





linux应用程序开源架构
重点(Top highlight)
Vulnerabilities in open source software, programming languages or projects is a big thing as a single exploit could cause a lot of chaos and lead to the loss of thousands of dollars for big organizations.
开源软件,编程语言或项目中的漏洞是一件大事,因为单一漏洞利用可能会造成很多混乱,并给大型组织造成数千美元的损失。
A lot of companies have been paying attention to vulnerabilities in software, dependencies, and languages they use in powering their system as they could be open to attacks if one of them is exploited.
许多公司一直在关注他们在为系统提供动力时使用的软件,依赖项和语言中的漏洞,因为如果其中之一被利用,它们很可能遭受攻击。
Luckily for us, we have a public database where all newly discovered vulnerabilities and common weaknesses are published and provided a fix as soon as discovered. These publicly published vulnerabilities database can be found on sites like CVE, NVD, WhiteSource Vulnerability Database, and so many more.
对我们来说幸运的是,我们有一个公共数据库,所有新发现的漏洞和常见弱点都将在该数据库中发布,并在发现后立即提供修复。 这些公开发布的漏洞数据库可在CVE , NVD , WhiteSource漏洞数据库等网站上找到。
With these sites, you can easily look up a vulnerability with its ID and get information on it. You can get the level of severity, the components affected, what caused the bug sometimes, how to fix it temporarily or permanently.
通过这些站点,您可以轻松地通过其ID查找漏洞并获取有关信息。 您可以获取严重性级别,受影响的组件,有时导致错误的原因,如何临时或永久修复它。
We can automate and speed up this process as well, by building a simple command-line application for looking up vulnerability details and information.
我们还可以通过构建一个简单的命令行应用程序来查找漏洞详细信息和信息,来自动化并加快该过程。
So in this article, we are going to explore how to build a command-line utility for looking up vulnerability details using Python.
因此,在本文中,我们将探讨如何构建命令行实用程序以使用Python查找漏洞详细信息。
设置您的Python环境 (Setting Your Python Environment)
The first step in building our command-line utility is setting up our Python environment for development. When working on Python projects, I always suggest setting up a virtual environment as it makes things easier and helps avoid conflict in modules versions.
构建命令行实用程序的第一步是设置Python开发环境。 在处理Python项目时,我总是建议您建立一个虚拟环境,因为它使事情变得更容易并且有助于避免模块版本之间的冲突。
If you are on Python 3, you can easily run python3 -m venv <name> to create a virtual environment or you install either of virtualenvwrapper or virtualenv to help set up a virtual environment. You can read more here on how to set up your environment.
如果您使用的是Python 3,则可以轻松地运行python3 -m venv <name>来创建虚拟环境,或者安装virtualenvwrapper或virtualenv来帮助设置虚拟环境。 您可以在此处阅读更多有关如何设置环境的信息。
Once your environment is up, the next thing is to install the required modules to build our app:
一旦您的环境启动,下一步就是安装所需的模块以构建我们的应用程序:
$ pip install requests beautifulsoup4 click lxmlFor this project, we installed:
对于此项目,我们安装了:
- Requests: Python HTTP request client library 请求:Python HTTP请求客户端库
- BeautifulSoup: Python library for parsing and extracting data from HTML and XMLBeautifulSoup:Python库,用于从HTML和XML解析和提取数据
- Click: A rich python command line framework点击:丰富的python命令行框架
- LXML: BeautifulSoup deps for processing HTML and XML.LXML:BeautifulSoup用于处理HTML和XML。
Next, we can create our folder structure using:
接下来,我们可以使用以下方法创建文件夹结构:
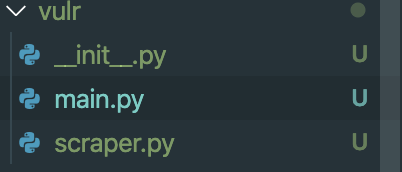
$ mkdir vulr && cd vulr
$ touch scraper.py main.py __init__.pyHere’s a full setup command for your environment:
这是针对您的环境的完整设置命令:
$ python3 -m venv vulr-env && source vulr-env/bin/activate$ pip install requests beautifulsoup4 click lxml$ mkdir vulr && cd vulr$ touch scraper.py main.py __init__.py$ pip freeze > requirements.txt$ touch readme.md .gitignore # optionalYou should get something like below:
您应该获得如下所示的内容:
编写我们的Web爬虫 (Writing Our Web Scraper)
To get details from the WhiteSource Vulnerabilities database using our command line, we’ll need to build a simple web scraper for extracting needed data and information about the vulnerability from the database.
