





python内置函数多少个
Python is the number one choice of programming language for many data scientists and analysts. One of the reasons of this choice is that python is relatively easier to learn and use. More importantly, there is a wide variety of third party libraries that ease lots of tasks in the field of data science. For instance, numpy and pandas are great data analysis libraries. Scikit-learn and tensorflow are for machine learning and data preprocessing tasks. We also have python data visualization libraries such as matplotlib and seaborn. There are many more useful libraries for data science in python ecosystem.
对于许多数据科学家和分析师来说,Python是编程语言的第一选择。 这种选择的原因之一是python相对易于学习和使用。 更重要的是,有各种各样的第三方库可以减轻数据科学领域的许多任务。 例如, numpy和pandas是出色的数据分析库。 Scikit-learn和tensorflow用于机器学习和数据预处理任务。 我们还有python数据可视化库,例如matplotlib和seaborn 。 在python生态系统中,还有许多用于数据科学的有用库。
In this post, we will not talk about these libraries or frameworks. We will rather cover important built-in functions of python. Some of these functions are also used in the libraries we mentioned. There is no point in reinventing the wheel.
在本文中,我们将不讨论这些库或框架。 我们宁愿介绍重要的python内置函数。 我们提到的库中也使用了其中一些功能。 重新发明轮子没有意义。
Let’s start.
开始吧。
1套 (1. Set)
Set function returns a set object from an iterable (e.g. a list). Set is an unordered sequence of unique values. Thus, unlike lists, sets do not have duplicate values. One use case of sets is to remove duplicate values from a list or tuple. Let’s go over an example.
Set函数从迭代器(例如列表)返回set对象。 Set是唯一值的无序序列。 因此,与列表不同,集合不具有重复值。 集的一种用例是从列表或元组中删除重复的值。 让我们来看一个例子。
list_a = [1,8,5,3,3,4,4,4,5,6]
set_a = set(list_a)
print(list_a)
print(set_a)
[1, 8, 5, 3, 3, 4, 4, 4, 5, 6]
{1, 3, 4, 5, 6, 8}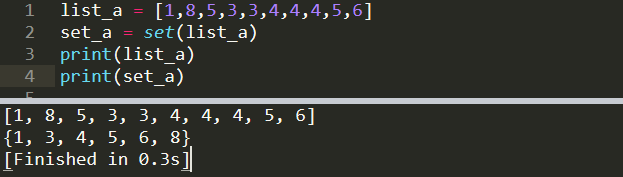
As you can see, duplicates are removed and the values are sorted. Sets are not subscriptable (because of not keeping an order) so we cannot access or modify the individual elements of a set. However, we can add elements to a set or remove elements from a set.
如您所见,将删除重复项并对值进行排序。 集合不可下标(因为不保持顺序),因此我们无法访问或修改集合的各个元素。 但是,我们可以将元素添加到集合中 或从集合中删除元素。
set_a.add(15)
print(set_a)
{1, 3, 4, 5, 6, 8, 15}2.列举 (2. Enumerate)
Enumerate provides a count when working with iterables. It can be placed in a for loop or directly used on an iterable to create an enumerate object. Enumerate object is basically a list of tuples.
枚举提供了使用可迭代对象时的计数。 可以将其放在for循环中,也可以直接在可迭代对象上使用以创建枚举对象。 枚举对象基本上是一个元组列表。
cities = ['Houston', 'Rome', 'Berlin', 'Madrid']
print(list(enumerate(cities)))
[(0, 'Houston'), (1, 'Rome'), (2, 'Berlin'), (3, 'Madrid')]Using with a for loop:
与for循环一起使用:
for count, city in enumerate(cities):
print(count, city)0 Houston
1 Rome
2 Berlin
3 Madrid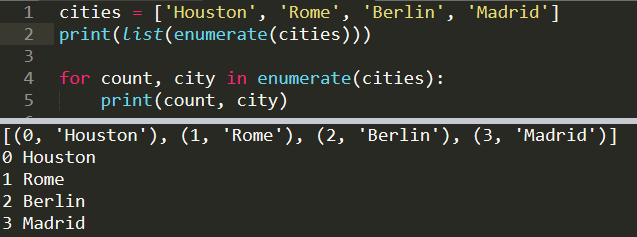
3.实例 (3. Isinstance)
Isinstance function is used to check or compare the classes of objects. It accepts an object and a class as arguments and returns True if the object is an instance of that class.
Isinstance函数用于检查或比较对象的类。 它接受一个对象和一个类作为参数,如果该对象是该类的实例,则返回True。
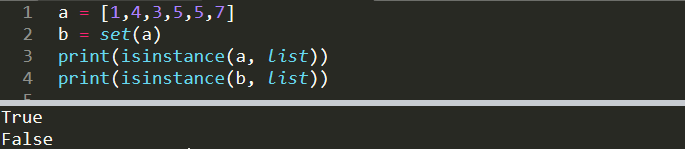
a = [1,4,3,5,5,7]
b = set(a)
print(isinstance(a, list))
print(isinstance(b, list))
True
FalseWe can access the class of an object using type function but isinstance comes in hand when doing comparisons.
