





As a fledgling Data Science student at Lambda School, it’s easy to get lost in Python’s vast ecosystem of data science libraries such as pandas, NumPy, and scikit-learn and lose sight of the underlying algorithm we depend on for our analysis.
作为Lambda学校的刚开始学习数据科学的学生,很容易迷失在Python庞大的数据科学图书馆生态系统(例如pandas , NumPy和scikit-learn)中,而忽视了我们分析所依赖的基础算法。
目标 (The Objective)
As a part of our Computer Science (CS) coursework — that we’re sharing with our Lambda Web Development compatriots — is to “take it back to the streets” and implement a common data science algorithm with native code rather than leaning on an existing library. This exercise would seem to help flex our CS learning and help refresh our understanding of the algorithmic underpinnings of the libraries we use every day. Challenge accepted!
作为与Lambda Web开发同胞共享的计算机科学(CS)课程的一部分,是“将其带回街头”,并使用本机代码实施通用的数据科学算法,而不是依靠现有的图书馆。 这项练习似乎可以帮助我们扩展CS学习,并有助于重新了解我们每天使用的库的算法基础。 接受挑战!
As a fan of the Go programming language, I decided to add a twist and use Go (https://golang.org) instead of Python as the implementation language of choice.
作为Go编程语言的忠实拥护者,我决定添加一种选择,并使用Go( https://golang.org )代替Python作为首选的实现语言。
随它踢 (Kick It With Go)
Go is a statically typed, compiled language initially designed at Google by Robert Griesemer, Rob Pike, and Ken Thompson (Wikipedia). It is fast becoming the lingua franca of networked computing leveraged by prominent projects such as Docker, Kubernetes, and Terraform as well as a common choice for server-side systems at companies such as Google, Uber, Twitch, and Dropbox.
Go是一种静态类型化的编译语言,最初由Robert Griesemer,Rob Pike和Ken Thompson( Wikipedia )在Google设计。 它Swift成为网络计算的通用语言,受到Docker,Kubernetes和Terraform等著名项目的利用,并成为Google,Uber,Twitch和Dropbox等公司的服务器端系统的常见选择。
问题:垃圾邮件分类 (The Problem: Spam Message Classification)
A classic problem of the Internet age was combating the major pain point of this new form of communication we embraced called email. That pain was spam — unwanted email messages mostly in the form of tiresome advertisements and outright scams. (How many Nigerian princes are there anyways!)
互联网时代的一个经典问题是如何克服这种我们称为电子邮件的新型通信方式的主要痛点。 这种痛苦是垃圾邮件-多余的电子邮件大多以烦人的广告和完全的欺诈的形式出现。 (反正有几位尼日利亚王子!)
The issue is how can a computer program determine that this bunch of text is a birthday wish from Mom and that gaggle of words is asking me to purchase some new form of snake oil.
问题是计算机程序如何确定这堆文本是妈妈的生日愿望,而一堆乱七八糟的词却要我购买某种新形式的蛇油。
One answer lay in the form of Bayesian Inference that builds upon Bayes Theorem to infer or classify email messages such as spam (unwanted) or ham (wanted).
一个答案是基于贝叶斯定理的贝叶斯推理形式,以对垃圾邮件(不需要的)或火腿(不需要的)等电子邮件进行推断或分类。
贝叶斯推理 (Bayesian Inference)
Bayes Theorem is a mathematical expression that describes the probability of an event occurring in terms of known conditions prior to that event. In the case of our pesky spam message (a nasty event), can we predict that the next email we receive is spam based on what we know of the words included in that email?
贝叶斯定理是一种数学表达式,它根据事件发生之前的已知条件来描述该事件发生的可能性。 对于我们讨厌的垃圾邮件消息(令人讨厌的事件),我们是否可以根据我们对该电子邮件中包含的单词的了解来预测收到的下一封电子邮件是垃圾邮件?
We don’t know with absolute certainty that the next message is spam but a smart computer program can quickly read the inbound message’s words and “know” how often those words were included in spam messages observed in the past.
我们不能完全肯定地知道下一封邮件是垃圾邮件,但是智能计算机程序可以快速读取入站邮件的单词,并“知道”在过去观察到的垃圾邮件中包含这些单词的频率。
Computer programs are fast (usually) so the hope is that our program can read the bag of words from the message, assess how those words have been used in messages in the past (humans have marked past messages as spam/unwanted or ham/desired) and classify that message as spam and remove it from our view.
