





 这篇博客简单介绍了Python中的数据结构,包括其基本概念和定义,帮助初学者理解如何在Python中定义和使用数据结构。
这篇博客简单介绍了Python中的数据结构,包括其基本概念和定义,帮助初学者理解如何在Python中定义和使用数据结构。
python中定义数据结构
You have multiples algorithms, the steps of which require fetching the smallest value in a collection at any given point of time. Values are assigned to variables but are constantly modified, making it impossible for you to remember all the changes. One way to work through this problem is to store this collection in an unsorted array and then scan this collection every time, to find the required value. But considering the collection has N elements, this would lead to an increase in the required amount of time proportional to N.
您有多种算法,其步骤要求在任何给定时间点获取集合中的最小值。 值已分配给变量,但会不断修改,从而使您无法记住所有更改。 解决此问题的一种方法是将该集合存储在未排序的数组中,然后每次扫描该集合以查找所需的值。 但是考虑到集合中有N个元素,这将导致与N成正比的所需时间增加。
Data structures to the rescue! Let us invent a common operation that ‘finds the minimum value from a set of elements.’ Here, the data structure is the common operation that all these algorithms will make use of to find the minimum element much faster.
数据结构抢救! 让我们发明一个通用的操作,“从一组元素中找到最小值”。 在这里,数据结构是所有这些算法将用来更快地找到最小元素的常用操作。
There is no one single way of looking up data. Hence, when using an algorithm, make sure to understand the kind of data structures used by it and the operations they are a part of. The main purpose of a data structure is to speed up operations. In the above example, when I talk about an unsorted array, that too is a data structure. If the algorithm you are working with doesn’t care about a quicker result, you could continue using the array to get results.
没有一种查找数据的单一方法。 因此,在使用算法时,请确保了解它所使用的数据结构的类型以及它们所包含的操作。 数据结构的主要目的是加快操作速度。 在上面的示例中,当我谈论一个未排序的数组时,它也是一个数据结构。 如果您使用的算法不关心更快的结果,则可以继续使用数组来获取结果。
In case a data structure is what your algorithm requires, time must be spent on designing and maintaining one so that it becomes easier to query and update the structure.
如果您的算法需要一种数据结构,则必须花时间设计和维护一个数据结构,以便查询和更新该结构变得更加容易。
Python中的数据结构 (Data Structures in Python)
Data structures provide us with a specific and way of storing and organizing data such that they can be easily accessed and worked with efficiently. In this article, you will learn about the various Python data structures and how they are implemented.
数据结构为我们提供了一种特定的方式来存储和组织数据,以便可以轻松地访问和有效地使用它们。 在本文中,您将学习各种Python数据结构及其实现方式。
A link to my GitHub repository to access the Jupyter notebook used for this demonstration:
指向我的GitHub存储库的链接,以访问用于此演示的Jupyter笔记本:
Broadly speaking, data structures can be classified into two types — primitive and non-primitive. The former is the basic way of representing data which contain simple values. The latter is a more advanced and a complex way off representing data that contain a collection of values in various formats.
广义上讲,数据结构可以分为两种类型:原始类型和非原始类型。 前者是表示包含简单值的数据的基本方法。 后者是一种更高级,更复杂的方式,用于表示包含各种格式的值的集合的数据。
Non primitive data structures can further be categorized into built-in and user defined structures. Python offers implicit support for built in structures that include List, Tuple, Set and Dictionary. Users can also create their own data structures (like Stack, Tree, Queue, etc.) enabling them to have a full control over their functionality.
非原始数据结构可以进一步分为内置结构和用户定义结构。 Python为内置结构(包括List,Tuple,Set和Dictionary)提供了隐式支持。 用户还可以创建自己的数据结构(如堆栈,树,队列等),使他们能够完全控制其功能。
清单 (LIST)
A list is a mutable sequence that can hold both homogeneous and heterogeneous data, in a sequential manner. An address is assigned to every element of the list, called an Index. The elements within a list are comma-separated and enclosed within square brackets.
