





递归函数基例和链条
因果推论 (Causal Inference)
This is the fifth post on the series we work our way through “Causal Inference In Statistics” a nice Primer co-authored by Judea Pearl himself.
这是本系列的第五篇文章,我们通过“因果统计推断”一书进行工作,这本由Judea Pearl本人合着的不错的入门文章。

You can find the previous post here and all the we relevant Python code in the companion GitHub Repository:
您可以在此处找到相关的上一篇文章以及相关的GitHub存储库中所有与我们相关的Python代码:
While I will do my best to introduce the content in a clear and accessible way, I highly recommend that you get the book yourself and follow along. So, without further ado, let’s get started!
尽管我会尽力以清晰易懂的方式介绍内容,但我强烈建议您自己拿书并继续学习。 因此,事不宜迟,让我们开始吧!
In the previous four posts I, II, III, IV, we covered Chapter I of the book where Pearl lays down the mathematical and conceptual foundations for Causal Inference. In this post we start diving into Chapter II where we diver more deeply into Graphical Models and Their Applications.
在前四, 第一 , 第二 , 第三和第四篇文章中 ,我们介绍了本书的第一章,其中Pearl为因果推理奠定了数学和概念基础。 在这篇文章中,我们开始深入研究第二章,在第二章中我们将更深入地探讨图形模型及其应用。
2.2链条和叉子 (2.2 Chains and Forks)
Structural causal models allow us to encode causal mechanisms that represent the data generating process. In their graphical form, they make it easy to quickly (and often visually) to detect interdependencies in the data and enable us to reason about the model and its correctness.
结构因果模型使我们能够编码代表数据生成过程的因果机制。 通过它们的图形形式,它们使快速(通常在视觉上)易于检测数据中的相互依赖性,并使我们能够对模型及其正确性进行推理。