(通常)计算机程序速度很快,因此希望我们的程序能够读取邮件中的单词,评估过去这些单词在邮件中的使用方式(人类将过去的邮件标记为垃圾邮件/有害邮件或有害邮件/有害邮件) ),并将该邮件归类为垃圾邮件,并将其从我们的视图中删除。
So we have a possible future event — that my next email will be spam. Let’s call that future event “A”. And we have known events that have occurred in the past. That is past emails with a particular set of words that have been considered spam or ham. Let’s call that event “B”.
因此,我们将来可能会发生一次事件-我的下一封电子邮件将是垃圾邮件。 让我们将未来事件称为“ A ”。 而且我们知道过去发生的事件。 那是过去带有特定单词集的电子邮件, 这些单词被视为垃圾邮件或火腿。 我们将该事件称为“ B ”。
Bayes Theorem gives us a way to express how the probability of spam (“A”) given the probability that the presence of a bunch of words has resulted in messages deemed to be spam in the past (“B”). Here’s that formula from Wikipedia:
贝叶斯定理为我们提供了一种方式来表达垃圾邮件的概率(“ A”),考虑到一堆单词的存在导致过去的邮件被视为垃圾邮件(“ B”)的可能性。 这是维基百科的公式:
One step we can take with our basic spam filtering approach is to assume that each message word is independent of each other. That is we naively assume that if we come across the word “cold” we don’t have any information that the word “beer” will also be in the message as well. This refers to the naive bayesian approach. It may be unrealistic (in the case of my personal network… perhaps extremely so) but we’ll go with it.
我们使用基本垃圾邮件过滤方法可以采取的步骤是,假设每个消息词彼此独立。 那就是我们天真地假设,如果我们碰到“冷”一词,我们就不会知道消息中也包含“啤酒”一词。 这是指朴素的贝叶斯方法。 这可能是不现实的(在我的个人网络中……也许是如此),但我们将继续进行下去。
But making this assumption allows us to simplify the Bayes Theorem expression above for spam modeling purposes.
但是,进行此假设可以使我们简化上述用于垃圾邮件建模的贝叶斯定理表达式。
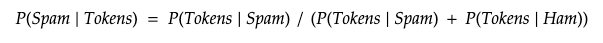
In short, if we take a naive approach the probability that a message is spam given the set of tokens can be expressed by what we’ve analyzed in our dataset. That is, the probability that those same tokens were in spam divided by the sum of the probabilities that the set of tokens in both spam and ham messages. Intuitively, if a bunch of words is almost always in spam messages but rarely in ham messages, the probability of spam will tend towards 100%.
简而言之,如果我们采取一种幼稚的方法,则在给定令牌集的情况下,邮件是垃圾邮件的概率可以通过我们在数据集中分析的内容来表示。 也就是说,这些相同令牌被放入垃圾邮件的概率除以垃圾邮件和火腿邮件中的令牌集合的概率之和。 直观地,如果一堆单词几乎总是出现在垃圾邮件中,而很少出现在火腿邮件中,则垃圾邮件的可能性将趋于100%。
消息对象 (A Message Object)
We’ll jump into Go code by describing what our program means by a message. Using Go’s struct object, the logic defines a message as a data structure with two attributes: Text (the message string) and isSpam (a true/false flag indicating if the message is spam). Here’s a little snippet of code that makes this definition.
