





无序查找算法
In this article, we mainly discuss how the sorting algorithm makes unordered records orderly.
在本文中,我们主要讨论排序算法如何使无序记录井然有序。
Sorting is the operation of arranging an array of records in increasing or decreasing order according to the size of one or more keywords
排序是根据一个或多个关键字的大小以升序或降序排列记录数组的操作
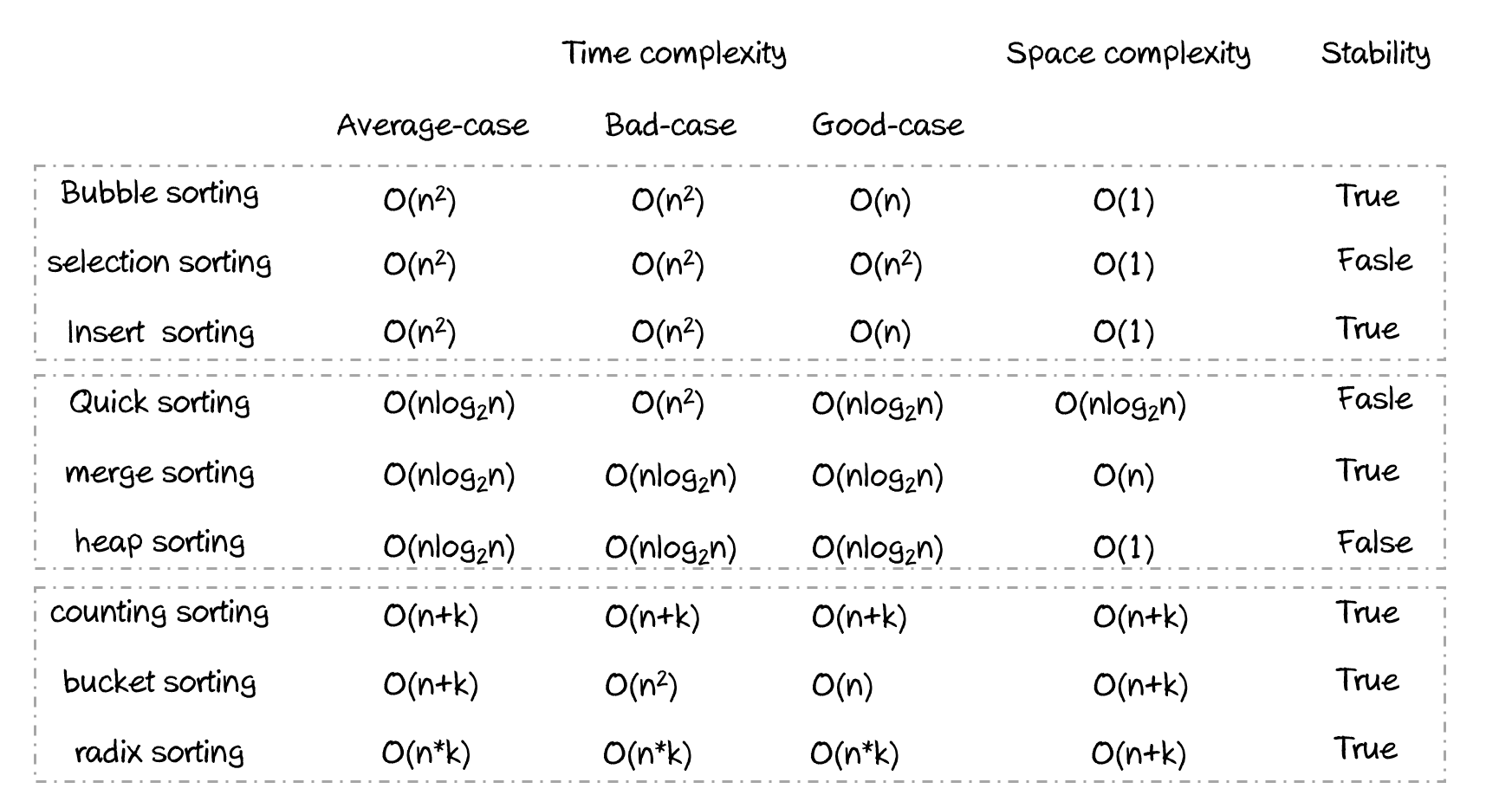
O(n²)排序算法(O(n²) sorting algorithms)
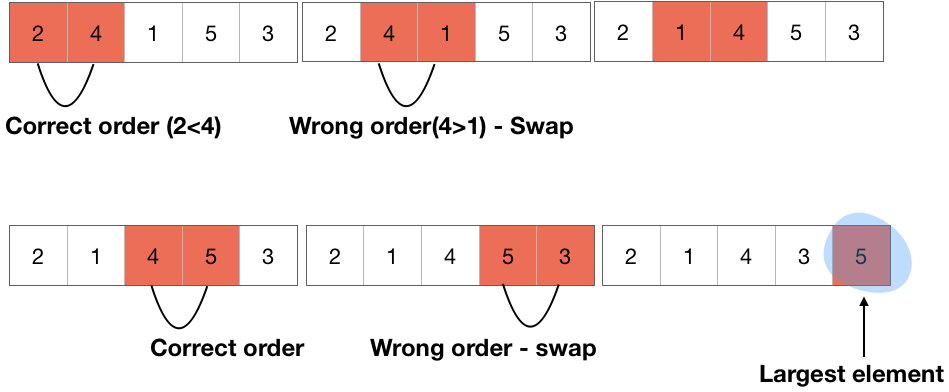
气泡排序(Bubble sort)
If the length of the array is n, then will be comparing n-1 loop. Each loop compares adjacent elements. If the first one is bigger than the second one, swap the two.
