






 本文介绍了如何在AWS上搭建深度学习环境,并强调了选择适合的GPU对于高效运行深度学习算法的重要性,参考了来自towardsdatascience的文章。
本文介绍了如何在AWS上搭建深度学习环境,并强调了选择适合的GPU对于高效运行深度学习算法的重要性,参考了来自towardsdatascience的文章。
aws搭建深度学习gpu
A decade ago, if you wanted access to a GPU to accelerate your data processing or scientific simulation code, you’d either have to get hold of a PC gamer or contact your friendly neighborhood supercomputing center. Today, you can log on to your AWS console and choose from a range of GPU based Amazon EC2 instances.
十年前,如果您想使用GPU来加速数据处理或科学模拟代码,则要么必须拥有PC游戏玩家,要么要与您友好的邻里超级计算中心联系。 今天,您可以登录到AWS控制台,并从一系列基于GPU的Amazon EC2实例中进行选择。
You can launch GPU instances with different GPU memory sizes (8 GB, 16 GB, 32 GB), NVIDIA GPU architectures (Turing, Volta, Maxwell, Kepler) different capabilities (FP64, FP32, FP16, INT8, TensorCores, NVLink) and number of GPUs per instance (1, 2, 4, 8, 16). You can also select instances with different numbers of vCPUs, system memory and network bandwidth and add a range of storage options (object storage, network file systems, block storage, etc.).
您可以启动具有不同GPU内存大小(8 GB,16 GB,32 GB),NVIDIA GPU架构(Turing,Volta,Maxwell,Kepler)不同功能(FP64,FP32,FP16,INT8,TensorCores,NVLink)和数量的GPU实例每个实例(1、2、4、8、16)个GPU的数量。 您还可以选择具有不同数量的vCPU,系统内存和网络带宽的实例,并添加一系列存储选项(对象存储,网络文件系统,块存储等)。
Options are always a good thing, provided you know what to choose when. My goal in writing this article is to provide you with some guidance on how you can choose the right GPU instance on AWS for your deep learning projects. I’ll discuss key features and benefits of various EC2 GPU instances, and workloads that are best suited for each instance type and size. If you’re new to AWS, or new to GPUs, or new to deep learning, my hope is that you’ll find the information you need to make the right choice for your projects.
只要您知道什么时候选择,选择总是一件好事。 我写本文的目的是为您提供一些指导,说明如何在AWS上为您的深度学习项目选择正确的GPU实例。 我将讨论各种EC2 GPU实例的关键功能和优势,以及最适合每种实例类型和大小的工作负载。 如果您是AWS的新手,GPU的新手或深度学习的新手,我希望您能找到所需的信息,以便为您的项目做出正确的选择。
为什么您应该选择正确的GPU实例,而不仅仅是正确的GPU (Why you should choose the right GPU instance, not just the right GPU)
A GPU is the workhorse of a deep learning system, but the best deep learning system is more than just a GPU. You have to choose the right amount of compute power (CPUs, GPUs), storage, networking bandwidth and optimized software that can maximize utilization of all available resources.
GPU是深度学习系统的主力军,但最好的深度学习系统不仅仅是GPU。 您必须选择适当数量的计算能力(CPU,GPU),存储,网络带宽和优化的软件,以最大程度地利用所有可用资源。
Some deep learning models need higher system memory or a more powerful CPU for data pre-processing, others may run fine with fewer CPU cores and lower system memory. This is why you’ll see many Amazon EC2 GPU instances options, some with the same GPU type but different CPU, storage and networking options.
一些深度学习模型需要更高的系统内存或更强大的CPU来进行数据预处理,而其他一些深度学习模型可能需要更少的CPU内核和更低的系统内存才能正常运行。 这就是为什么您会看到许多Amazon EC2 GPU实例选项的原因,有些选项具有相同的GPU类型,但CPU,存储和网络选项不同。
If you’re new to AWS or new to deep learning on AWS, making this choice can feel overwhelming, but you are here now, and I’m going to guide you through the process.
如果您是AWS的新手或AWS深度学习的新手,那么做出这样的选择可能会让人感到不知所措,但是现在您来了,我将指导您完成整个过程。
On AWS, you have access to two families of GPU instances — the P family and the G family of EC2 instances. Different generations under P family (P3, P2) and G family (G4, G3) instances are based on different generations of GPUs architecture as shown below.