我们将通过一条消息描述程序的含义,跳入Go代码。 使用Go的struct对象,该逻辑将消息定义为具有两个属性的数据结构: 文本 (消息字符串)和isSpam (指示消息是否为垃圾邮件的true / false标志)。 这是定义此代码的一小段代码。
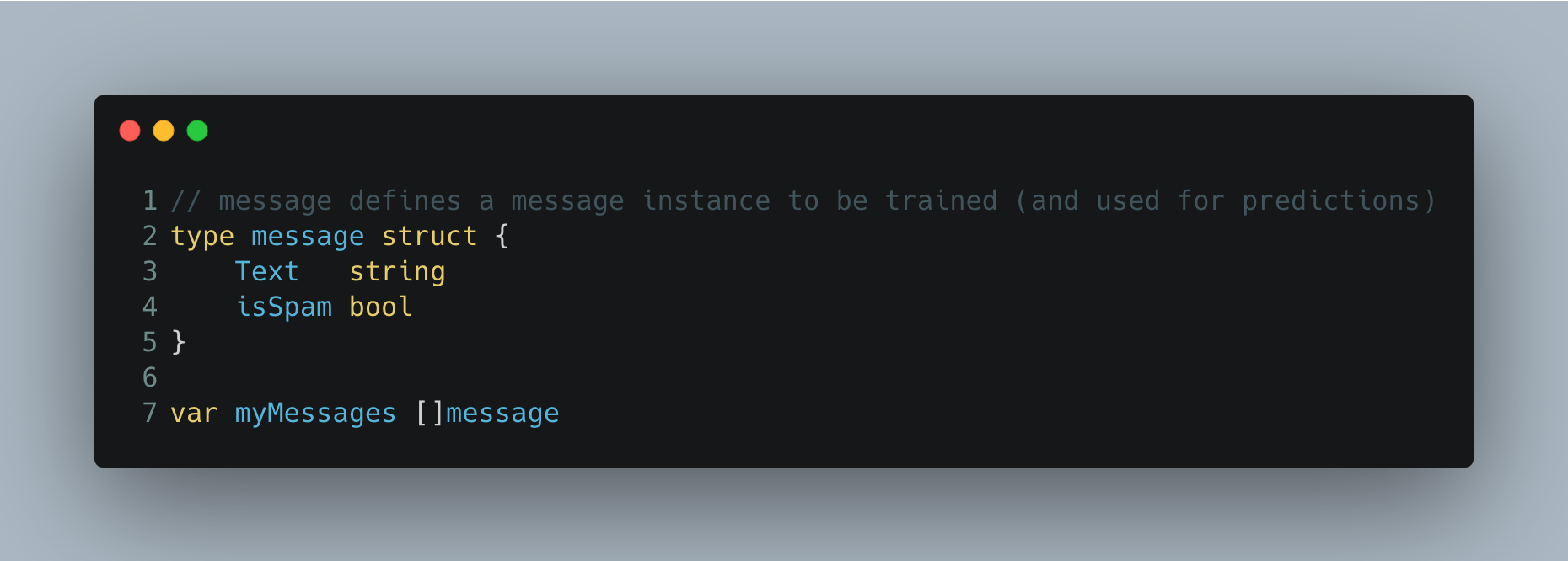
A bunch of messages such as we’ll use for fitting our model is simply an array of message structs represented by the myMessages variable defined in line 7 above.
一堆消息(例如我们将用于拟合模型的消息)只是由上面第7行中定义的myMessages变量表示的消息结构数组。
标记消息词 (Tokenize Message Words)
To mathematically process words in a message, we’ll need to get a handle on how to define words from all of the characters that can be included in a message. For example, how does our process interpret punctuation such as the question mark at the end of this sentence?
为了对消息中的单词进行数学处理,我们需要了解如何从消息中可以包含的所有字符中定义单词。 例如,我们的过程如何解释标点符号,例如句子结尾的问号?
To help, we’ll need to “tokenize” words to eliminate extraneous and ambiguous characters and treat words in a consistent manner across all messages. To do that, we’ll fashion a rudimentary tokenization process using these basic rules:
为了提供帮助,我们需要对单词进行“标记”,以消除多余的和不明确的字符,并在所有消息中以一致的方式对待单词。 为此,我们将使用以下基本规则构建基本的令牌化过程:
- generate a unique token string for each allowable word in all messages 为所有消息中的每个允许单词生成唯一的令牌字符串
- ignore spaces so each word is considered the text between spaces (ie. separate the message string into individual words splitting the string when encountering embedded spaces) 忽略空格,因此每个单词都被视为空格之间的文本(即,将消息字符串分成单个单词,当遇到嵌入空格时将其拆分为字符串)