如果数组的长度为n,则将比较n-1循环。 每个循环比较相邻的元素。 如果第一个大于第二个,则交换两个。
def bubble_sort(arr:list):
'''
1. loop count = len(listing)-1
2. Each cycle compares and exchanges the internal elements pairwise
'''
print(f'before:{arr}')
for i in range(1,len(arr)):
for j in range(0,len(arr)-i):
if arr[j] >arr[j+1]:
arr[j],arr[j+1]=arr[j+1],arr[j]
print(f'after:{arr}')
'''
before:[1, 3, 8, 12, 9, 33, 5, 6, 35, 23]
after:[1, 3, 5, 6, 8, 9, 12, 23, 33, 35]
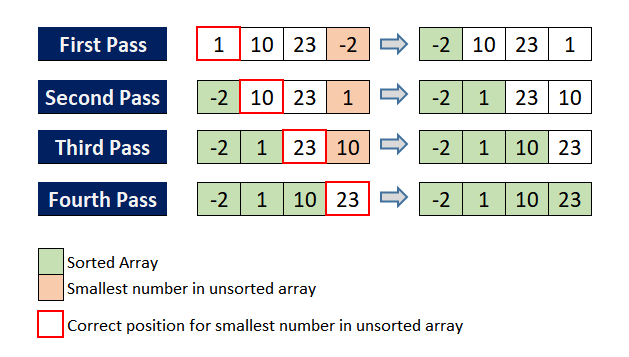
'''选择排序(Selection Sort)
First find the smallest element in the unsorted sequence and store it at the beginning of the sorted sequence. Then continue to find the smallest element from the remaining unsorted elements, and then put it at the end of the sorted sequence.
首先找到未排序序列中的最小元素,并将其存储在排序序列的开头。 然后继续从剩余的未排序元素中找到最小的元素,然后将其放在排序序列的末尾。
def selection_sort(arr:list):
print(f'before:{arr}')
for i in range(0,len(arr)-1):
minidx=i
for j in range(i+1,len(arr)):
if arr[j]<arr[minidx]:
minidx=j
if i != minidx:
arr[i],arr[minidx]=arr[minidx],arr[i]
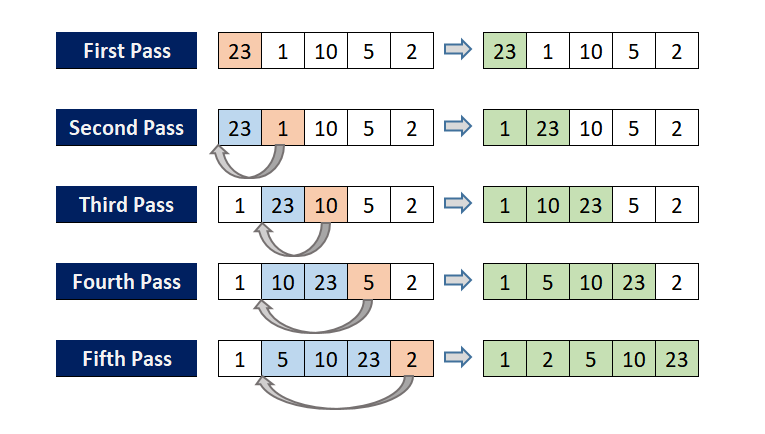
print(f'after:{arr}')插入排序(Insert Sort)
The first element of the first sequence to be sorted is regarded as an ordered sequence, and the second element to the last element are regarded as an unsorted sequence. Scan the unsorted sequence from beginning to end, insert each element into the proper position of the ordered sequence.
