





 本文探讨了人工智能在机械工程领域的应用,介绍如何利用Python和机器学习技术提升机械设备的设计、分析与制造效率。
本文探讨了人工智能在机械工程领域的应用,介绍如何利用Python和机器学习技术提升机械设备的设计、分析与制造效率。
机械工程人工智能
Artificial Intelligence and Machine Learning seems to be the current buzzword as everyone seems to be getting into this subject. Artificial Intelligence seems to have a role in all fields of science. According to Britannica , “Artificial intelligence (AI), is broadly defined as the ability of a digital computer or computer-controlled robot to perform tasks commonly associated with intelligent beings.” By intelligent beings it basically means humans … but maybe not all humans…so anyway,It is usually classified into three subsets as shown below.
人工智能和机器学习似乎是当前的流行语,因为每个人似乎都在涉足这一领域。 人工智能似乎在科学的所有领域都发挥着作用。 据全书“人工智能(AI),被广泛地定义为数字的能力的计算机或计算机控制的机器人来执行通常与智能生物相关联的任务”。 对于有智慧的人,它基本上是指人类……但可能并非所有人……因此,无论如何,它通常分为以下三个子集。
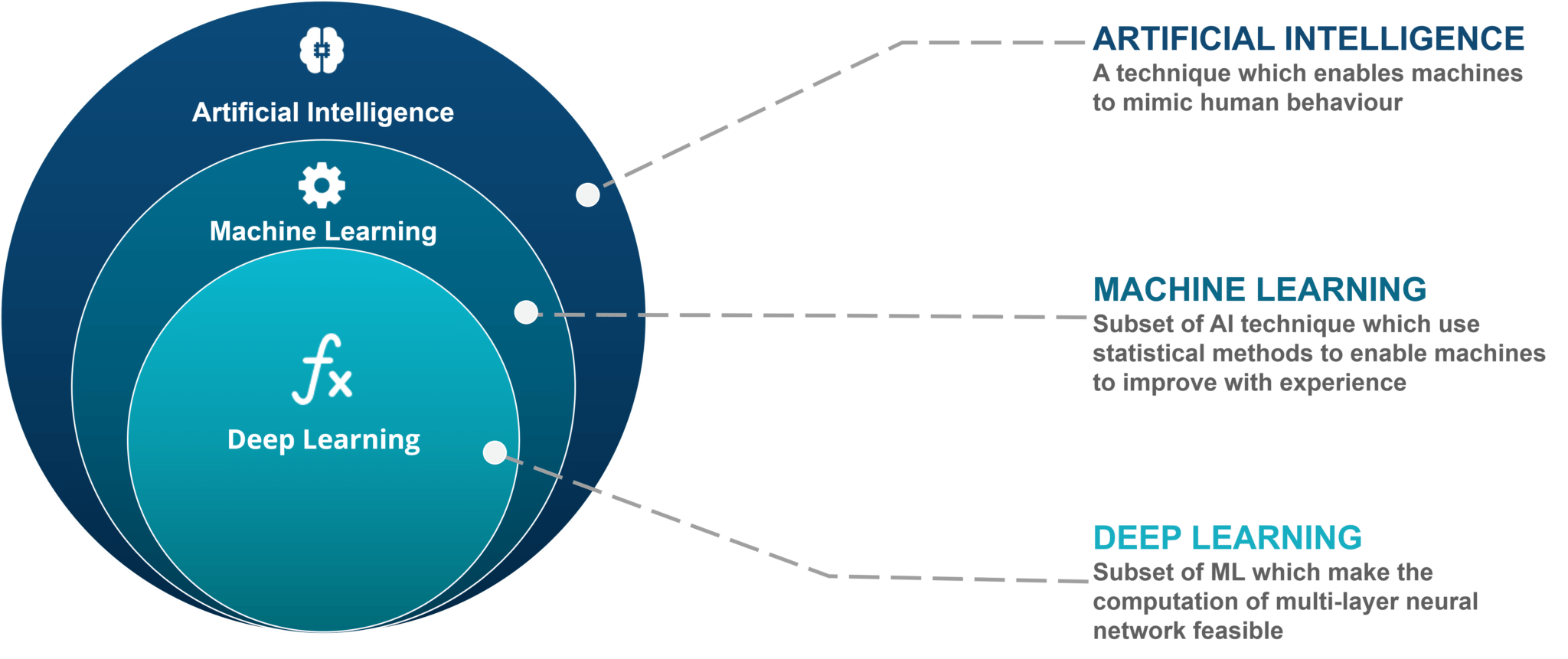
Artificial Intelligence is a broader term which in cooperates Machine Learning. Machine learning uses statistical methods to allow machines to improve with experience.
