型。 1️⃣首先,对输入图进行预处理,以将关系转换为显式节点。 因此,存在几个诱导的标记边缘s->p, p->s, p->o, o->p 。 然后通过R-GCN对图形进行编码,以获得实体和关系嵌入。 2️⃣同一张图通过另一个R-GCN编码,并带有其他功能,以显示是否已经使用关系。 该计划以以下方式构造:当存在未访问的关系时,softmax选择最可能的关系,然后将该关系附加到计划中。 一旦准备好序列,就可以扩展这些关系的主题和对象。 最后,所得序列通过LSTM编码。 图形编码和计划编码都馈入解码器以生成输出。📏实验表明:1) DualEnc在计划构建中看不见的测试集上表现出很好的概括性; 2)文本生成质量优于直接应用的转换器; 3)大大加快了规划阶段的速度,例如,2019 SOTA需要250秒才能解决一个 7倍的三倍实例,而DualEnc可以在10秒内解决所有4928个示例。

Finally, let’s move from data-to-text to summarization. In the domain of abstractive summarization Huang et al employ KGs built from a document to enhance the generation procedure in their ASGARD approach.
最后,让我们从数据到文本过渡到摘要。 在抽象总结领域, Huang等 使用从文档中构建的KG来增强其ASGARD方法中的生成过程。

Concretely, the encoder consists of two parts. 1️⃣ RoBERTa is used to encode input paragraphs. The final layer embeddings are fed into a BiLSTM to obtain hidden states. 2️⃣ OpenIE is used to extract triples and induce a graph from the input document. Tokens of relations are transformed into explicit nodes similar to DualEnc, and initial node states are taken from the BiLSTM from step 1. Graph Attention Net (GAT) is then used to update the node states with a readout function to get a graph context vector. 3️⃣ The generation process is conditioned by both vectors obtained at steps 1 and 2.
具体而言,编码器由两部分组成。 1️⃣RoBERTa用于编码输入段落。 最终的层嵌入被馈送到BiLSTM中以获得隐藏状态。 2️⃣OpenIE用于提取三元组并从输入文档中生成图形。 关系的令牌被转换为类似于DualEnc的显式节点,并且从步骤1的BiLSTM中获取初始节点状态。然后,使用图注意力网络(GAT)通过读取功能更新节点状态以获得图上下文向量。 3️⃣生成过程取决于在步骤1和步骤2中获得的两个向量。
🧙♂️Some magic happens in training: ASGARD resorts to reinforcement learning where thee reward function depends on ROUGE and cloze score. The cloze part consists in extracting OpenIE graphs from human-written summaries and generating cloze-style questions based on them for the system to better learn the meaning of the summarized document. 📦 So you kinda have a QA model inside! The authors generate 1M+ cloze questions for CNN and NYT datasets. 📏 Experiments report improvements over previous baselines! However, the unanimous winner is a pre-trained BART fine-tuned on the target dataset 😅 Well, looks like the “TPUs go brrr” strategy works here, too.
training♂️一些不可思议的事情发生在训练中: ASGARD依靠强化学习,其中奖励功能取决于ROUGE和完形填空得分。 完形填空部分包括从人工编写的摘要中提取OpenIE图,并基于这些摘要生成完形填空样式的问题,以使系统更好地了解摘要文档的含义。 📦这样您内部就有一个质量检查模型! 作者为CNN和NYT数据集生成了1M +次完形填空问题。 📏实验报告比以前的基准有所改善! 但是,一致的获胜者是在目标数据集上进行了微调的预训练BART。😅,看起来“ TPU变得更聪明”策略在这里也起作用。
对话式AI:改善面向目标的机器人 (Conversational AI: Improving Goal-Oriented Bots)
In the ConvAI domain, I am a bit biased towards goal-oriented systems as KGs and structured data naturally extend their capabilities.
在ConvAI领域中,由于KG和结构化数据自然地扩展了它们的功能,因此我偏向于面向目标的系统。

🔥 First, Campagna et al propose a method to synthesize goal-oriented dialogues as additional training data for the dialogue state tracking (DST) task. The authors create an abstract model (one could name it an ontology, too) that defines basic states, actions, and transitions. Why this is cool: 1️⃣ the model can be applied to various domains like restaurant booking or train connection search with any slots and values; 2️⃣ synthesized data allows for a zero-shot transfer in domains where you have very limited supervised data. 3️⃣ In fact, the experiments show that using only the synthesized corpus for training (and evaluating on the real MultiWoz 2.1 test) reaches about 2/3 of the accuracy of the original full training set 💪 I believe the method could be used as a general data augmentation practice in developing dialogue systems in specific domains or where annotated training data is limited.
🔥首先, Campagna等人提出了一种方法,可以将面向目标的对话作为对话状态跟踪(DST)任务的附加训练数据进行合成。 作者创建了一个定义基本状态,动作和转换的抽象模型(也可以将其称为本体 )。 为什么这样很酷:1️⃣该模型可以应用于各种领域,例如餐厅预订或具有任何位置和值的火车连接搜索; 2️⃣综合数据允许在您的监督数据非常有限的域中进行零快照传输。 3️⃣实际上,实验表明, 仅使用合成语料进行训练(并在真实的MultiWoz 2.1测试中进行评估),其精度约为原始完整训练集的2/3💪我相信该方法可以用作一般方法开发特定领域或注释的培训数据受限的对话系统中的数据增强实践。

