





智能机器人机器人心得
Eureka! As water sloshed over the side of the bath, the solution popped into Archimedes’ head. The problem he had been toiling at for days was finally solved. All the components of the solution slid neatly into place, a gift from his subconscious.
尤里卡! 当水从浴缸的侧面溢出时,溶液突然涌入阿基米德的头顶。 他辛苦工作了几天的问题终于解决了。 解决方案的所有组成部分都整齐地滑入到位,这是他下意识的礼物。
Anyone involved in creative work or problem solving will have experienced such eureka moments — a solution presenting itself in a flash of insight. In his latest book Novacene, James Lovelock offers his Gaia hypothesis as a potent example of this: Gaia is not easy to explain because it is a concept that arises by intuition from internally held and mostly unconscious information. Solutions obtained in this way can often be deconstructed into their component parts, but are not initially achievable with straightforward step-by-step reasoning. Too many things would have to be held in mind simultaneously. It is our ability to think in this non-linear way that makes our minds so powerful, ensuring that engineers and scientists will always find solutions more easily than a computer could. Put simply, there is no straightforward algorithm for creativity.
从事创造性工作或解决问题的任何人都将经历过这样的尤里卡时刻—一种能在洞察力中脱颖而出的解决方案。 詹姆斯·洛夫洛克(James Lovelock)在其最新著作《小说》中指出了盖亚(Gaia)假说,以此作为一个有力的例子: 盖亚(Gaia)难以解释,因为它是一种凭直觉产生于内部持有且几乎无意识的信息的概念 。 以这种方式获得的解决方案通常可以分解为它们的组成部分,但是最初不能通过简单的逐步推理来实现。 同时必须记住太多事情。 我们以这种非线性方式思考的能力使我们的思维变得如此强大,从而确保工程师和科学家总是比计算机更容易找到解决方案。 简而言之,没有简单的创造力算法。
But, with the ongoing revolution in artificial intelligence, this is starting to change. We are finally working out how to get our computers to find non-linear solutions. With access to big datasets and enough computing power, many of the problems that were always difficult for computers — natural language processing and image recognition for example — are starting to be solved through the application of machine learning. There has been particular success in the use of Deep Neural Networks (DNNs), which can surpass human performance in many well defined tasks. Notably defeating the world Go champion in 2015, a feat many experts in computer science thought was still many tens of years away.
但是,随着人工智能的不断革命,这种情况开始改变。 我们最终正在研究如何使我们的计算机找到非线性解决方案。 通过访问大型数据集和足够的计算能力,许多对计算机而言始终是困难的问题(例如自然语言处理和图像识别)已开始通过应用机器学习来解决。 深度神经网络(DNN)的使用取得了特别的成功,它可以在许多定义明确的任务中超过人类的表现。 值得注意的是,在2015年击败了世界围棋大赛冠军之后,许多计算机科学专家的壮举仍遥遥无期。
深度神经网络的简要介绍 (A very brief introduction to Deep Neural Networks)
DNNs were originally conceived as an algorithmic emulation of the human brain in the 1940s, but they did not show their full potential until their voracious appetite for data and computing power could be fulfilled. Their power is encompassed by the fact that they can act as universal function approximators — a perfectly trained and large enough DNN can find all potential insights from any input. But, despite their long history, there is no precise theory of how they learn, so no one really knows why they work as well as they do. This means there are no prescriptive rules detailing how to structure a network for a specific task. Instead, it must be worked out through experimentation. One of the major breakthroughs from such exploration was a simple but crucial one — the networks went from being shallow to deep.