人工智能是与机器学习合作的更广泛的术语。 机器学习使用统计方法来使机器根据经验进行改进。
Deep Learning, again, is the subset of Machine Learning which uses multi layer neural networks that mimic the human brain and can learn incredibly difficult tasks with enough data.
深度学习同样是机器学习的子集,它使用模仿人类大脑的多层神经网络,并且可以利用足够的数据学习难以完成的任务。
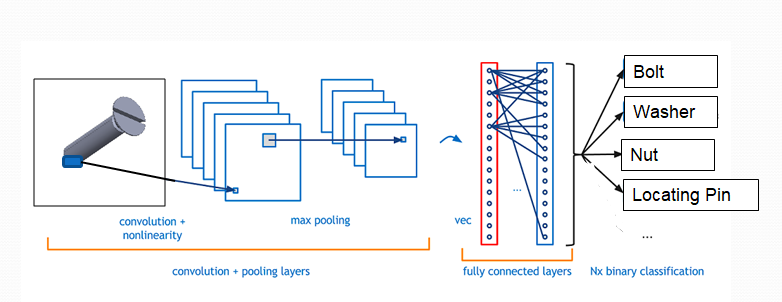
We are going to talk about Deep learning methods and its possible role in the field of Mechanical Engineering. Some common examples could be Anomaly Detection(Machine Learning) and Image based Part Classification(Deep Learning). The focus will be on Image based part classifiers and why we need them.
我们将讨论深度学习方法及其在机械工程领域的可能作用。 一些常见的示例可能是异常检测(机器学习)和基于图像的零件分类(深度学习) 。 重点将放在基于图像的零件分类器上以及我们为什么需要它们。
Firstly, what is an image classifier? The ever famous AI which recognizes cat-dog pictures should come to mind. Here’s a link to the code of such a program. The data-set used contains images of cats and dogs, the algorithm learns from it and then is able to guess with 97% accuracy whether a randomly shown image is a cat or a dog.
首先,什么是图像分类器? 想到猫的狗图片的著名AI应该浮现在脑海。 这是该程序代码的链接 。 所使用的数据集包含猫和狗的图像,该算法从中获知,然后能够以97%的准确度猜测随机显示的图像是猫还是狗。

We will attempt a similar code but using Nuts, Bolts, Washers and Locating Pins as our Cats and Dogs….. because mechanical engineering.
我们将尝试类似的代码,但是将螺母,螺栓,垫圈和定位销用作猫和狗。

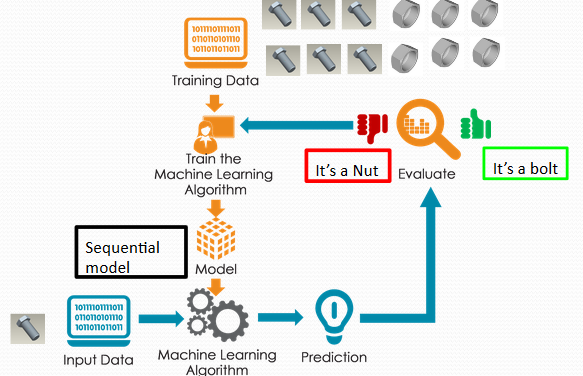
So how does it work? An algorithm is able to classify images(efficiently) by using a Machine Learning algorithm called Convolutional Neural Networks(CNN) a method used in Deep Learning. We will be using a simple version of this model called Sequential to let our model distinguish the images into four classes Nuts, Bolts, Washers and Locating Pins. The model will learn by “observing” a set of training images. After learning we will see how accurately it can predict what an image (which it has not seen) is.
