





python svm向量
介绍: (Introduction:)
The support vector machines algorithm is a supervised machine learning algorithm that can be used for both classification and regression. In this article, we will be discussing certain parameters concerning the support vector machines and try to understand this algorithm in detail.
支持向量机算法是一种可监督的机器学习算法,可用于分类和回归。 在本文中,我们将讨论与支持向量机有关的某些参数,并尝试详细了解该算法。
几何解释: (Geometrical Interpretation:)
For understanding, let us consider the SVM used for classification. The following figure shows the geometrical representation of the SVM classification.
为了理解,让我们考虑用于分类的SVM。 下图显示了SVM分类的几何表示。
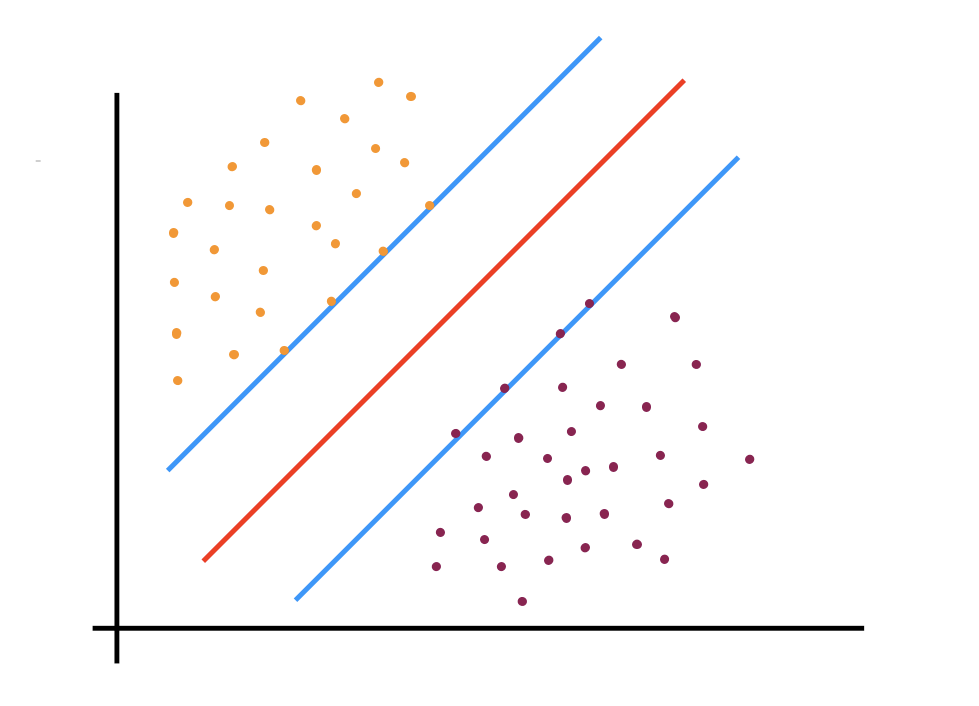
After taking a look at the above diagram you might notice that the SVM classifies the data a bit differently as compared to the other algorithms. Let us understand this figure in detail. The Red-colored line is called as the ‘hyperplane’. This is basically the line or the plane which linearly separates the data. Along with the hyperplane, two planes that are parallel to the hyperplane are created. While creating these two planes, we make sure that they pass through the points that are closest to the hyperplane. These points can be called as the nearest points. The hyperplane is adjusted in such a way that it lies exactly in the middle of the two parallel planes. The distance between these two planes is called the ‘margin’. The advantage of these two parallel planes is that it helps us to classify the two classes in a better way. Now a question arises that there can be multiple hyperplanes and out of them why did we select the one in the above diagram? The answer to that is we select the hyperplane for which the margin i.e the distance between the two parallel planes is maximum. The points that are on these two parallel planes are called support vectors. The above figure is obtained after training the data. Now for the classification of unknown data or the testing data, the algorithm will only take into consideration the reference of the support vectors for classification.