在AWS上,您可以访问两个GPU实例系列-P系列和G系列EC2实例。 P系列(P3,P2)和G系列(G4,G3)实例下的不同世代基于不同世代的GPU架构,如下所示。
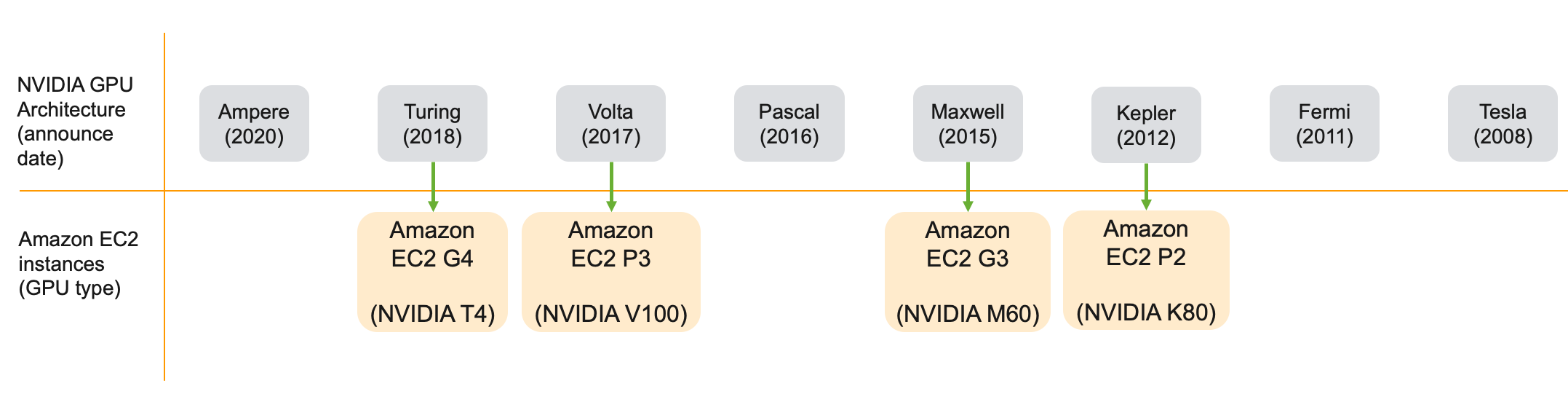
Each instance family (P and G), includes instance types (P2, P3, G3, G4), and each instance type includes instances with different sizes. Each instance size has a certain vCPU count, GPU memory, system memory, GPUs per instance, and network bandwidth. A full list of all available options is shown in the diagram below.
每个实例族(P和G)都包括实例类型(P2,P3,G3,G4),并且每个实例类型都包括具有不同大小的实例。 每个实例大小都有一定的vCPU数量,GPU内存,系统内存,每个实例的GPU和网络带宽。 下图显示了所有可用选项的完整列表。
Now let’s take a look at each of these instances by family, generation and sizes.
现在,让我们按族,代和大小来查看每个实例。
Amazon EC2 P3: 高性能深度学习培训的最佳实例 (Amazon EC2 P3: Best instance for high-performance deep learning training)
P3 instances provide access to NVIDIA V100 GPUs based on NVIDIA Volta architecture and you can launch a single GPU per instance or multiple GPUs per instance (4 GPUs, 8 GPUs). A single GPU instance p3.2xlarge can be your daily driver for deep learning training. And the most capable instance p3dn.24xlarge gives you access to 8 x V100 with 32 GB GPU memory, 96 vCPUs, 100 Gbps networking throughput for record setting training performance.