我们可以使用类型函数来访问对象的类,但是在进行比较时会使用isinstance。
4.伦 (4. Len)
Len function returns the length of an object or the number of items in an object. For instance, len can be used to check:
Len函数返回对象的长度或对象中的项目数。 例如,len可用于检查:
- Number of characters in a string 字符串中的字符数
- Number of elements in a list 列表中的元素数
- Number of rows in a dataframe 数据框中的行数
a = [1,4,3,5,5,7]
b = set(a)
c = 'Data science'print(f'The length of a is {len(a)}')
print(f'The length of b is {len(b)}')
print(f'The length of c is {len(c)}')The length of a is 6
The length of b is 5
The length of c is 12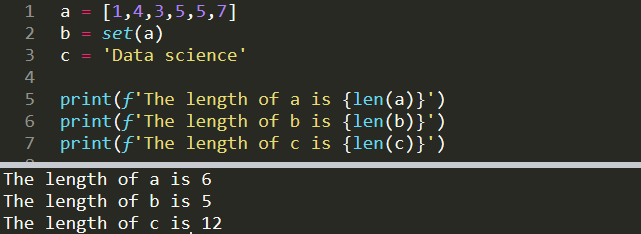
5.排序 (5. Sorted)
As the name clearly explains, sorted function is used to sort an iterable. By default, sorting is done in ascending order but it can be changed with reverse parameter.
顾名思义,sorted函数用于对Iterable进行排序。 默认情况下,排序按升序进行,但可以使用反向参数进行更改。
a = [1,4,3,2,8]print(sorted(a))
print(sorted(a, reverse=True))[1, 2, 3, 4, 8]
[8, 4, 3, 2, 1]We may need to sort a list or pandas series when doing data cleaning and processing. Sorted can also be used to sort the characters of a string but it returns a list.
进行数据清理和处理时,我们可能需要对列表或熊猫系列进行排序。 Sorted也可以用于对字符串的字符进行排序,但是它返回一个列表。
c = "science"
print(sorted(c))
['c', 'c', 'e', 'e', 'i', 'n', 's']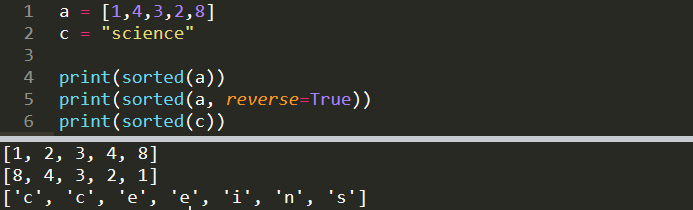
6.邮编 (6. Zip)
Zip function takes iterables as argument and returns an iterator consists of tuples. Consider we have two associated lists.
Zip函数将Iterables作为参数,并返回由元组组成的迭代器。 考虑我们有两个关联的列表。
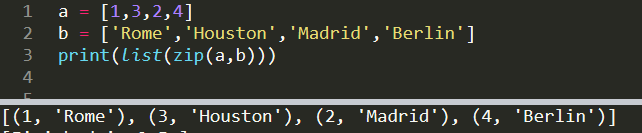
a = [1,3,2,4]
b = ['Rome','Houston','Madrid','Berlin']print(list(zip(a,b)))
[(1, 'Rome'), (3, 'Houston'), (2, 'Madrid'), (4, 'Berlin')]The iterables do not have to have the same length. The first matching indices are zipped. For instance, if list a was [1,3,2,4,5] in the case above, the output would be the same. Zip function can also take more than two iterables.
可迭代对象的长度不必相同。 首个匹配索引已压缩。 例如,如果在上述情况下列表a为[1,3,2,4,5],则输出将相同。 Zip函数也可以采用两个以上的可迭代项。
7.任何和全部 (7. Any and All)
I did not want to separate any and all functions because they are kind of complement of each other. Any returns True if any element of an iterable is True. All returns True if all elements of an iterable is True.
我不想分离任何和所有功能,因为它们互为补充。 如果iterable的任何元素为True,则Any返回True。 如果iterable的所有元素均为True,则All返回True。
One typical use case of any and all is checking the missing values in a pandas series or dataframe.
任何一种情况的一个典型用例是检查熊猫系列或数据框中的缺失值。
import pandas as pd
ser = pd.Series([1,4,5,None,9])print(ser.isna().any())
print(ser.isna().all())True
False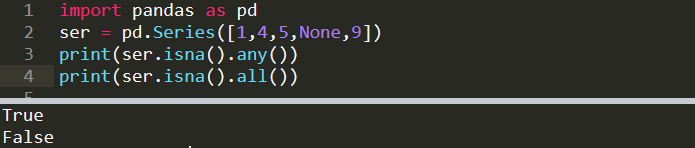
8.范围 (8. Range)
Range is an immutable sequence. It takes 3 arguments which are start, stop, and step size. For instance, range(0,10,2) returns a sequence that starts at 0 and stops at 10 (10 is exclusive) with increments of 2.