DNN最初在1940年代被认为是人脑的算法仿真,但是直到能够满足人们对数据和计算能力的巨大需求时,DNN才显示出其全部潜力。 它们可以充当通用函数逼近器 ,因此具有强大的功能 -训练有素且足够大的DNN可以从任何输入中发现所有潜在的见解。 但是,尽管他们的历史悠久,却没有关于他们如何学习的精确理论,因此没有人真正知道他们为什么会如此出色地工作。 这意味着没有说明性规则详细说明如何为特定任务构建网络。 相反,必须通过实验来解决。 这种探索的主要突破之一是一个简单但至关重要的突破-网络从浅到深。

Neural networks are constructed from two basic components, nodes and the directional links between them — the combination of a node and its links being analogous to a biological neuron. Each node receives numerical inputs from other nodes further up the network. These inputs are summed and fed through a non-linear activation function. The result of this is then passed, via the links, to nodes further down the chain. As each link carries a signal from one node to another, the signal it carries is amplified or attenuated by the link’s weight. The key to training a network is choosing these weights in such a way as to get your desired output for a given input. An image recognition DNN, for example, takes as its initial input all the values of the pixels of an image. It then passes this through several layers of nodes and outputs a probability that the image was one of a particular predefined class.
神经网络由节点和它们之间的定向链接这两个基本组成部分构成-节点及其链接的组合类似于生物神经元。 每个节点都从网络上其他节点接收数字输入。 这些输入相加并通过非线性激活函数馈入。 然后,将其结果通过链接传递到更下游的节点。 当每条链路将信号从一个节点传送到另一节点时,它所承载的信号都会因链路的权重而放大或衰减。 训练网络的关键是选择这些权重,以便获得给定输入所需的输出。 例如,图像识别DNN将图像像素的所有值作为其初始输入。 然后,它通过多个节点层,并输出图像是特定预定义类别之一的概率。

The process of choosing these weights is known as training a network. The prevalent method for carrying out this training is with a large dataset of labelled data — inputs where you already know the correct output. This data is systematically passed through the network, which is asked for its outputs given a set of inputs. The outputs it produces are compared to the correct outputs through a loss function, which is defined to be minimal when the network always makes the correct prediction. Based on how wrong the network’s guess was, its weights are changed in such a way as to reduce the loss function’s value, through a process known as backpropagation.
选择这些权重的过程称为训练网络。 进行此训练的普遍方法是使用带有标签数据的大型数据集-输入,您已经知道正确的输出。 该数据系统地通过网络传递,并在给定一组输入的情况下要求其输出。 通过损失函数将其产生的输出与正确的输出进行比较, 损失函数在网络始终做出正确的预测时被定义为最小。 根据网络猜测的错误程度,可以通过称为反向传播的过程来更改其权重,以降低损失函数的值。
The paradigm of minimising a loss function is a powerful one, it allows neural networks to do much more than find patterns in large datasets. A loss function is really just another way of expressing a utility function, a concept familiar across science, mathematics and philosophy. As any rational and goal-driven behaviour can be formulated in the form of utility maximisation, there is no theoretical limit to what neural networks could do. The difficulty comes in choosing the appropriate loss function and finding the appropriate network structure.
最小化损失函数的范例是一种强大的范例,它允许神经网络做更多的事情,而不是在大型数据集中查找模式。 损失函数实际上只是表达效用函数的另一种方式,这是在科学,数学和哲学中都熟悉的概念。 由于任何理性的和目标驱动的行为都可以用效用最大化的形式来表述 ,因此神经网络的功能没有理论上的限制。 困难在于选择适当的损失函数并找到适当的网络结构。
This is where the depth of networks comes into play. It turns out that stacking layers of neurons on top of one another works much better than putting lots of neurons side-by-side in one giant layer. In this configuration, the network somehow learns to encode a hierarchy of abstraction in its layers. In the case of face detection, for example, the first network layers act as edge detectors, whereas the nodes in the final layers act as facial feature detectors, spotting the presence of eyes and noses. This structure emerges spontaneously in the training process and is eerily similar to the way we, as humans, seem to understand the world.
