



 本文深入探讨了SQL中的排序(ORDER BY)、分组(GROUP BY)、HAVING子句及窗口函数的应用技巧。通过具体实例,讲解了如何高效地对查询结果进行排序和分组,以及如何利用窗口函数简化复杂查询,提升代码的可读性和性能。
本文深入探讨了SQL中的排序(ORDER BY)、分组(GROUP BY)、HAVING子句及窗口函数的应用技巧。通过具体实例,讲解了如何高效地对查询结果进行排序和分组,以及如何利用窗口函数简化复杂查询,提升代码的可读性和性能。
At first, it is worth mentioning that Oracle is presented here as a collecting SQL language. Aggregate functions and manner of their application fit the entire SQL family and are applicable to all queries considering the syntax of each language.
首先,值得一提的是,Oracle在这里是一种收集SQL语言。 考虑到每种语言的语法,聚合函数及其应用程序的方式适合整个SQL系列,并且适用于所有查询。
I’ll try to briefly and quickly explain all the details in two parts. The article will most likely be useful for beginners.
我将尝试简要快速地分两部分解释所有细节。 这篇文章对初学者很可能有用。
第1部分
排序依据,分组依据,具有 (Part 1
Order by, Group by, Having)
订购 (ORDER BY)
The ORDER BY clause allows sorting the output values, i.e., sorting the retrieved value by a specific column. Sorting can also be applied by a column alias that is defined with a clause.
ORDER BY子句允许对输出值进行排序,即,按特定列对检索到的值进行排序。 排序也可以通过用子句定义的列别名来应用。
The advantage of ORDER BY is that it can be applied to both numeric and string columns. String columns are usually sorted alphabetically.
ORDER BY的优点是它可以应用于数字列和字符串列。 字符串列通常按字母顺序排序。
By default, the ascending (ASC) sorting is applied. For the sorting to be descending, an additional DESC clause is used.
默认情况下,应用升序(ASC)排序。 为了使排序降序,使用了一个附加的DESC子句。
Syntax:
句法:
SELECT column1, column2,... (indicates the name
FROM table_name
ORDER BY column1, column2... ASC | DESC;Let’s consider the examples:
让我们考虑以下示例:
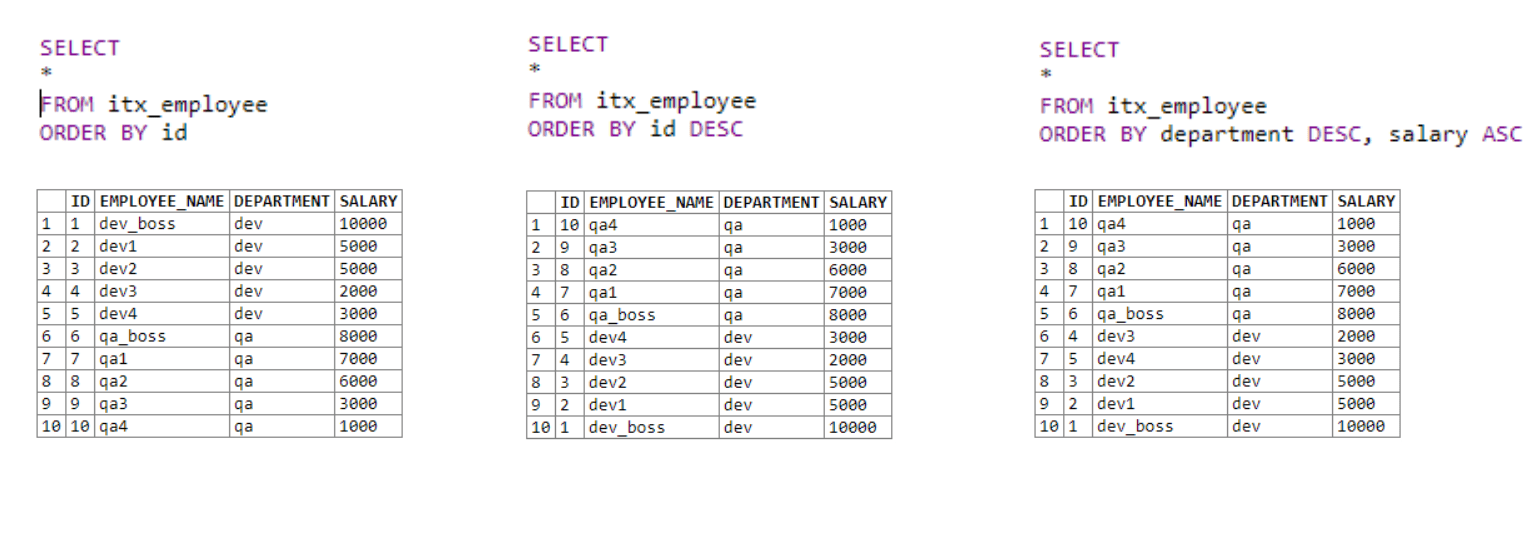
In the first table, we get all the data and sort it in ascending order by the ID column.