P3实例提供对基于NVIDIA Volta架构的NVIDIA V100 GPU的访问,您可以为每个实例启动一个GPU或为每个实例启动多个GPU(4个GPU,8个GPU)。 单个GPU实例p3.2xlarge可以成为您进行深度学习培训的日常驱动程序。 最强大的实例p3dn.24xlarge使您可以访问具有32 GB GPU内存,96个vCPU,100 Gbps网络吞吐量的8 x V100,以提供创纪录的培训性能。
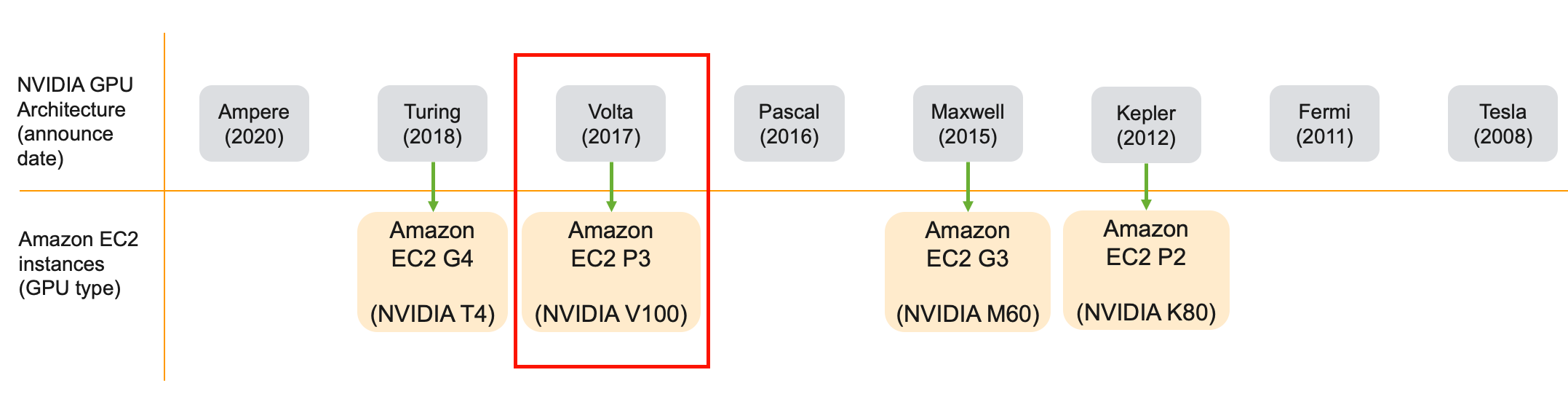
P3 instance features at a glance:
P3实例功能一目了然:
GPU Generation: NVIDIA Volta
GPU一代 :NVIDIA Volta
Supported precision types: FP64, FP32, FP16, Tensor Cores (mixed-precision)
支持的精度类型 :FP64,FP32,FP16,Tensor Core(混合精度)
GPU memory: 16 GB, 32 GB only on p3dn.24xlarge
GPU内存 :16 GB,仅p3dn.24xlarge上为32 GB
GPU interconnect: NVLink high-bandwidth interconnect, 2nd generation
GPU互连 :NVLink高带宽互连,第二代
The NVIDIA V100 includes special cores for deep learning called Tensor Cores to run mixed-precision training. Rather than training the model in single precision (FP32), your deep learning framework can use Tensor Cores to perform matrix multiplication in half-precision (FP16) and accumulate in single precision (FP32). This often requires updating your training scripts, but can lead to much higher training performance. Each framework handles this differently, so refer to your framework’s official guides (TensorFlow, PyTorch and MXNet) for using mixed-precision.
NVIDIA V100包含用于深度学习的特殊核心(称为Tensor核心)以运行混合精度培训。 您的深度学习框架无需使用单精度(FP32)训练模型,而可以使用Tensor Cores以半精度(FP16)执行矩阵乘法并以单精度(FP32)进行累加。 这通常需要更新您的训练脚本,但是可以带来更高的训练效果。 每个框架的处理方式都不相同,因此请参阅框架的官方指南( TensorFlow , PyTorch和MXNet )以使用混合精度。
P3 instances come in 4 different sizes: p3.2xlarge, p3.8xlarge, p3.16xlarge and p3dn.24xlarge.Let’s take a look at each of them.
P3实例有4种不同的大小: p3.2xlarge , p3.8xlarge , p3.16xlarge和p3dn。 24xlarge. 让我们看看它们中的每一个。
p3.2xlarge:用于单GPU训练的最佳GPU实例 (p3.2xlarge: Best GPU instance for single GPU training)
This should be your go-to instance for most of your deep learning training work. You get access to one NVIDIA V100 GPU with 16 GB GPU memory, 8 vCPUs, 61 GB system memory and up to 10 Gbps network bandwidth. V100 is the fastest GPU available in the cloud at the time of this writing and supports Tensor Cores that can further improve performance if your scripts can take advantage of mixed-precision training.
这应该是您大部分深度学习培训工作的首选实例。 您可以访问一个具有16 GB GPU内存,8个vCPU,61 GB系统内存和高达10 Gbps网络带宽的NVIDIA V100 GPU。 在撰写本文时,V100是云中可用的最快的GPU,并且支持Tensor Core,如果您的脚本可以利用混合精度培训,它们可以进一步提高性能。
You can provision this instance using Amazon EC2, Amazon SageMaker Notebook instances or submit a training job to an Amazon SageMaker managed instance using the SageMaker Python SDK. If you spin up an Amazon EC2 p3.2xlarge instance and run the nvidia-smi command you can see that the GPU on the instances is a V100-SXM2 version which supports NVLink (we’ll discuss this in the next section). Under Memory-Usage you’ll see that it has 16 GB GPU memory. If you need more than 16 GB of GPU memory for large models or large dat
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1355
1355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