那么它是怎样工作的? 通过使用称为深度学习中使用的卷积神经网络(CNN)的机器学习算法,该算法能够高效地对图像分类。 我们将使用此模型的一个简单版本(称为顺序序列),使我们的模型将图像区分为四类:螺母,螺栓,垫圈和定位销。 该模型将通过“观察”一组训练图像来学习。 学习后,我们将看到它可以预测出什么图像(未看到)是多么准确。
Go directly to the code in github
数据集 (Data-set)
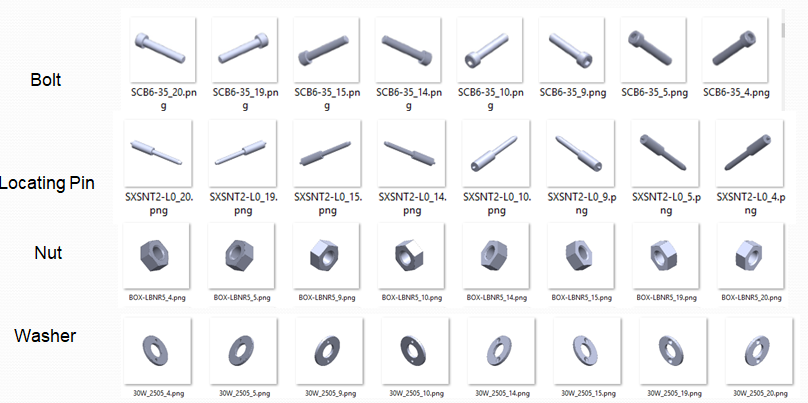
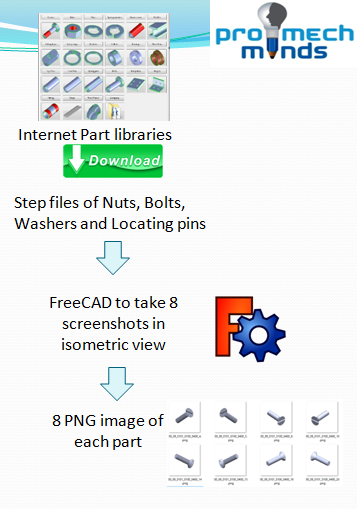
We downloaded 238 parts each of the 4 classes (Total 238 x 4 = 952) from various part libraries available on the internet. Then we took 8 different isometric images of each part. This was done to augment the data available, as only 238 images for each part would not be enough to train a good neural network. A single class now has 1904 images(8 isometric images of 238 parts) a total of 7616 images. Each image is of 224 x 224 pixels.
我们从互联网上提供的各种零件库中下载了4个类中的238个零件(总计238 x 4 = 952)。 然后,我们为每个零件拍摄了8张不同的等轴测图。 这样做是为了增加可用数据,因为每个部分只有238张图像不足以训练一个好的神经网络。 现在,一个类拥有1904个图像(8个等轴测图像,共238个部分),总共7616个图像。 每个图像为224 x 224像素。
We then have our labels with numbers 0,1,2,3 each number corresponds to a particular image and means it belongs to certain class
然后,我们得到带有数字0、1、2、3的标签,每个数字对应一个特定的图像,这意味着它属于特定类别
#Integers and their corresponding classes
{0: 'locatingpin', 1: 'washer', 2: 'bolt', 3: 'nut'}After training on the above images we will then see how well our model predicts a random image it has not seen.
在对以上图像进行训练之后,我们将看到我们的模型预测未看到的随机图像的能力。
方法 (Methodology)
The process took place in 7 steps. We will get to the details later. The brief summary is
该过程分7个步骤进行。 稍后我们将详细介绍。 简要摘要是
Data Collection : The data for each class was collected from various standard part libraries on the internet.
数据收集 :每个类别的数据都是从互联网上的各种标准零件库中收集的。
Data Preparation : 8 Isometric view screenshots were taken from each image and reduced to 224 x 224 pixels.
数据准备:从每个图像中获取8张等轴测视图屏幕快照,并将其缩小为224 x 224像素。
Model Selection : A Sequential CNN model was selected as it was simple and good for image classification
模型选择:选择顺序CNN模型,因为它简单且易于图像分类
Train the Model: The model was trained on our data of 7616 images with 80/20 train-test split
训练模型:使用我们的7616图像数据对模型进行了训练,并进行了80/20火车测试拆分
Evaluate the Model: The results of the model were evaluated. How well it predicted the classes?
评估模型:评估了模型的结果。 它对课程的预测如何?
Hyperparameter Tuning: This process is done to tune the hyperparameters to get better results . We have already tuned our model in this case
超参数调整:完成此过程以调整超参数以获得更好的结果。 在这种情况下,我们已经调整了模型
Make Predictions: Check how well it predicts the real world data
做出预测:检查其对现实世界数据的预测程度
数据采集 (Data Collection)
We downloaded the part data of various nuts and bolts from the different part libraries on the internet. These websites have numerous 3D models for standard parts from various makers in different file formats. Since we will be using FreeCAD API to extract the images we downloaded the files in neutral format (STEP).