在第一个表中,我们获取所有数据,并按ID列升序对其进行排序。
In the second, we also get all the data sorted by the ID column in descending order using DESC.
在第二个中,我们还使用DESC获得了按ID列降序排列的所有数据。
The third table uses several fields for sorting. First, we sort by the department. If the first statement is equal for the fields with the same department, the second sorting condition is applied; in our case, it’s salary.
第三个表使用几个字段进行排序。 首先,我们按部门排序。 如果第一个语句对于具有相同部门的字段相等,则应用第二个排序条件;否则,将使用第二个排序条件。 就我们而言,这是工资。
It’s pretty simple. We can specify more than one sorting condition, which allows us to sort the output lists more efficiently.
很简单 我们可以指定多个排序条件,这使我们可以更有效地对输出列表进行排序。
通过...分组 (GROUP BY)
In SQL, the GROUP BY clause collects data retrieved from specific groups in a database. Grouping divides all data into logical sets so that statistical calculations can be performed separately in each group.
在SQL中,GROUP BY子句收集从数据库中特定组检索的数据。 分组将所有数据划分为逻辑集,以便可以在每个组中分别执行统计计算。
This clause is used to combine the selection results by one or more columns. After grouping, there will be only one entry for each value used in the column.
此子句用于按一列或多列组合选择结果。 分组后,该列中使用的每个值将只有一个条目。
The use of GROUP BY is closely related to the use of aggregate functions and the HAVING statement. An aggregate function in SQL is a function that returns a single value over a set of column values. For example: COUNT (), MIN (), MAX (), AVG (), SUM ().
GROUP BY的使用与聚合函数和HAVING语句的使用紧密相关。 SQL中的聚合函数是一种在一组列值上返回单个值的函数。 例如: COUNT(),MIN(),MAX(),AVG(),SUM()。
Syntax:
句法:
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
ORDER BY column_name(s);GROUP BY appears after the conditional WHERE clause in the SELECT query. Optionally, you can use ORDER BY to sort the output values.
GROUP BY出现在SELECT查询中的条件WHERE子句之后。 (可选)您可以使用ORDER BY对输出值进行排序。
Based on the table from the previous example, we need to find the maximum salary for each department. The final data selection should include the name of the department and the maximum salary.
