





基于深度学习的mr降噪
问题陈述 (Problem Statement)
The supermarket has 10 checkout counters, with 6 of them being operated. Currently these 6 checkout counters are being operated by employees that have low skill. The supermarket has 3 types of employees available to operate: highly skilled, skilled, and low skill. They have 15 of each type of employee available. Each type of employee can check out 30, 25, and 20 customers per 2-hour time interval based on their skill level. The management has identified that by every extra customer they checkout, they expect a profit of 2 USD. The management wants to (i) identify the demand of the checkout counters in various time intervals during the day [i.e, 8AM to 10AM, 10AM to 12AM, 12AM to 2PM, 2PM to 4PM, 4PM to 6PM and 6PM to 8PM] and to (ii) optimize the number of checkout counters open, and the skill level of the operators to manage the customers efficiently.
该超市有10个结帐柜台,其中有6个正在运行。 目前,这6个结帐柜台由技能低下的员工操作。 超级市场有3种类型的员工可以操作:高技能,熟练和低技能。 每种类型的员工都有15名。 每种类型的员工都可以根据其技能水平在每2小时的时间间隔内签出30、25和20个客户。 管理层已确定,他们结账的每多一位客户,他们都希望获得2美元的利润。 管理层希望(i)在一天中的各个时间间隔内确定结帐柜台的需求(即8AM至10 AM、10AM至12 AM、12AM至2 PM、2PM至4 PM、4PM至6PM和6PM至8PM)和(ii)优化开设的结帐柜台的数量以及运营商有效管理客户的技能水平。
解决方案概要 (Solution Outline)
Let’s divide the problem into 2 stages. Stage I -Identifying the customer checkout demand in different time intervals mentioned in the problem. Stage II -Checkout counters optimization and the operators schedule.
让我们将问题分为两个阶段。 第一阶段-确定问题中提到的不同时间间隔内的客户结帐需求。 第二阶段-结帐柜台优化和操作员时间表。
Stage I -Identifying the customer checkout demand in different time intervals mentioned in the problem.
第一阶段-确定问题中提到的不同时间间隔内的客户结帐需求。
There are many ways to identify the customer demand such as bar code scanning, manual counting, etc. Let us assume that the demand of the customers is being monitored by a security camera at the checkout counters. I would like to automate this process by using Deep Learning object identification algorithm in Python.
有多种识别客户需求的方法,例如条形码扫描,手动计数等。让我们假设客户的需求正在由结帐柜台处的安全摄像机监控。 我想通过在Python中使用深度学习对象识别算法来自动化此过程。
Let’s Dive into Deep Learning
让我们潜入深度学习

Let’s start simply by taking a small 10 minutes Mr. Bean cartoon episode and try to find the run time of Mr. Bean in the total video. This work can be scalable to a higher level to find customer demand and their wait times.
让我们以一小段10分钟的Bean先生卡通情节开始,然后尝试在整个视频中查找Bean先生的运行时间。 这项工作可以扩展到更高的级别,以找到客户需求及其等待时间。
First, the most important thing to do in a video classification is to break the video into images as video is nothing but image snaps. By doing this, we are converting the video classification problem into an image classification problem.
首先,视频分类中最重要的事情是将视频分解为图像,因为视频不过是图像快照。 通过这样做,我们将视频分类问题转换为图像分类问题。
count = 0
videoFile = "Train.mp4"#capturing the video from the given path
cap = cv2.VideoCapture(videoFile)
frameRate = cap.get(5) #frame rate
x=1
while(cap.isOpened()):
frameId = cap.get(1) #current frame number
ret, frame = cap.read()
if (ret != True):
break
if (frameId % math.floor(frameRate) == 0):
filename ="Mrframe%d.jpg" % count;count+=1
cv2.imwrite(filename, frame)
cap.release()
print ("Done!")The python code above reads and breaks the video into images and saves them. Next comes the brute force approach of labelling a few images manually with 1 for Mr Bean presence and 0 for absence for training our model. Now, our training .csv file is ready.
上面的python代码读取视频并将其分解为图像,然后将其保存。 接下来是蛮力方法,手动标记一些图像,其中1表示Bean先生在场,0表示不存在以训练我们的模型。 现在,我们的培训.csv文件已准备就绪。
# Read the labelled csv file
data = pd.read_csv('Mrmapping.csv')
data.head() # printing first five rows of the file# Read the labelled images
X = [ ] # creating an empty array
for img_name in data.Image_ID:
img = plt.imread('' + img_name)
X.append(img) # storing each image in array X
X = np.array(X) # converting list to arrayNow we have the labelled images with their labels. Before building our model, lets preprocess it.