Focusing on relation extraction in dialogues, Yu et al develop DialogRE, a new dataset comprised of 36 relations taken from about 2k dialogues from Friends. Although the relations are not annotated with Wikidata or DBpedia URIs, the dataset still poses a considerable challenge even for BERT. Furthermore, the authors propose a new metric that shows how many turns a system needs to extract a certain relation.
Yu等人着重于对话中的关系提取,开发了DialogRE ,这是一个新的数据集,包括从Friends的大约2k对话中获取的36个关系。 尽管没有用Wikidata或DBpedia URI注释关系,但是即使对于BERT,数据集仍然构成很大的挑战。 此外,作者提出了一种新的度量标准,该度量标准显示系统提取特定关系需要转多少圈。
OpenDialKG was one of the best paper award nominees at ACL 2019 for the efforts promoting graph-based reasoning in dialogue systems in a new dataset. Zhou et al did a great job adopting the main ideas of OpenDialKG in their new KdConv dataset suited for Chinese 👏
OpenDialKG是ACL 2019最佳论文奖提名之一,因为它致力于在新数据集中的对话系统中促进基于图的推理。 Zhou等在他们适合中国人的新KdConv数据集中采用OpenDialKG的主要思想做得很出色。
There is also a lineup of works studying how to incorporate external knowledge in end-to-end dialogue systems. If your background knowledge is expressed as textual triples or table cells (or even plain text), Lin et al suggest using Transformer as knowledge encoder, while Qin et al rely on memory network-like encoder. If you have a commonsense KG like ConceptNet, Zhang et al extract concepts from utterances to build a local graph and then employ a GNN encoder to encode the “central concept” of the conversation which will affect the decoder. If you are interested in even more recent ConvAI goodies, be sure to check the proceedings of the NLP for ConvAI workshop co-located (well, virtually) with ACL!
还有一系列研究如何将外部知识纳入端到端对话系统的作品。 如果您的背景知识表示为文本三元组或表格单元格(甚至纯文本), Lin等人建议使用Transformer作为知识编码器,而Qin等人则依赖于类似于内存网络的编码器。 如果您有一个像ConceptNet这样的常识性KG, Zhang等人就从话语中提取概念以构建局部图,然后使用GNN编码器对将影响解码器的对话“中心概念”进行编码。 如果您对最新的ConvAI产品感兴趣,请务必检查与ACL一起(实际上是在同一地点)的ConvAI研讨会的NLP程序!
信息提取:OpenIE和链接预测 (Information Extraction: OpenIE and Link Prediction)
If your work happens to be about building KGs from raw text documents, probably you already know that OpenIE is a de-facto standard to start from. As we have seen in previous sections, rule-based frameworks like OpenIE4 or OpenIE 5 are still actively used. That is, increasing the quality of OpenIE extractions could alleviate many problems in KG construction. A small note: KGs obtained after Open IE are also called Open KGs.
如果您的工作恰好是从原始文本文档构建KG,那么您可能已经知道OpenIE是事实上的标准。 正如我们在前几节中所看到的,仍在积极使用基于规则的框架,如OpenIE4或OpenIE 5。 也就是说,提高OpenIE提取的质量可以减轻KG构建中的许多问题。 注意:Open IE之后获得的KG也称为Open KG 。
Kolluru et al propose a generative OpenIE approach, IMoJIE (Iterative Memory-based Joint Information Extraction). Inspired by the CopyAttention paradigm, the authors propose an iterative generative seq2seq IE algorithm: at each iteration, the original sequence is concatenated with previous extractions and passed through BERT to obtain final embeddings. The LSTM decoder with copy and attention mechanisms is then tasked to generate a new extraction (tokens that would comprise a triple, for instance). 🤖To further improve the training set, the authors aggregate and rank outputs of OpenIE 3, OpenIE 4, and other systems as “silver labels” for generation. Although the architecture looks pretty simple, it does bring significant improvements 📈 compared to existing baselines. The ablation study reports that BERT is pretty crucial for the overall quality, so I’d hypothesize that quality could be further improved plugging in a bigger Transformer, or using a domain-specific pre-trained LM, e.g., if your text is from legal or biomed field.
Kolluru等人提出了一种生成式OpenIE方法,即IMoJIE(基于迭代内存的联合信息提取) 。 受CopyAttention范式的启发,作者提出了一种迭代生成的seq2seq IE算法:在每次迭代中,原始序列都与先前的提取串联在一起,并通过BERT进行传递以获得最终嵌入。 然后,具有复制和注意机制的LSTM解码器的任务是生成新的提取(例如,包含三元组的令牌)。 🤖为了进一步改进培训集,作者将OpenIE 3,OpenIE 4和其他系统的输出汇总和排名,作为“银色标签”进行生成。 尽管该体系结构看起来很简单,但与现有基准相比确实带来了重大改进。 消融研究报告说,BERT对于整体质量至关重要,因此我认为可以进一步提高质量,例如插入更大的Transformer或使用经过特定领域培训的LM,例如,如果您的文字来自法律法规,或生物医学领域。

