





kafka流式数据可视化
在Spark中使用的简介 (Introduction to working with(in) Spark)
After the previous post wherein we explored Apache Kafka, let us now take a look at Apache Spark. This blog post covers working within Spark’s interactive shell environment, launching applications (including onto a standalone cluster), streaming data and lastly, structured streaming using Kafka. To get started right away, all of the examples will run inside Docker containers.
在上一篇探讨Apache Kafka的文章之后,现在让我们看一下Apache Spark。 这篇博客文章介绍了在Spark的交互式Shell环境中工作,启动应用程序(包括在独立集群中),流数据以及使用Kafka进行结构化流。 为了立即开始,所有示例都将在Docker容器中运行。
火花 (Spark)

Spark was initially developed at UC Berkeley’s AMPLab in 2009 by Matei Zaharia, and open-sourced in 2010. In 2013 its codebase was donated to the Apache Software Foundation which released it as Apache Spark in 2014.
Spark最初由Matei Zaharia于2009年在加州大学伯克利分校的AMPLab开发,并于2010年开源。2013年,其代码库捐赠给了Apache软件基金会,该基金会于2014年以Apache Spark的形式发布。
“Apache Spark™ is a unified analytics engine for large-scale data processing”
“ Apache Spark™是用于大规模数据处理的统一分析引擎”
It offers APIs for Java, Scala, Python and R. Furthermore, it provides the following tools:
它提供了Java,Scala,Python和R的API。此外,它还提供了以下工具:
Spark SQL: used for SQL and structured data processing.
Spark SQL :用于SQL和结构化数据处理。
MLib: used for machine learning.
MLib :用于机器学习。
GraphX: used for graph processing.
GraphX :用于图形处理。
Structured Streaming: used for incremental computation and stream processing.
结构化流 :用于增量计算和流处理。
Prerequisites:This project uses Docker and docker-compose. View this link to find out how to install them for your OS.
先决条件:该项目使用Docker和docker-compose。 查看此链接以了解如何为您的操作系统安装它们。
Clone my git repo:
克隆我的git repo:
git clone https://github.com/Wesley-Bos/spark3.0-examples.gitNote: depending on your pip and Python version, the commands vary a little:
注意: 根据您的pip和Python版本,命令会有所不同:
pip becomes pip3
点变成pip3
python become python3
python成为python3
Before we begin, create a new environment. I use Anaconda to do this but feel free to use any tool of your liking. Activate the environment and install the required libraries by executing the following commands:
在开始之前,请创建一个新环境。 我使用Anaconda来执行此操作,但是可以随意使用任何您喜欢的工具。 通过执行以下命令来激活环境并安装所需的库:
pip install -r requirements.txtBe sure to activate the correct environment in every new terminal you open!
确保在 您打开的 每个 新 终端中 激活正确的环境 !
1. Spark交互式外壳 (1. Spark interactive shell)
Run the following commands to launch Spark:
运行以下命令以启动Spark:
docker build -t pxl_spark -f Dockerfile .docker run --rm --network host -it pxl_spark /bin/bashExecuting code, in Spark, can be performed within the interactive shell or by submitting the programming file directly to Spark, as an application, using the command spark-submit.
在Spark中执行代码可以在交互式外壳中执行,也可以使用命令spark-submit将编程文件作为应用程序直接提交给Spark。
To start up the interactive shell, run the command below:
要启动交互式shell,请运行以下命令:
pysparkThis post centres on working with Python. However, if you desire to work in Scala, use spark-shell instead.
这篇文章的重点是使用Python。 但是,如果您希望在Scala中工作,请改用spark-shell。
Try out these two examples to get a feeling with the shell environment.
尝试这两个示例,以了解shell环境。
Read a .csv file:
读取.csv文件:
>>> file = sc.textFile(“supplementary_files/subjects.csv”)
>>> file.collect()
>>> file.take(AMOUNT_OF_SAMPLES)>>> subjects = file.map(lambda row: row.split(“,”)[0])
>>> subjects.collect()Read a text file:
读取文本文件:
>>> file = sc.textFile(“supplementary_files/text.txt”)
>>> file.collect()
>>> file.take(2)>>> wordCount = file.flatMap(lambda text: text.lower().strip().split(“ “)).map(lambda word: (word, 1)).reduceByKey(lambda sum_occurences, next_occurence: sum_occurences+next_occurence)>>> wordCount.collect()Press Ctrl+d to exit the shell.