这就是网络深度发挥作用的地方。 事实证明,将神经元层相互堆叠起来比将许多神经元并排放置在一个巨型层中要好得多。 在这种配置中,网络以某种方式学会了在其层中对抽象层次进行编码。 例如,在人脸检测中,第一个网络层充当边缘检测器,而最后一层中的节点充当面部特征检测器,从而发现眼睛和鼻子。 这种结构是在训练过程中自发出现的,并且与我们人类一样理解世界的方式异常相似。
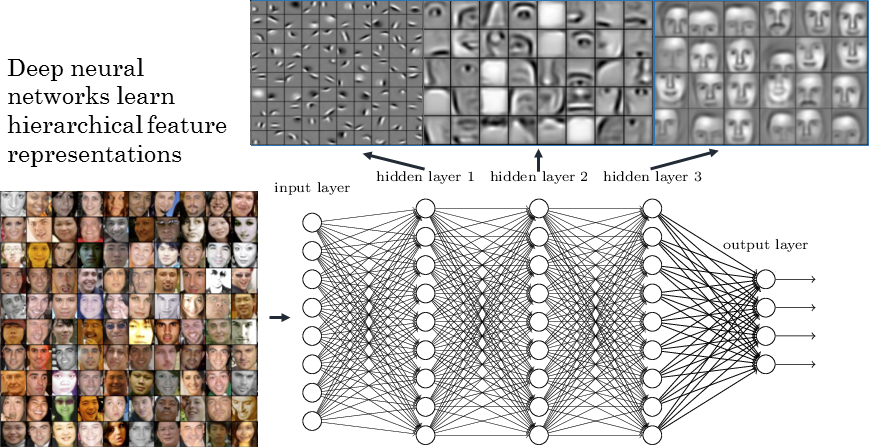
神经网络学习如何代表他们的世界 (Neural Networks learn how to represent their world)
The hierarchy of representations that DNNs build is both the key to their success and the core of their mystery. A typical DNN is structured to produce progressively more complex representations of its input with a neural architecture that is specific to the task at hand. The process of producing a specialised set of high level representations is known as encoding. These representations are finally combined with a couple of layers of simple logic to create the final output of the network, in a stage of simplified inference. In the case of image detection, the pixel values of an image are encoded into high level representations by many convolutional layers — a network architecture that works very well for image processing. The simplified inference is carried out by one or two unspecialised layers of neurons, which make use of the representations to decide which of the predefined image classes the input picture is most likely to belong to. In face detection, for example, the simplified inference stage will look to see if there is sufficient activation of the neurons that represent eyes and noses.
DNN构建的表示层次结构既是其成功的关键,也是其奥秘的核心。 典型的DNN的结构是通过特定于手头任务的神经体系结构逐步生成其输入的更复杂的表示形式。 产生一组专门的高级表示的过程称为编码 。 最后,在简化推论的阶段,将这些表示与几层简单的逻辑结合起来,以创建网络的最终输出。 在图像检测的情况下,图像的像素值被许多卷积层编码为高级表示形式-一种非常适合图像处理的网络体系结构。 简化的推理是由一层或两层非专门的神经元层执行的,它们利用这些表示来确定输入图片最可能属于哪个预定义图像类别。 例如,在人脸检测中,简化的推理阶段将着眼于表示眼睛和鼻子的神经元是否被充分激活。

Most of the heavy lifting of the DNN is carried out in the encoding layer. Learning good representations is what takes most of the time and computing power. This leads to one very nice property of DNNs — the same representations can be used for a wide variety of tasks. For example, the representations built by networks trained to classify images of a thousand different objects can be commandeered to match instagram influencers to brands based on their posts contents. The huge potential of DNNs for natural language processing also revolves around this concept. This is exhibited by BERT, Google’s powerful language encoder, which is trained to predict words removed from text.
DNN的大部分繁琐工作都在编码层中执行。 学习良好的表示方法需要花费大量时间和计算能力。 这导致了DNN的一个非常不错的特性-相同的表示形式可用于多种任务。 例如,可以训练由训练以对一千个不同对象的图像进行分类的网络构建的表示, 以根据他们的帖子内容将instagram影响者与品牌进行匹配。 DNN在自然语言处理方面的巨大潜力也围绕着这一概念。 这是由Google强大的语言编码器BERT展示的,它经过训练可以预测从文本中删除的单词。
The obvious advantage of reusable representations is that it allows researchers to build on the success of others, without costing them lots of computing power and data processing. This hugely accelerates the process of engineering state of the art DNNs for a wide variety of tasks. However, the implications of transferable representations go deeper than quality of life improvements for machine learning researchers.
