





语音通话视频通话前端
The views and opinions expressed in this blog are purely those of my own and do not reflect the official positions of my current or past employers.
本博客中表达的观点和观点纯属我个人观点,并不反映我现在或过去的雇主的正式立场。
This past weekend, I came across a news article that mentioned that millions of students in India are stuck at home with no access to either internet or online education. In fact, over half the world’s population still does not have any internet connection. While this digital divide has manifested itself in the U.S., especially with regards to in children’s education during the Coronavirus pandemic lockdown, the problem is far worse in Asia and Africa where fewer than 1 in 5 people are connected to the internet.
Ť他过去的周末,我碰到的是提到,新闻报道在印度数以百万计的学生被困在家里,没有获得任何一种互联网或网络教育 。 实际上,世界上超过一半的人口仍然没有任何互联网连接。 尽管这种数字鸿沟已在美国表现出来,特别是在冠状病毒大流行封锁期间的儿童教育方面 , 但在亚洲和非洲,只有不到五分之一的人与互联网相连 , 这一问题更加严重。
As a result of lockdowns being implemented globally, many adults and children are excluded from online education and telehealth.
由于在全球范围内实施了封锁措施,许多成人和儿童无法参加在线教育和远程医疗。
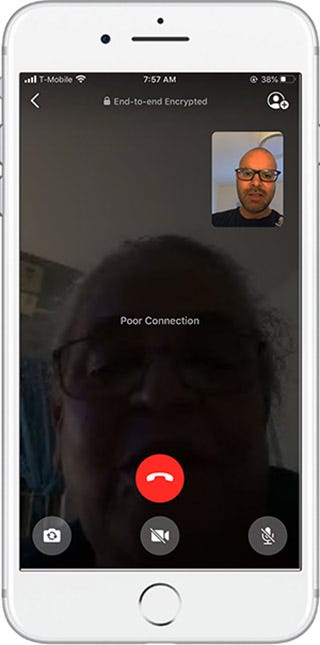
Despite the 1 in 5 statistic mentioned above, the problem in fact, is actually worse. For even those who have access to the internet, the price is premium and the bandwidth limited. For instance, while talking to my parents in India, they frequently run out of their allocated 4 GB far before the allowance period, after which the bandwidth gets throttled: Stalled frames, choppy audio, painful delays, and eventual disconnections, and subsequent retries are a normal occurrence, but still arguably much better than normal telephone conversations because I get to “see” them.
尽管上面提到的统计数字是五分之一,但实际上问题实际上更为严重。 即使对于那些可以访问互联网的人,价格也很高,而且带宽有限。 例如,在与我在印度的父母交谈时,他们经常在分配许可期限之前很长时间就耗尽了分配的4 GB带宽,之后带宽受到限制: 帧停滞,音频断断续续,痛苦的延迟,最终断开连接,以及随后的重试这是正常的情况,但可以说仍然比普通的电话交谈要好得多,因为我可以“看到”它们。
I understand when Andrew Stuart explains that video calling is better for the mental health¹ of people. But, video calls typically require 2 Mbps up and 2 Mbps down as in the case of Zoom, a privilege many cannot avail.
我了解安德鲁·斯图尔特(Andrew Stuart) 解释说视频通话对人们的心理健康¹更好。 但是, 与Zoom一样 , 视频通话通常需要2 Mbps的上行速度和2 Mbps的下行速度 ,许多人无法获得这种特权。
To address this problem, I propose a new approach based on the insight that if we are willing to give up some realism or realistic rendering of faces and screens, then there is whole new world of face and screen representations that can be derived for ultra-low bandwidth, with an acceptable quality of experience.
为了解决这个问题,我基于一种见解提出了一种新的方法,即如果我们愿意放弃面部和屏幕的某种真实感或逼真的渲染,那么就可以得到全新的面部和屏幕表示的新世界。低带宽,并具有可接受的体验质量。
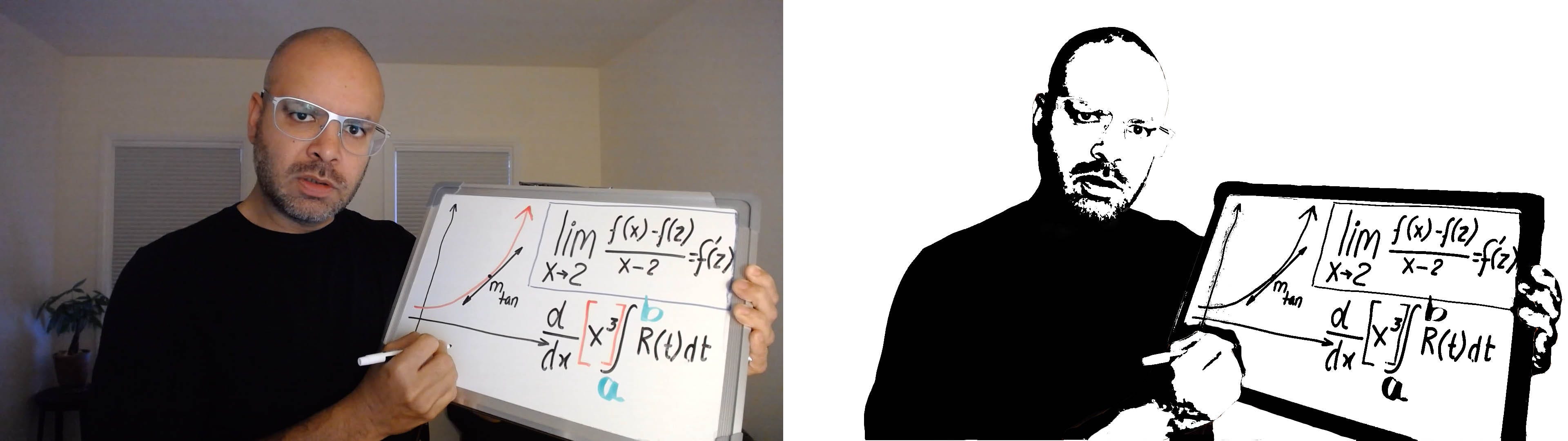
This article explores such representations and methods that reduce needed bandwidth from the normal 2 Mbps to as low as 1.5 Kbps, allowing video to be encoded along with telephone audio with minimal degradation in audio quality. The proposed solution can be primarily implemented as software needing no change in the underlying infrastructure. This would in turn be cheaper, and allow internet access to people that are currently being marginalized based on their affordability.