要排序的第一个序列的第一个元素被视为有序序列,而最后一个元素的第二个元素被视为未排序的序列。 从头到尾扫描未排序的序列,将每个元素插入有序序列的正确位置。
What is the proper position of the ordered sequence? Extract the first element which needs to insert, and compare it with the elements in the ordered sequence from back to front. If the element in the ordered sequence is larger than the element to be inserted, move the element back one position (this position is the vacancy when the first element which needs to insert left over after extraction). Until an element(in ordered sequence) is smaller than the element which needs to be inserted, and put the element behind the element(which in ordered sequence).
有序序列的正确位置是什么? 提取需要插入的第一个元素,并将其与按顺序从后到前的元素进行比较。 如果有序序列中的元素大于要插入的元素,则将元素移回一个位置(此位置是提取后第一个需要插入的元素遗留的空位)。 直到一个元素(按顺序排列)小于需要插入的元素,然后将该元素放在该元素(按顺序排列)之后。
def insert_sort(arr:list):
'''
sequence: [1,2,8,4,7,6,9]:
index: 0,1,2,3,4,5,6
ordered: 1,2,8
unordered: 4,7,6,9
extract 4 (idx=3), and the vacancy 4 leftover will be filled by 8(idx=2)
each loop, push the larger one in ordered sequence back to vacancy,
until find a position element(first one of unordered) insert in
'''
print(f'before:{arr}')
for i in range(0,len(arr)):
preidx=i-1
current=arr[i]
while preidx>0 and arr[preidx]>current:
arr[preidx+1]=arr[preidx]
preidx-=1
arr[preidx+1]=current
print(f'after:{arr}')O(n log n)排序算法(O(n log n) sorting algorithms)
快速排序(Quick Sort)
Quicksort (sometimes called partition-exchange sort) is an efficient sorting algorithm. Developed by British computer scientist Tony Hoare in 1959 and published in 1961, and it is still a commonly used algorithm for sorting. When implemented well, it can be about two or three times faster than its main competitors, merge sort and heapsort. — — Qouted from wiki
快速排序(有时称为分区交换排序)是一种有效的排序算法。 由英国计算机科学家Tony Hoare于1959年开发,并于1961年出版,至今仍是一种常用的排序算法。 如果实施得当,它的速度可以比主要竞争对手(合并排序和堆排序)快两到三倍。 — —维基百科(Qouted)
Why Quicksort so fast? Here is the answer.
为什么Quicksort这么快? 这就是答案。
Quick sort is a typical application for the idea of divide and conquer in sorting algorithms. Essentially, quick sort should be regarded as a recursive divide-and-conquer method based on bubble sort.
快速排序是排序算法中分而治之的典型应用。 本质上,快速排序应被视为基于冒泡排序的递归分治方法。
Choosing a good pivot is critical because it will affect the performance of the Quicksort algorithm. Generally speaking, a random pivot will provide O(nlogn) and worst case O(n²). The probability of the worst case is very small, which means that a random selection of pivot is good enough.
选择一个好的关键点很关键,因为它会影响Quicksort算法的性能。 一般而言,随机支点将提供O(nlogn)和最坏情况下的O(n²)。 最坏情况的可能性很小,这意味着对枢轴的随机选择就足够了。
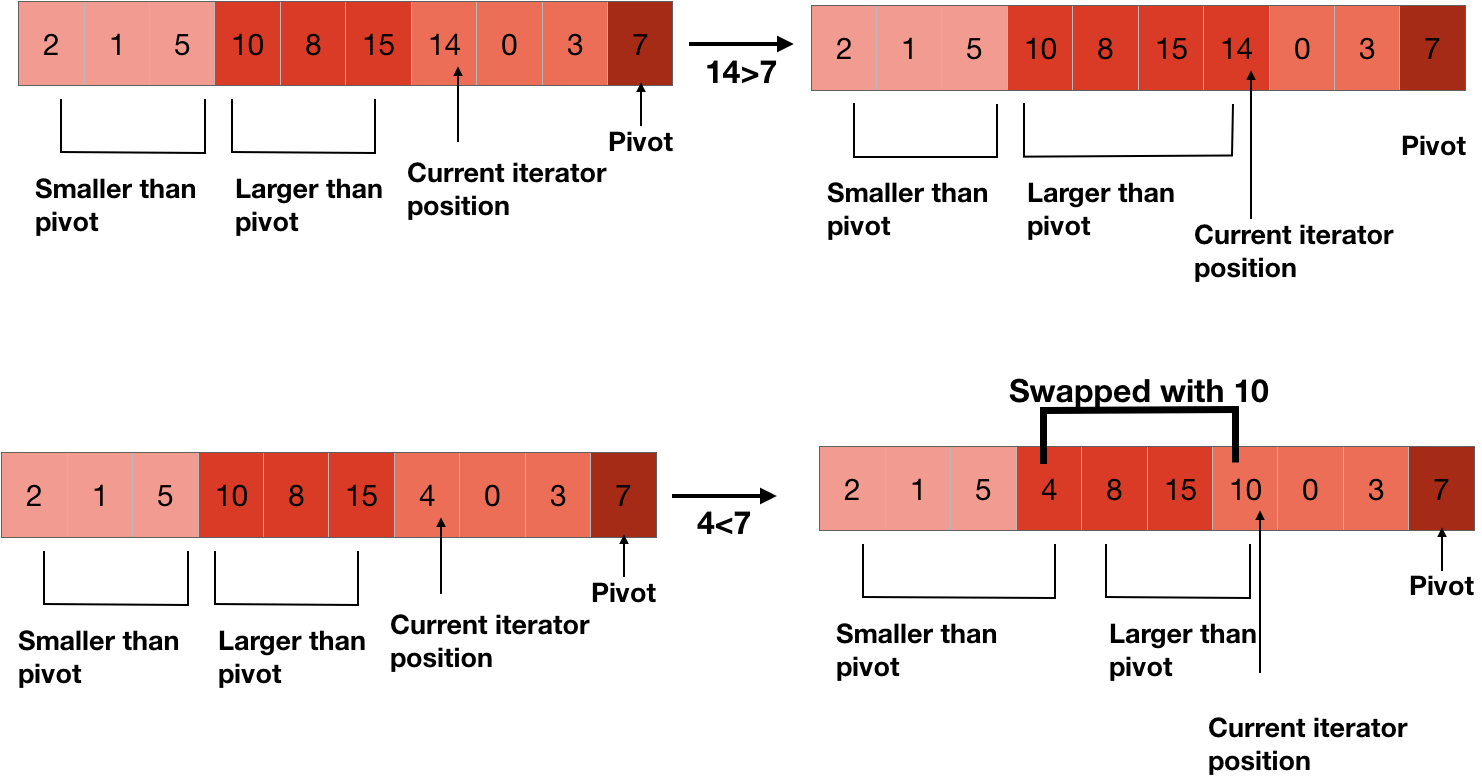
The calculation steps are as follows:
计算步骤如下:
- Pick an element from the sequence and call it a pivot. 从序列中选择一个元素并将其称为枢轴。
- Re-order the sequence, all elements smaller than the pivot are placed in front of the pivot, and all elements larger than the pivot are placed behind the pivot(the same number can go to either side). After the partition exits, the pivot is in the proper position of the sequence. This is called a partition operation. 重新排序顺序,所有小于枢轴的元素都放置在枢轴的前面,所有大于枢轴的元素都放置在枢轴的后面(相同的编号可以移到任一侧)。 分区退出后,枢轴位于序列的正确位置。 这称为分区操作。
- Recursively sort the sub-sequences of elements smaller than the pivot and the sub-sequences of elements greater than the pivot. 递归地排序小于枢轴的元素的子序列和大于枢轴的元素的子序列。
In the example below, I show four partition strategy.
在下面的示例中,我展示了四个分区策略。
def quick_sort(arr:list,low,high):
'''
choosing a good pivot is critical
partition1: first element as pivot
partition2: last element as pivot
partition3: random pivot
partition4: first element as pivot and use two pointer
'''
if len(arr) == 1:
return arr
if low < high:
pi = partition1(arr, low, high)
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, high)
return arr
def partition1(arr, low, high):
'''
pivot is the first element
single pointer to smaller
'''
pivot = arr[low]
i = low + 1
for j in range(low + 1, high + 1):
if arr[j] <= pivot:
arr[i], arr[j] = arr[j], arr[i]
i = i + 1
arr[low], arr[i - 1] = arr[i - 1], arr[low]
return i - 1
def partition2(arr,low,high):
'''
pivot the last element,
single pointer to smaller
'''
i = (low - 1)
pivot = arr[high]
for j in range(low, high):
if arr[j] <= pivot:
i+=1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i+1
def partition3(arr,low,high):
'''
first or last element as pivot,quick sort perform
badly on already sorted (or almost sorted) arrays.
random pivot
single pointer to larger
'''
idx=random.randrange(low,high)
arr[low],arr[idx]=arr[idx],arr[low] # change pivot to first element
return partition1(arr,low,high)
def partition4(arr,low,high):
'''
pivot is the first element
double pointers, one point to smaller,and one point to larger
'''
p_small,p_large=low+1,high
pivot = arr[low]
while True:
while p_small<=p_large and arr[p_large]>=pivot:
p_large-=1
while p_small<=p_large and arr[p_small]<=pivot:
p_small+=1
if p_small<=p_large:
arr[p_small],arr[p_large] = arr[p_large],arr[p_small]
else:
break
arr[low],arr[p_large]=arr[p_large],arr[low]
return p_large
if __name__ == '__main__':
arr=[1,4,9,6,7,3,4,1,12,6,16,19,15,16]
print(f'After:{quick_sort(arr,0,len(arr)-1)}')合并排序(Merge Sort)
Merge sort is an effective sorting algorithm based on merge operations. Like Quicksort, this algorithm is also a typical application for the idea of Divide and Conquer.