根据上一个示例的表格,我们需要找到每个部门的最高薪水。 最终的数据选择应包括部门名称和最高工资。
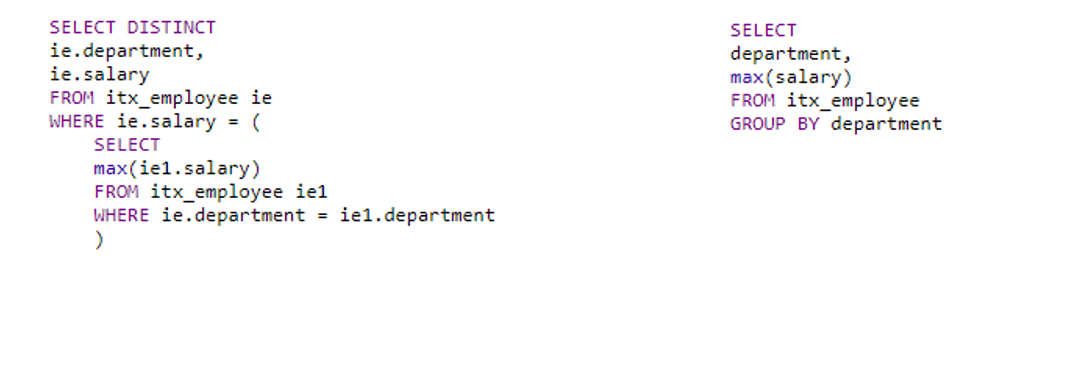
In the first example, we solve the task without grouping but using a subquery, i.e., nest one query into another one. In the second solution, we use grouping.
在第一个示例中,我们不用分组而是使用子查询来解决任务,即将一个查询嵌套到另一个查询中。 在第二个解决方案中,我们使用分组。
The second example is shorter and more readable, although it performs the same functions as the first one.
尽管第二个示例执行与第一个示例相同的功能,但它更短并且更具可读性。
How does GROUP BY work here: it splits two departments into QA and dev groups first, and then looks for the maximum salary for each of them.
GROUP BY在这里的工作方式:首先将两个部门分为质量检查小组和开发小组,然后为每个部门寻找最高薪水。
拥有 (HAVING)
HAVING is a filtering tool. It indicates the result of aggregate functions performance. The HAVING clause is used when we cannot use the WHERE keyword, i.e., with aggregate functions.
HAVING是一种过滤工具。 它指示聚合函数性能的结果。 当我们不能使用WHERE关键字(即带有聚合函数)时,将使用HAVING子句。
While the WHERE clause defines predicate for rows filtering, the HAVING clause is used after grouping to establish a logical predicate that filters groups by the values of aggregate functions. This statement is necessary for checking the values obtained through aggregate functions from groups of returned rows.
虽然WHERE子句为行过滤定义了谓词,但在分组之后使用HAVING子句来建立逻辑谓词,以根据聚合函数的值来过滤组。 该语句对于检查通过聚合函数从返回的行组中获得的值是必需的。
Syntax:
句法:
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
HAVING conditionFirst, we define the departments with an average salary higher than 4000 and then the max salary using filtering.
首先,我们定义平均工资高于4000的部门,然后使用过滤定义最高工资。

The first example uses two subqueries: the 1st to find the maximum salary, and the 2nd to filter the average salary. The second example, again, is much simpler and more concise.
第一个示例使用两个子查询:第一个子查询查找最高薪水,第二个子查询过滤平均薪水。 同样,第二个示例更简单,更简洁。
查询计划 (Query plan)
Quite often, there are situations when a query runs for a long time, consuming significant memory resources and disks. To understand why queries are running long and inefficiently, we can check the query plan.
在很多情况下,查询长时间运行会消耗大量的内存资源和磁盘。 要了解为什么查询运行时间长且效率低下,我们可以检查查询计划。
The query plan is the intended execution plan for the query, i.e., how the DMS will execute it. The DMS describes all the operations that will be performed within the subquery. Having analyzed everything, we will be able to understand the weak points in the query and use the query plan to optimize them.
查询计划是查询的预期执行计划,即DMS如何执行查询。 DMS描述了将在子查询中执行的所有操作。 分析完所有内容后,我们将能够了解查询中的薄弱环节,并使用查询计划对其进行优化。
Execution of any SQL statement in Oracle retrieves the so-called execution plan. This query execution plan is a description of how Oracle will fetch data according to the SQL statement being executed. A plan is a tree that contains a sequence of steps and the relations between them.