列表是一个可变序列,可以按顺序存储同质和异质数据。 将地址分配给列表的每个元素,称为索引。 列表中的元素以逗号分隔,并括在方括号内。
You can add, remove, or change elements from the list without changing its identity. Following are some of the functions used commonly while working with lists:
您可以在列表中添加,删除或更改元素,而无需更改其标识。 以下是使用列表时常用的一些功能:
Creating a list:
创建列表:
initial_list = [1,2,3,4]
print(initial_list)Lists can contain different types of variable, even in the same list.
列表可以包含不同类型的变量,即使在同一列表中也是如此。
my_list = ['R', 'Python', 'Julia', 1,2,3]
print(my_list)Adding an element to a list:
将元素添加到列表中:
my_list = ['R', 'Python', 'Julia']
my_list.append(['C','Ruby'])
print(my_list)my_list.extend(['Java', 'HTML'])
print(my_list)my_list.insert(2, 'JavaScript')
print(my_list)The outputs vary while using different functions like insert, extend and append with a list.
使用不同的功能(如插入,扩展和追加列表)时,输出会有所不同。
· The insert function adds an element at the position/index specified.
·insert函数在指定的位置/索引处添加元素。
· The append function will add all elements specified, as a single element.
·append函数会将指定的所有元素添加为单个元素。
· The extend function will add elements on a one-by-one basis.
·扩展功能将在一对一的基础上添加元素。
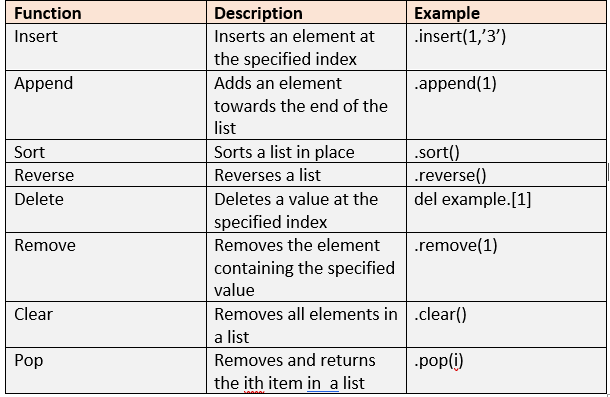
Accessing elements:
访问元素:
Lists can be indexed using square brackets to retrieve the element stored in a position. Indexing in lists returns the entire item at that position whereas in strings, the character at that position is returned.
列表可以使用方括号索引,以检索存储在位置中的元素。 在列表中建立索引将返回该位置处的整个项目,而在字符串中,将返回该位置处的字符。
Deleting elements from a list:
从列表中删除元素:
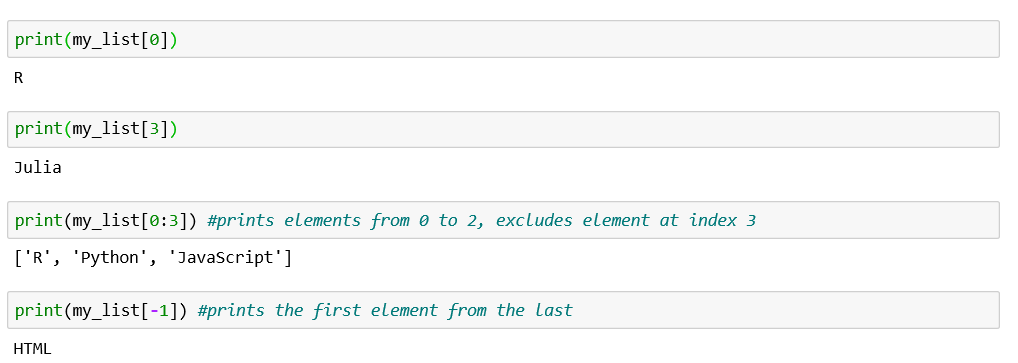
Once again, notice the outputs while using different functions like pop, delete and remove with the list. Remove is used when you want to remove element by specifying its value. We use del to remove an element by index, pop() to remove it by index if you need the returned value.