可重用表示形式的明显优势在于,它使研究人员可以在他人的成功基础上发展,而无需花费很多计算能力和数据处理能力。 这极大地加速了各种任务的最新技术DNN的工程开发过程。 但是,对于机器学习研究人员而言,可转移表示形式的含义要比生活质量改善更为深刻。
Somehow, DNNs are able to learn to build complex and sophisticated representations of the world that have a universal utility. This has allowed DNNs to break new ground in computer science, but — as DNNs demonstrate their ability to learn fundamental natural truths from data by themselves — they are starting to revolutionise many other scientific fields as well. A recent application in material science, for example, sees DNNs predicting the properties of materials, a task that would have previously taken many years running a full algorithmic simulation on a supercomputer. In this case, DNNs are somehow able to learn the sophisticated and complex characteristics of various materials and build them into a set of easily interpretable representations. Such applications are popping up all over science, from DNNs finding mathematical proofs to understanding the cosmic structure of our universe. But, the blackbox nature of DNNs is starting to lead scientists to question how far they can be taken.
不知何故,DNN能够学习构建具有通用性的复杂复杂的世界表示。 这使DNN在计算机科学领域开辟了新的领域,但随着DNN展示出自己从数据中学习基本自然事实的能力,它们也开始革新许多其他科学领域。 例如,最近在材料科学中的一项应用使DNN能够预测材料的特性,这项任务以前需要花费很多年才能在超级计算机上运行完整的算法仿真。 在这种情况下,DNN能够以某种方式学习各种材料的复杂特性,并将其构建为一组易于解释的表示形式。 从DNN查找数学证明到理解我们宇宙的宇宙结构,此类应用正在整个科学领域中兴起。 但是,DNN的黑盒性质开始使科学家们质疑可以将它们带走多远。
可解释性危机 (A crisis of explainability)
The problem with getting a DNN to build a complex and sophisticated non-linear representations is that it becomes very difficult to understand which features of the data it is exploiting. We are comfortable thinking through a few logical steps, but not the thousands or even millions that are carried out at once by a DNN. This makes it almost impossible to explain the exact reason a network gave us a particular solution. It just seems to be able to get it right.
使用DNN构建复杂而复杂的非线性表示的问题在于,很难理解要利用的数据的哪些特征。 我们很乐意考虑一些逻辑步骤,而不是DNN一次执行的数千甚至数百万。 这几乎无法解释网络为我们提供特定解决方案的确切原因。 它似乎似乎能够解决问题。
One danger of this is that our networks start making decisions with undesirable patterns found in the data. They can, for example, learn about systemic racism when trying to predict which criminals are likely to reoffend. This is potentially very harmful, although can be corrected for with awareness of the problem and appropriate tuning of the training process. But, when our aim is to build up scientific theories from first principles, the lack of explainability presents an even stickier challenge. Can you really say you have understood a problem if a blackbox can get you the right solution, but you can’t explain the mechanism underneath?
这样做的危险之一是我们的网络开始使用数据中发现的不良模式进行决策。 他们可以,例如,了解全身种族主义试图预测犯罪分子很可能在再次犯罪 。 尽管可以通过了解问题并适当调整培训过程来纠正此问题,但这可能非常有害。 但是,当我们的目标是从第一条原则建立科学理论时,缺乏可解释性提出了更加艰巨的挑战。 如果黑匣子可以为您提供正确的解决方案,但您无法解释其背后的机制,您真的可以说您已经理解了一个问题吗?
