





决策树算法原理
决策树 (Decision Trees)
Decision Tree is a tree shaped algorithm used to determine a course of action. Each branch of the tree represents a possible decision, occurrence or reaction.
决策树是用于确定操作过程的树形算法。 树的每个分支代表一个可能的决策,发生或React。
信息论: (Information Theory:)
Information Theory is the fundamentals of decision trees. In order for us to understand Decision Tree algorithm, we need to understand Information Theory.
信息论 是决策树的基础。 为了使我们了解决策树算法,我们需要了解信息论。
The basic idea of information theory is that the “informational value” of a data-set depends on the degree to which the content of the message is surprising or messy. If an event is very probable, it is no surprise (and generally uninteresting) when that event happens as expected; hence transmission of such a message carries very little new information. However, if an event is unlikely to occur, it is much more informative to learn that the event happened or will happen.
信息理论的基本思想是,数据集的“信息价值”取决于消息内容令人惊讶或混乱的程度。 如果某个事件很可能发生,那么当该事件按预期发生时就不足为奇了(通常并不有趣)。 因此,此类消息的传输几乎没有新信息。 但是,如果事件不太可能发生,则了解该事件已发生或将要发生将提供更多信息。
For example, there are at-least 3000 varieties of fishes available in both coast of India alone, if we are building a “shark” classifier to identify whether, it is a Shark or not. It is important for us to introduce non-shark images to the datasets as negative samples in-order for the classifier to distinguish between a shark and a non-shark fish. The entropy is high only when the mixture of positive samples (shark) and negative samples (non-shark) are equal, implying the data-set has interesting features to learn.
例如,如果我们正在建立一个“鲨鱼”分类器来识别它是否是鲨鱼,仅在印度两个海岸就有至少3000种鱼类。 对于我们来说,重要的是将非鲨鱼图像作为负样本引入数据集中,以便分类器区分鲨鱼和非鲨鱼。 仅当正样本(鲨鱼)和负样本(非鲨鱼)的混合物相等时, 熵才高,这意味着数据集具有学习的有趣特征。
If all images in our data-set are positive(shark), then we don’t learn anything new — no matter how many images of shark it contains.
如果数据集中的所有图像都是正图像(鲨鱼),那么我们就不会学到任何新东西,无论它包含多少鲨鱼图像。
It is observed that the entropy is maximum when the probabilities are equal.
可以看出,当概率相等时,熵最大。
决策树: (Decision Tree:)
The basic idea behind a Decision Tree is to break classification down into a set of choices about each entry (i.e. column) in our feature vector. We start at the root of the tree and then progress down to the leaves where the actual classification is made.
决策树背后的基本思想是将分类分解为关于特征向量中每个条目(即列)的一组选择。 我们从树的根部开始,然后向下进行到进行实际分类的叶子。
For example, lets assume we are on a hiking trip to lake district and the rain is on and off, we need to decide whether to stay indoor or go on a hike.
例如,假设我们要去湖区远足,而雨时断时续,我们需要决定是呆在室内还是远足。
As you can see from FIG 1 above, we have created a decision tree diagram where the decision blocks (rectangles) indicate a choice that we must make. We then have branches which lead us to other decision blocks or a terminating block (ovals). A terminating block is a leaf node of the tree, indicating that a final decision has been made.
从上面的图1中可以看到,我们创建了一个决策树图,其中决策块 (矩形)指示我们必须做出的选择 。 然后,我们有了将我们引向其他决策块或终止块 (椭圆)的分支 。 终止块是树的叶节点,表示已做出最终决定。
树木建造: (Tree Construction:)
Decision tree algorithms use information theory in some shape or form to obtain the optimal, most informative splits (i.e. the “decisions”) to construct a series of “if/then” rules in a tree-like manner.
决策树算法使用某种形式或形式的信息理论来获取最佳,信息量最大的拆分(即“决策”),以树状方式构建一系列“如果/则”规则。
First step in constructing a decision tree is forming the root node of the tree. ie, which feature is split to form the rest of the tree.
构造决策树的第一步是形成决策树的根节点。 即,哪个特征被分割以形成树的其余部分。
In order for us to find the root node, we calculate the information gain from each feature column. The feature column with maximum information gain is selected as the root node and split is made from the selected root node to construct the decision tree.
为了找到根节点,我们从每个要素列计算信息增益。 选择具有最大信息增益的特征列作为根节点,并从选定的根节点进行拆分以构建决策树。

Formula to calculate Entropy :
计算熵的公式:

Where , p = number of unique values in a feature column / total number of features in a feature column
其中,p =特征列中唯一值的数目/特征列中特征的总数
For example, Lets find the entropy of the below animal dataset
例如,让我们找到以下动物数据集的熵

The dataset is looking quite messy and the entropy is high in this case
在这种情况下,数据集看起来非常混乱,并且熵很高


Total number of animals= 8
动物总数= 8
Number of Giraffe in Dataset = 3
数据集中的长颈鹿数量= 3
Number of Tiger in Dataset = 2
数据集中的老虎数= 2
Number of Monkey in Dataset = 1
数据集中的猴子数= 1
Number of Elephant in Dataset = 2
数据集中的大象数= 2
Hence the entropy is calculated as below,
因此,熵的计算如下


import math
entropy = -(3/8)*math.log2(3/8)+(2/8)*math.log2(2/8)+(1/8)*math.log2(1/8)+(2/8)*math.log2(2/8)print(entropy)The entropy here is approximately 1.9. This is considered a high entropy , a high level of disorder ( meaning low level of purity).
此处的熵约为1.9 。 这被认为是高熵,高水平的无序(意味着低水平的纯度)。
示例:决策树 (Example : Decision Tree)
Lets take an example data-set below and build a decision tree on it. Here “play” feature is the independent variable and rest of the feature columns are dependent variables.
让我们以下面的数据集为例,并在其上构建决策树。 这里的“播放”功能是自变量,其余功能列是因变量。

We will take 5 steps to build the decision tree:
我们将采取5个步骤来构建决策树:
Step 1: Compute the Entropy of data-set (target variable) — E(s)
步骤1:计算数据集的熵(目标变量)— E(s)
Step 2: Compute Information gain for each dependent variable — Gain(Outlook), Gain(temp), Gain(humidity), Gain(windy) using the below equations:
步骤2:使用以下公式计算每个因变量(增益(Outlook),增益(温度),增益(湿度),增益(风))的信息增益:
I(outlook) = ((total number of sunny /total features in outlook) * E(outlook=sunny)) * ((total number of overcast/total features in outlook) E(outlook=overcast)) * ((total number of rainy/total features in outlook) E(outlook=rainy))
I(outlook) =( (outlook中晴天/总特征数)* E(outlook =晴天))*((outlook中阴/总特征数)E(outlook =阴暗))*((总数前景中的阴雨/总特征数)E(outlook = rainy))
Gain(outlook) = E(s) — I(outlook)
收益(外观) = E(s)-我(外观)
I(temp) = ((total number of hot/total features in temp) * E(temp=hot)) * ((total number of mild/total features in temp) E(temp=mild)) * ((total number of cool/total features in temp) E(temp=cool))
I(温度) =( (温度中热/特征总数)* E(温度=热))*((温度中轻度/特征总数)E(温度=轻度))*((总数的冷/总特征的数量)E(temp = cool))
Gain(temp) = E(s) — I(temp)
增益(温度) = E(s)-I(温度)
I(humidity) = ((total number of high/total features in humidity) * E(humidity=high)) * ((total number of normal/total features in humidity) E(humidity=normal))
I(湿度) =( (湿度中高/总特征数)* E(湿度=高))*((湿度中正常/总特征数)E(湿度=正常))
Gain(humidity) = E(s) — I(humidity)
增益(湿度) = E(s)— I(湿度)
I(windy) = ((total number of true/total features in windy) * E(windy=true)) * ((total number of false/total features in windy) E(windy=false))
I(windy) =( (windy中真实/总特征的总数)* E(windy = true))*((windy中错误/总特征的总数)E(windy = false))
Gain(windy) = E(s) — I(windy)
增益(有风) = E(s)-I(有风)
Step 3: Find the feature with maximum Gain and select that as root node Gain(Outlook) or Gain(temp) or Gain(humidity) or Gain(windy)
步骤3:找到具有最大增益的功能,然后将其选择为根节点“增益”(Outlook) 或“增益”(温度) 或“增益”(湿度) 或“增益”(风)
Step 4: Find the next node to split the tree further
步骤4 :找到下一个节点以进一步拆分树
Step 5: A decision tree would repeat this process as it grows deeper and deeper till either it reaches a pre-defined depth or no additional split can result in a higher information gain beyond a certain threshold which can also usually be specified as a hyper-parameter!
第5步:决策树会随着过程的不断深入而重复该过程,直到达到预定深度或没有其他拆分都可以导致超出特定阈值的更高信息增益,通常也可以将其指定为超参数!
Step 1: Compute the Entropy of data-set (target variable) — E(s)
步骤1:计算数据集的熵(目标变量)— E(s)