本文探讨了将所需带宽从正常的2 Mbps降低到低至1.5 Kbps的这种表示形式和方法,从而使视频与电话音频一起被编码,而音频质量的下降最小。 所提出的解决方案可以主要实现为无需更改基础架构的软件。 反过来,这将更便宜,并允许基于他们的负担能力使当前被边缘化的人们访问互联网。
蜂窝电话与互联网 (Cellular Telephone vs Internet)
You can skip this section if you are convinced that cellular telephone calls are more reliable, faster, and better than VoIP calls
如果您确信蜂窝电话呼叫比VoIP呼叫更可靠,更快和更好,则可以跳过本节
From anecdotal experience, it is clear that a cellular telephone call is often more reliable than a video call in many attributes such as delays, dropped calls, ease of use, minimal variation in call quality and long distance options.
从轶事经验来看,很明显,蜂窝电话在许多属性(例如延迟,掉线,易用性,通话质量的最小变化和长途选择)中通常比视频电话更可靠。
Video-call providers such as Google Meet, Discord, Gotomeeting, Amazon Chime, and potentially Facebook use a protocol called WebRTC that enables real-time communication between two or more parties. WebRTC also relies on an internet protocol called User Datagram Protocol, which offers speedy delivery of packets, but provides poor guarantees resulting in some packets to either not arrive or arrive out of order, thereby resulting in lost frames and jitter (a variation in the latency of a packet flow between peers)². Newer Machine Learning techniques such as using WaveNetEq³ in Google Duo improves the audio quality, however video quality variations remain unsolved.
诸如Google Meet,Discord,Gotomeeting,Amazon Chime和可能的Facebook之类的视频通话提供商使用称为WebRTC的协议,该协议支持两个或多个参与者之间的实时通信。 WebRTC还依赖于称为“用户数据报协议”的互联网协议,该协议可快速传送数据包,但提供的保证很差,导致某些数据包未到达或到达顺序混乱,从而导致帧丢失和抖动(延迟的变化)对等体之间的数据包流的数量)²。 较新的机器学习技术,例如在Google Duo中使用WaveNetEq³,可以改善音频质量,但是视频质量变化仍未解决。
On the other hand, while cellular telephone calls are also increasingly based on packets, engineers have found ways of making packet-switching cellphone networks increasingly efficient by constantly ensuring stringent quality standards and clever bandwidth management. Another reason why cellular calls work well is that the bandwidth needed for audio is much lower compared to that for video. Further, the encoding standards have been developed over many decades allowing the human brain to fill in gaps. I will eventually argue that many of the goals of internet-video calling such as two-way video calling, multi-party video broadcasts and live events, screen sharing, A/B testing of Quality of Experience (QoE)⁷ are also possible over cellular telephone calls. However, in the rest of this article, we shall only focus on two-way video call to set the stage.
另一方面,尽管蜂窝电话呼叫也越来越多地基于分组,但工程师们发现了通过不断确保严格的质量标准和聪明的带宽管理来使分组交换手机网络越来越高效的方法。 蜂窝电话运行良好的另一个原因是,与视频相比,音频所需的带宽要低得多。 此外,编码标准已经发展了数十年,允许人脑填补空白。 我最终将辩称,互联网视频通话的许多目标,例如双向视频通话,多方视频广播和现场活动,屏幕共享,体验质量(QoE)⁷的A / B测试,都可以通过蜂窝电话。 但是,在本文的其余部分中,我们将仅着眼于双向视频通话来奠定基础。
体系结构:电话视频 (Architecture: Video Over Telephone)
The primary goal in an educational video is to obtain the minimum video representation prioritizing information transfer (e.g.,whiteboard, sketches), followed by human actions (e.g., pointing, writing) and expressions (e.g., lips, eyebrows), while excluding distracting elements such as background, non-expressive elements of a face, as well as annoying video call elements such as freeze frames, variable frame rates, etc. Another architectural goal is to prioritize reliable frame rate with low latency and low jitter (smooth and consistent), as well as high audio quality.