我们从互联网上不同的零件库下载了各种螺母和螺栓的零件数据。 这些网站具有来自不同制造商的标准零件的不同文件格式的大量3D模型。 由于我们将使用FreeCAD API提取图像,因此我们以中性格式(STEP)下载了文件。
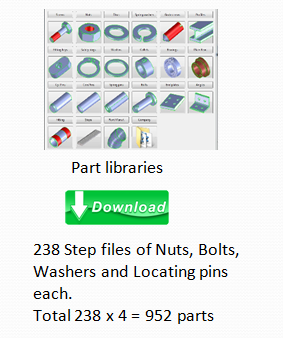
As already mentioned earlier, 238 parts from each of the 4 class was downloaded, that was a total of 952 parts.
如前所述,从4个类的每个部分中下载了238个部分,总共952个部分。
资料准备 (Data Preparation)
Then we ran a program using FreeCAD API that automatically took 8 isometric screenshots of 224 x 224 pixels of each part. FreeCAD is a free and open-source general-purpose parametric 3D computer-aided design modeler which is written in Python.
然后,我们使用FreeCAD API运行了一个程序,该程序自动拍摄了8个等距的屏幕截图,每个部分的224 x 224像素。 FreeCAD是一个免费的开源通用参数化3D计算机辅助设计建模器,它使用Python编写。
As already mentioned above, each data creates 8 images of 224 x 224 pixels. So we now have a total of 1904 image from each of the 4 classes, thus a total of 7616 images. Each image is treated as a separate data even though 8 images come from the same part.
如上所述,每个数据创建8个224 x 224像素的图像。 因此,我们现在从4个类别的每个类别中总共获得了1904张图像,因此共有7616张图像。 即使8个图像来自同一部分,每个图像也被视为单独的数据。
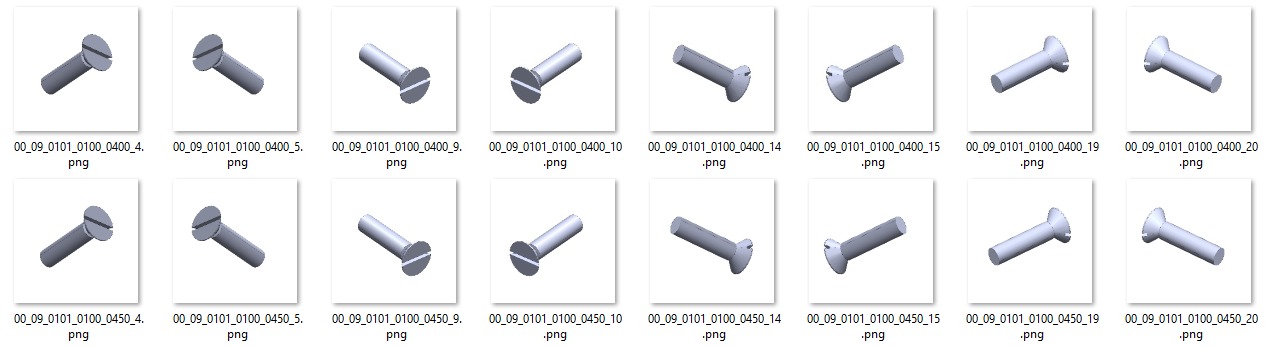
The images were kept in separated folders according to their class. i.e. we have four folders Nut,Bolt, Washer and Locating Pin.
图像根据类别被保存在单独的文件夹中。 即,我们有四个文件夹:螺母,螺栓,垫圈和定位销。
Next, each of these images were converted into an array with their pixel values in grayscale. The value of the pixels range from 0 (black), 255 (white). So its actually 255 shades of gray.
接下来,将这些图像中的每个图像转换为像素值为灰度的数组。 像素值的范围是0(黑色),255(白色)。 因此,它实际上是255个灰色阴影。
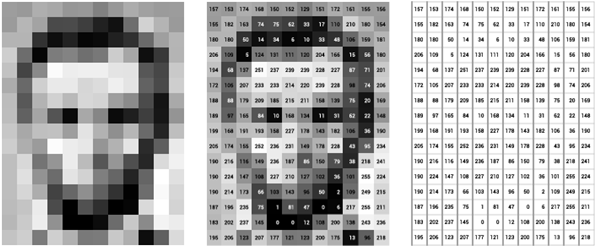
Now each of our image becomes a 224 x 224 array. So our entire dataset is a 3D array of 7616 x 224 x 224 dimensions.7616 (No. of images) x 224 x 224 (pixel value of each image)
现在,我们的每个图像都变成了224 x 224的阵列。 因此,我们的整个数据集是一个7616 x 224 x 224尺寸的3D数组。7616( 图像数量 )x 224 x 224( 每个图像的像素值 )
Similarly we create a the label dataset by giving the value of the following integers for the shown classes to corresponding indexes in the dataset. If our 5th(index) data in the dataset(X) is a locating pin , the 5th data in label set (Y) will have value 0.