This leaves us with a dilemma — the complex non-linearity of DNNs is what gives them their power, but also what makes them difficult to interpret. There will always be techniques to try to reconstruct some of the patterns that DNNs are making use of. But, if we want to model complex systems that have up to now escaped straightforward algorithmic approaches, maybe we have to accept we won’t be able to know all the details. In the next section I will argue that we actually accept this kind of thing all the time — in our eureka moments…
这给我们带来了一个难题:DNN的复杂非线性使其具有强大的功能,但又使它们难以解释。 总会有一些技术来尝试重建DNN正在使用的某些模式。 但是,如果我们要对迄今为止无法使用简单的算法方法的复杂系统进行建模,也许我们必须接受我们无法知道所有细节。 在下一节中,我将争辩说,在尤里卡时刻,我们实际上一直在接受这种事情……
毕竟我们的大脑是神经网络 (Our brains are neural networks, after all)
As discussed before on this blog, we humans also think with representations. This conveys many benefits when interpreting the world, from allowing us to communicate easily, to compressing the amount of information we have to store when we remember things. The higher level representations that our brains construct are so fundamental to the way we think that they comprise most of our conscious experience. When thinking in terms of images, we manipulate entire representations of objects. When thinking verbally we manipulate words that contain a huge amount of information in a few syllables. However, these representations come to us unconsciously — they act as a baseline of our experience that we are unaware of building.
如之前在此Blog上所讨论的 ,我们人类也使用表示法进行思考。 这在解释世界时带来了很多好处,从允许我们轻松地交流到压缩我们记住事情时必须存储的信息量。 我们的大脑构建的更高层次的表示对于我们认为的方式如此基础,以至于它们构成了我们大多数有意识的体验。 当考虑图像时,我们操纵对象的整个表示。 进行口头思考时,我们会在几个音节中操纵包含大量信息的单词。 但是,这些表示是在不知不觉中出现的,它们是我们不了解的经验的基准。
We can now immediately see the connection between the way we interpret the world and the way neural networks learn to interpret the world. We also have an encoding process — which is almost entirely unconscious — where we build high level representations. We then manipulate these representations with simple logic, as in the stage of simplified inference in DNNs. It is only this last stage that we are typically conscious of, allowing us to communicate a simplified version of our internal world to others, or think step by step through problems we want to solve. In the same way it is difficult to explain the depths of a neural network, we have difficulty explaining the deep workings of our subconscious brain.
现在,我们可以立即看到解释世界的方式与神经网络学习解释世界的方式之间的联系。 我们还有一个编码过程-几乎完全是无意识的-在其中构建高级表示。 然后,我们在DNN的简化推理阶段中使用简单的逻辑来操纵这些表示。 通常,我们只是意识到这最后一个阶段,使我们能够与他人交流内部世界的简化版本,或者逐步思考要解决的问题。 以同样的方式很难解释神经网络的深度,我们很难解释潜意识大脑的深层运作。
Could it be this that explains the appearance of our insights from outside our conscious awareness? To solve a sophisticated problem, our brain carries out reasoning that is too complex to have a consistent conscious experience of. Perhaps it does this by building new representations of the world, or even just manipulating so many variables simultaneously that they cannot be all held in consciousness?
难道这就是从我们有意识的意识之外解释了我们的见解的出现? 为了解决复杂的问题,我们的大脑进行的推理过于复杂,无法获得一致的意识体验。 也许这是通过建立新的世界表示方式来完成的,或者甚至只是同时操纵如此多的变量以至于无法将它们全部保持在意识中?
By allowing our artificial neural networks to train themselves, we are therefore giving the computers the gift of proto-creativity. It may therefore be impossible to hope to fully explain the inference power of the deepest and most powerful DNNs, any more than we can understand our own creative problem solving process.