The Graphical Model directly and explicitly encodes which variables depend on which others, which variables are independent conditional on other variables, etc.
图形模型直接和显式地编码哪些变量取决于哪些变量,哪些变量是独立于其他变量的条件等。
Pearl illustrates this point with three simple Structural Causal Models that all have the same Graphical Model:
Pearl用三个简单的因果模型说明了这一点,它们都具有相同的图形模型:
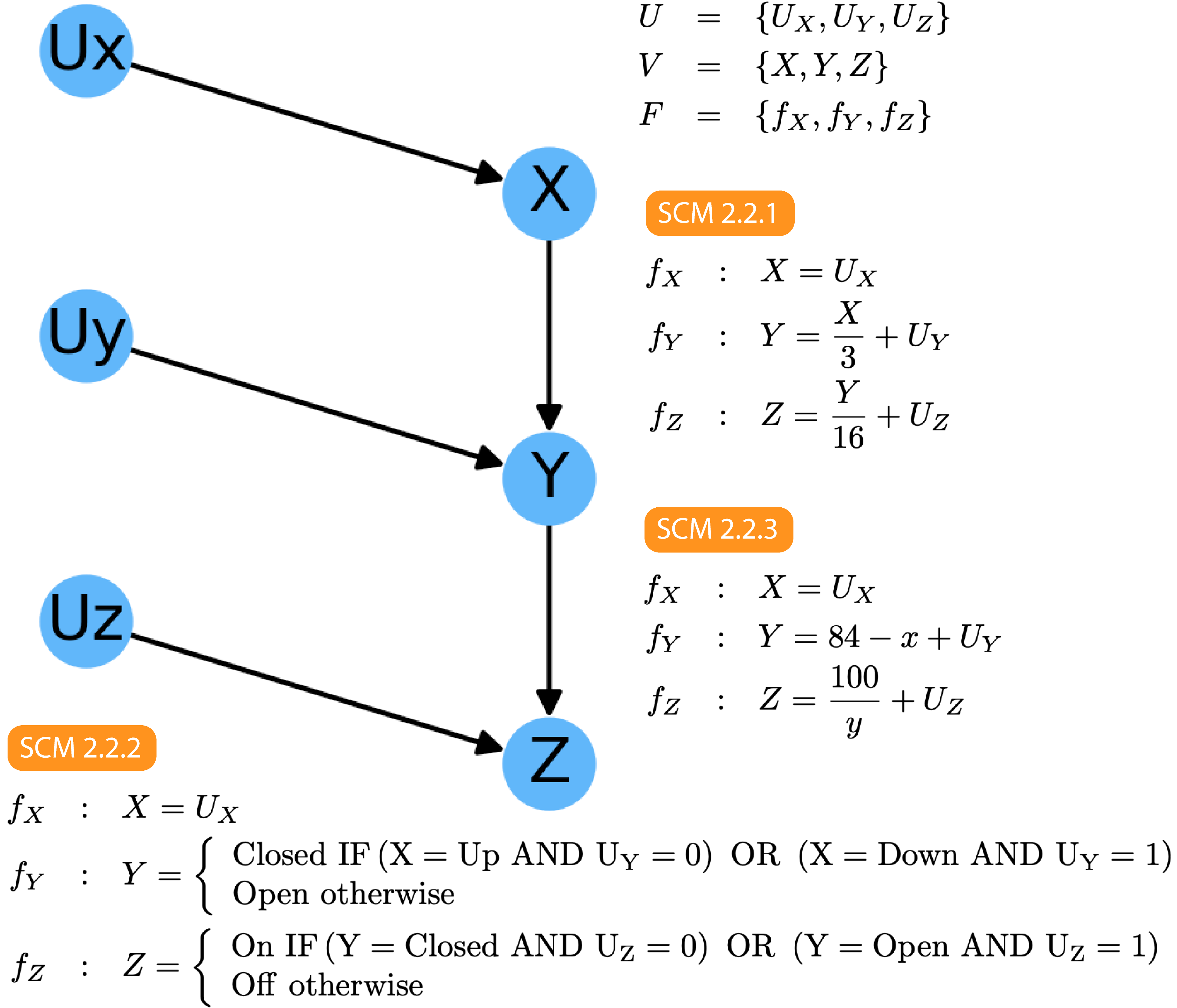
Regardless of what the exact form of the functions in F, just by inspection of the graphical model we can immediately say:
无论F中函数的确切形式是什么,仅通过检查图形模型,我们都可以立即得出以下结论:
Z and Y are dependent — P(Z|Y) ≠ P(Z)
Z和Y取决于 — P(Z | Y)≠P(Z)
Y and X are dependent — P(Y|Z) ≠ P(Y)
Y和X是依赖的 -P(Y | Z)≠P(Y)
Z and X are likely dependent — P(Z|X)≠P(Z)
Z和X可能是依赖的 -P(Z | X)≠P(Z)
Z and X are independent conditional on Y— P(Z|X, Y)=P(Z|Y)
Z和X在Y — P(Z | X,Y)= P(Z | Y) 上为独立条件
The first two items are easy to understand and refine the fundamental rule of Graphical models:
前两项很容易理解并完善了图形模型的基本规则:
Rule 0 (Edge dependency) — Any two variables with a directed edge between them are dependent
规则0(边依存性)-两个有向边的变量都是依存的
This is easy to understand as the formula for one explicitly requires the value for the other. Point 3 is a bit trickier. Z depends on Y that depends on X so, by transitivity, we can also expect that Z depends on X. However, it is possible that the specific forms of fY and fZ break this dependency. The book refers to this possibility as a “Pathological Case of Intransitive Dependence”: something uncommon that non the less we should be aware of.