- lowercase all alpha characters 小写所有字母字符
and… throw out all characters other than lowercase alphanumeric characters a to z and digits 0 to 1
并且…抛出除小写字母数字字符a至z和数字0至1以外的所有其他字符
So the message “Hey! hey… Why didn’t you get 2 DQ peanut buster parfaits?!” when tokenized would generate this list of tokens
所以消息“ 嘿! 嘿……你为什么不买2个DQ花生巴克冻糕? ”进行标记时会生成此标记列表
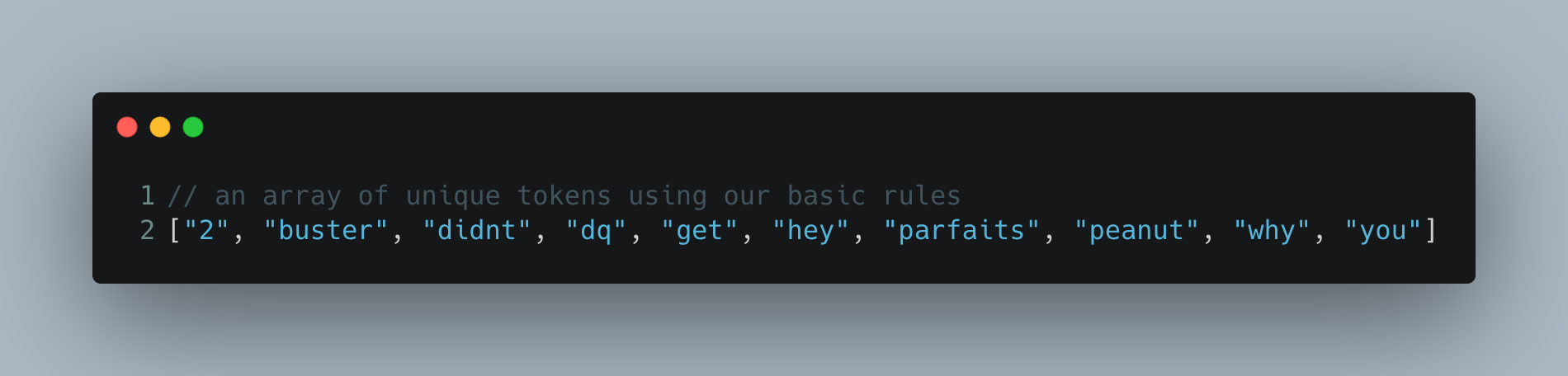
After tokenizing all of our words we’ll have a count of how many times each word appears in a spam message or ham (non-spam) message. Presumably, some spammy words are far more prevalent in spam messages than not.
在标记完所有单词之后,我们将计算每个单词出现在垃圾邮件或非垃圾邮件中的次数。 据推测,某些垃圾邮件词在垃圾邮件中的流行程度要远高于非垃圾邮件。
创建分类器模型 (Create a Classifier Model)
Similar to what we do with some of the Python ecosystem’s sophisticated statistical inference and machine learning libraries we’ll create a model object to classify our messages. Like messages above, the logic stands up a Go struct object to house the model’s attributes.
与我们对某些Python生态系统的复杂统计推断和机器学习库所做的类似,我们将创建一个模型对象来对消息进行分类。 像上面的消息一样,该逻辑建立一个Go结构对象以容纳模型的属性。
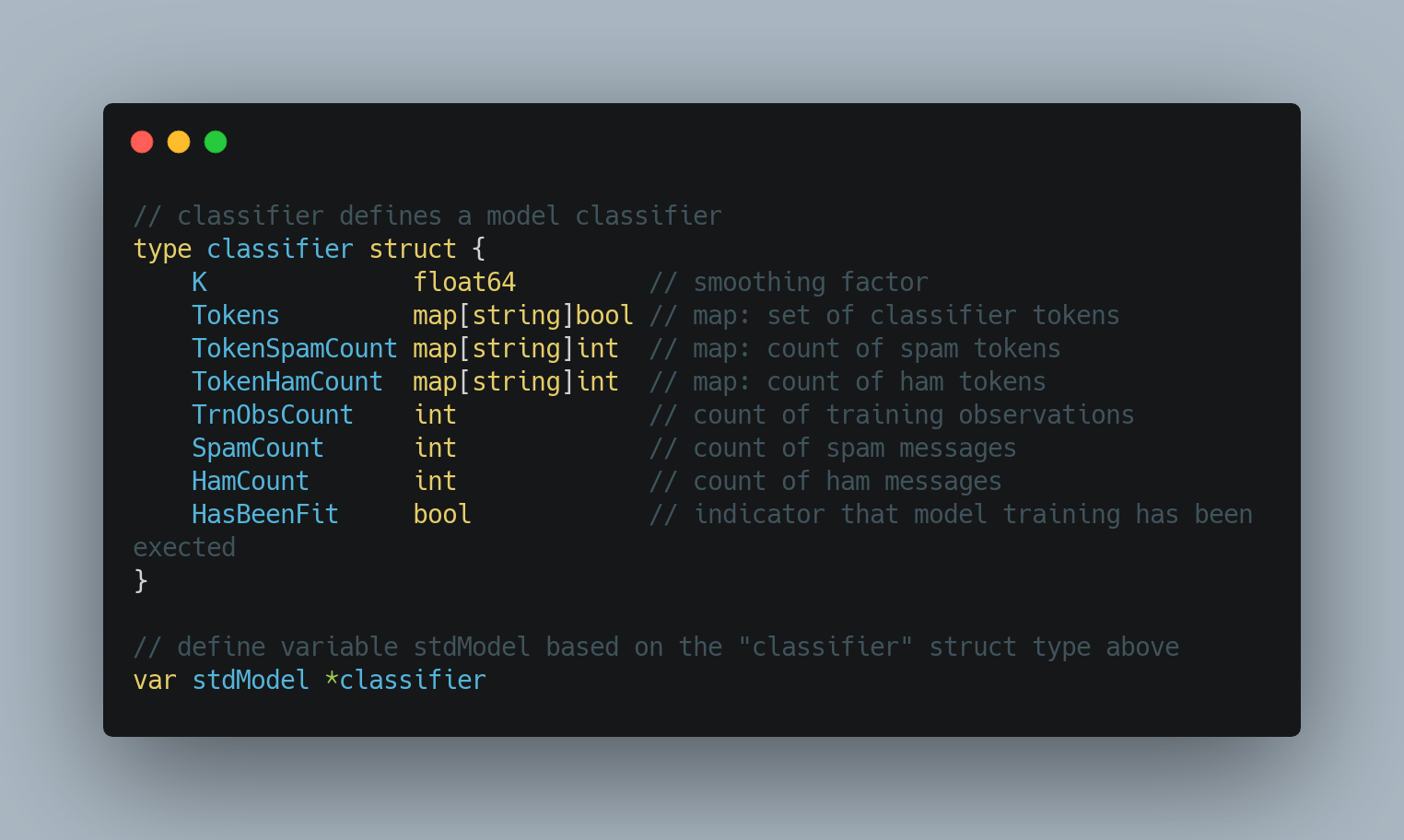
We’ll fit our dataset to the model and fill in these object attribute details based on that operation. In particular, we’ll know based on our data:
我们将数据集拟合到模型,并基于该操作填充这些对象属性详细信息。 特别是,我们将根据我们的数据知道:
- our unique set of tokens 我们独特的令牌集
- the number of spam messages in which a token is found 找到令牌的垃圾邮件数量
- the number of ham messages in which a token is found 找到令牌的火腿消息数
- total number of messages we have processed 我们已处理的消息总数
- with the total the number of spam messages 与垃圾邮件总数
- … and the number of ham messages …以及火腿消息的数量
To fit the classifier model, the code reads in a CSV file of spam/ham message downloaded from Kaggle (Dataset: Spam Text Message Classification — thanks TeamAI & Kaggle! link)
为了适合分类器模型,该代码读取从Kaggle下载的垃圾邮件/火腿邮件的CSV文件(数据集: 垃圾邮件文本邮件分类 -感谢TeamAI&Kaggle! 链接 )
预测垃圾邮件 (Predicting Spam)
Okay… the reason we’re here. Let’s do a prediction. The prediction task is to calculate the naive bayesian metrics generating a value we can interpret as a prediction.
好吧...我们在这里的原因。 让我们做一个预测。 预测任务是计算朴素贝叶斯指标,生成可以解释为预测的值。
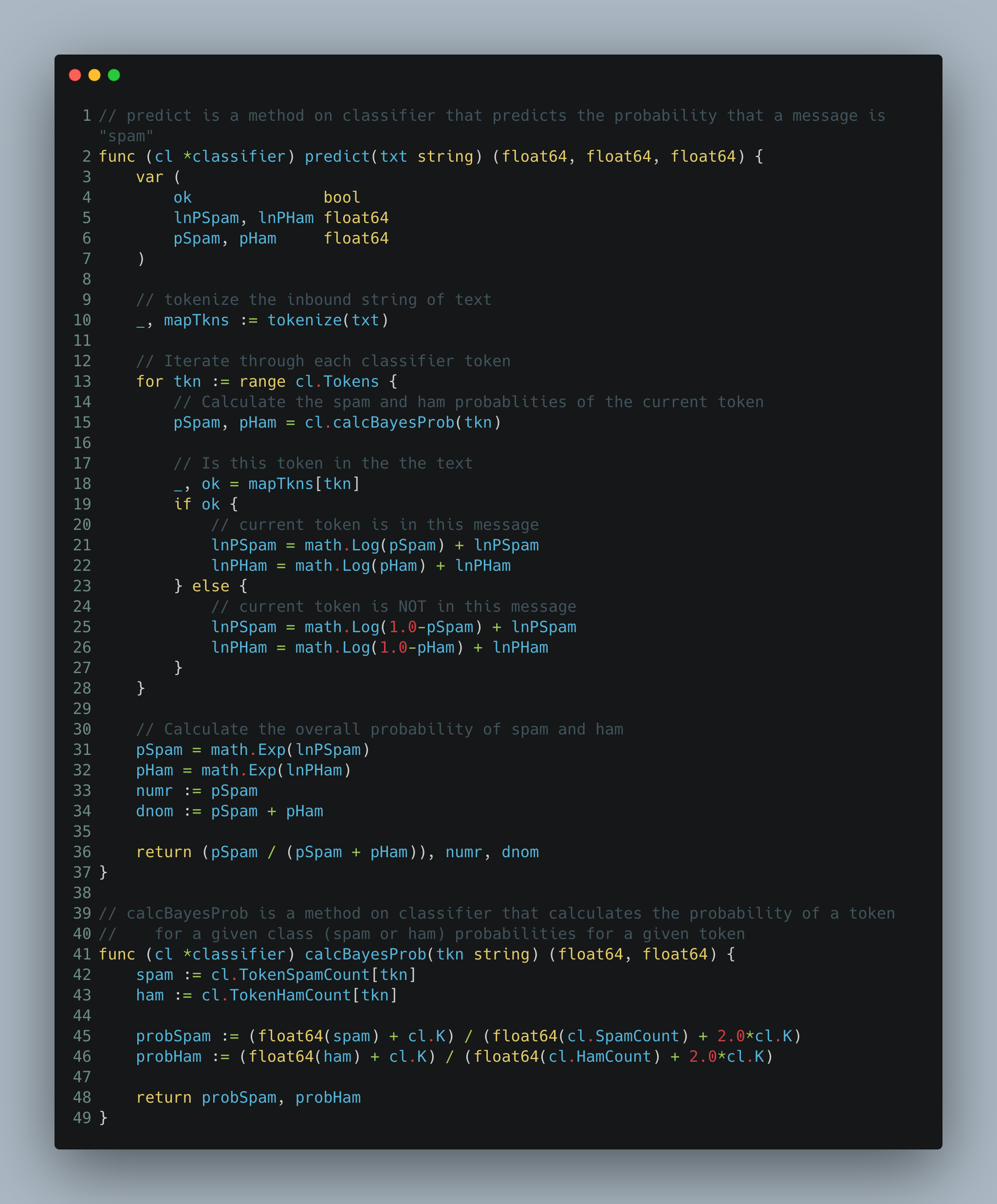
To generate a prediction the logic will:
要生成预测,逻辑将:
- accept a string text 接受字符串文字
- convert the string to a set of tokens 将字符串转换为一组标记
- for each token, calculate the probability of it appearing in a spam and ham message 对于每个令牌,计算它出现在垃圾邮件和火腿邮件中的概率
- for the set of tokens calculate the overall probability of that set appearing in a spam and ham message; in this case, instead of multiplying very small numbers the logic adds up the natural log of each value 为这组令牌计算该组出现在垃圾邮件和火腿邮件中的总体概率; 在这种情况下,逻辑不是将非常小的数字相乘,而是将每个值的自然对数相加