类似地,我们通过将所示类的以下整数值赋予数据集中的相应索引来创建标签数据集。 如果数据集(X)中的第5个( 索引 )数据是定位销,则标签集(Y)中的第5个数据将具有值0。
#integers and the corresponding classes as already mentioned above
{0: 'locatingpin', 1: 'washer', 2: 'bolt', 3: 'nut'}选型 (Model Selection)
Since this is an image recognition problem we will be using a Convolutional Neural Network (CNN). CNN is a type of Neural Network that handles image data especially well. A Neural Network is a type of Machine learning algorithm that learns in a similar manner to a human brain.
由于这是图像识别问题,因此我们将使用卷积神经网络(CNN)。 CNN是一种神经网络,可以很好地处理图像数据。 神经网络是一种机器学习算法,以类似于人脑的方式学习。
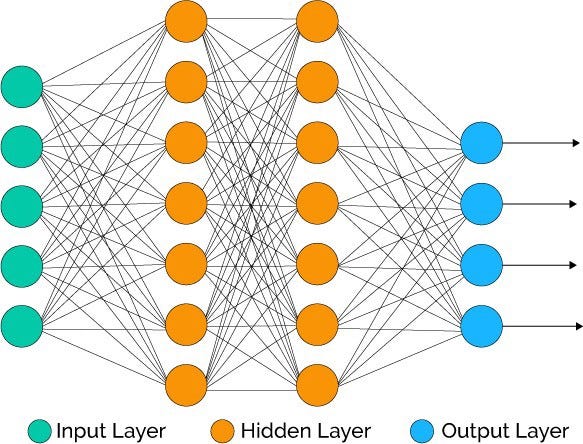
The following code is how our CNN looks like. Don’t worry about it if you don’t understand. The idea is the 224 x 224 features from each of our data will go through these network and spit out an answer. The model will adjusts its weights accordingly and after many iterations will be able to predict a random image’s class.
以下代码是我们的CNN的样子。 如果您不了解,请不要担心。 这个想法是,我们每个数据的224 x 224特征将通过这些网络并给出答案。 该模型将相应地调整其权重,并且在多次迭代之后将能够预测随机图像的类别。
#Model description
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 222, 222, 128) 1280
_________________________________________________________________
activation_1 (Activation) (None, 222, 222, 128) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 111, 111, 128) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 109, 109, 128) 147584
_________________________________________________________________
activation_2 (Activation) (None, 109, 109, 128) 0
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 54, 54, 128) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 373248) 0
_________________________________________________________________
dense_1 (Dense) (None, 64) 23887936
_________________________________________________________________
dense_2 (Dense) (None, 4) 260
_________________________________________________________________
activation_3 (Activation) (None, 4) 0
=================================================================
Total params: 24,037,060
Trainable params: 24,037,060
Non-trainable params: 0Here is a YouTube video of Mark Rober (a NASA mechanical engineer) explaining how neural networks work with very little coding involved.
这是Mark Rober(美国宇航局机械工程师)的YouTube视频,解释了神经网络如何以很少的编码工作。
模型训练 (Model Training)
Now finally the time has come to train the model using our dataset of 7616 images. So our [X] is a 3D array of 7616 x 224 x224 and [y] label set is a 7616 x 1 array. For all training purposes a data must be split into at least two parts: Training and Validation (Test) set (test and validation are used interchangeably when only 2 sets are involved).
现在终于到了使用我们的7616张图像数据集训练模型的时候了。 因此,我们的[X]是7616 x 224 x224的3D数组,[y]标签集是7616 x 1的数组。 对于所有培训目的,数据必须至少分为两部分:培训和验证(测试)集(仅涉及两个集时,测试和验证可互换使用)。
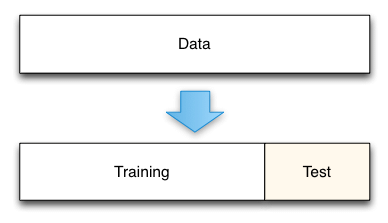
The training set is the data the model sees and trains on. It is the data from which it adjusts its weights and learn. The accuracy of our model on this set is the training accuracy. It is generally higher than the validation accuracy.