按Ctrl + d退出外壳。
2. Spark应用程序—在集群上启动 (2. Spark application — launching on a cluster)
Spark applications can be performed by itself or on a cluster. The most straightforward approach is deploying Spark on a private cluster.
Spark应用程序可以单独执行,也可以在集群上执行。 最直接的方法是在专用集群上部署Spark。
Follow the instructions below to execute an application on a cluster.
请按照以下说明在集群上执行应用程序。
Initiate the Spark container:
启动Spark容器:
docker run --rm --network host -it pxl_spark /bin/bashStart a master:
启动大师:
start-master.shGo to the web UI and copy the URL of the Spark Master.
转到Web UI,然后复制Spark Master的URL。
Start a worker:
开始工作:
start-slave.sh URL_MASTERReload the web UI; a worker should be added.
重新加载Web UI; 应该增加一个工人。
Launch an example onto the cluster:
在集群上启动一个示例:
spark-submit --master URL_MASTER examples/src/main/python/pi.py 10View the web UI; an application has now been completed.
查看网页界面; 申请已完成。
Consult the official documentation for more specific information.
有关更多特定信息,请查阅官方文档 。
3. Spark应用程序-流数据 (3. Spark application — streaming data)
The above examples solely handled stationary code. The subsequent cases entail streaming data along with five DStream transformations to explore.
以上示例仅处理固定代码。 随后的情况需要流数据以及要探索的五个DStream转换。
Note that these transformations are a mere glimpse of the viable options. View the official documentation for additional information regarding pyspark streaming.
请注意,这些转换只是可行选项的一瞥。 查看 官方文档 以获取有关pyspark流的其他信息。
In a separate terminal, run the netcat command on port 8888:
在另一个终端中,在端口8888上运行netcat命令:
nc -lC 8888In the Spark container, submit one of the cases for DStreams. Beneath is a summary of what each code sample does.
在Spark容器中,提交DStreams的一种情况。 下面是每个代码示例的摘要。
reduce_by_key.py: count the occurrence of the word ‘ERROR’, per batch.
reduce_by_key.py : 每批计算单词“ ERROR”的出现。
update_by_key.py: count the occurrence of all the words throughout a stream of data.
update_by_key.py :统计整个数据流中所有单词的出现。
count_by_window.py: count the number of lines within a window.
count_by_window.py :计算窗口中的行数。
reduce_by_window.py: calculate the sum of the values within a window.
reduce_by_window.py :计算窗口内值的总和。
reduce_by_key_and_window.py: count the occurrence of ERROR-messages within a window.
reduce_by_key_and_window.py :计算窗口中ERROR消息的发生。
Enter text data inside the netcat terminal. In the Spark terminal, the data is displayed accordingly. An example can be seen in the images below.
在netcat终端中输入文本数据。 在Spark终端中,将相应显示数据。 下图显示了一个示例。
spark-submit python_code_samples/update_by_key.py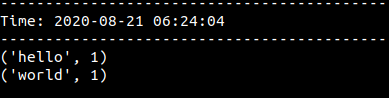

4. Spark结构化流 (4. Spark structured streaming)
Lastly, there is structured streaming. A concise, to the point, description of structured streaming reads: “Structured Streaming provides fast, scalable, fault-tolerant, end-to-end exactly-once stream processing without the user having to reason about streaming.”
最后,是结构化的流媒体。 简而言之,对结构化流的描述为: “结构化流提供了快速,可伸缩,容错,端到端的一次精确流处理,而用户无需推理流。”
The objective of this last section is to ingest data into Kafka, access it in Spark and finally write it back to Kafka.