教育视频的主要目标是获得最小的视频表示,优先考虑信息传递(例如,白板,草图),其次是人为动作(例如,指向,书写)和表情(例如,嘴唇,眉毛), 同时排除干扰因素例如背景,人脸的非表达元素,以及令人讨厌的视频通话元素,例如定格,可变帧频等。 另一个架构目标是优先考虑具有低延迟和低抖动(平滑且一致)的可靠帧频,以及高音质。
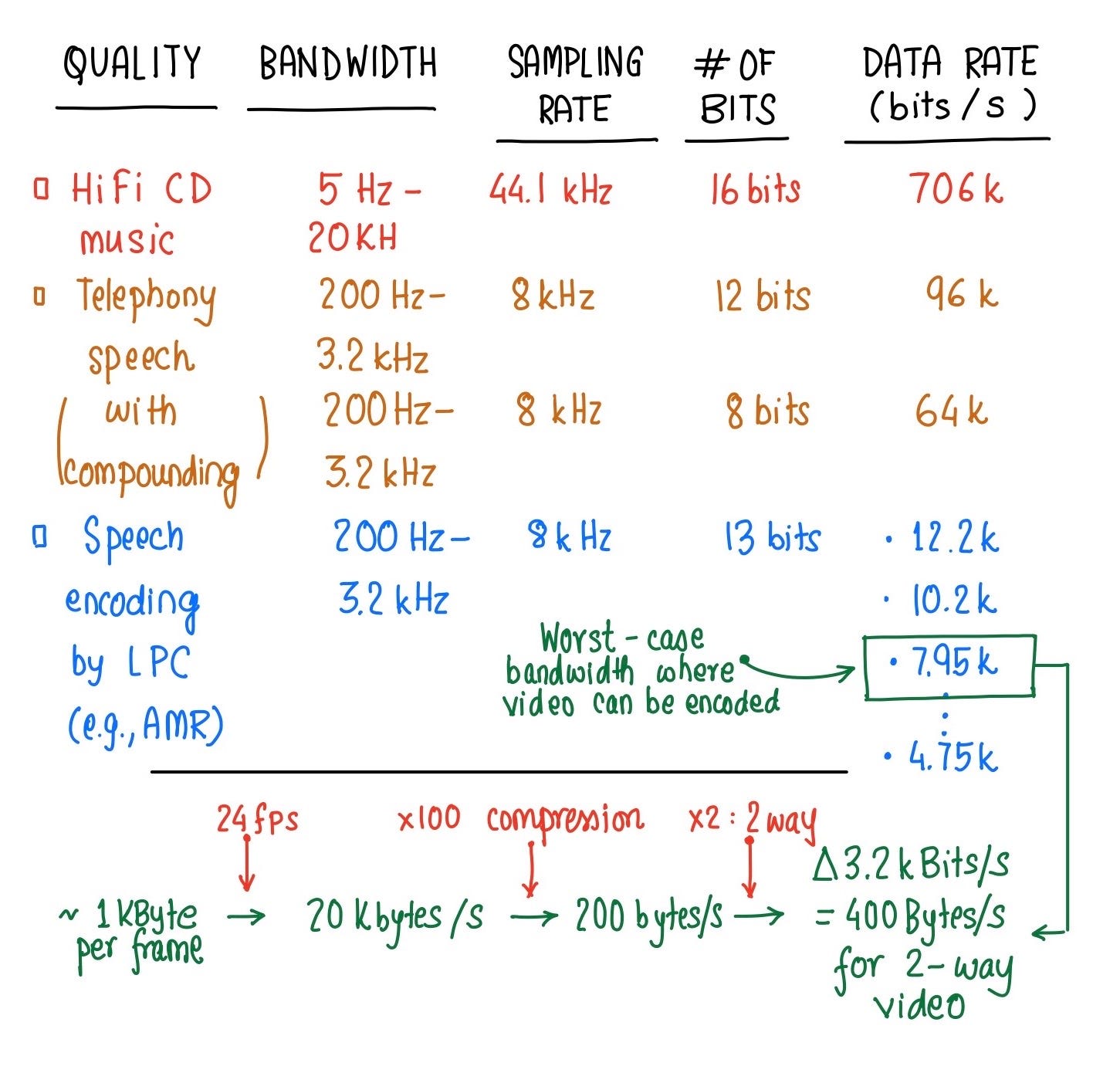
In any telephone call, the human tolerance for delay is at most 200 ms. For telephone calls, all packets do not matter as the encoding schemes are so sophisticated that even if some packets are lost, the caller can still be heard. The sophisticated schemes can handle multiple rates of transmission that adaptively adjust based on available bandwidth. As a result, Adaptive Multi-rate Codec (AMR) is popular. AMR codec uses eight source codecs with bit-rates of 12.2, 10.2, 7.95, 7.40, 6.70, 5.90, 5.15 and 4.75 Kbps. For our analysis, we picked 7.95 Kbps as our worst case analysis. Assuming a frame rate of 24 frames per second and a video compression ratio of 100 (H.264 lossy video compression can be as high as 200), we get a target of approximately 1 KB/frame uncompressed as a back-of-envelope calculation. This would assume a 7.5 kbps audio transmission rate, out of which 3.2 kbps is allocated to 2-way video transmission and 4.75 kbps for audio transmission. If we were to meet this worst-case design target, we can surely do better.
在任何电话呼叫中,人为的延迟容忍度最多为200毫秒。 对于电话呼叫,所有数据包都无关紧要,因为编码方案非常复杂,即使丢失了某些数据包,仍可以听到呼叫者的声音。 复杂的方案可以处理多种传输速率,这些速率可以根据可用带宽进行自适应调整。 结果, 自适应多速率编解码器 (AMR)很流行。 AMR编解码器使用八种源编解码器,其比特率分别为12.2、10.2、7.95、7.40、6.70、5.90、5.15和4.75 Kbps。 对于我们的分析,我们选择7.95 Kbps作为最坏情况分析。 假设每秒24帧的帧速率和100的视频压缩率(H.264有损视频压缩可能高达200), 我们得出的目标约为1 KB /帧未压缩,作为信封的背面计算。 这将假定音频传输率为7.5 kbps,其中将3.2 kbps分配给2路视频传输,将4.75 kbps分配给音频传输。 如果我们要达到最坏情况的设计目标,我们肯定可以做得更好。
视频截取 (Video Capture)
The first step is to capture video. For my prototype, I captured video at a frame size of 640x480 at 24 frames per second as this frequency is known to be good enough for deriving aesthetic film-like motion characteristics.