The entropy of data-set E(s) is 0.94
数据集E(s)的熵为0.94
Step 2: Compute Information gain of each features
步骤2:计算每个功能的信息增益
Feature 1: outlook
功能1:前景

The information gain from the ‘outlook’ feature is 0.24
“外观”功能获得的信息收益为0.24
Feature 2: temp
特征2:温度

Feature 3: Humidity
特点3:湿度

Feature 4: windy
特色四:大风

Step 3: Find the feature with maximum Gain and select that as root node Gain(Outlook) or Gain(temp) or Gain(humidity) or Gain(windy)
步骤3:找到具有最大增益的功能,然后将其选择为根节点“增益”(Outlook)或“增益”(温度)或“增益”(湿度)或“增益”(风)
So, the maximum gain is identified as 0.24 , hence Outlook is our ROOT Node
因此,最大增益被标识为0.24,因此Outlook是我们的ROOT节点
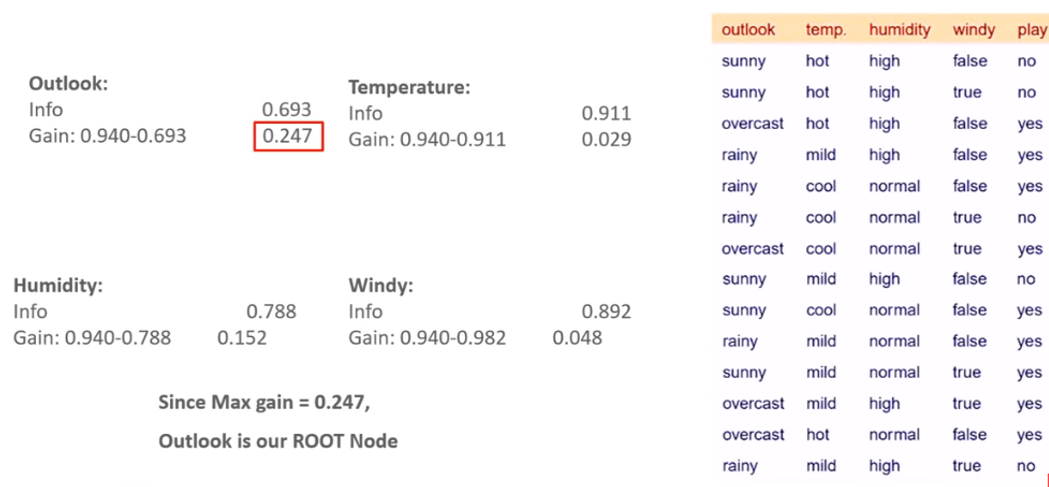
Step 4: With more than two features the first split is made on the most informative feature and then at every split the information gain for each additional feature needs to be recomputed because it would not be the same as the information gain from each feature by itself. The entropy and information gain would have to be calculated after one or more splits have already been made which would change the results.
步骤4 :具有两个以上的特征时,首先对信息量最大的特征进行分割,然后在每个分割处都需要重新计算每个附加特征的信息增益,因为它与每个特征本身的信息增益不相同。 在已经进行了一次或多次拆分之后,必须计算熵和信息增益,这会改变结果。


Step 5: A decision tree would repeat this process as it grows deeper and deeper till either it reaches a pre-defined depth or no additional split can result in a higher information gain beyond a certain threshold which can also usually be specified as a hyper-parameter!
第5步 :决策树会随着其越来越深而重复此过程,直到达到预定深度或没有其他拆分都可以导致超出特定阈值的更高信息增益,通常也可以将其指定为超参数!

Hope you had a great insight on decision tree algorithm by understanding the computations behind information gain and entropy.
希望您通过了解信息增益和熵背后的计算,对决策树算法有深刻的了解。
Do let me know your feedback in the comments
请在评论中让我知道您的反馈意见
Reference:
参考:
https://web.stanford.edu/~montanar/RESEARCH/BOOK/partA.pdf
https://web.stanford.edu/~montanar/RESEARCH/BOOK/partA.pdf
https://web.mit.edu/6.933/www/Fall2001/Shannon2.pdf
https://web.mit.edu/6.933/www/Fall2001/Shannon2.pdf
https://towardsdatascience.com/entropy-how-decision-trees-make-decisions-2946b9c18c8
https://towardsdatascience.com/entropy-how-decision-trees-make-decisions-2946b9c18c8
翻译自: https://medium.com/swlh/decision-tree-algorithm-109b6fd75328
决策树算法原理















 381
381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