再一次,在使用弹出,删除和删除等不同功能时注意输出。 如果要通过指定元素的值来删除元素,则使用Remove。 如果需要返回的值,我们使用del删除索引元素,pop()删除索引元素。
Slicing a List:
切片列表:
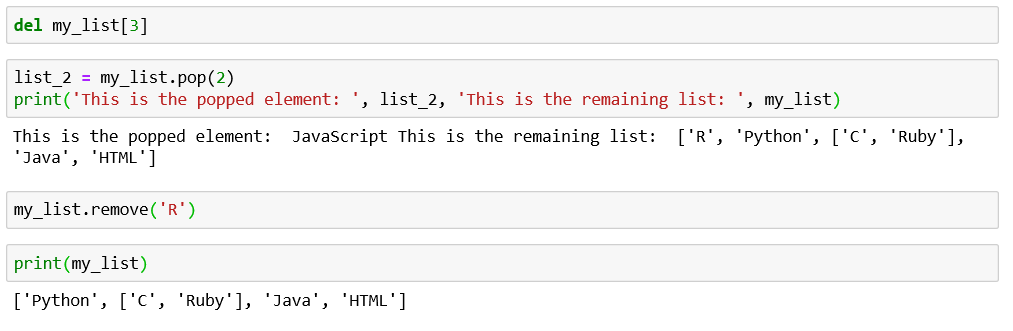
While indexing is limited to accessing a single element, slicing accesses a sequence of data from a list.
虽然索引仅限于访问单个元素,但切片访问列表中的数据序列。
Slicing is done by defining the index values of the first element and the last element from the parent list that is required in the sliced list. It is written as [ a : b ] where a, b are the index values from the parent list. If a or b is not defined, then the index value is considered to be the first value for a if a is not defined and the last value for b when b is not defined.
通过定义切片列表中所需的父列表的第一个元素和最后一个元素的索引值来完成切片。 它写为[a:b],其中a,b是父列表的索引值。 如果未定义a或b,则在未定义a时将索引值视为a的第一个值,而在未定义b时将索引值视为b的最后一个值。
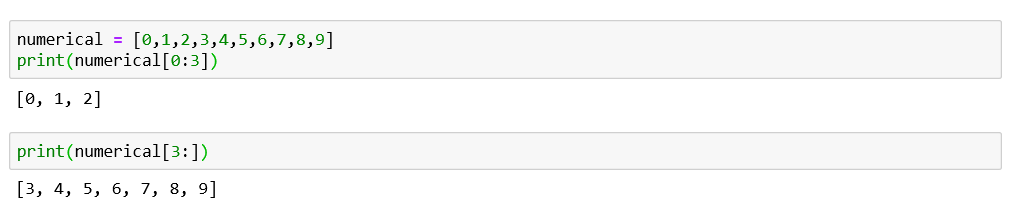
Sort function:
排序功能:
# print the sorted list but not change the original onenumero = [1,12,4,25,19,8,29,6]
print(sorted(numero))
numero.sort(reverse=True)
print(numero)Max, Min and ASCII value:
最大值,最小值和ASCII值:
· In a list with elements as string, max( ) and min( ) is applicable. max( ) would return a string element whose ASCII value is the highest and the lowest when min( ) is used.
·在以字符串为元素的列表中, max()和min()适用。 当使用min()时, max()将返回其ASCII值最高和最低的字符串元素。
· Only the first index of each element is considered each time and if their value is the same then the second index is considered and so on and so forth.
·每次只考虑每个元素的第一个索引,如果它们的值相同,则考虑第二个索引,依此类推。
new_list = ['apple','orange','banana','kiwi','melon']
print(max(new_list))
print(min(new_list))And what happens in case numbers are declared as strings?