第一步是捕获视频。 对于我的原型,我以每秒24帧的速度捕获640x480帧大小的视频,因为已知该频率足以派生出类似电影的美学运动特性 。
逼真的视频表示 (Near-realistic Video Representations)
I experimented with different video formats but I decided to pursue the bi-level image (each pixel is either black or white) format using Simple Global Thresholding to obtain the video below. There are other usable bi-level thresholding techniques such as Adaptive Mean Thresholding and Adaptive Gaussian Thresholding, where the latter was less noisy but I like to defer advanced video processing until after segmentation because I thought it best to prioritize processing for certain regions (e.g. face, whiteboard) instead of global approaches. If neural computation is not possible on the sender’s side, then a simple global threshold might work.
我尝试了不同的视频格式,但我决定使用“ 简单全局阈值”追求双层图像(每个像素为黑色或白色)格式,以获取下面的视频。 还有其他可用的两级阈值处理技术,例如“自适应平均阈值”和“自适应高斯阈值”,后者的噪音较小,但我希望将高级视频处理推迟到分段之后进行,因为我认为最好优先处理某些区域(例如人脸) (白板),而不是全局方法。 如果发送方无法进行神经计算,则可能需要一个简单的全局阈值。
I also experimented with the ASCII rendering format as shown in the video below.
我还尝试了ASCII渲染格式,如下面的视频所示。
Additionally, I tried the Neural Style Transfer techniques using the example code provided here based on the paper⁶ and the Github code provided by Justin Johnson, Alexandre Alahi, Fei-Fei Li, but in the end I decided to pursue the bi-level images for wholly pragmatic reasons.
此外,我尝试了神经式转换使用所提供的示例代码技术, 这里基础上paper⁶和Github的代码提供贾斯汀·约翰逊 , 亚历山大Alahi , 斐翡丽 ,但最后我决定追求双级图像完全出于务实的原因。
视频语义分割 (Video Semantic Segmentation)
The core idea here is that we can use Deep Learning to segment and prioritize specific areas of a frame. In this case, I prioritized the following segments in decreasing order of priority: whiteboard, hands, face, torso, and background.
这里的核心思想是,我们可以使用深度学习对框架的特定区域进行细分并确定优先级。 在这种情况下,我按优先级从高到低的顺序划分了以下几部分:白板,手,脸,躯干和背景。


I am using Superannotate to annotate my videos and a combination of OpenCV and Da Vinci Resolve 16 to enhance the segmented video frames.
我正在使用Superannotate来注释我的视频,并使用OpenCV和Da Vinci Resolve 16的组合来增强分段的视频帧。
基于细分的视频增强 (Segment-based Video Enhancement)
The next step is to remove the background, followed by exposure, shadows, and contrast enhancement. However, the exact parameters are highly dependent on the lighting as well as the exposure, hence I developed some heuristics for my training samples.
下一步是移除背景,然后移除曝光,阴影和对比度增强。 但是,确切的参数在很大程度上取决于照明和曝光,因此我为训练样本开发了一些启发式方法。
Instead of multiple steps involving exposure, shadow and contrast enhancement, I decided to apply the heuristics of S-curve enhancement.
我决定不采用涉及曝光,阴影和对比度增强的多个步骤,而是决定采用S曲线增强的启发式方法。

In the tonal histogram for an RGB image, the lower-left quadrant represents the shadows while the upper-right quadrant represents the highlights. A simple heuristic could be to reducing the tones in the shadow regions by roughly around one standard deviation and increasing the tones in the highlight region around two standard deviations.
在RGB图像的色调直方图中,左下象限代表阴影,而右上象限代表高光。 一种简单的试探法是将阴影区域中的色调降低大约一个标准偏差,并在高光区域中将色调增加两个标准偏差附近。
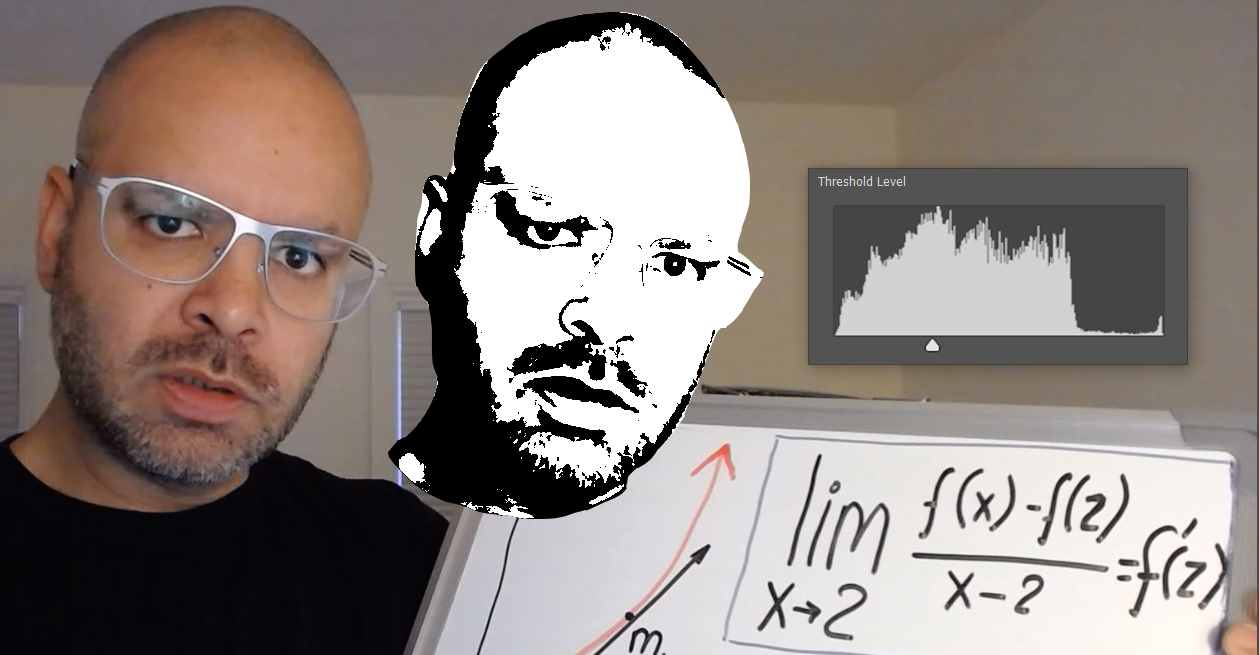
In setting the threshold for bi-level images, I applied the heuristic of setting it at the peak of the distribution. This heuristic seem to apply well at least for night lighting.