最后一部分的目的是将数据吸收到Kafka中,在Spark中访问它,最后将其写回到Kafka。
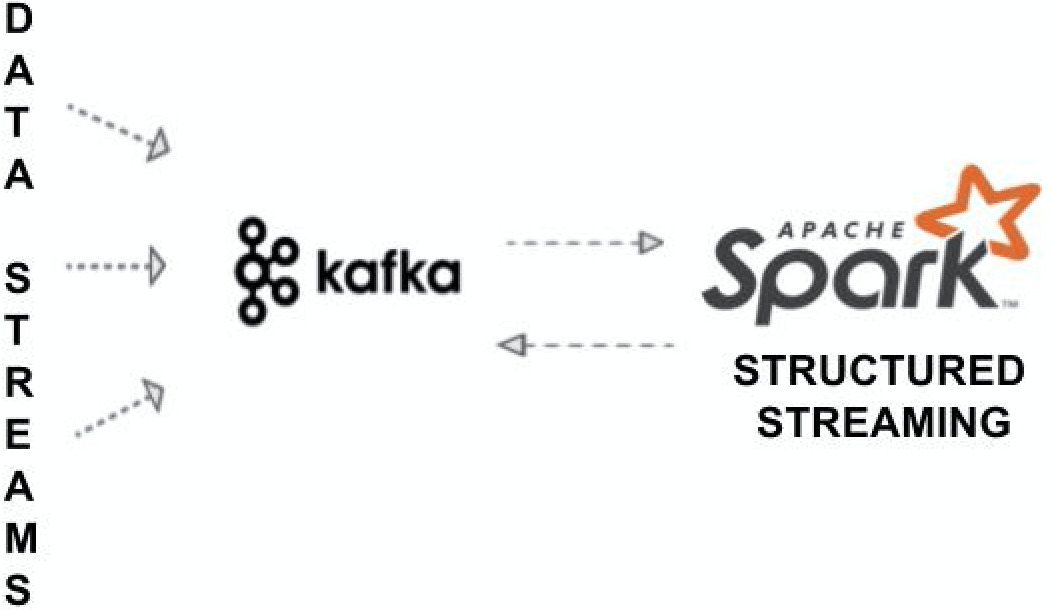
Launch the Kafka environment:
启动Kafka环境:
docker-compose -f ./kafka/docker-compose.yml up -dProduce and consume data:
产生和使用数据:
For convenience, open two terminal beside each other.
为方便起见,请打开两个彼此相邻的端子。
python kafka/producer.pypython kafka/consumer.pySubmit the application to Spark (inside the Spark container):
将应用程序提交到Spark(在Spark容器内部):
spark-submit --packages org.apache.spark:spark-sql-kafka-0–10_2.12:3.0.0 python_code_samples/kafka_structured_stream.pyOpen a new terminal and start the new_consumer:
打开一个新终端并启动new_consumer:
python kafka/new_consumer.pyIn the producer terminal, enter data; both consumers will display this data. The messages can be seen in the Confluent Control centre as well.
在生产者终端中,输入数据; 两个使用者都将显示此数据。 这些消息也可以在Confluent控制中心中看到。
回顾 (Recap)
Throughout this article, we explored the following issues:
在本文中,我们探讨了以下问题:
- Reading files within the interactive shell. 在交互式外壳中读取文件。
- Launching an application; by itself and on a cluster. 启动一个应用程序; 本身和群集上。
- Working with streaming data. 处理流数据。
- Working with structured streaming. 使用结构化流。
An interesting blog post from Databricks gives a more extensive view of structure streaming. This particular post explains how to utilise Spark to consume and transform data streams from Apache Kafka.
Databricks的一篇有趣的博客文章提供了结构流的更广泛视图。 这篇特别的文章介绍了如何利用Spark来使用和转换Apache Kafka中的数据流。
Lastly, I want to thank you for reading until the end! Any feedback on where and how I can improve is much appreciated. Feel free to message me.
最后,感谢您的阅读直到最后! 非常感谢您对我在哪里以及如何改进的任何反馈。 随时给我发消息。
翻译自: https://medium.com/@wesleybos99/structured-streaming-in-spark-3-0-using-kafka-db44cf871d7a
kafka流式数据可视化















 2051
2051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