现在我们有了带有标签的图像。 在构建模型之前,请对其进行预处理。
from keras.models import Sequential
from keras.applications.vgg16 import VGG16
from keras.layers import Dense, InputLayer, Dropoutbase_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3)) # include_top=False to remove the top layerX_train = base_model.predict(X_train)
X_valid = base_model.predict(X_valid)
X_train.shape, X_valid.shape# converting to 1-D
X_train = X_train.reshape(125, 7*7*512)
X_valid = X_valid.reshape(54, 7*7*512)# centering the data
train = X_train/X_train.max()
X_valid = X_valid/X_train.max()Next comes the building, compiling and training of the model.
接下来是模型的构建,编译和培训。
# 1. Building the model
model = Sequential()
model.add(InputLayer((7*7*512,))) # input layer
model.add(Dense(units=1024, activation='sigmoid')) # hidden layer
model.add(Dense(2, activation='softmax')) # output layer# 2. Compiling the model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])# 3. Training the model
model.fit(train, y_train, epochs=100, validation_data=(X_valid, y_valid))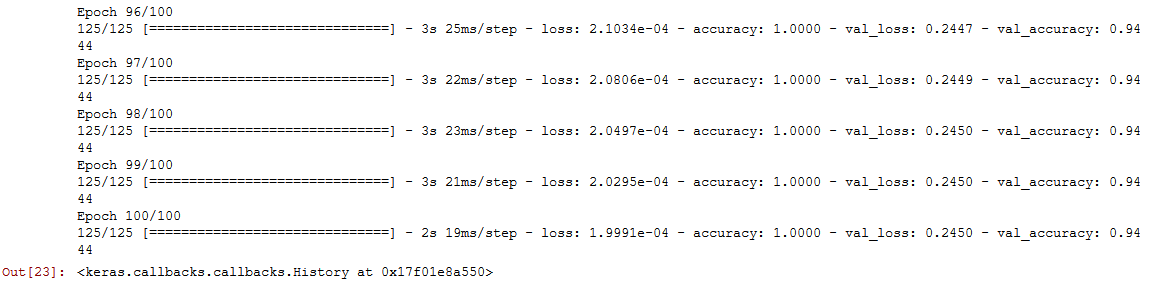
Our model performed with 94% of accuracy on this video. Now, let’s calculate the Mr Bean’s run time.
我们的模型在此视频上的准确度达到94%。 现在,让我们计算Bean先生的运行时间。
# Predicting the Images
predictions = model.predict_classes(test_image)# Run Time Output
print("The screen time of Mr Bean is", predictions[predictions==1].shape[0], "seconds")
print("The screen time of others is", predictions[predictions==0].shape[0], "seconds")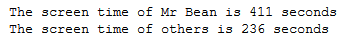
So, this is how we can calculate the runtime of Mr Bean in a given video and this work can be scalable to find the customer checkout demand and their wait times in different time intervals.
因此,这是我们如何计算给定视频中Bean先生的运行时间,并且可以扩展此工作以查找客户结帐需求及其在不同时间间隔的等待时间。
Complete Python Code hyperlinked.
完整的Python代码超链接。
Let’s say by using this algorithm, we found the customer checkout demand as 8AM to 10AM — 100 No.s, 10AM to 12AM — 110 No.s, 12AM to 2PM — 120 No.s, 2PM to 4PM — 130 No.s, 4PM to 6PM — 120 No.s and 6PM to 8PM — 110 No.s.
假设使用此算法,我们发现客户结帐需求为:上午8点至上午10点-100号,上午10点至12点-110点,12点至2PM-120点,2PM至4PM-130点, 4PM至6PM — 120个编号和6PM至8PM — 110个编号。
Stage II -Checkout counters optimization and the operators schedule.
第二阶段-结帐柜台优化和操作员时间表。
Now, let’s start our mathematical optimization model and then we will move to a typical spreadsheet modelling. A typical model contains 1. Input Parameters, 2. Decision Variables, 3. Objective Function and 4. Constraints.