在设置双层图像的阈值时,我应用了在分布的峰值处设置阈值的试探法。 这种启发式方法似乎至少适用于夜间照明。
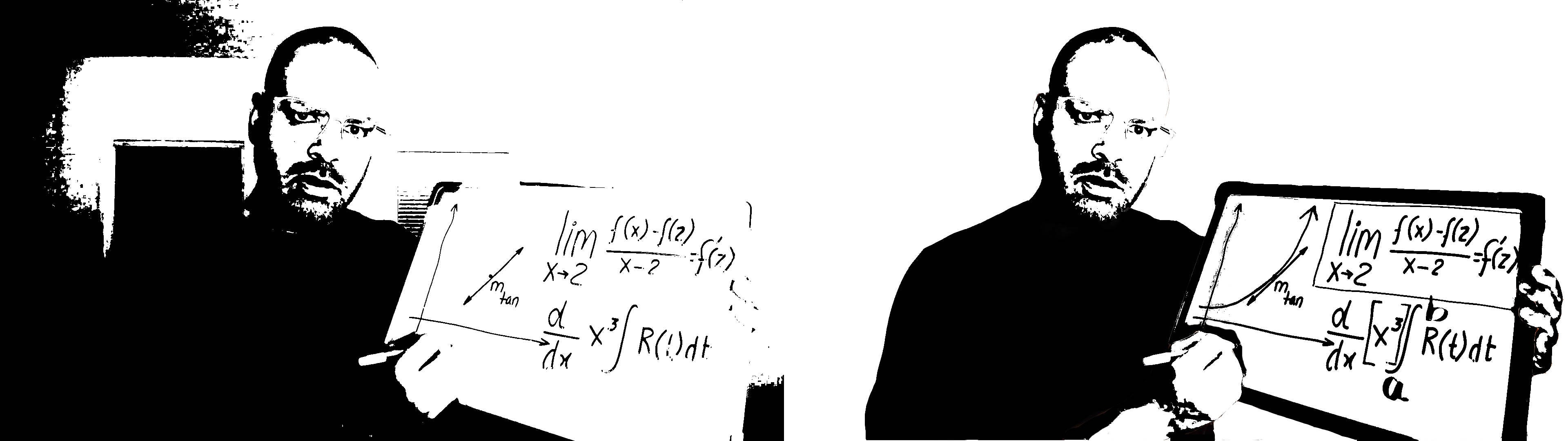
Overall, the localized video pre-processing based on segmented video frames provided a bi-level image with higher clarity.
总体而言,基于分段视频帧的本地化视频预处理提供了具有更高清晰度的双层图像。
向量化 (Vectorization)
The next step was to convert a bi-level pixelated image into a vector image. As vector-based images are not made up of a specific number of dots, they can not only be scaled to a larger size without losing any quality, but also reduce the footprint of the image significantly.
