






灵感:GPT-3 (Inspiration: GPT-3)
In June of 2020, OpenAI launched their new model GPT-3, which not only has futuristic NLP(Natural Language Processing) capabilities, but was also able to generate React code and simplify command-line commands.
2020年6月,OpenAI推出了他们的新模型GPT-3,该模型不仅具有未来派的NLP(自然语言处理)功能,而且还能够生成React代码并简化命令行命令 。
Looking at these demos was a huge inspiration for us and we realized that while doing data analysis, a lot of times, we often forget less-used pandas or plotly syntax and need to search for it. Copying the code from StackOverflow then requires modifying the variables and column names accordingly. We started exploring for something which generates ready-to-execute code for human queries like:
观看这些演示对我们来说是一个巨大的灵感,我们意识到,在进行数据分析时,很多时候, 我们经常会忘记使用较少的熊猫或绘图语法,而需要进行搜索 。 然后,从StackOverflow复制代码需要相应地修改变量和列名。 我们开始探索可以为人工查询生成易于执行的代码的东西,例如:
show rainfall and humidity in a heatmap from dataframe df
在数据框df的热图中显示降雨量和湿度
or
要么
group df by state and get average & maximum of user_age
按状态对df分组,并获得user_age的平均值和最大值
Snippets was one such extension we used for some time but after a certain number of snippets, the UI becomes unintuitive. While it is good for static templates, we needed something more to handle dynamic nature of our use-case.
片段是我们使用了一段时间的扩展,但是经过一定数量的片段后,UI变得不直观。 尽管这对于静态模板很有用,但我们还需要更多东西来处理用例的动态性质。
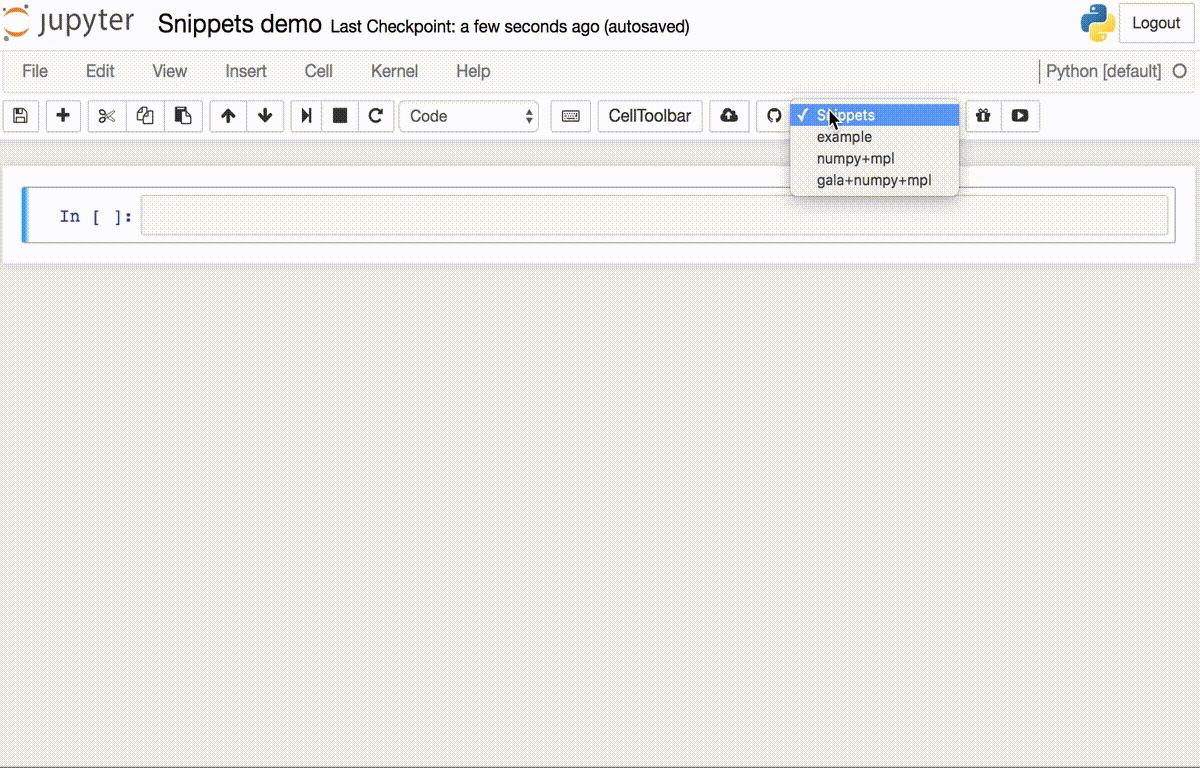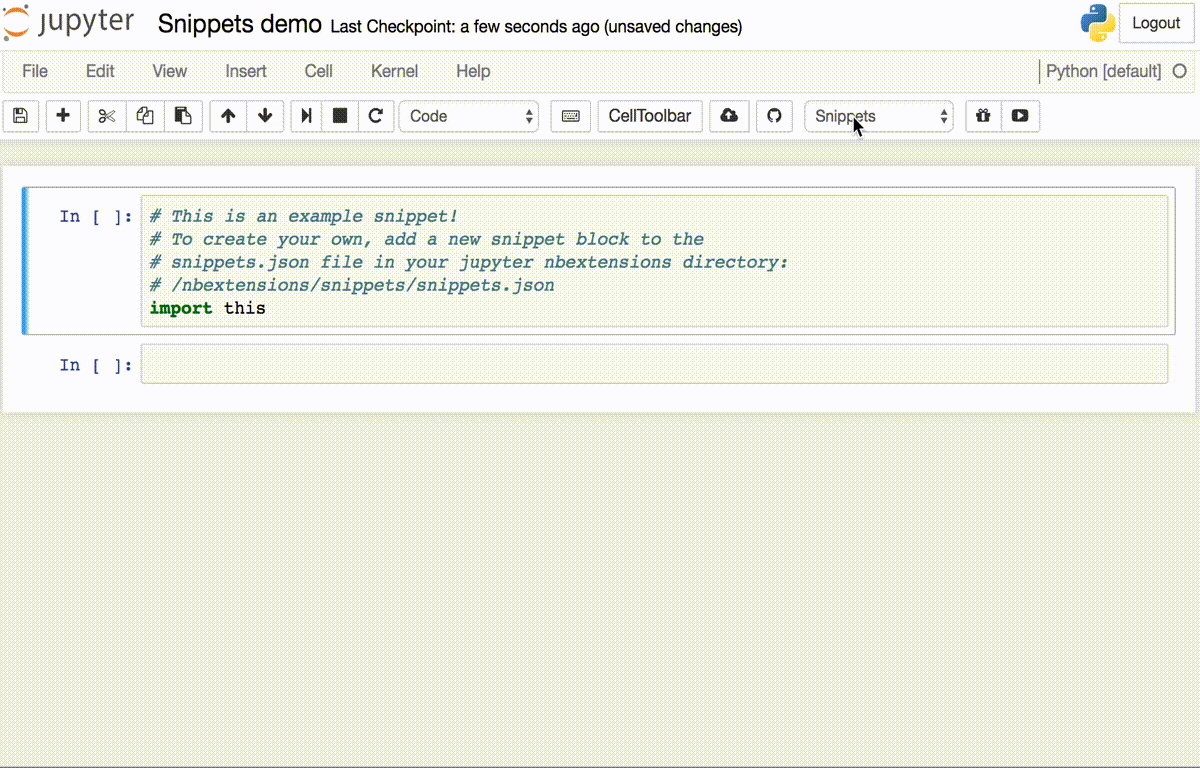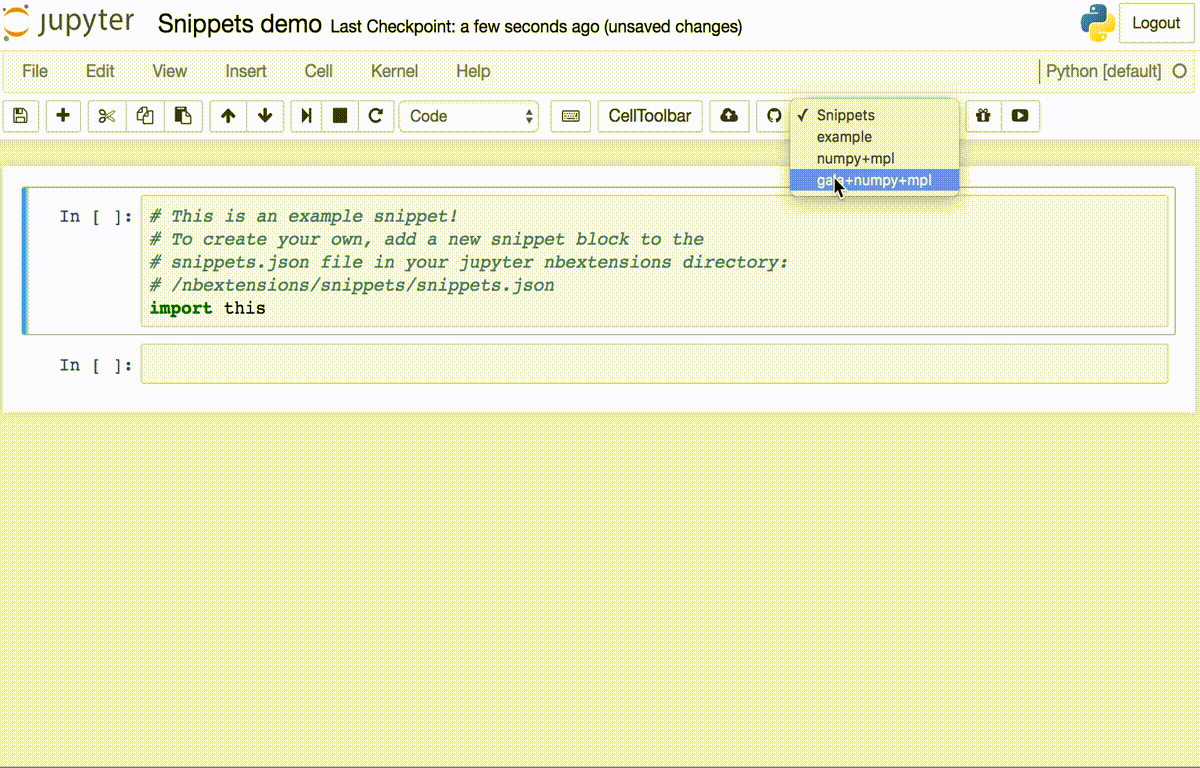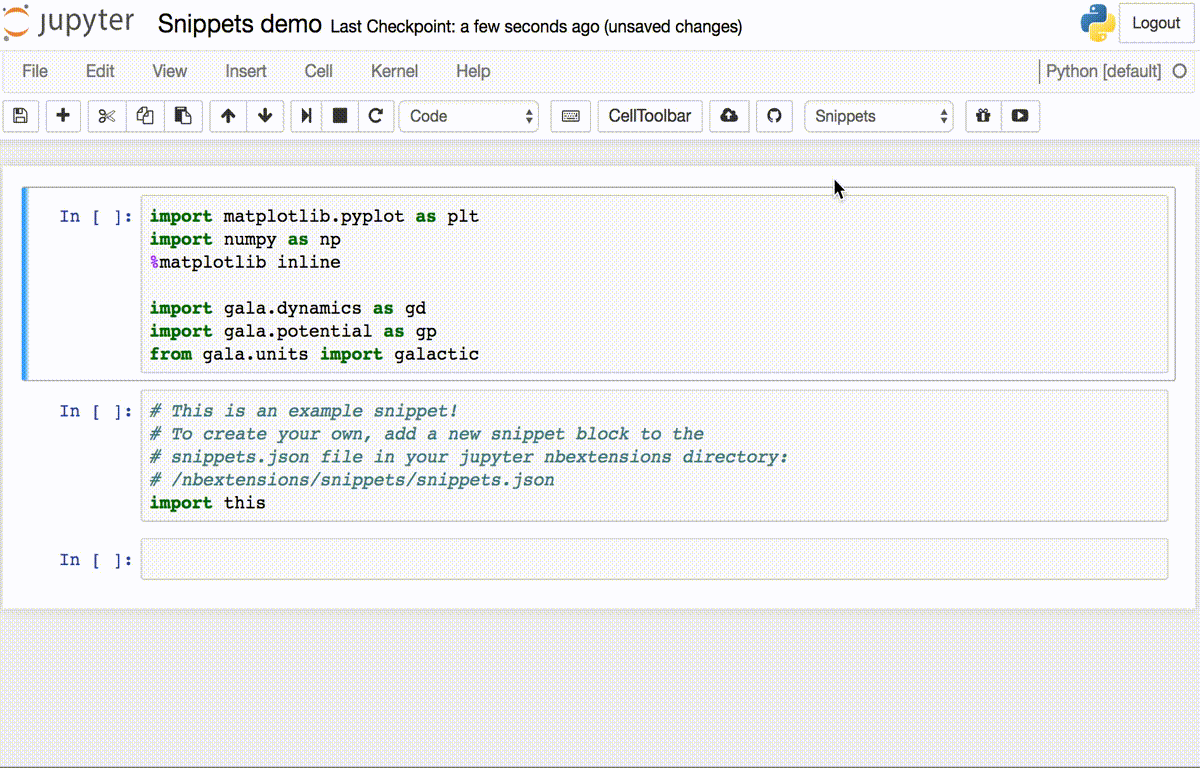
We decided to attempt building a new jupyter extension for this purpose. Unfortunately, we didn’t have beta access to GPT-3, so using that amazing model wasn’t an option.
为此,我们决定尝试构建一个新的jupyter扩展。 不幸的是,我们没有GPT-3的Beta版访问权限,因此无法选择使用该出色的模型。
简化任务: (Simplifying the task:)
We wanted to build something which runs on our desktops (with GPUs). We initially tried treating the problem as a chat-bot problem and started with Rasa but were soon stopped short due to lack of proper training data.
我们想构建一些可以在台式机(带有GPU)上运行的东西。 我们最初尝试将问题视为聊天机器人问题,并从Rasa开始,但由于缺乏适当的培训数据而很快就停了下来。