现在,让我们开始数学优化模型,然后转到典型的电子表格建模。 典型模型包含1.输入参数,2。决策变量,3。目标函数和4.约束。
Input Parameters
输入参数
(i) Di = Customers demand in ‘ i ’ time intervals, where i =[1,2,3,4,5,6], [i.e, 8AM to 10AM, 10AM to 12AM, 12AM to 2PM, 2PM to 4PM, 4PM to 6PM and 6PM to 8PM]
(i)Di =客户在'i'个时间间隔内的需求,其中i = [1,2,3,4,5,6],即8AM至10 AM、10AM至12 AM、12AM至2 PM、2PM至4PM, 4PM至6PM和6PM至8PM]
(ii) Rj= Counter operators per hour rate, where ‘ j ’ = [1,2,3], [i.e, High Skilled, Skilled, Low Skilled]
(ii)Rj =每小时柜台操作员费率,其中'j'= [1,2,3],[即,高技能,熟练,低技能]
(iii) Tj = Operators average checkout times productivity/capability, where ‘ j ’ = [1,2,3], [i.e, High Skilled, Skilled, Low Skilled]
(iii)Tj =运营商的平均结账时间生产率/能力,其中'j'= [1,2,3],[即,高技能,熟练,低技能]
(iv) M = Monetary value for one extra customer checkout in the time interval
(iv)M =在此时间间隔内进行一次额外客户结帐的货币价值
(v) COi = Current number of operators working (Currently only low skilled) in ‘ i ’ time intervals, where i =[1,2,3,4,5,6], [i.e, 8AM to 10AM, 10AM to 12AM, 12AM to 2PM, 2PM to 4PM, 4PM to 6PM and 6PM to 8PM]
(v)COi =在“ i”个时间间隔内工作的当前操作员数量(目前仅是低技能人员),其中i = [1,2,3,4,5,6],即8AM至10 AM、10AM至12AM ,12AM至2 PM、2PM至4 PM、4PM至6PM和6PM至8PM]
(vi) CCi = Current number of counters operating in ‘ i ’ time intervals, where i =[1,2,3,4,5,6], [i.e, 8AM to 10AM, 10AM to 12AM, 12AM to 2PM, 2PM to 4PM, 4PM to 6PM and 6PM to 8PM]
(vi)CCi =以“ i”个时间间隔运行的计数器的当前数量,其中i = [1,2,3,4,5,6],即8AM至10 AM、10AM至12 AM、12AM至2 PM、2PM到4 PM、4PM到6PM和6PM到8PM]
2. Decision Variables
2. 决策变量
(i) Ci = No. of counters to operate in ‘ i ’ time intervals, where i =[1,2,3,4,5,6], [i.e, 8AM to 10AM, 10AM to 12AM, 12AM to 2PM, 2PM to 4PM, 4PM to 6PM and 6PM to 8PM]
(i)Ci =在“ i”个时间间隔内运行的计数器数量,其中i = [1,2,3,4,5,6],即8AM至10 AM、10AM至12 AM、12AM至2PM, 2PM至4 PM、4PM至6PM和6PM至8PM]
(ii) Oij = No. of ‘ j ’ type operators to be deployed in ‘ i ’ time intervals, where i =[1,2,3,4,5,6], [i.e, 8AM to 10AM, 10AM to 12AM, 12AM to 2PM, 2PM to 4PM, 4PM to 6PM and 6PM to 8PM], ‘ j ’ = [1,2,3], [i.e, High Skilled, Skilled, Low Skilled]
(ii)Oij =要在'i'个时间间隔内部署的'j'型运算符的数量,其中i = [1,2,3,4,5,6],即8AM至10 AM、10AM至12AM ,从12AM到2PM,从2PM到4PM,从4PM到6PM,从6PM到8PM],'j'= [1,2,3],[即,高技能,熟练,低技能]
3. Objective Function
3. 目标函数
Operator cost saving = Σ COi*2*R3
节省运营商成本=ΣCOi * 2 * R3
Monetary value gained or lost in ‘ i ’ time interval = (Σ Oij*Tj — Di)*M
在'i'时间间隔内获得或损失的货币价值=(ΣOij * Tj-Di)* M
Maximize total cost savings = Σi COi*2*R3 +Σi (Σj Oij*Tj — Di)*M
最大程度地节省总成本=ΣiCOi * 2 * R3 +Σi(ΣjOij * Tj-Di)* M
4. Constraints
4. 约束
(i) Ci ≤ 10
(i)Ci≤10
(ii) Σj Oij = Ci
(ii)ΣjOij = Ci
(iii) Σi Oij ≤ 15
(iii)ΣiOij≤15
(iv) Σj Oij*Tj ≥ Di
(iv)ΣjOij * Tj≥Di
(v) Ci, Oij Integers and ≥ 0
(v)Ci,Oij整数且≥0
The above mathematical optimization model helps in finding the optimal number of counters to operate in different time intervals with the operators schedule.
上面的数学优化模型有助于找到最佳数量的计数器,以根据操作员时间表在不同时间间隔内操作。
Now, let us see the spreadsheet modelling and the result.