下一步是将双层像素化图像转换为矢量图像。 由于基于矢量的图像不是由特定数量的点组成,因此它们不仅可以缩放到更大的尺寸而不会损失任何质量,而且还可以大大减少图像的占地面积。


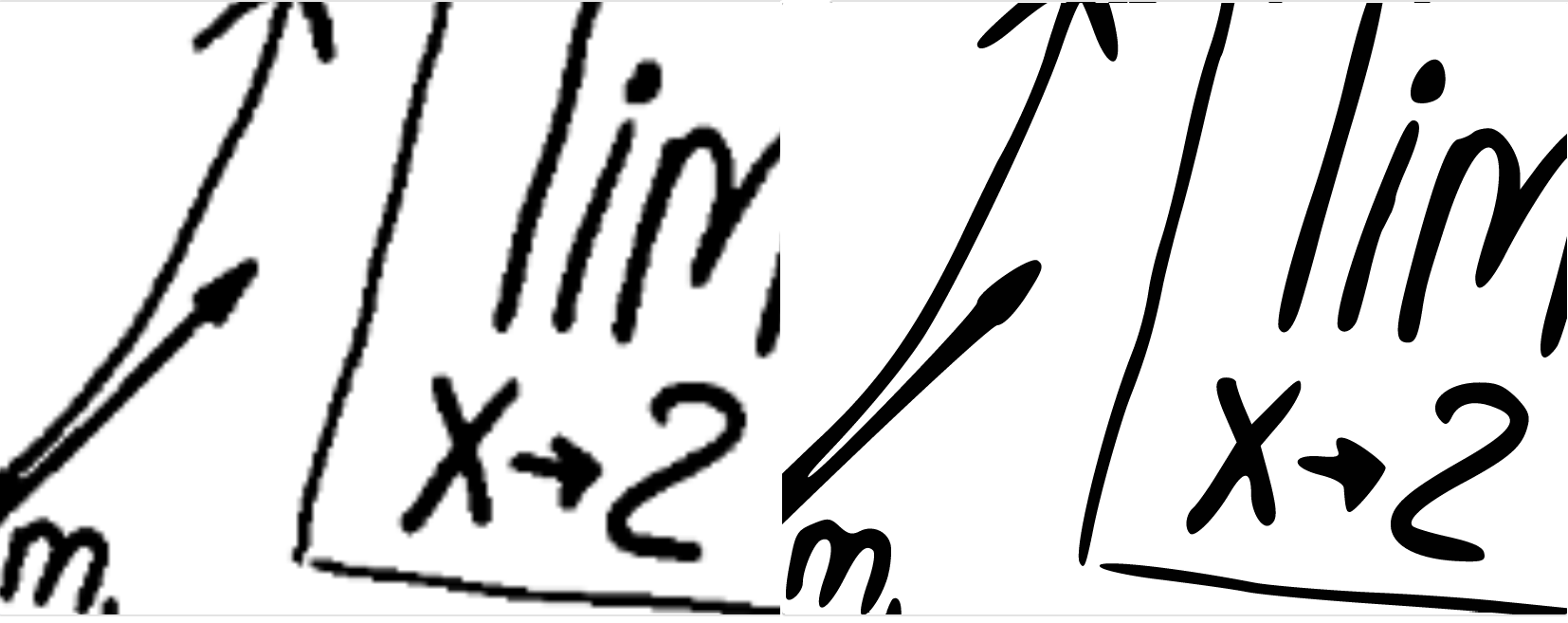
编码方式 (Encoding)
Encoding is necessary to compress data to fit the available bandwidth of communication as well as meet the delay requirements. Most video encoding standards are based on Discrete Cosine Transformation (DCT). Transformations such as the H.264 standard can compress videos by a factor of 200, but H.264 is not only quite compute heavy but also built for “natural” rendering. For this reason, I decided to explore video encoders optimized for our specific use. Compression technologies for videos include Spatial compression, which exploits redundancy within a single frame, and Temporal compression, which exploits redundancy such as motion redundancy between frames. Currently, I am experimenting with different encoding technologies to obtain a balance between Quality of Experience and compression. This investigation includes bi-level bitmap (pixel) based frames as well as vector based frames. Popular methods of compression for bi-level bitmap images include Run-length encoding, entropy encoding such as Arithmetic coding, as well as the JBIG2 standard for bi-level images. Following this, I shall investigate exploiting motion redundancy.
为了压缩数据以适合通信的可用带宽并满足延迟要求,必须进行编码。 大多数视频编码标准都基于离散余弦变换(DCT)。 诸如H.264标准之类的转换可以将视频压缩200倍,但是H.264不仅计算量大,而且还为“自然”渲染而构建。 因此,我决定探索针对我们的特定用途而优化的视频编码器。 视频的压缩技术包括:空间压缩(利用单个帧内的冗余)和时间压缩(利用帧之间的运动冗余)。 目前,我正在尝试不同的编码技术,以在体验质量和压缩之间取得平衡。 此研究包括基于双层位图(像素)的帧以及基于矢量的帧。 双层位图图像的流行压缩方法包括游程长度编码 ,诸如算术编码的熵编码以及双层图像的JBIG2标准。 此后,我将研究利用运动冗余。
解码和渲染 (Decoding and Rendering)
After decoding the compressed streaming video on the receiver end, one needs to render the video either on a smartphone or on a larger screen such as a TV. Vector representations are easy to scale and work well for representing whiteboard information, but they result in non-realistic rendering of faces, which for our purposes might work well. However, we need to test the Quality of Experience to confirm this. On the other hand, bitmap-based representations lead to pixelation when scaled. It should be noted that there are a few simple algorithms that can be applied to enhance those frames such as Nearest neighbor enhancement, Bi-cubic enhancement, sharpening, and removing of artifacts.
在接收端解码压缩的流视频后,需要在智能手机或更大的屏幕(例如电视)上呈现视频。 矢量表示很容易缩放,并且可以很好地表示白板信息,但是它们会导致不真实的面部渲染,对于我们的目的来说可能效果很好。 但是,我们需要测试体验质量以确认这一点。 另一方面,基于位图的表示在缩放时会导致像素化。 应当注意,有一些简单的算法可用于增强那些帧,例如最近邻增强,双三次增强,锐化和去除伪像。
In conclusion, I started with a 640 x 480 RGB image (~1 MB/frame) and transformed it to a bi-level image (~38 KB/frame). Vectorization futher reduced the frame size to about 10 KB/frame. While it is still further away than the 1 KB/frame worst-case target we discussed earlier, I believe there is a chance to meet that target. It is possible through the use of custom compression techniques that exploit redundancies such as having no background or through further opportunities in extreme vectorization such as having line drawings.
总之,我从640 x 480 RGB图像(〜1 MB /帧)开始,然后将其转换为双层图像(〜38 KB /帧)。 向量化进一步将帧大小减小到大约10 KB /帧。 虽然它仍然比我们之前讨论的1 KB /帧最坏情况目标还远,但我相信仍有机会实现该目标。 通过使用利用冗余的自定义压缩技术(例如没有背景)或通过极端矢量化的其他机会(例如具有线条图),这是可能的。
研究挑战和下一步 (Research challenges and next steps)
There are a number of approaches worth investigating based on available compute on either the sender or receiver ends, as well as the available communication bandwidth.