合并排序是一种基于合并操作的有效排序算法。 像Quicksort一样,该算法也是分而治之理念的典型应用。
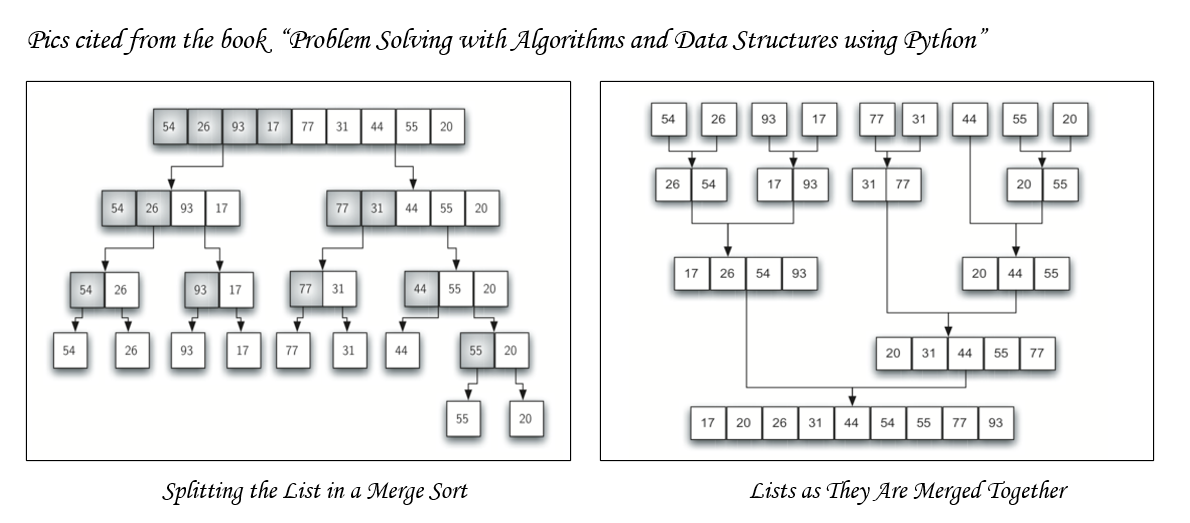
def merge_sort(arr:list):
'''
recursion from head to tail and iteration from tail to head
'''
if (len(arr) < 2):
return arr
middle =len(arr) // 2
left, right = arr[0:middle], arr[middle:]
return merge(merge_sort(left), merge_sort(right))
def merge(left,right):
result = []
while left and right:
if left[0] <= right[0]:
result.append(left.pop(0))
else:
result.append(right.pop(0))
while left:
result.append(left.pop(0))
while right:
result.append(right.pop(0))
return result
if __name__ == '__main__':
arr=[54,26,93,17,77,31,44,55,20]
print(f'After:{merge_sort(arr)}')堆排序(Heap Sort)
Heapsort refers to a sorting algorithm designed using the data structure of the heap. A heap is a binary tree that is completely filled except for the bottom layer, and the value of the child node is always less than (or greater than) its parent node.