Oracle中任何SQL语句的执行都会检索所谓的执行计划。 该查询执行计划描述了Oracle将如何根据正在执行SQL语句获取数据。 计划是一棵树,其中包含一系列步骤及其之间的关系。
The tools allowing us to get the estimated execution plan of a query include Toad, SQL Navigator, PL / SQL Developer, and others. These tools provide a number of indicators of the query resource intensiveness, among which the main ones are: cost — the cost of execution and cardinality (or rows).
使我们能够获取查询的估计执行计划的工具包括Toad,SQL Navigator,PL / SQL Developer等。 这些工具提供了许多查询资源密集度的指标,其中主要指标是:成本-执行成本和基数 (或行数 )。
The higher the value of these indicators, the less efficient the query.
这些指标的值越高,查询的效率越低。
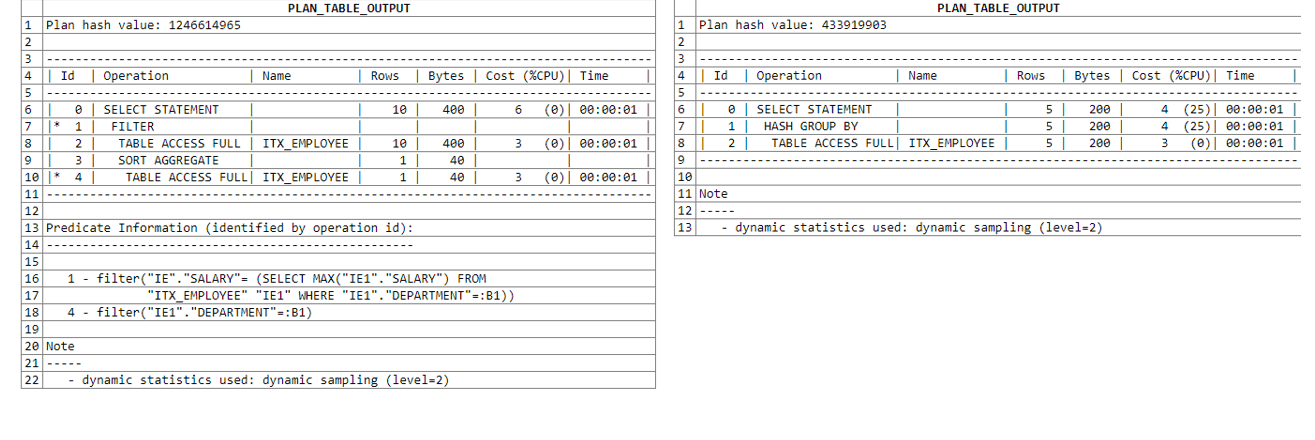
Below there is the query plan analysis. The first solution uses a subquery; the second uses grouping. Note that in the first case, 22 lines are processed, in the second one — 15.
下面是查询计划分析。 第一个解决方案使用子查询; 第二个使用分组。 请注意,在第一种情况下,处理了22行,在第二种情况下处理了15行。
Another query plan analysis that uses two subqueries:
另一个使用两个子查询的查询计划分析:
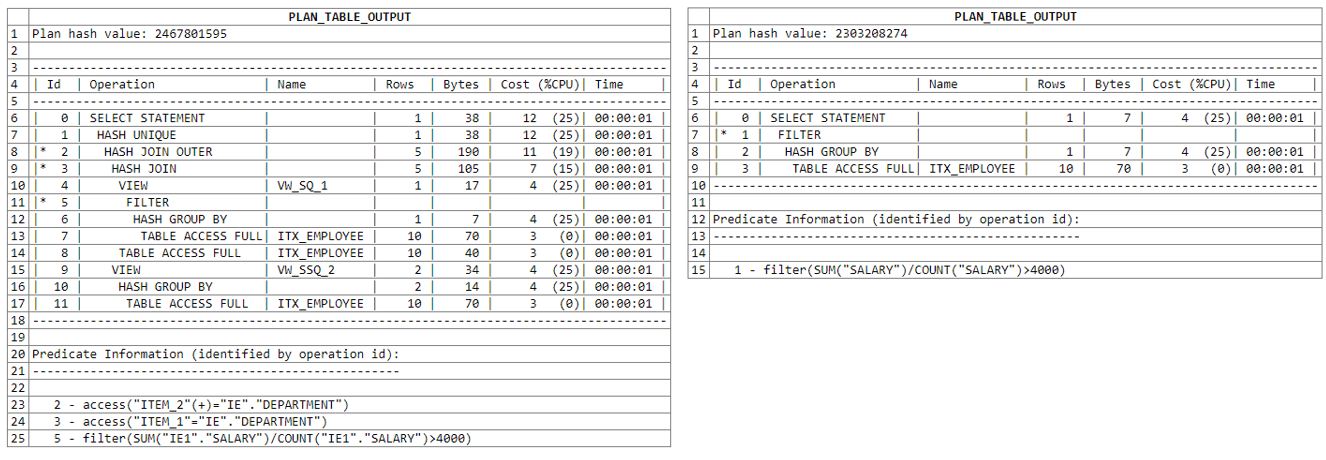
This is an example of the ineffective use of SQL tools, and we do not recommend to use it in your queries.