训练集是模型看到并训练的数据。 它是从中调整权重和学习的数据。 我们在该集合上的模型的准确性是训练准确性。 它通常高于验证精度。
The validation data usually comes from the same distribution as the training set and is the data the model has not seen. After the model has trained from the training set, it will try to predict the data of the validation set. How accurately it predicts this, is our validation accuracy. This is more important than the training accuracy. It shows how well the model generalizes.
验证数据通常来自与训练集相同的分布,并且是模型尚未看到的数据。 从训练集中训练模型之后,它将尝试预测验证集的数据。 它的预测准确度是我们的验证准确度。 这比训练的准确性更为重要。 它显示了模型的概括性。
In real life application it is common to split it even into three parts. Train, Validation and Test.
在现实生活中,通常将其分为三个部分。 培训,验证和测试。
For our case we will only split it into a training and test set. It will be a 80–20 split. 80 % of the images will be used for training and 20% will be used for testing. That is train on 6092 samples, test on 1524 samples from the total 7616.
对于我们的情况,我们只会将其分为训练和测试集。 这将是80–20的比例。 80%的图像将用于训练,而20%的图像将用于测试。 也就是说,对6092个样本进行训练,对总计7616个样本中的1524个样本进行测试。
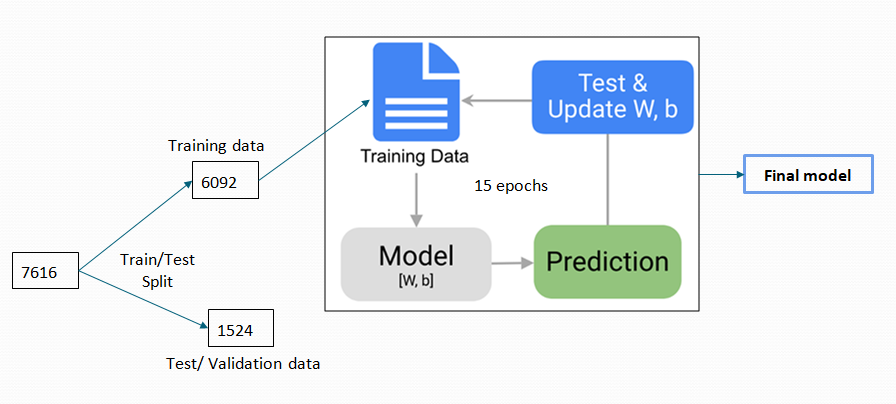
For our model we trained for 15 epochs with a batch-size of 64.
对于我们的模型,我们训练了15个时期,批处理大小为64。
The number of epochs is a hyperparameter that defines the number times that the learning algorithm will work through the entire training dataset.
时期数是一个超参数,它定义学习算法将在整个训练数据集中工作的次数。
One epoch means that each sample in the training dataset has had an opportunity to update the internal model parameters. An epoch is comprised of one or more batches.
一个时期意味着训练数据集中的每个样本都有机会更新内部模型参数。 一个时期由一个或多个批次组成。
You can think of a for-loop over the number of epochs where each loop proceeds over the training dataset. Within this for-loop is another nested for-loop that iterates over each batch of samples, where one batch has the specified “batch size” number of samples. [2]
您可以考虑在每个循环在训练数据集上进行的时期数的for循环。 在此for循环中,是另一个嵌套的for循环,它对每一批样本进行迭代,其中一批具有指定的“批次大小”数目的样本。 [2]
That is our model will go through our entire 7616 samples 15 times (epoch) in total and adjust its weights each time so the prediction is more accurate each time. In each epoch, it will go through the 7616 samples, 64 samples (batch size) at a time.
也就是说,我们的模型将总共15次(历时)遍历整个7616个样本,并每次调整其权重,从而使每次预测都更加准确。 在每个时期,它将进行7616个样本,一次64个样本(批大小)。
评估模型 (Evaluate the model)
The model keeps updating its weight so as to minimize the cost(loss), thus giving us the best accuracy. Cost is a measure of inaccuracy of the model in predicting the class of the image. Cost functions are used to estimate how badly models are performing. Put simply, a cost function is a measure of how wrong the model is in terms of its ability to estimate the relationship between X and y. [1]
该模型会不断更新其权重,以最大程度地降低成本(损失),从而为我们提供最佳的准确性。 成本是模型在预测图像类别时的不准确性的度量。 成本函数用于估计模型的执行状况。 简而言之,成本函数是根据模型估计X和y之间关系的能力来衡量模型的错误程度。 [1]
If the algorithm predicts incorrectly the cost increases, if it predicts correct the cost decreases.