- return the set’s spam and ham values and generate the overall naive bayesian metric we talked about above 返回集合的垃圾邮件和火腿值,并生成我们上面讨论的整体朴素贝叶斯指标
看一看! (Take a Look!)
For Go developers or those interested in checking some go code, take a gander at my GitHub repo: https://github.com/danoand/CS-Data-Science-Build-Week-1.
对于围棋开发人员或对检查围棋代码感兴趣的人,请在我的GitHub存储库上轻描淡写: https : //github.com/danoand/CS-Data-Science-Build-Week-1 。
The Go modeling code resides in the modeling.go file in the root of the repo. The comparable Python model can be found in the python/app.py file.
Go建模代码位于存储库根目录中的modelling.go文件中。 可在python / app.py文件中找到类似的Python模型。
Better yet! The repo is a web application that displays an interactive web page where you can predict messages from the underlying dataset or type in your own message. You can compare the results from our native Go model and a Python scikit-learn model.
更好了! 回购是一个Web应用程序,它显示一个交互式网页,您可以在其中预测基础数据集中的消息或键入您自己的消息。 您可以将本机Go模型和Python scikit-learn模型的结果进行比较。
Navigate to https://bayes.dananderson.dev to take a look!
翻译自: https://medium.com/@danfanderson/naive-bayes-classifier-a-naive-gopher-approach-7848fa157ce8















 2593
2593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