如果数字被声明为字符串,会发生什么?
new_list1 =['3','45','22','56','11']
print(max(new_list1))
print(min(new_list1))Even if the numbers are declared in a string the first index of each element is considered and the maximum and minimum values are returned accordingly.
即使数字在字符串中声明,也要考虑每个元素的第一个索引,并相应地返回最大值和最小值。
You can also find the maximum and minimum values based on the length of a string.
您还可以根据字符串的长度找到最大值和最小值。
Copying & working on a list:
复制并处理列表:
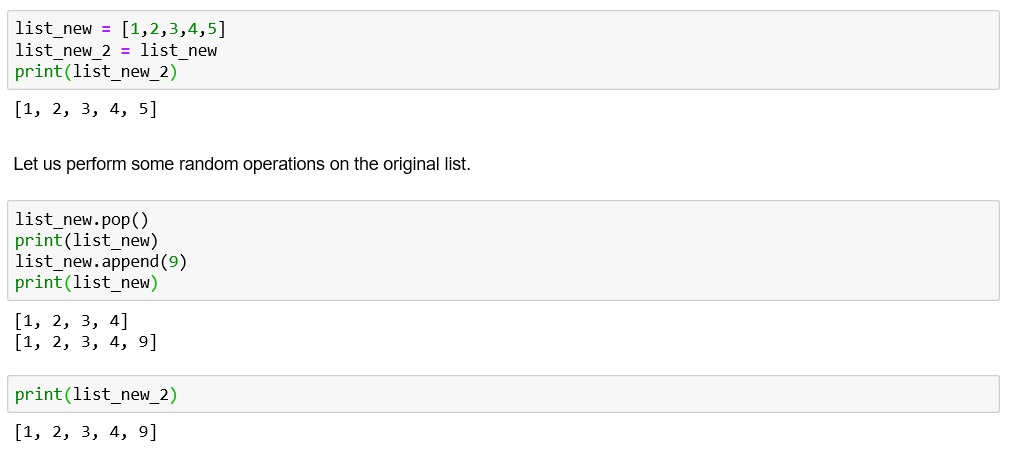
Although no operation has been performed on the copied list, the values for it have also been changed. This is because you have assigned the same memory space of new_list to new_list_2.
尽管未对复制的列表执行任何操作,但其值也已更改。 这是因为您已将new_list的相同存储空间分配给new_list_2。
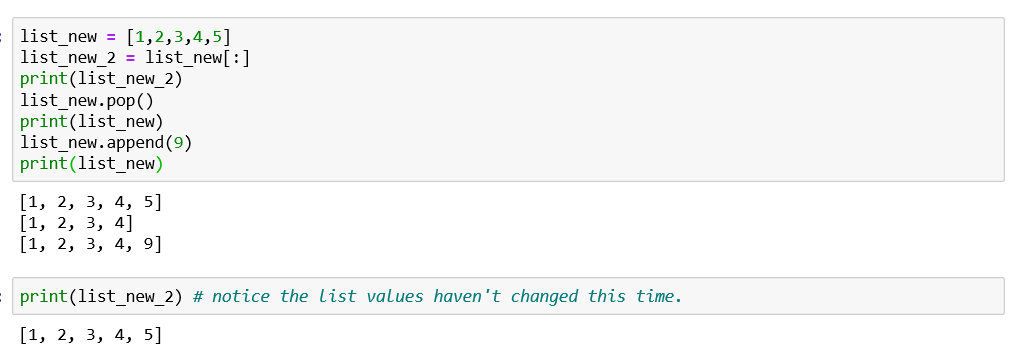
How do we fix this?
我们该如何解决?
If you recall, in slicing we had seen that parent list [a:b] returns a list from parent list with start index a and end index b and if a and b is not mentioned then by default it considers the first and last element. We use the same concept here.