通过允许我们的人工神经网络进行自我训练,我们为计算机赋予了原始创造力。 因此,可能无法完全解释最深,功能最强大的DNN的推理能力,这超出了我们理解自己的创造性问题解决过程的能力。
This is not to say that human brains are not hugely more powerful and sophisticated than your average neural network. This is evident in our ability to dig deeper and offer explanations of the representations we build. We can break down our mental representation of a dog into its individual components — ears, nose, fur — that led us to represent a particular object as a dog. But, here we are just drawing from the huge set of representations that we have available to us. A typical DNN has a much smaller set, specifically tailored to the task at hand. This idea could point us to methods for improving the explainability of neural networks. But, for now, I want to explore how these representations are arrived at in the first place, leading us to a strange and interesting conclusion…
这并不是说人的大脑没有比您的普通神经网络强大和复杂得多。 这在我们更深入地挖掘和提供对我们构建的表示形式的解释方面的能力中显而易见。 我们可以将我们对狗的心理表征分解为它的各个组成部分-耳朵,鼻子,皮毛-从而使我们将特定的物体表现为狗。 但是,在这里,我们只是从我们可以使用的大量表示中汲取灵感。 典型的DNN的集合要小得多,专门针对手头的任务量身定制。 这个想法可以为我们指出提高神经网络可解释性的方法。 但是,到目前为止,我想首先探讨这些表示形式是如何得出的,从而使我们得出一个奇怪而有趣的结论……
我们的现实由效用函数定义 (Our reality is defined by our utility function)
It is all very well stating that both we and our artificial neural networks make sense of the world through representations, but how is it that they are arrived at in the first place? There are infinite ways of clustering and combining input data, what is the guiding principle for deciding the best way to do it? For DNNs this is actually well known — it is decided by the utility function used to train the network.
很好地说明了我们和我们的人工神经网络都通过表示来理解世界,但是它们是如何首先到达的呢? 有无数种对输入数据进行聚类和组合的方法,确定最佳方法的指导原则是什么? 对于DNN,这实际上是众所周知的-它由用于训练网络的效用函数决定。
As already discussed, the neurons in the encoding layers of the network automatically organise themselves into useful representations. It is this fact that leads to the fundamental mystery and power of DNNs. Neural networks, therefore, learn to see the world in the way that is best suited for them to achieve the goal that they are trained for.
正如已经讨论过的,网络编码层中的神经元会自动将自己组织成有用的表示形式。 正是这一事实导致了DNN的基本奥秘和力量。 因此,神经网络将以最适合他们的方式来学习世界,以实现他们所要达到的目标。
This exact reasoning applies to how we represent the world. Our representations must be built in such a way as to maximise our ability to achieve our own goals, defined by some human-level utility function. If this conclusion is close to the truth it is of earth shattering importance. It is these representations that comprise our entire conscious understanding of the world. All of what we think of as reality is necessarily a mental representation of it.
这种确切的推理适用于我们如何代表世界。 我们的表示形式必须以最大化我们实现自己的目标的能力的方式构建,这是由一些人类层面的效用函数定义的。 如果这个结论接近事实,那将是毁灭地球的重要性。 这些表示构成了我们对世界的整个有意识的理解。 我们认为是现实的所有事物必然是它的一种心理表征。
This is exactly the idea Donald Hoffman presents in his Case Against Reality, explored from another angle before on this blog. We do not actually have a conscious experience of reality, just a conscious experience of our representations of it. There is therefore no guarantee that we experience a faithful reproduction of the real world. The one underlying assumption for this idea to work is that the utility function of humans is that defined by evolution. In other words, our representations of the world are those that maximise our ability to successfully reproduce and propagate.
这正是唐纳德•霍夫曼(Donald Hoffman)在他的“反对现实的案例”中提出的想法,该想法是在此博客之前从另一个角度探索的。 我们实际上没有对现实的有意识的体验,而只是对我们对现实表示的有意识的体验。 因此,不能保证我们会真实地再现真实世界。 这个想法起作用的一个基本假设是,人类的效用函数是由进化定义的。 换句话说,我们对世界的表示是使我们成功复制和传播的能力最大化的表示。
Compellingly, this conclusion is simultaneously being arrived at in the world of artificial intelligence research. Specifically in the field of reinforcement learning — where agents driven by neural networks are trained to interact in a world and complete predefined tasks. A recent paper from Google’s DeepMind found that agents learned better when allowed to construct a model of the world themselves, rather than when a model was explicitly provided for them. This is a counterintuitive result. You would usually expect that giving an agent lots of information about the world in which it was acting, via a predefined model, should allow it to learn more quickly. It wouldn’t have to spend time learning how to model the world and how to move in it, it would just have to learn how to move. However, the agent did much better when allowed to construct its own representations of the world, rather than trying to make sense of the ‘real’ world in which it found itself.