看了上面的图后,您可能会注意到SVM与其他算法相比对数据的分类有些不同。 让我们详细了解该图。 红色线称为“超平面”。 这基本上是线性分离数据的线或平面。 与超平面一起,创建了与超平面平行的两个平面。 在创建这两个平面时,我们确保它们穿过最靠近超平面的点。 这些点可以称为最近点。 超平面的调整方式使其恰好位于两个平行平面的中间。 这两个平面之间的距离称为“边距”。 这两个平行平面的优势在于,它可以帮助我们以更好的方式对这两个类别进行分类。 现在出现一个问题,可能有多个超平面,为什么我们从上图中选择一个? 答案是选择超平面,其裕度即两个平行平面之间的距离最大。 这两个平行平面上的点称为支持向量。 上图是训练数据后获得的。 现在,对于未知数据或测试数据的分类,该算法将仅考虑参考支持向量进行分类。
Python实现: (Python Implementation:)
The python implementation is shown below. The data is divided into a training dataset and a testing dataset. The notations used are X_train, X_test, y_train, y_test. This is done with the help of the ‘train-test-split function’. Now let's get to the implementation part. First, we start off by importing the libraries that are required to implement the SVM algorithm.
python实现如下所示。 数据分为训练数据集和测试数据集。 使用的符号是X_train,X_test,y_train,y_test。 这是通过“ train-test-split函数”来完成的。 现在让我们进入实现部分。 首先,我们首先导入实现SVM算法所需的库。
# Import SVM from sklearn import svm# Creating a SVM Classifier
classifier = svm.SVC(C=0.01, break_ties=False, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape='ovr', degree=1, gamma='scale', kernel='rbf',max_iter=-1,probability=False, random_state=None, shrinking=True,tol=0.001, verbose=False)
# Training the model
classifier.fit(X_train, y_train)As seen from the above code block, the implementation is quite easy. Let us discuss the parameters that we need to specify in the brackets. These parameters are used to tune the model to obtain better accuracy. The most commonly used parameters that we use for tuning are:
从上面的代码块可以看出,实现非常容易。 让我们讨论一下我们需要在方括号中指定的参数。 这些参数用于调整模型以获得更好的精度。 我们用于调优的最常用参数是:
C : This is the regularization parameter. It is inversely proportional to C. The most common values that we use for C are 1, 10, 100, 1000.
C:这是正则化参数。 它与C成反比。我们为C使用的最常见值为1、10、100、1000。
kernel: The most commonly used kernels are, ‘linear’, ‘poly’, ‘rbf’. When the data is linearly separable, we can use the linear kernel. When the data is not linearly separable and the relationship is of a higher degree then we use ‘poly’ as the kernel. The ‘rbf’ is used when we don't exactly know which kernel is to be specified.
内核:最常用的内核是“线性”,“多边形”,“ rbf”。 当数据是线性可分离的时,我们可以使用线性核。 当数据不是线性可分离的并且关系具有更高的程度时,我们使用“ poly”作为内核。 当我们不完全知道要指定哪个内核时,将使用“ rbf”。
gamma: This parameter is used to handle non-linear classification. When the points are not linearly separable, we need to transform them into a higher dimension. A small gamma will result in low bias and high variance while a large gamma will result in higher bias and low variance. Thus we need to find the best combination of ‘C’ and ‘gamma’.
gamma:此参数用于处理非线性分类。 当这些点不能线性分离时,我们需要将它们转换为更高的维度。 较小的伽玛将导致低偏差和高方差,而较大的伽玛将导致较高的偏差和低方差。 因此,我们需要找到“ C”和“γ”的最佳组合。
结论: (Conclusion:)
Support Vector Machines is one of the widely used algorithms in machine learning. I hope that the geometrical interpretation along with its implementation in python along with the parameter tuning is understood. Happy learning!
支持向量机是机器学习中广泛使用的算法之一。 我希望可以理解几何解释及其在python中的实现以及参数调整。 学习愉快!
python svm向量















 5514
5514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