如果您还记得的话,在切片时,我们已经看到父列表[a:b]从父列表返回了一个列表,其起始索引为a,终止索引为b,如果未提及a和b,则默认情况下它将考虑第一个和最后一个元素。 我们在这里使用相同的概念。
管 (TUPLE)
Tuples are used to hold together multiple objects. Unlike lists, tuples are both immutable and specified within parentheses instead of square brackets. The values within a tuple cannot be overridden, that is, they cannot be changed, deleted, or reassigned. Tuples can hold both homogeneous and heterogeneous data.
元组用于将多个对象保持在一起。 与列表不同,元组是不可变的,并且在括号而不是方括号中指定。 元组中的值不能被覆盖,也就是说,不能更改,删除或重新分配它们。 元组可以同时存储同质和异质数据。
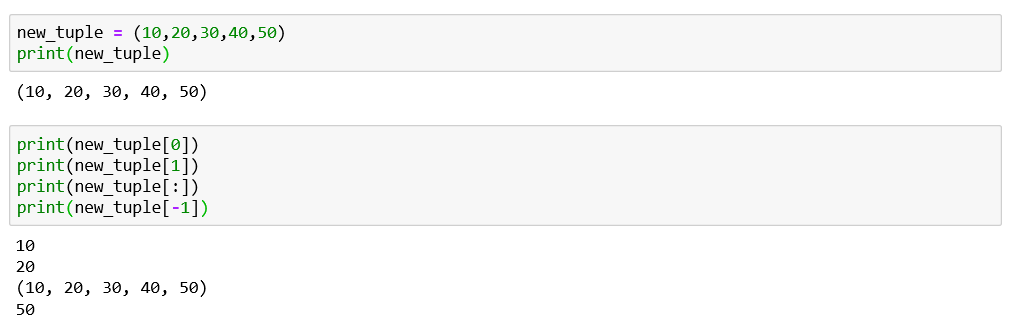
Creating and accessing elements from a tuple:
从元组创建和访问元素:
Appending a tuple:
附加一个元组:
tuple_1 = (1,2,3,4,5)
tuple_1 = tuple_1 + (6,7,8,9,10)
print(tuple_1)Tuples are immutable.
元组是不可变的。
Divmod function:
Divmod函数:
Think of tuples as something which has to be True for a particular something and cannot be True for no other values. For better understanding, let’s use the divmod() function.
将元组视为对于特定事物必须为True且对于其他任何值都不能为True的事物。 为了更好地理解,让我们使用divmod()函数。
xyz = divmod(10,3)
print(xyz)
print(type(xyz))Here the quotient has to be 3 and the remainder has to be 1. These values cannot be changed whatsoever when 10 is divided by 3. Hence divmod returns these values in a tuple.
在这里,商必须为3,余数必须为1。将10除以3时,这些值都不能更改。因此divmod以元组形式返回这些值。
Built-In Tuple functions:
内置元组功能:
Count and Index are used with tuples as they are with lists.
计数和索引与元组一起使用,就像与列表一样。
example = ("Mumbai","Chennai","Delhi","Kolkatta","Mumbai","Bangalore")
print(example.count("Mumbai"))print(example.index("Delhi"))字典 (DICTIONARY)
If you are looking to implement something like a telephone book, a dictionary is what you need. Dictionaries basically store ‘key-value’ pairs. In a phone directory, you’ll have Phone and Name as keys and the various names and numbers assigned are the values. The ‘key’ identifies an item and the ‘value’ stores the item’s value. The ‘key-value’ pairs are separated by commas and the values are separated from the keys using a colon ‘:’ character.