基于发送方或接收方端的可用计算以及可用的通信带宽,有许多方法值得研究。
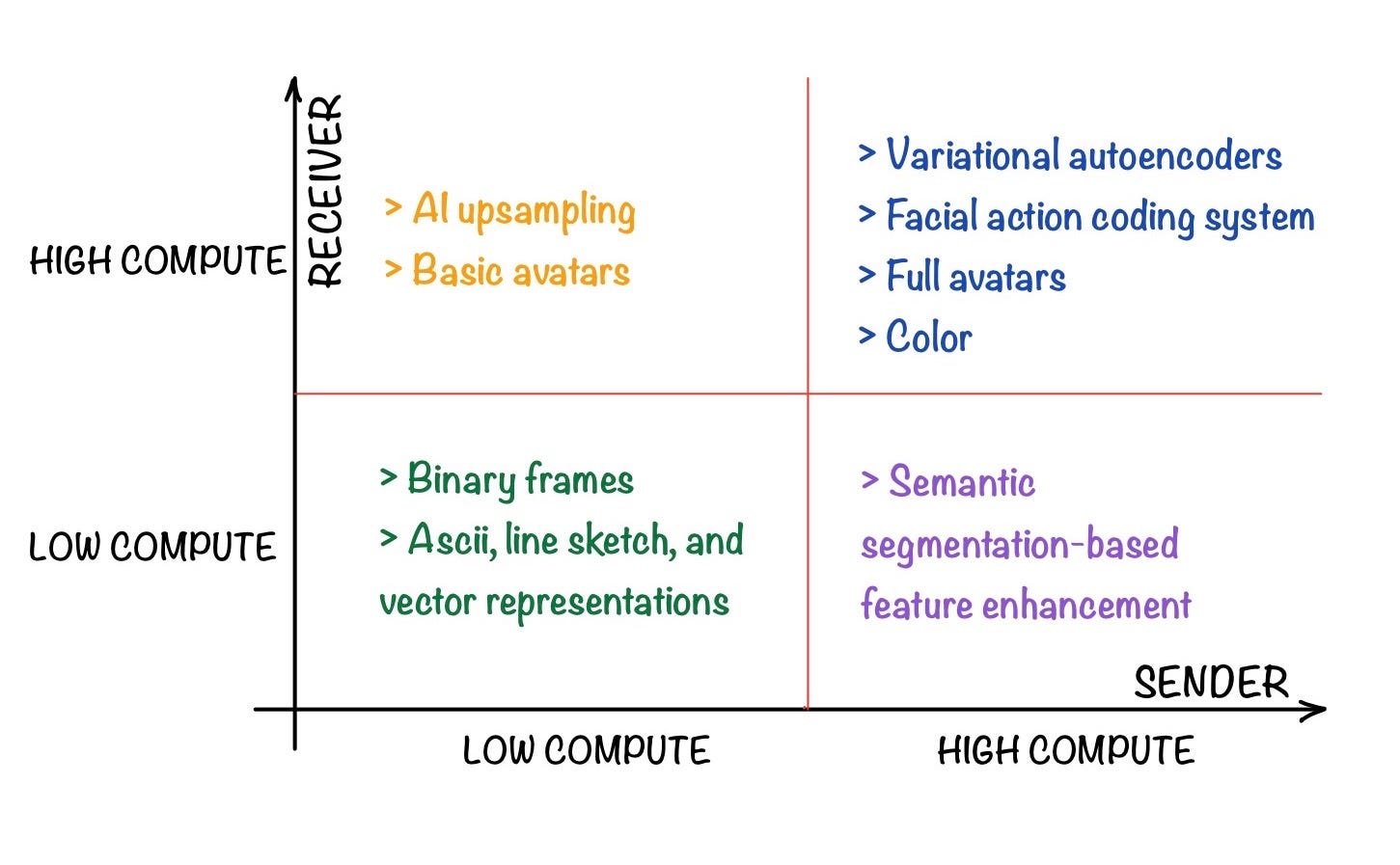
Video Optimizations
视频优化
Areas to investigate include optimizing video encodings around spatial frequencies for better interpretation of human actions⁴, and facial expressions such as Facial Action Coding Systems⁵.
要研究的领域包括优化围绕空间频率的视频编码以更好地解释人类行为⁴以及面部表情,例如面部动作编码系统⁵。
Novel representations
新颖的表象
Simple representations such as ASCII, 3D avatars, and other human-understandable representations are worth investigating. End-to-end AI-based approaches such as using variational autoencoders can be used to generate compact intermediate representations, though intermediate latent space encodings cannot be understood by humans. Of all approaches, I am most optimistic about variational encoders and related technologies. Another approach is the Facial Action Coding Systems (FACS), where an intermediate representation consists of Action Units (AUs) that control different muscles and movements. Such an FACS intermediate representation can actually encode a face and position in roughly 44 AUs, 3 for XYZ translation and 3 for angles resulting in 50 floats or 200 bytes per frame, which can be much lower after compression, almost certainly much lower than the target of 1 KB/frame. Such an encoding can be used to render an avatar on the receiver’s end. The latter two approaches would also need heavy compute on both the sender and the receiver side.