堆排序是指使用堆的数据结构设计的排序算法。 堆是一棵二叉树,除底层外已完全填充,并且子节点的值始终小于(或大于)其父节点。
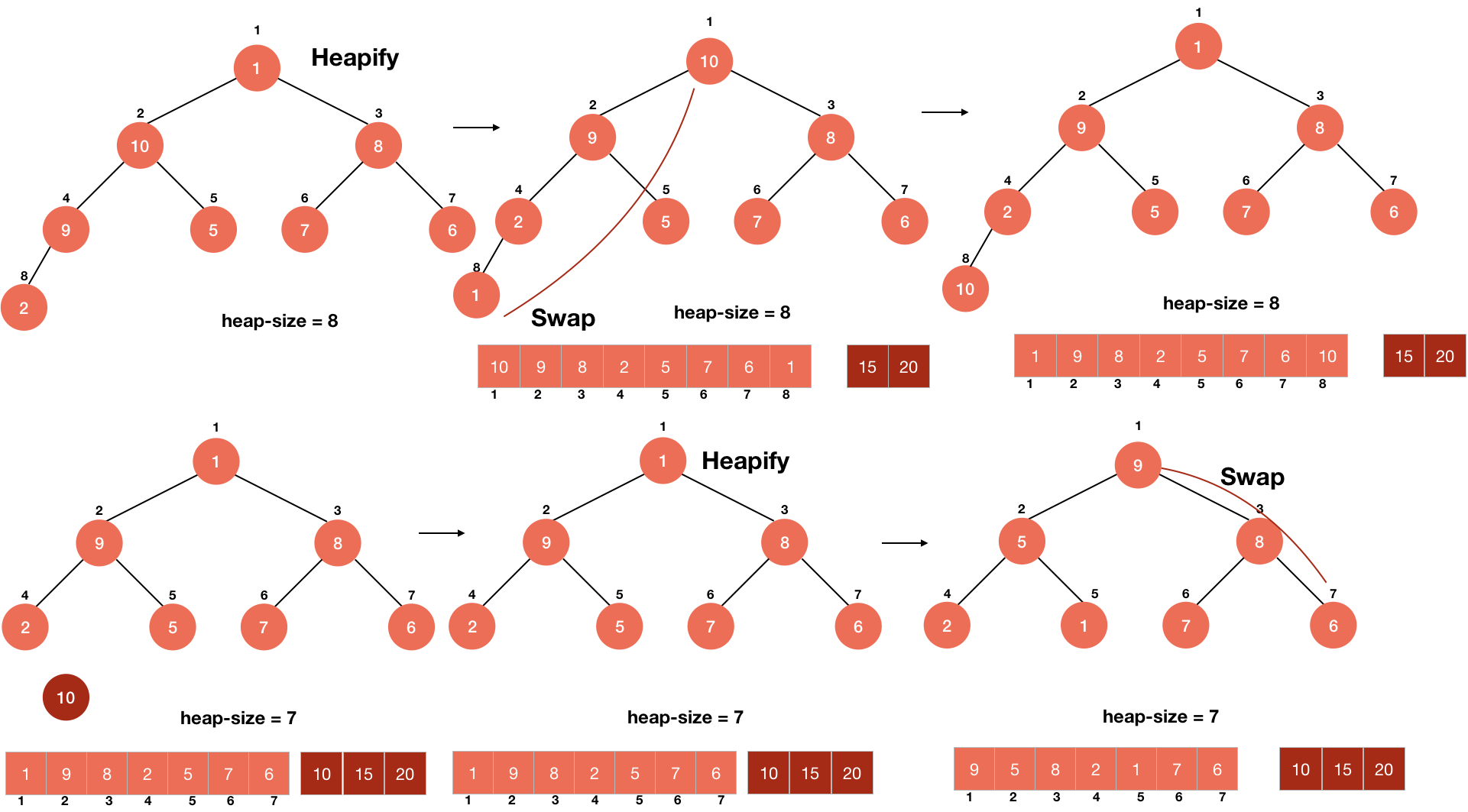
'''
We can refer python bulitin heapq lib
heap.heapify
heap.merge
'''
def heapify(arr,n,i):
root=i
l=2*i+1
r=2*i+2
if l<n and arr[i]<arr[l]:
root=l
if r<n and arr[root]<arr[r]:
root=r
if root !=i:
arr[root],arr[i] = arr[i],arr[root]
heapify(arr,n,root)
def heap_sort(arr):
n=len(arr)
for i in range(n//2,-1,-1):
heapify(arr,n,i)
for i in range(n-1,0,-1):
arr[i],arr[0] = arr[0],arr[i]
heapify(arr,i,0)
return arr
if __name__ == "__main__":
arr=[7,3,1,5,10,11,16,9,8]
print(f'After:{heap_sort(arr)}')O(n)算法(O(n) Algorithms)
These three sorting algorithms all use the buckets, but there are obvious differences in the use of buckets.
这三种排序算法都使用存储桶,但是在使用存储桶方面存在明显差异。
计数排序 (Counting Sort)
The core of counting sort is to convert the input data values into key value store in the additional space. As a sort of linear time complexity, count sort requires that the input data must be an integer with a certain range.
计数排序的核心是将输入数据值转换为附加空间中的键值存储。 作为一种线性时间复杂性,计数排序要求输入数据必须是具有一定范围的整数。
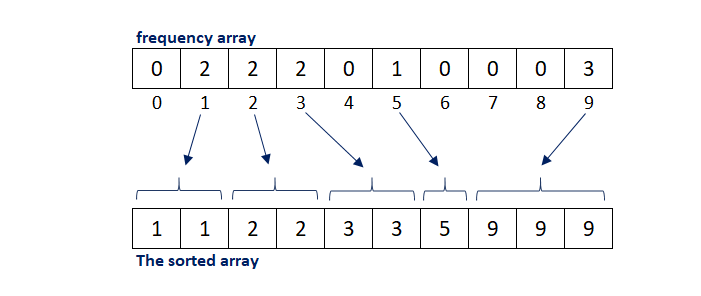
'''
if the max of the integer array is very huge,
then the bucket will use a lot of memory.