这很容易理解,因为其中一个的公式明确要求另一个的值。 第三点有点棘手。 Z取决于依赖于X的Y,因此,通过传递性 ,我们还可以期望Z依赖于X。但是,fY和fZ的特定形式可能会打破这种依赖关系。 该书将这种可能性称为“ 不及物依赖的病理学案例 ”:这是我们不应该意识到的罕见现象。
Point 4 is the most interesting of all and, while apparently non-trivial it is easy to understand. If we look in our dataset and find out what the current value of Y is, that immediately helps us determine what the value of Z is (using P(Z|Y)). On the other hand, fixing the value of Y essentially isolates X from Z. Changes in the value of X are compensated by changes in the value o Uy such that Y remains fixed. This is defined in the book as:
第4点是所有内容中最有趣的一点,尽管很简单,但很容易理解。 如果我们查看数据集并找出Y的当前值是什么,那将立即帮助我们确定Z的值是什么(使用P(Z | Y))。 另一方面,固定Y的值本质上将X与Z隔离开。X值的变化由o Uy的值变化所补偿,以使Y保持固定。 在书中定义为:
Rule 1 (Conditional Independence on Chains) — Two variables, X and Y, are conditionally independent given Z, if there is only one unidirectional path between X and Y and Z is any set of variables that intercepts that path.
规则1(链上的条件独立性)—如果X和Y之间只有一条单向路径,并且Z是截断该路径的任何一组变量,则给定Z时,两个变量X和Y在条件上是独立的。
A fundamental assumption underlying Rule 1 is that the error terms Ux, Uy, and Uz are independent.
规则1的基本假设是误差项Ux,Uy和Uz是独立的。
On the other hand, if our DAG looks like this:
另一方面,如果我们的DAG如下所示:
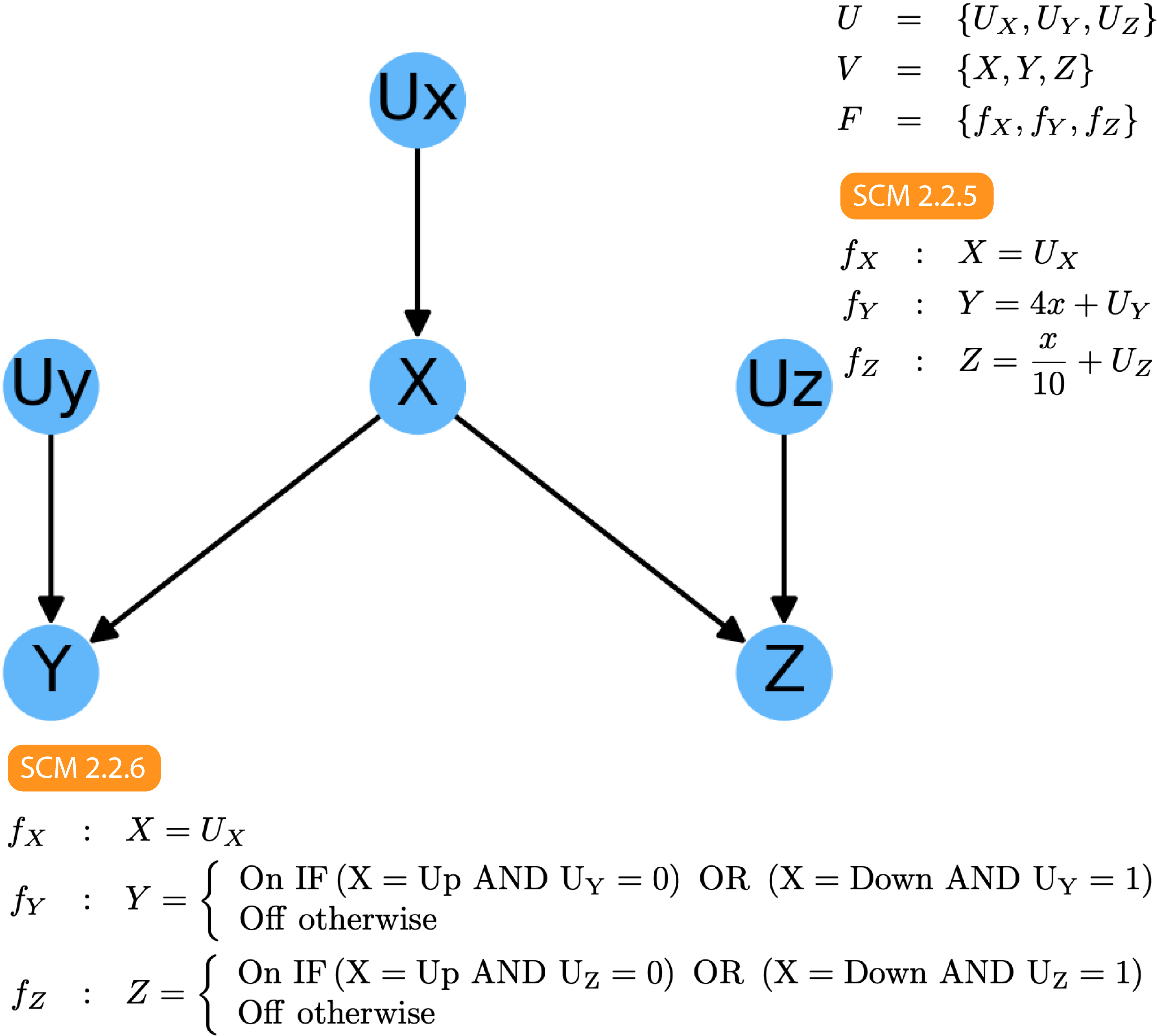
Then, following a similar reasoning, we can immediately know that:
然后,按照类似的推理,我们可以立即知道:
X and Y are dependent — P(X|Y)≠P(X)
X和Y是依赖的 -P(X | Y)≠P(X)
X and Z are dependent — P(X|Z)≠P(Z)
X和Z是依赖的 -P(X | Z)≠P(Z)
Z and Y are likely dependent — P(Z|Y)≠P(Z)
Z和Y很可能是依赖的 -P(Z | Y)≠P(Z)
Y and Z are independent, conditional on X — P(Y|Z, X)=P(Y|X)
Y和Z是独立的,并取决于X — P(Y | Z,X)= P(Y | X)