现在,让我们看一下电子表格的建模和结果。
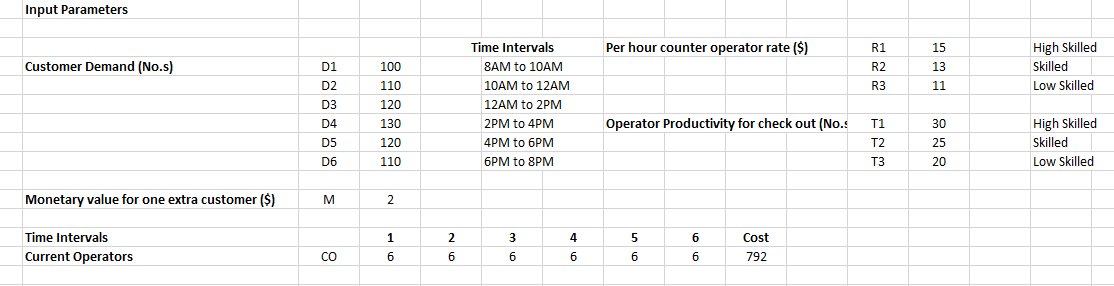
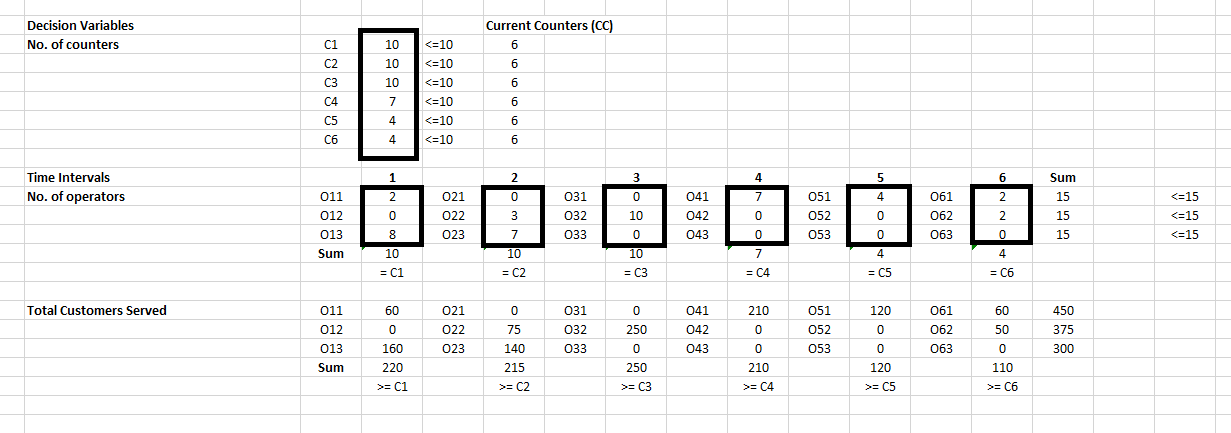
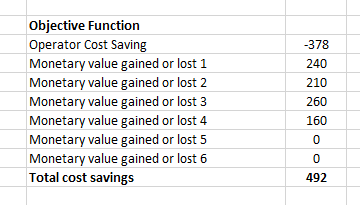
After creating the spreadsheet modelling as above, by using MS Solver add in MS Excel, I have optimized our objective function and the result is, C1 = 10 counters in time interval 1, C2 = 10, C3 = 10, C4 = 7, C5 = 4, C6 = 4 similarly and O11 = 2 High skilled operators in time interval 1, O12 = 0, O13 = 8, O21 = 0, O22 = 3, O23 = 7, O31 = 0, O32 = 10, O33 = 0, O41 = 7, O42 = 0, O43 = 0, O51 = 4, O52 = 0, O53 = 0, O61 = 2, O62 = 2, O63 = 0 similarly.
在创建完如上所述的电子表格模型之后,通过使用MS Excel中的MS Solver add,我优化了目标函数,结果是,时间间隔1,C1 = 10个计数器,C2 = 10,C3 = 10,C4 = 7,C5 = 4,C6 = 4和O11 = 2在时间间隔1,O12 = 0,O13 = 8,O21 = 0,O22 = 3,O23 = 7,O31 = 0,O32 = 10,O33 = 0的高级操作员,O41 = 7,O42 = 0,O43 = 0,O51 = 4,O52 = 0,O53 = 0,O61 = 2,O62 = 2,O63 = 0。
By performing our optimization analysis, we can save 492 USD per day which is 0.18 Million a year which is not a less amount.
通过执行优化分析,我们每天可以节省492美元,即每年18万美元。
I would like to thank my friend Chris Chou for proofreading this content.
感谢我的朋友克里斯·周(Chris Chou)对此内容进行了校对。
Python代码参考 (Python Code Reference)
[1] Pulkit Sharma, Deep Learning Tutorial to Calculate the Screen Time of Actors in any Video (with Python codes) (2018), https://www.analyticsvidhya.com/blog/2018/09/deep-learning-video-classification-python/
[1] Pulkit Sharma,《用于计算任何视频中演员的屏幕显示时间的深度学习教程(带有Python代码)》(2018年), https: //www.analyticsvidhya.com/blog/2018/09/deep-learning-video- 分类-python /
翻译自: https://medium.com/swlh/mr-beans-runtime-calculation-using-deep-learning-3eabdedccc38
基于深度学习的mr降噪















 6692
6692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