如果算法错误地预测成本增加,则如果算法正确预测成本降低。
After training for 15 epochs we can see the following graph of loss and accuracy. (Cost and loss can be used interchangeably for our case)
训练15个纪元后,我们可以看到以下损失和准确性图表。 (成本和损失在我们的案例中可以互换使用)
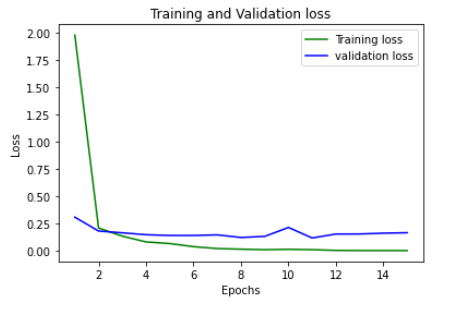
The loss decreased as the model trained more times. It becomes better at classifying the images with each epoch. The model is not able to improve the performance much on the validation set.
随着模型训练更多次,损失减少了。 在每个时期对图像进行分类变得更好。 该模型无法在验证集上大大提高性能。
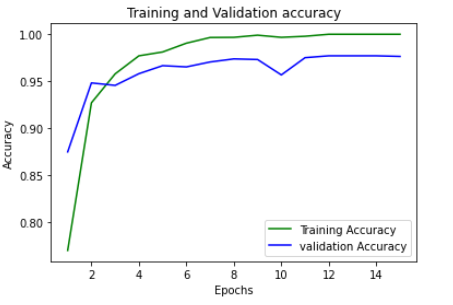
The accuracy increased as the model trains for each epoch. It becomes better at classifying the images. The accuracy is for the validation set is lower than the training set as it has not trained on it directly. The final value is 97.64% which is not bad.
随着模型针对每个时期的训练,准确性提高。 在图像分类方面变得更好。 验证集的准确性低于训练集,因为它没有直接对其进行训练。 最终值为97.64%,还不错。
超参数调整 (Hyperparameter Tuning)
The next step would to be change the hyperparameters, the learning rate,number of epochs, data size etc. to improve our model. In machine learning, a hyperparameter is a parameter whose value is used to control the learning process. By contrast, the values of other parameters (typically node weights) are derived via training.[3]
下一步将是更改超参数,学习率,时期数,数据大小等,以改进我们的模型。 在机器学习中 , 超 参数是一个参数,其值用于控制学习过程。 相比之下,其他参数的值(通常是节点权重)是通过训练得出的。[3]
For our purpose we have already modified these parameters before this article was written, in a way to obtain an optimum performance for display on this article. We increased the dataset size and number of epochs to improve the accuracy.
为了达到我们的目的,在写本文之前,我们已经修改了这些参数,以便获得最佳性能以显示在本文上。 我们增加了数据集的大小和时期数以提高准确性。
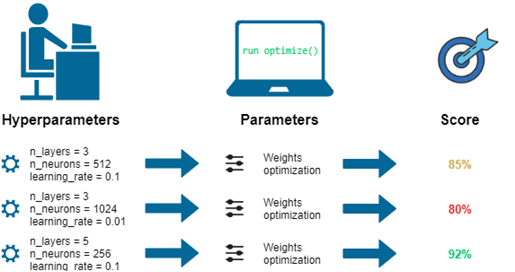
作出预测 (Make Predictions)
The final step after making the adjustments on the model is to make predictions using actual data that will be used on this model. If the model does not perform well on this further hyperparameter tuning can commence.
对模型进行调整后的最后一步是使用将在该模型上使用的实际数据进行预测。 如果模型在此上表现不佳,则可以开始进一步的超参数调整。
Machine Learning is a rather iterative and empirical process and thus the tuning of hyperparameters is often compared to an art rather than science as although we have an idea of what changes will happen by changing certain hyperparameters, we cannot be certain of it.
机器学习是一个反复的,经验性的过程,因此,通常将超参数的调整与艺术而不是科学进行比较,尽管我们已经知道通过更改某些超参数会发生什么变化,但我们无法确定。
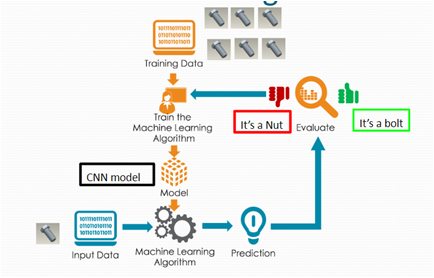
应用领域 (Applications)
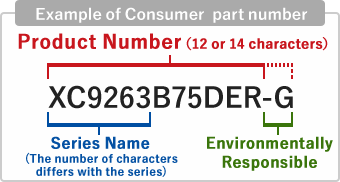
This ability to classify mechanical parts could enable us to recommend parts from a standard library based only on an image or a CAD model provided by the customer. Currently to search for a required part from a standard library you have to go through a catalogue and be able to tell which part you want based on the available options and your knowledge of the catalogue. There are serial codes to remember as a change in a single digit or alphabet might mean a different type of part.