Points 1 and 2 follow directly from Rule 0. Point 3 is a logical consequence of the fact that Z and Y have a common cause: any specific value of X will result in specific values of Y and Z making them correlated across all values of X.
点1和2直接从规则0得出。点3是Z和Y具有共同原因的逻辑结果:X的任何特定值都将导致Y和Z的特定值,从而使它们在X的所有值之间相关。
Finally, Point 4 requires a bit more thinking to properly understand, but is directly related to Point 3. If we fix the value of X, Y and Z are only allowed to vary due to their respective Uy and Uz which we assume to be independent. This result is summarized in Rule 2:
最后,第4点需要更多的思考才能正确理解,但与第3点直接相关。如果我们固定X,Y和Z的值,则仅由于它们各自的Uy和Uz(我们认为是独立的)而被允许变化。 。 规则2中汇总了此结果:
Rule 2 (Conditional Independence in Forks) — If a variable X is a common cause of variables Y and Z, and there is only one path between Y and Z, then Y and Z are independent conditional on X.
规则2(分叉中的条件独立性)—如果变量X是变量Y和Z的常见原因,并且Y和Z之间只有一条路径,则Y和Z是X的独立条件。
Congratulations on making it this far in these blog post series. I sincerely hope that you continue to enjoy reading them as much as I enjoy writing them.
祝贺您在这些博客文章系列中取得了如此长的成就。 我衷心希望您继续喜欢阅读它们,就像我喜欢写它们一样。
Just a quick reminder that you can find the code for all the examples above in our GitHub repository:
谨在此提醒您,您可以在我们的GitHub存储库中找到上述所有示例的代码:
And if you would like to be notified when the next post comes out, you can subscribe to the The Sunday Briefing newsletter:
而且,如果您希望在下一篇文章发表时得到通知,可以订阅《星期日简报》时事通讯:
翻译自: https://medium.com/data-for-science/causal-inference-part-v-chains-and-forks-7b0b088c346e
递归函数基例和链条
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