为了使用命令行从WhiteSource Vulnerabilities数据库中获取详细信息,我们需要构建一个简单的Web爬网程序,以从数据库中提取所需的数据和有关该漏洞的信息。
Earlier we installed Requests and Beautifulsoup which we’ll be using in together to build a simple scraper and extract all available details about the vulnerability.
之前我们安装了Requests和Beautifulsoup,我们将一起使用它们来构建简单的抓取工具并提取有关该漏洞的所有可用详细信息。
Basically, our web scraper will extract available information on a particular vulnerability when given its CVE-ID. CVE-ID is a unique ID given to every published vulnerability for easy identification's sake.
基本上,我们的网络抓取工具会在获得特定漏洞的CVE-ID后提取其可用信息。 CVE-ID是赋予每个已发布漏洞的唯一ID,以便于识别。
Now let’s write a basic code setup for our scraper:
现在让我们为刮板编写一个基本的代码设置:
import requests
from bs4 from BeautifulSoupBASE_URL = "https://www.whitesourcesoftware.com/vulnerability-database/"def get_html(url):
request = requests.get(url)
if request.status_code == 200:
return request.content
else:
raise Exception("Bad request")def lookup_cve(name):
passAbove we have created a basic structure for our web scraper. We added the WhiteSource vulnerability lookup URL, added a function to get the HTML content of the request and we also added an empty lookup_cve function.
上面,我们为网页刮板创建了一个基本结构。 我们添加了WhiteSource漏洞查找URL,添加了获取请求HTML内容的函数,还添加了一个空的lookup_cve函数。
Now let’s head over to this WhiteSource Vuln Lab, open the developer console, and study the DOM structure of the page.
现在,让我们转到WhiteSource Vuln Lab ,打开开发人员控制台,并研究页面的DOM结构。
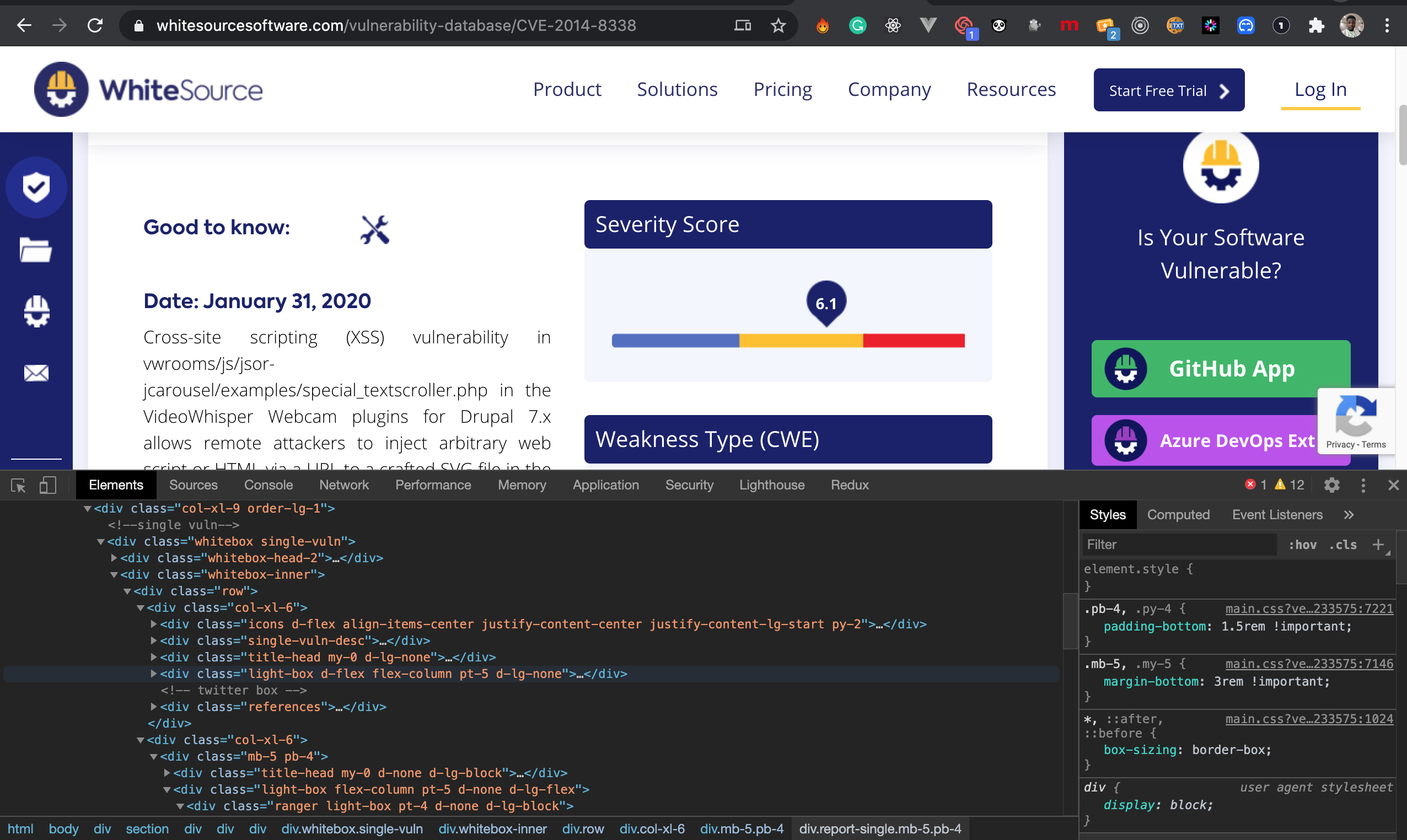
The next thing is to extract the headers and cookies sent when requesting for the webpage. In order to send a successful request to the webpage, we need to act like a browser so we won’t get a forbidden error.