对机械零件进行分类的能力使我们能够仅根据客户提供的图像或CAD模型从标准库中推荐零件。 当前,要从标准库中搜索所需零件,您必须遍历目录,并能够根据可用选项和对目录的了解来确定需要哪个零件。 需要记住一些序列号,因为一位数字或字母的更改可能意味着零件的类型不同。
If an image can be used to get the required part from the standard library, all we will need to do is to make a rough CAD model of it and send it through our algorithm. The algorithm will decide which parts are best and help narrow down our search significantly.
如果可以使用图像从标准库中获取所需零件,则我们要做的就是为其制作一个粗略的CAD模型并通过我们的算法发送。 该算法将决定哪个部分是最好的,并有助于大大缩小搜索范围。
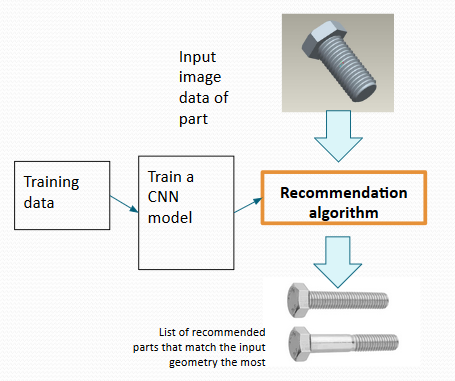
If the classification method gets detailed and fine-tuned enough it should be able to classify with much detail what type of part you want. The narrowed search saves a lot of time. This is especially useful in a library where there are thousands of similar parts.
如果分类方法足够详细并且进行了微调,它应该能够非常详细地分类所需的零件类型。 缩小搜索范围可节省大量时间。 这在包含成千上万个相似部分的库中特别有用。
结论 (Conclusion)
Deep Learning (Artificial Intelligence) is a field of study that has immense possibilities as it enables us to extract a lot of knowledge from raw data. At its core it is merely data analysis. In this age of the internet, data is everywhere and if we are able to extract it efficiently, a lot can be accomplished.
深度学习(人工智能)是一个研究领域,具有极大的可能性,因为它使我们能够从原始数据中提取很多知识。 其核心只是数据分析。 在这个互联网时代,数据无处不在,如果我们能够有效地提取数据,那么可以完成很多工作。
This field has a lot of possible applications in the domain of Mechanical Engineering as well. Since almost all studies in Deep Learning need a domain expert it would be advisable for all engineers with interest in Data Analytics, even though they haven’t majored in Computer Sciences, to learn about data science, machine learning and examine its possibilities. The knowledge of the domain plus the skills of data analysis will really help us excel in our own fields.
该领域在机械工程领域也有很多可能的应用。 由于几乎所有深度学习研究都需要一名领域专家,因此,即使对数据分析感兴趣的所有工程师(即使他们没有主修计算机科学),也建议他们学习数据科学,机器学习并检查其可能性。 领域知识和数据分析技能将真正帮助我们在自己的领域中脱颖而出。
致谢 (Acknowledgements)
I am thankful to Pro-Mech Minds for letting me do this and specially to its data science team which includes Gopal Kisi, Bishesh Shakya and Series Chikanbanjar for their immense help with this project. Pro-Mech Minds & Engineering Services is one of the companies in Nepal working with both mechanical and IT solutions in engineering. This idea popped as an attempt to combine design engineering with Data Science. Last but not the least I would like to offer my special thanks to Saugat K.C. for acting as a mentor for our Data Science team.
我感谢Pro-Mech Minds让我做到这一点,尤其是感谢包括Gopal Kisi,Bishesh Shakya和Series Chikanbanjar在内的数据科学团队在此项目上的巨大帮助。 Pro-Mech思维与工程服务公司是尼泊尔从事工程机械和IT解决方案的公司之一。 这个想法突然出现,试图将设计工程与数据科学相结合。 最后但并非最不重要的一点,我要特别感谢Saugat KC担任我们的数据科学团队的导师。

翻译自: https://towardsdatascience.com/artificial-intelligence-in-mechanical-engineering-a9dd94adc492
机械工程人工智能















 8122
8122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