if the data distribution is very discrete,
the bucket use efficiency is very low,
a lot of space is wasted
'''
def counting_sort(arr):
'''use array as bucket'''
counts = [0] * (max(arr)+1)
for num in arr:
counts[num] += 1
result=[]
for num,count in enumerate(counts):
if count==0:
continue
result.append([num]*count)
return sum(result,[])
if __name__ == '__main__':
arr=[54,26,93,17,77,31,44,55,20]
print(f'After:{counting_sort(arr)}')桶分类(Bucket Sort)
Bucket sorting is an upgraded version of counting sorting. In order to make bucket sorting more efficient, we need to do two things, the first is try to increase the number of buckets, and the second is the mapping function used can evenly distribute the input N data into K buckets.
桶分类是计数分类的升级版本。 为了使存储桶排序更有效率,我们需要做两件事,第一是尝试增加存储桶的数量,第二是使用的映射功能可以将输入的N个数据平均分配到K个存储桶中。
At the same time, for the sorting of the elements in the bucket, the choice of sorting algorithm is crucial to performance.
同时,对于存储桶中的元素排序,排序算法的选择对于性能至关重要。
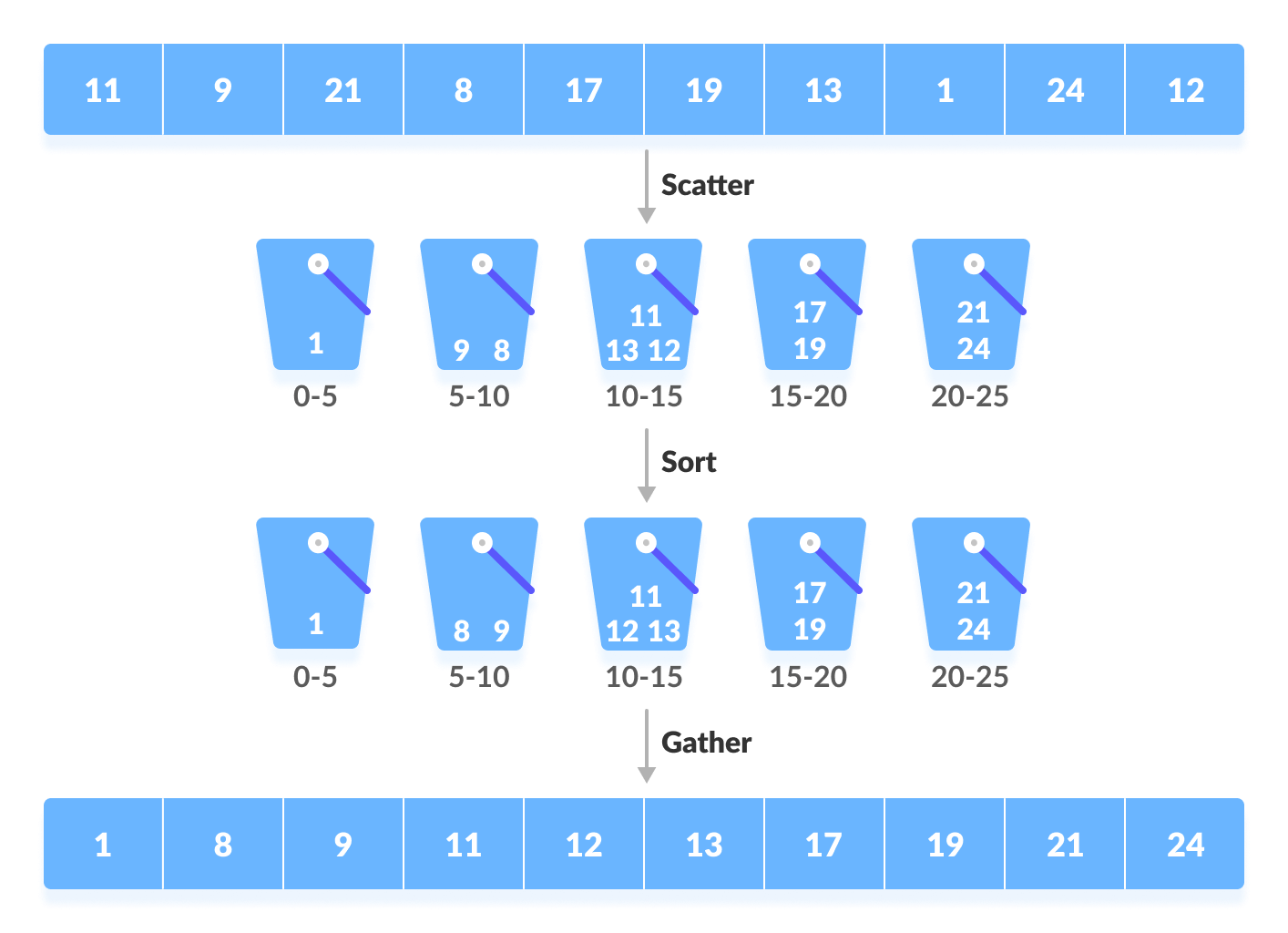
def bucket_sort(arr):
'''
sorted is a built-in sorting algorithm in python,
which can be replaced by a stable sorting algorithm
'''
max_,min_=max(arr),min(arr)
stride=(max_-min_)/len(arr)
buckets=[[] for i in range(len(arr)+1)]
for num in arr:
buckets[int((num-min_)//stride)].append(num)
return sum([sorted(bucket) for bucket in buckets],[])
if __name__ == '__main__':
arr=[54,26,93,17,77,31,44,55,20]
print(f'After:{bucket_sort(arr)}')板蓝根(Radix Srot)
Radix sorting is a non-comparative integer sorting algorithm. The principle is to cut integers into different numbers by digits, and then compare them according to each digit.