接下来的事情是提取请求网页时发送的标题和cookie。 为了将成功的请求发送到网页,我们需要像浏览器一样操作,以免出现禁止的错误。
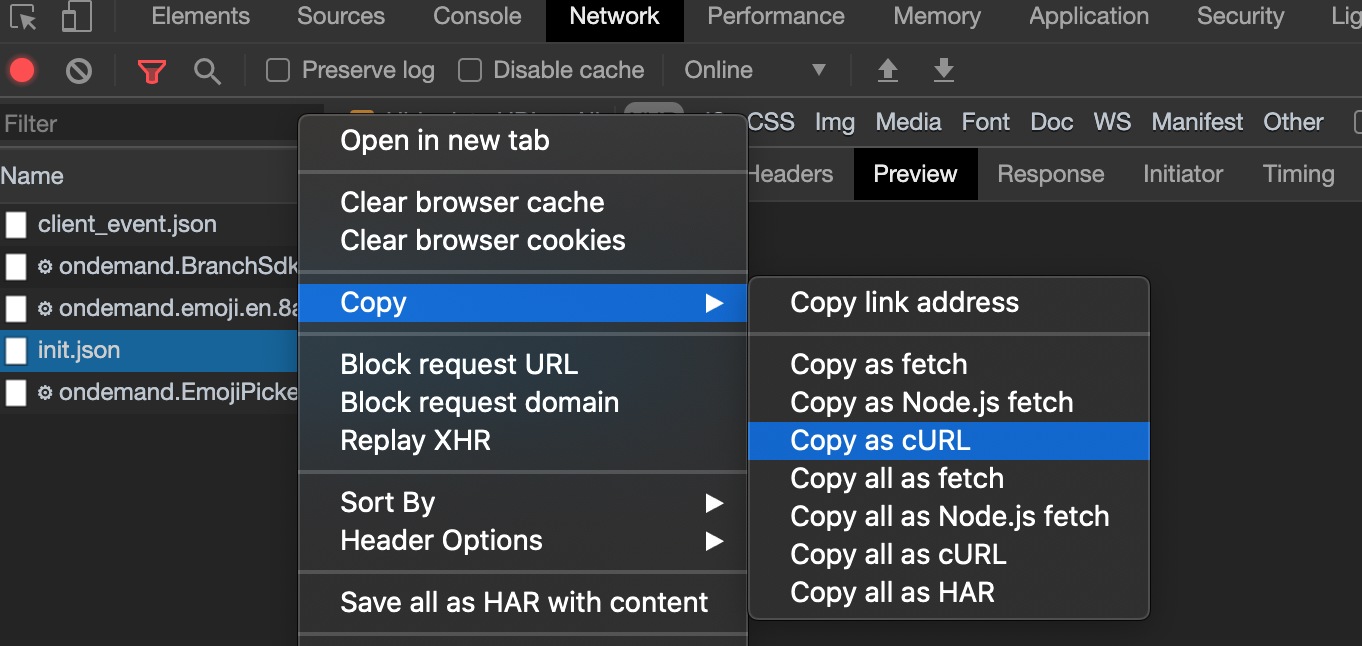
You can do that on the Network tab, so click on and click on All. Then click on the request sent to get the webpage. It’s usually the first request sent from the browser.
您可以在“网络”选项卡上执行此操作,因此请单击,然后单击“全部”。 然后单击发送的请求以获取网页。 通常是浏览器发送的第一个请求。

Right click on it and mouse over on Copy and click on Copy as cURL. This will copy the request in cURL format including its headers and cookies:
右键单击它,然后将鼠标悬停在“复制”上,然后单击“复制为cURL”。 这将以cURL格式复制请求,包括其标头和cookie:
Now to extract the cURL command including the headers and cookies to Python requests, we can easily use this tool. This will help convert the cURL command to any language and popular HTTP request library.