如果您想实现电话簿之类的东西,则需要词典。 字典基本上存储“键值”对。 在电话目录中,您将具有“电话”和“名称”作为键,并且分配的各种名称和数字是值。 “键”标识一个项目,“值”存储该项目的值。 “键值”对用逗号分隔,并且值之间用冒号“:”字符与键分开。
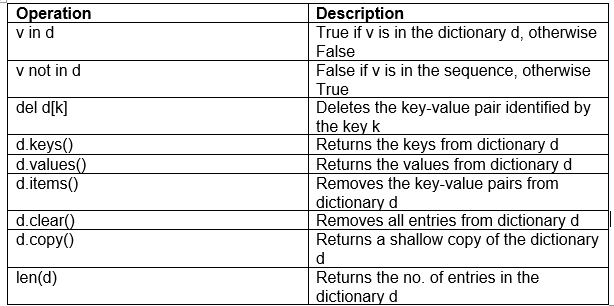
You can add, remove, or change existing key-value pairs in a dictionary. Below mentioned are some of the common functions performed using a dictionary.
您可以在字典中添加,删除或更改现有的键值对。 下面提到的是使用字典执行的一些常用功能。
Creating a dictionary:
创建字典:
new_dict = {} # empty dictionary
print(new_dict)
new_dict = {'Jyotika':1, 'Manu':2, 'Geeta':3, 'Manish':4}
print(new_dict)Adding or changing a key-value pair:
添加或更改键值对:

Deleting key-value pairs:
删除键值对:
· Use the pop() function to delete values, which returns the value that has been deleted.
·使用pop()函数删除值,该值返回已删除的值。
· To retrieve the key-value pair, you use the popitem() function which returns a tuple of the key and value.
·要检索键值对,请使用popitem()函数,该键返回键和值的元组。
· To clear the entire dictionary, you use the clear() function.
·要清除整个词典,请使用clear()函数。
new_dict_2 = new_dict.pop('Manu')
print(new_dict_2)
new_dict_3 = new_dict.popitem()
print(new_dict_3)Values() and keys() functions:
Values()和keys()函数:
· values( ) function returns a list with all the assigned values in the dictionary.
·values()函数返回一个列表,其中包含字典中所有已分配的值。
· keys( ) function returns all the index or the keys to which contains the values that it was assigned to.
·keys()函数返回包含已为其分配值的所有索引或键。
print(new_dict.values())
print(type(new_dict.values()))
print(new_dict.keys())
print(type(new_dict.keys()))集合 (SETS)
Sets are an unordered collection of unique elements. Sets are mutable but can hold only unique values in the dataset. Set operations are similar to the ones used in arithmetic.
集是唯一元素的无序集合。 集是可变的,但只能在数据集中保留唯一值。 设置操作类似于算术中使用的操作。
new_set = {1,2,3,3,3,4,5,5}
print(new_set)
new_set.add(8)
print(new_set)Other operations on sets:
机上的其他操作:
.union() — combines data in both sets
.union() - 合并两组数据
.intersection() — outputs data common to both sets
.intersection() —输出两组通用的数据
.difference() — deletes the data present in both and outputs data present only in the set passed.
.difference() —删除两个目录中都存在的数据,并仅输出所传递的集合中存在的数据。
.symmetricdifference() — deletes the data present in both and outputs the data which is remaining in both sets.
.symmetricdifference() —删除两个组中都存在的数据,并输出两个组中剩余的数据。

用户定义的数据结构的简要概述 (A brief overview of user-defined data structures)
- Stack: Based on the principles of FILO (first in last out) and LIFO (last in first out), stacks are linear data structures in which addition of new elements is accompanied by equal number of removals from the other end. There are two types of operations in Stack: 堆栈:基于FILO(先进先出)和LIFO(先进先出)的原理,堆栈是线性数据结构,其中添加新元素时会从另一端进行相同数量的删除。 Stack中有两种类型的操作:
a) Push — To add data into the stack.
a)推入—将数据添加到堆栈中。
b) Pop — To remove data from the stack.
b)Pop(弹出)—从堆栈中删除数据。
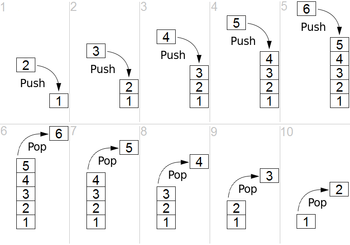
We can implement stacks using modules and data structures from the Python library, namely — list, collections.deque, queue.LifoQueue.