令人信服的是,这一结论在人工智能研究领域中同时出现。 特别是在强化学习领域,在该领域中,由神经网络驱动的代理经过训练,可以在世界范围内进行交互并完成预定义的任务。 谷歌的DeepMind公司最近发表的一篇论文发现,如果允许代理商自己构建世界模型,而不是为他们明确提供模型,他们就会学得更好。 这是违反直觉的结果。 您通常希望通过预定义的模型为业务代表提供有关其所处世界的大量信息,这应使其能够更快地学习。 它不必花时间学习如何建模世界以及如何在其中移动,而只需学习如何移动。 但是,如果允许其构造自己的世界表示,则代理会做得更好,而不是试图弄清它所处的“真实”世界。
It is true that reinforcement learning agents have a much more simplified task to complete than that of a thriving human being. It is also self-evident that we don’t explicitly act to maximise our evolutionary fitness. Instead we try to fulfil a series of proxy utility functions, which work together to have the net effect of increasing our fitness — we eat when we are hungry, find partners with which to start a family and so on. The exact structure of the utility function that humans use to make sense of the world for humans is therefore opaque. There are compelling ideas on offer, but a definitive answer has yet to emerge.
的确,与蓬勃发展的人类相比,强化学习代理要完成的任务要简单得多。 不言而喻,我们没有明确地采取行动来最大化我们的进化适应性。 取而代之的是,我们尝试实现一系列代理实用程序功能,这些功能可以共同发挥作用,从而提高我们的身体素质-饥饿时进食,寻找与之建立家庭的伙伴,等等。 因此,人类用来理解人类世界的效用函数的确切结构是不透明的。 有很多引人入胜的想法 ,但尚未给出明确的答案。
To make successful inferences in this complicated world we must have a pretty good representative model of it. But, we can’t escape from Hoffman’s theory — compellingly backed up by cutting edge AI research — that we may well be designed with irretrievably incomplete representations of the world around us. As humans, can we really ever hope to comprehend reality as it is? Maybe we can look to the way our machines are learning to start giving us insights into this most ancient of questions.
为了在这个复杂的世界中取得成功的推论,我们必须有一个很好的代表性模型。 但是,我们无法摆脱霍夫曼的理论(在尖端AI研究的支持下得到有力的支持),我们很可能在设计时就以对我们周围世界的不可挽回的不完整表示来设计。 作为人类,我们真的可以希望真正理解现实吗? 也许我们可以看看我们的机器学习的方式来开始让我们深入了解这个最古老的问题。
In any case, it is certain that there is much wisdom in the depths of our subconscious — we would do well to take full advantage of our eureka moments. As noted by Lovelock: the “A causes B” way of thinking is one-dimensional and linear whereas reality is multidimensional and non-linear. We are finally inventing the tools we need to explore and exploit this fact.
无论如何,可以肯定的是,我们的潜意识深处有很多智慧-我们会很好地利用我们的尤里卡时刻。 正如洛夫洛克所指出的那样: “ A导致B”的思维方式是一维的和线性的,而现实是多维的和非线性的 。 我们终于发明了探索和利用这一事实所需的工具。
This essay was originally published at https://pursuingreality.com . If you enjoyed the article you can find other articles and sign up to the mailing list there.
这篇文章最初发表在https://pursuingreality.com上 。 如果您喜欢该文章,则可以找到其他文章并在那里注册邮件列表。
翻译自: https://medium.com/@adam_80562/if-robots-spoke-of-god-5a6ea5fb4d1b
智能机器人机器人心得















 2204
2204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