范围是一个不变的序列。 它接受3个参数,分别是start , stop和step size。 例如,range(0,10,2)返回一个序列,该序列从0开始并在10(不包括10)处停止,且增量为2。
The only required argument is stop. Start and step arguments are optional.
唯一需要的参数是stop。 开始和步骤参数是可选的。
print(list(range(5)))
[0, 1, 2, 3, 4]print(list(range(2,10,2)))
[2, 4, 6, 8]print(list(range(0,10,3)))
[0, 3, 6, 9]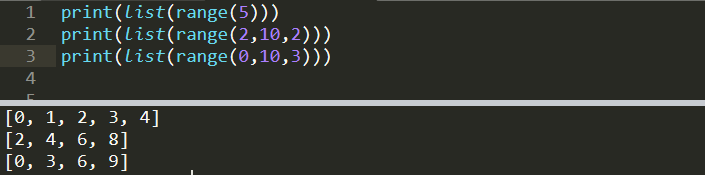
9.地图 (9. Map)
Map function applies a function to every element of an iterator and returns an iterable.
Map函数将一个函数应用于迭代器的每个元素,并返回一个可迭代的对象。
a = [1,2,3,4,5]print(list(map(lambda x: x*x, a)))
[1, 4, 9, 16, 25]We used map function to square each element of list a. This operation can also be done with a list comprehension.
我们使用map函数对列表a的每个元素求平方。 该操作也可以通过列表理解来完成。
a = [1,2,3,4,5]
b = [x*x for x in a]
print(b)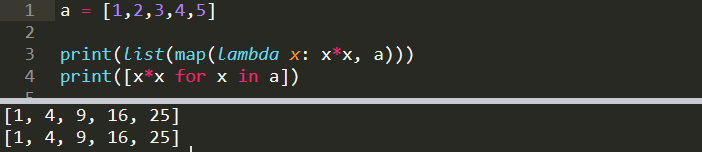
List comprehension is preferable over map function in most cases due to its speed and simpler syntax. For instance, for a list with 1 million elements, my computer accomplished this task in 1.2 seconds with list comprehension and in 1.4 seconds with map function.
在大多数情况下,列表理解比map函数更可取,因为它的速度和语法更简单。 例如,对于具有一百万个元素的列表,我的计算机通过列表理解在1.2秒内完成了此任务,而在使用map功能时在1.4秒内完成了此任务。
When working with larger iterables (much larger than 1 million), map is a better choice due to memory issues. Here is a detailed post on list comprehensions if you’d like to read further.
当使用较大的可迭代对象(远大于100万)时,由于内存问题,映射是更好的选择。 如果您想进一步阅读,这是有关列表理解的详细信息。
10.清单 (10. List)
List is a mutable sequence used to store collections of items with same or different types.
列表是一个可变序列,用于存储相同或不同类型的项目的集合。
a = [1, 'a', True, [1,2,3], {1,2}]print(type(a))
<class 'list'>print(len(a))
5a is a list that contains an integer, a string, a boolean value, a list, and a set. For this post, we are more interested in creating list with a type constructor (list()). You may have noticed that we used list() throughout this post. It takes an iterable and converts it to a list. For instance, map(lambda x: x*x, a) creates an iterator. We converted to a list to print it.
a是一个包含整数,字符串,布尔值,列表和集合的列表。 对于本文,我们对使用类型构造函数(list())创建列表更感兴趣。 您可能已经注意到,本文中我们一直使用list()。 它需要一个可迭代的并将其转换为列表。 例如,map(lambda x:x * x,a)创建一个迭代器。 我们将其转换为列表以进行打印。
We can create a list from a range, set, pandas series, numpy array, or any other iterable.
我们可以从范围,集合,熊猫系列,numpy数组或任何其他可迭代对象创建列表。
import numpy as npa = {1,2,3,4}
b = np.random.randint(10, size=5)
c = range(6)print(list(a))
[1, 2, 3, 4]print(list(b))
[4, 4, 0, 5, 3]print(list(c))
[0, 1, 2, 3, 4, 5]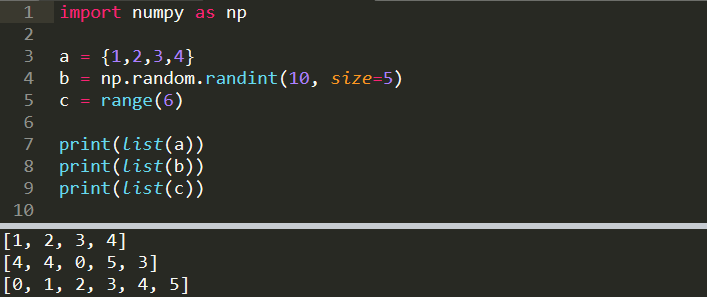
Thank you for reading. Please let me know if you have any feedback.
感谢您的阅读。 如果您有任何反馈意见,请告诉我。
python内置函数多少个















 772
772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