我们可以使用Python库中的模块和数据结构来实现堆栈,即list,collections.deque,queue.LifoQueue。
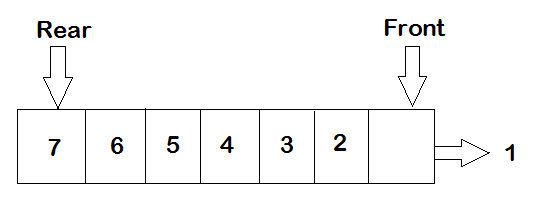
2. Queue: Queue is a linear data structure which is based on the First in First out principle (FIFO). The data which is entered first will be accessed first. Operations on a queue can be performed from both ends, head and tail. En-queue and De-queue are terms for operations used to add or delete items from a queue. Similar to Stacks, we can implement stacks using modules and data structures from the Python library, namely — list, collections.deque.
2.队列:队列是一种线性数据结构,它基于先进先出原则(FIFO)。 首先输入的数据将被首先访问。 队列的操作可以从头和尾的两端进行。 入队和出队是用于在队列中添加或删除项目的操作的术语。 与堆栈类似,我们可以使用Python库中的模块和数据结构(即list,collections.deque)实现堆栈。
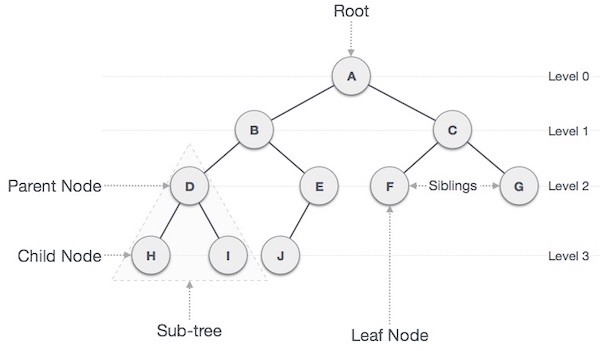
3. Tree: Trees are no-linear data structures consisting of roots and nodes. The point of origination of the data is termed as the parent node and every other node arising subsequently has is a child node. The last nodes are the leaf nodes. The level of the nodes shows the depth of information in a tree.
3.树:树是由根和节点组成的非线性数据结构。 数据的起源点称为父节点,随后出现的每个其他节点都有一个子节点。 最后的节点是叶节点。 节点的级别显示树中信息的深度。
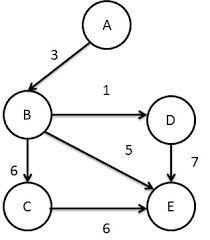
4. Graph: A graph in python typically store data collection of points called vertices (nodes) and edges (edges). A graph can be represented using the python dictionary data types. The keys of the dictionary are represented as vertices and the values represent the edges between the vertices.
4.图形:Python中的图形通常存储称为顶点(节点)和边(edge)的点的数据收集。 可以使用python字典数据类型表示图形。 字典的键表示为顶点,值表示顶点之间的边。
Data structures help organizing information and whether you are a novice or a programming veteran, you can’t ignore the crucial concepts surrounding data structures.
数据结构有助于组织信息,无论您是新手还是编程老手,都不能忽略围绕数据结构的关键概念。
For a more exhaustive coverage of the different data structures used in Python, refer to the following links:
有关Python中使用的不同数据结构的更详尽介绍,请参见以下链接:
· The official Python documentation for lists, dictionaries, and tuples
· The book A Byte of Python.
·《 Python字节 》一书。
翻译自: https://towardsdatascience.com/data-structures-in-python-a-brief-introduction-b4135d7a9b7d
python中定义数据结构















 7049
7049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