While link prediction (LP) on RDF-like KGs has an established track record and several milestones, we could not say the same about LP on open KGs.
尽管类似RDF的KG的链路预测(LP)已有良好的记录和几个里程碑,但对于开放式KG的LP,我们不能说相同的话。

But now we can! 🤩 Broscheit et al define the task of open link prediction given the challenges of open KGs:
但是现在我们可以了! s Broscheit等人鉴于开放式KG的挑战,定义了开放链接预测的任务:
Given a (‘subject text’, ‘relation text’, ?) query, the system has to predict genuine, new facts that can’t be trivially explained.
给定一个(“主题文本”,“关系文本”,?)查询,该系统必须预测无法被简单解释的真实的新事实。
- However, no entity or relation URIs available that would bind many surface forms to one representation. 但是,没有可用的实体或关系URI将许多表面形式绑定到一种表示形式。
- Still, various surface forms of the same entity or relation might constitute a test set leakage, so the test set has to be carefully constructed and cleaned. 尽管如此,同一实体或关系的各种表面形式仍可能构成测试仪泄漏,因此必须仔细构造和清洁测试仪。
The authors propose a methodology how to build and clean the dataset, an evaluation protocol, and the benchmark itself. The OLPBench is one of the largest datasets for LP with KG embeddings: it contains 30M triples, 1M distinct open relations, and 2.5M mentions of 800K unique entities 👀. For experiments, the authors use ComplEx, where multi-token mentions are aggregated via LSTM. The open LP task turns out to be very difficult 😯: even mighty 768d ComplEx yields only 3.6 MRR, 2 Hits@1, and 6.6 Hits@10. Clearly, this is a very challenging dataset: it is quite interesting to see the approaches that would be not only scalable to such a large graph but also increase the performance to FB15k-237-like numbers (FYI, currently it is about 35 MRR points and 55 Hits@10).
作者提出了一种方法来构建和清理数据集,评估协议以及基准本身。 OLPBench是带有KG嵌入的LP的最大数据集之一:它包含3000万个三元组,1M个不同的开放关系以及250万个提及的800K个唯一实体👀。 对于实验,作者使用ComplEx,其中通过LSTM汇总了多个令牌。 开放的LP任务非常困难😯:即使强大的768d ComplEx也只能产生3.6 MRR,2 Hits @ 1和6.6 Hits @ 10。 显然,这是一个非常具有挑战性的数据集:非常有趣的是,这些方法不仅可以扩展到如此大的图形,而且还可以将性能提高到类似FB15k-237的数字(仅供参考,目前约为35个MRR点和55 Hits @ 10)。
By the way, if you are further interested in building KGs from text, I’d encourage you to check the proceedings of the recent AKBC 2020 conference which attracted a great lineup of speakers and publications 👏
顺便说一句,如果您进一步感兴趣于从文本中构建KG,我鼓励您查看最近的AKBC 2020会议的会议记录,该会议吸引了众多演讲者和出版物publication
结论 (Conclusion)
This year at ACL’20 we see less KG-augmented language models (but do have a look at TaPas and TABERT that were designed to work over tables) and maybe a bit less of NER. On the other hand, graph-to-text NLG is on the rise!Still, you made it to the end, dear reader, and you deserve some applause :)
今年在ACL'20上,我们看到了较少的KG增强型语言模型(但确实了解了设计用于表格的TaPas和TABERT ),而NER的数量可能要少一些。 另一方面,图文NLG仍在上升!亲爱的读者,您终于做到了,值得鼓掌:)

Let me know in the comments what you liked and what is to be improved. Thanks for reading and stay tuned for more publications 😌
在评论中让我知道您喜欢什么以及有待改进的地方。 感谢您的阅读,敬请期待更多出版物😌
翻译自: https://towardsdatascience.com/knowledge-graphs-in-natural-language-processing-acl-2020-ebb1f0a6e0b1
acl自然语言处理















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