基数排序是一种非比较整数排序算法。 原理是将整数按数字切成不同的数字,然后根据每个数字进行比较。
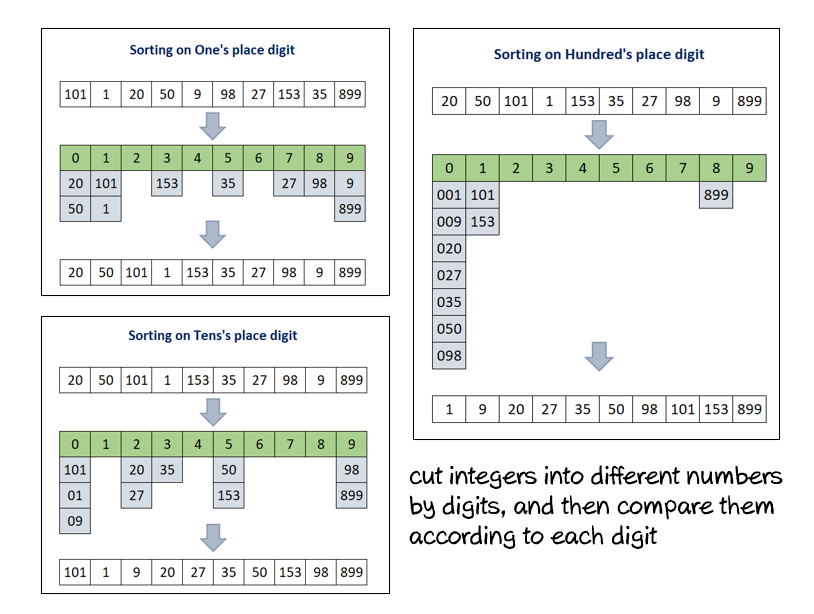
'''
first, find the max digit, if max value is 999,then max digit is 3
create new buckets each swap, and put number in buckets by digit then extract out.
loop until digit up to max digit.
'''
def radix_sort(arr):
digit=0
def find_max_digit(max_):
digit=1
while True:
max_=max_/10
if max_ > 1:
digit+=1
else:
break
return digit
def single_swap(arr,digit):
buckets = [[] for _ in range(10)]
for num in arr: # put in bucket
t = int((num / 10 ** digit) % 10)
buckets[t].append(num)
return sum(buckets,[]) # pop from bucket
max_digit=find_max_digit(max(arr))
while digit < max_digit:
arr=single_swap(arr,digit)
digit = digit + 1
return arr
if __name__ == '__main__':
arr=[101,1,20,50,9,98,27,153,35,809]
print(f'After:{radix_sort(arr)}')概要(Summary)
- This article mainly introduces nine different types of algorithms, which can be divided into three categories based on time complexity.本文主要介绍九种不同类型的算法,根据时间复杂度可将其分为三类。
- Different sorting algorithms have different core ideas and implementation strategies. 不同的排序算法具有不同的核心思想和实现策略。
- We need to focus on the core ideas of the algorithm and implement it in a concise way. 我们需要关注算法的核心思想并以简洁的方式实现它。
That’s all. THX.
就这样。 谢谢。
升级编码 (Level Up Coding)
Thanks for being a part of our community! Subscribe to our YouTube channel or join the Skilled.dev coding interview course.
感谢您加入我们的社区! 订阅我们的YouTube频道或参加Skilled.dev编码面试课程。
翻译自: https://levelup.gitconnected.com/sorting-algorithms-make-disorder-become-orderly-a0ff45d71d12
无序查找算法














 689
689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