这是无效使用SQL工具的一个示例,我们不建议在查询中使用它。
All of the above features will make your life easier when writing queries and increase the quality and readability of your code.
上述所有功能将使编写查询时的工作变得更轻松,并提高代码的质量和可读性。
第2部分
视窗功能 (Part 2
Window Functions)
Window functions appeared in Microsoft SQL Server 2005. They perform calculations on a given range of rows within a SELECT clause. In short, a “window” is a set of rows where computation takes place. “Window” allows us to reduce the data and process it better. Such a feature allows us to split the entire dataset into windows.
窗口函数出现在Microsoft SQL Server 2005中。它们对SELECT子句中给定范围的行执行计算。 简而言之,“窗口”是一组进行计算的行。 “窗口”使我们可以减少数据并更好地处理它。 这样的功能使我们可以将整个数据集拆分为多个窗口。
Window functions have a huge advantage. There is no need to form a data set for calculations, which allows us to save all the data set rows with their unique ID. The result of the window functions operation is added to the resulting selection in one more field.
窗口功能具有巨大的优势。 无需形成用于计算的数据集,这使我们能够使用其唯一ID保存所有数据集行。 窗口功能操作的结果将在另一个字段中添加到结果选择中。
Syntax:
句法:
SELECT column_name(s) Aggregate function (column for calculation) OVER ([PARTITION BY column to the group] FROM table_name [ORDER BY column to sort] [ROWS or RANGE to delimit rows within a group])OVER PARTITION BY is a property to define a window size. Here you can specify additional information; for example, a row number.
OVER PARTITION BY是定义窗口大小的属性。 您可以在此处指定其他信息。 例如,一个行号。
Let’s consider the following example: another department has been added to our table, now there are 15 rows there. We’ll try to derive employees, their salary, and the maximum salary of the organization.