现在要提取cURL命令(包括标头和cookie到Python请求),我们可以轻松地使用此工具。 这将有助于将cURL命令转换为任何语言和流行的HTTP请求库。
All you need to do is paste your cURL command, select Python and you get a nice formatted implementation of the request in Python Request:
您需要做的就是粘贴您的cURL命令,选择Python,您将在Python Request中获得请求的格式良好的实现:

Now from the second text box, we’ll copy out the headers and cookies dictionaries and update our code as below:
现在,从第二个文本框中,复制标题和cookie字典,并更新我们的代码,如下所示:
import requests
from bs4 from BeautifulSoupBASE_URL = "https://www.whitesourcesoftware.com/vulnerability-database/"cookies = {
'_ga': 'GA1.2.1677532255.1591419793179',
...
}headers = {
'authority': 'www.whitesourcesoftware.com',
'cache-control': 'max-age=0',
...
}def get_html(url):
request = requests.get(url, headers=headers, cookies=cookies)
print(request.content)
if request.status_code == 200:
return request.content
else:
raise Exception("Bad request")The next thing to do is to extract all information displayed on the page using its dom structure orderly.
下一步是按顺序使用其dom结构提取页面上显示的所有信息。
From the above code, we:
从上面的代码,我们:
- Extracted the description, date, language, references, severity score, top_fix, weakness, and reports. 提取描述,日期,语言,参考,严重性得分,top_fix,弱点和报告。
- We added another function extract_cvs_table to extract data from the CVS table found on the right side of the page. 我们添加了另一个函数extract_cvs_table,以从页面右侧的CVS表中提取数据。
- Then we structure the results into a simple dictionary 然后我们将结果构造成一个简单的字典
To test this, you simply call the function and pass the CVE id:
要对此进行测试,只需调用该函数并传递CVE id:
cve_details = lookup_cve("CVE-2020-6803")print(cve_details)Then run:
然后运行:
$ python scraper.pyVoila! We have successfully created our web scraper.
瞧! 我们已经成功创建了我们的网页抓取工具。
构建我们的命令行应用程序 (Building Our Command Line Application)
The next thing to do now is to build our command-line application using the click library we installed earlier on.
现在要做的下一件事是使用我们先前安装的点击库来构建我们的命令行应用程序。
Like I explained briefly earlier, Click is a command-line framework, and its one of the best you can find out there due to its simplicity and structure.
就像我之前简要解释的那样,Click是一个命令行框架,由于它的简单性和结构性,它是您可以在其中找到的最好的框架之一。
To get started, let's have a look at our CLI code setup in main.py:
首先,让我们看一下main.py中的CLI代码设置:
import sys
import click@click.group()
@click.version_option("1.0.0")
def main():
"""Vulnerability Lookup CLI"""
print("Hey")@main.command()
@click.argument('name', required=False)
def look_up(**kwargs):
"""Get vulnerability details using its CVE-ID on WhiteSource Vuln Database"""
click.echo(kwargs)if __name__ == '__main__':
args = sys.argv
if "--help" in args or len(args) == 1:
print("Vulnerability Checker - Vulr")
main()With the above setup, we have created a command called look_up and passed an argument — name to the command. This will be the command used to get vulnerability information.
通过上述设置,我们创建了一个名为look_up的命令,并将一个参数-name传递给该命令。 这将是用于获取漏洞信息的命令。
To implement the web scraper on this command, you will need to import the lookup_cve from the scraper.py and pass the argument passed to the function. Once we do that, we then display the resulting data by printing them out.
要在此命令上实施Web scraper,您将需要从scraper.py导入lookup_cve并将参数传递给函数。 完成此操作后,我们将通过打印输出结果数据来显示它们。
Here’s how to do that:
这样做的方法如下:
To run this:
要运行此命令:
$ python main.py look-up CVE-2014-8338Ta-da! Our command-line application is working.
- 我们的命令行应用程序正在运行。
最后的想法 (Final Thoughts)
So far we have explored how to build a web scraper to extract data from the WhiteSource Vulnerabilities database to get vulnerability information and implement it in a command-line application so it can be used to display vulnerability details right from the command line.
到目前为止,我们已经探索了如何构建Web抓取工具以从WhiteSource Vulnerabilities数据库中提取数据,以获取漏洞信息并将其在命令行应用程序中实现,以便可以将其直接用于从命令行显示漏洞详细信息。
The next thing you can do is publish this on PyPI so other users will be able to install and use it using the PIP package manager.
接下来,您可以在PyPI上发布此内容,以便其他用户可以使用PIP包管理器进行安装和使用。
linux应用程序开源架构















 1789
1789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