Having failed to build a truly generative model, we decided to develop a supervised model which can work for the use-cases defined in the training pipeline and could be easily extended. Taking inspiration from chatbot pipelines, we decided to simplify the problem into the following components:
由于未能建立真正的生成模型,我们决定开发一种监督模型,该模型可以适用于培训管道中定义的用例,并且可以轻松扩展。 从chatbot管道中获得启发,我们决定将问题简化为以下组件:
- Generate / Gather training data 生成/收集训练数据
- Intent matching: What is it that the user wants to do? 意图匹配:用户想要做什么?
- NER(Named Entity Recognition): Identify variables(entities) in the sentences NER(命名实体识别):识别句子中的变量(实体)
- Fill Template: Use extracted entities in a fixed template to generate code 填充模板:在固定模板中使用提取的实体来生成代码
- Wrap inside jupyter extension 包装在jupyter扩展内部
生成训练数据: (Generating training data:)
In order to simulate what end “users” are going to query to the system, we started with some formats we thought we ourselves use to describe the command in English. For example:
为了模拟最终“用户”要向系统查询的内容,我们从一些我们认为自己用来用英语描述命令的格式开始。 例如:
display a line plot showing $colname on y-axis and $colname on x-axis from $varname
显示示出从$ varname的上y轴$ colname的和$ colname的上x轴的线图
Then, we generate variations by using a very simple generator to replace $colname and $varname to get variations in the training set.
然后,我们使用非常简单的生成器替换$ colname和$ varname来生成变体,以获取训练集中的变体。

意向匹配: (Intent Matching:)
After having generated the data, which is mapped with a unique “intent_id” for specific intents, we then used Universal Sentence Encoder to get embeddings of the user query and find cosine similarity with our predefined intent queries(generated data). Universal Sentence Encoder is similar to word2vec which generates embeddings, but for sentences instead of words.
生成数据后,将其映射为用于特定意图的唯一“ intent_id”,然后,我们使用通用语句编码器获取用户查询的嵌入,并找到与我们预定义的意图查询(生成的数据)的余弦相似度。 Universal Sentence Encoder类似于word2vec ,它生成嵌入,但用于句子而不是单词。

NER(命名实体识别): (NER(Named Entity Recognition):)
The same generated data could be then used to train a custom entity recognition model, which could detect column, variable, library names. For this purpose, we explored HuggingFace models but ended up using Spacy to train a custom model, primarily because HuggingFace models are transformer based models and are a bit heavy as compared to Spacy.