让我们考虑以下示例:另一个部门已添加到我们的表中,现在那里有15行。 我们将尝试得出员工,他们的薪水和组织的最高薪水。
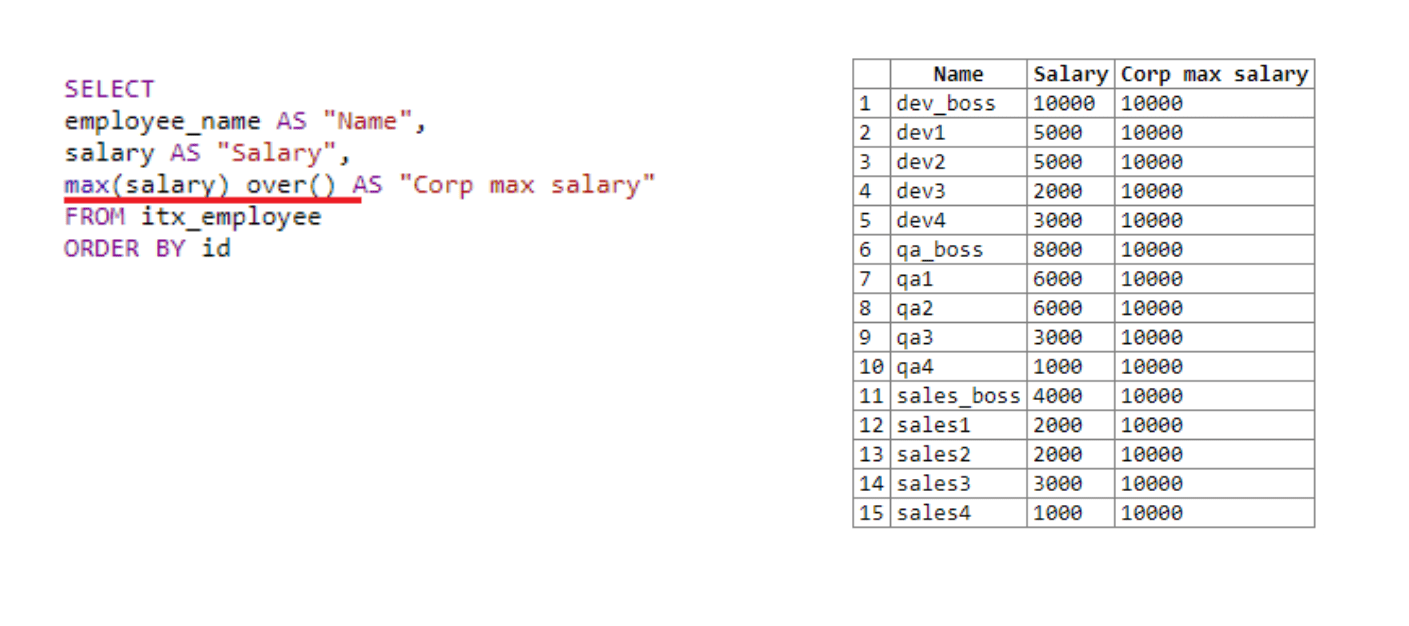
In the first field, we take the name, in the second one — the salary. Next, we use the over () window function to get the maximum salary throughout the organization since the window size is not indicated. Over () with empty brackets applies to the entire selection. Therefore, the maximum salary is 10,000. The result of the window function is added to each line.
在第一个字段中,我们取第二个名字-薪水。 接下来,由于未指定窗口大小,因此我们使用over()窗口函数来获得整个组织的最高薪水。 带有空括号的Over()适用于整个选择。 因此,最高工资为10,000。 窗口函数的结果将添加到每一行。
If we remove the mention of the window function from the fourth line of the query, i.e., only max (salary) remains, the query will not work. The maximum salary simply could not be calculated. Since the data would be processed line by line, and at the time of calling max (salary), there would be only one value of the current row, i.e., of the current employee. That is where you can see the advantage of the window function. At the time of the call, it works with the entire window and with all data available.