诸如ASCII,3D化身和其他人类可理解的表示之类的简单表示形式值得研究。 尽管人们无法理解中间潜伏空间编码,但是可以使用基于端到端基于AI的方法(例如使用变体自动编码器)来生成紧凑的中间表示。 在所有方法中,我对可变编码器和相关技术最为乐观。 另一种方法是面部动作编码系统 (FACS),其中中间表示由控制不同肌肉和动作的动作单元(AU)组成。 这种FACS中间表示实际上可以以大约44个AU编码人脸和位置,对于XYZ平移编码为3个,对于角度编码为3个,导致每帧50个浮点或200个字节,压缩后可以低得多,几乎可以肯定比目标低很多1 KB /帧 。 这样的编码可以用于在接收者的一端渲染化身。 后两种方法在发送方和接收方都需要大量计算。
Encoding alongside audio
音频编码
This is the biggest challenge in my opinion. There is a plethora of audio encoding standards such as Enhanced voice services, variable-rate multimode-wideband, mult-rate wideband, enhanced variable-rate codec, GSM enhanced full rate among others on either ends of the call. When a call is initiated from one carrier in one country and ends in another carrier in a different country, the quality of the streaming audio varies significantly depending on the encodings used as well as the quality of the connection. The challenge is to encode the video alongside the audio such that the video can be reliably decoded and will “survive” the transmission.
我认为这是最大的挑战。 在通话的两端,都有大量的音频编码标准,例如增强语音服务,可变速率多模宽带,多速率宽带,增强可变速率编解码器,GSM增强全速率。 当从一个国家/地区的一个运营商发起呼叫并在另一个国家/地区的另一运营商终止呼叫时,流音频的质量会根据所使用的编码以及连接质量而有很大不同。 面临的挑战是将视频与音频一起编码,以便可以对视频进行可靠的解码并“幸存”传输。
A framework for novel applications
新应用程序的框架
There are lots of novel applications possible such as interactive teaching methods using Vector-graphic animations or even minimalist augmented reality along with video and audio calls.
可能有许多新颖的应用程序,例如使用矢量图形动画的交互式教学方法,甚至是极简的增强现实以及视频和音频通话。
User: Build Android app as pilot.
用户:构建Android应用作为试点。
I would appreciate it if you provide some feedback, or pass this article on to someone or some company that might have the resources and talent to develop a complete solution and an Android app that can be deployed in developing countries for educational purposes. I have been working on this during the past weekend, and it is impractical for me to develop a solution quickly. I thank you in advance for your help!
如果您提供了一些反馈意见,或者将本文传递给可能有足够资源和才能开发完整解决方案的人或公司,以及可以在发展中国家用于教育目的而部署的Android应用,我将不胜感激。 在过去的一个周末中,我一直在进行此工作,因此,快速开发解决方案对我来说是不切实际的。 预先感谢您的帮助!
[1] Lauren E. Sherman; Minas Michikyan; Patricia M. Greenfield; The effects of text, audio, video, and in-person communication on bonding between friends. Cyberpsychology: Journal of Psychosocial Research on Cyberspace, 2013, 7(2), Article 3.
[1] Lauren E. Sherman; 米纳斯·米奇基扬(Minas Michikyan); 帕特里夏·格林菲尔德(Patricia M. 文本,音频,视频和面对面的交流对朋友之间联系的影响 。 网络心理学:网络空间心理社会研究杂志,2013,7 (2),第3条。
[2] García, B.; Gallego, M.; Gortázar, F.; Bertolino, A., Understanding and estimating quality of experience in WebRTC applications. Computing 2018, 101, 1–23.
[2]加西亚,B。 M. F.Gortázar; Bertolino,A., 了解和评估WebRTC应用程序的体验质量 。 计算2018,101,1–23。
[3] Pablo Barrera, Software Engineer, Google Research and Florian Stimberg, Research Engineer, DeepMind, Improving Audio Quality in Duo with WaveNetEQ, April 1, 2020, Google AI Blog.
[3]巴勃罗·巴雷拉,软件工程师,谷歌的研究和弗洛里安Stimberg,研究工程师,DeepMind, 提高音频质量的双核与WaveNetEQ ,2020年4月1日, 谷歌AI博客 。
[4] Steven M. Thurman Emily D. Grossman, Diagnostic spatial frequencies and human efficiency for discriminating actions, 2010 November 16, Springer, Attention, Perception and Pyschophysics.
[4]史蒂文·瑟曼(Steven M. Thurman)艾米莉·格罗斯曼(Emily D. Grossman), 《区分空间的诊断空间频率和人类效率》 ,2010年11月16日,施普林格,注意力,知觉和心理物理学。
[5] Paul Ekman, Facial action coding system, 1978.
[5] Paul Ekman,《 面部动作编码系统》 ,1978年。
[6] Justin Johnson, Alexandre Alahi, Li Fei-Fei, Perceptual Losses for Real-Time Style Transfer and Super-Resolution, 2016, European Conference of Computer Vision.
[6] 贾斯汀·约翰逊 , 亚历山大Alahi , 李飞飞 , 感知损失为实时式转换和超分辨率 ,2016年,计算机视觉的欧洲会议。
[7] Julie (Novak) Beckley, Andy Rhines, Jeffrey Wong, Matthew Wardrop, Toby Mao, Martin Tingley, Data Compression for Large-Scale Streaming Experimentation, Dec 2, 2019, Netflix Technology Blog.
[7] Julie(Novak)Beckley,Andy Rhines,Jeffrey Wong,Matthew Wardrop,Toby Mao,Martin Tingley, 大规模流实验的数据压缩 ,2019年12月2日,Netflix技术博客。
翻译自: https://towardsdatascience.com/video-calling-for-billions-without-internet-40d10069c464
语音通话视频通话前端

















 1808
1808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