然后,可以使用相同的生成数据来训练自定义实体识别模型,该模型可以检测列,变量,库名称。 为此,我们探索了HuggingFace模型,但最终使用Spacy训练了自定义模型,这主要是因为HuggingFace模型是基于变压器的模型,并且与Spacy相比有些笨重。

填充模板: (Fill Template:)
Filling a template is very easy once the entities are correctly recognized and intents are correctly matched. For example, “show 5 rows from df” query would result in two entities: a variable and a numeric. Template code for this was straightforward to write.
一旦正确识别实体并且正确匹配意图,填充模板就非常容易。 例如,“显示df中的5行”查询将产生两个实体:变量和数字。 模板代码很容易编写。

与Jupyter集成: (Integrate with Jupyter:)
Suprisingly, this one turned out to be the most complex of all, as it is slightly tricky to write such complex extensions for Jupyter and there is little documentation or examples available (as compared to other libraries like HuggingFace or Spacy). With some trial and errors, and a bit of copy-paste from already existing extensions, we were finally able to wrap everything around as a single python package, which could be installed via pip install
令人惊讶的是,事实证明这是所有程序中最复杂的,因为为Jupyter编写如此复杂的扩展有点棘手,而且几乎没有文档或示例(与其他类似HuggingFace或Spacy的库相比)。 经过一些试验和错误,以及已经存在的扩展中的一些复制粘贴,我们终于能够将所有内容包装为单个python软件包,可以通过pip install
We had to create a frontend as well as a server extension which gets loaded when jupyter notebook is triggered. Frontend sends the query to server to get the generated template code and then inserts it in the cell and executes it.
我们必须创建一个前端以及一个服务器扩展,该服务器扩展会在触发jupyter notebook时加载。 前端将查询发送到服务器以获取生成的模板代码,然后将其插入单元格中并执行它。
演示: (Demo:)
The demo video was prepared on Chai Time Data Science dataset by Sanyam Bhutani.
该演示视频由Sanyam Bhutani在Chai Time Data Science数据集上准备。
局限性: (Limitations:)
Like with many ML models, sometimes intent matching and NER fail miserably, even when the intent is obvious to the human eye. Some of the areas we could attempt to improve the situation are:
与许多ML模型一样,有时即使意图对人眼来说,意图匹配和NER也会惨败。 我们可以尝试改善情况的一些领域是:
Gather/Generate higher-quality English sentence training data.
Paraphrasingis one technique we haven’t tried yet to generate different ways of speaking the same sentence.收集/生成高质量的英语句子训练数据。
Paraphrasing是我们尚未尝试产生不同的说同一句话的方式的一种技术。- Gather real-world variable names, library names as opposed to randomly generating them. 收集实际的变量名,库名,而不是随机生成它们。
- Try NER with a transformer-based model. 使用基于变压器的模型尝试NER。
- With enough data, train a language model to directly do English->code like GPT-3 does, instead of having separate stages in the pipeline. 有了足够的数据,就可以训练语言模型来像GPT-3一样直接执行英语->代码,而不必在管道中进行单独的处理。
That’s all folks!
那是所有人!
I hope you enjoyed reading the article. The entire code for the extension, which is ready-to-install on a local GPU machine is available here.
希望您喜欢阅读本文。 为扩展整个代码,这是准备安装的本地GPU机上是可以在这里找到 。
Deepak and I hacked this together over a couple of weekends. The code is not production-ready but good enough for people to modify and use for their own. We would love to hear feedback and ideas for improvement. :)
迪帕克(Deepak)和我在两个周末共同破解了这个问题。 该代码尚未投入生产,但足以让人们修改和使用。 我们希望听到反馈和改进意见。 :)
翻译自: https://towardsdatascience.com/data-analysis-made-easy-text2code-for-jupyter-notebook-5380e89bb493















 573
573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