如果我们从查询的第四行中删除对窗口函数的提及,即仅保留max(薪水) ,则该查询将无法工作。 最高工资根本无法计算。 由于将逐行处理数据,并且在调用max(salary)时 ,当前行(即当前员工)只有一个值。 在那可以看到窗口功能的优势。 在通话时,它适用于整个窗口以及所有可用数据。
Let’s consider another example where we need to get the maximum salary of each department:
让我们考虑另一个示例,我们需要获取每个部门的最高薪水:
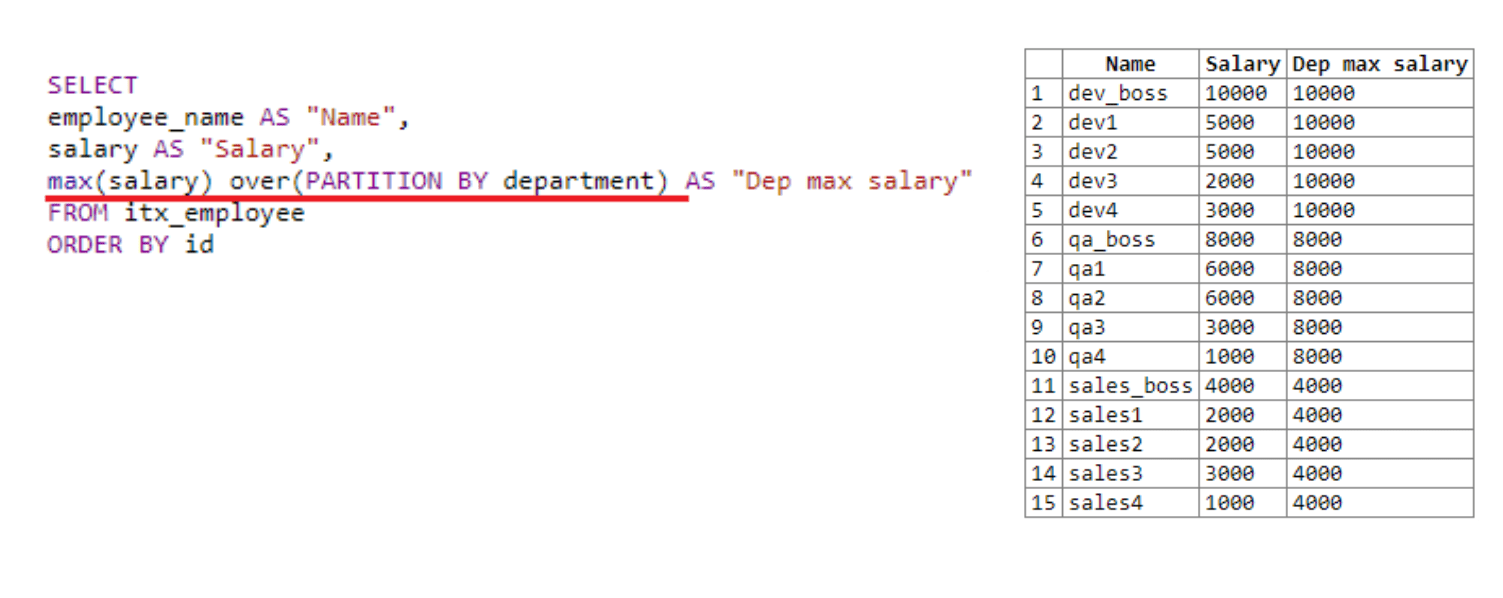
Here we set the frames for the window (set of rows on which window function operates), dividing it into departments. We have three departments: dev, QA, and sales.
在这里,我们设置窗口的框架(窗口功能在其上运行的行集),将其划分为多个部门。 我们有三个部门:开发部门,质量保证部门和销售部门。
The window finds the maximum salary for each department. As a result of the selection, we see that it found the maximum salary for dev first, then for QA, and then for sales. As mentioned above, the result of the window function is written in each row’s fetch result.
该窗口查找每个部门的最高工资。 通过选择,我们发现它找到了开发人员的最高薪水,然后是质量检查,然后是销售。 如上所述,窗口函数的结果写入每行的获取结果中。
That’s how PARTITION BY works.
这就是PARTITION BY的工作方式。
结论 (Conclusion)
SQL is not as simple as it seems at first glance. Everything described above is the basic functionality of window functions. With their help, you can “simplify” your queries. But there is much more potential hidden in them: there are utility clauses (for example, ROWS or RANGE) that can be combined to add more functionality to queries.
SQL并不像乍看起来那样简单。 上述所有内容都是窗口功能的基本功能。 在他们的帮助下,您可以“简化”查询。 但是它们中隐藏着更多的潜力:可以将实用程序子句(例如,ROWS或RANGE)组合在一起,为查询添加更多功能。
I hope the post was useful for everyone interested in the topic.
我希望该帖子对对此主题感兴趣的每个人都有用。
Originally published at https://www.intexsoft.com on August 31, 2020.
最初于 2020年8月31日 在 https://www.intexsoft.com 上 发布 。

















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









