





instagram分享
重点 (Top highlight)
Instagram Server is entirely Python powered.
Instagram服务器完全由Python驱动。
Well, mostly. There’s also some Cython, and our dependencies include a fair amount of C++ code exposed to Python as C extensions.
好吧,主要是。 还有一些Cython,我们的依赖项包括大量作为C扩展公开给Python的C ++代码。
Our server app is a monolith, one big codebase of several million lines and a few thousand Django endpoints [1], all loaded up and served together. A few services have been split out of the monolith, but we don’t have any plans to aggressively break it up.
我们的服务器应用程序是一个整体,一个包含几百万行的大型代码库和几千个Django端点[1],它们都已加载并一起使用。 一些服务已从整体中分离出来,但是我们没有任何计划将其拆分。
And it’s a fast-moving monolith; we have hundreds of engineers shipping hundreds of commits every day. We deploy those commits continuously, every seven minutes, typically deploying to production around a hundred times per day. We aim to keep less than an hour of latency between a commit landing in master and going live in production. [2]
这是一块快速移动的巨石。 我们有数百名工程师每天发送数百项承诺。 我们每七分钟连续部署一次这些提交,通常每天部署约一百次。 我们的目标是在提交提交到主服务器和正式投入生产之间保持不到一小时的延迟。 [2]
It’s really, really difficult to keep this massive monolithic codebase, hurtling along at hundreds of commits per day, from devolving into complete chaos. We want to make Instagram a place where all our engineers can be productive and ship useful features quickly!
保持庞大的整体式代码库(每天处理数百次提交)变得完全混乱是非常非常困难的。 我们希望使Instagram成为所有我们的工程师都可以提高工作效率并快速发布有用功能的地方!
This post is about how we’ve used linting and automated refactoring to help manage the scale of our Python codebase. In the next few weeks, we’ll share more details of other tools and techniques we’ve developed to manage other aspects of our codebase’s quality.
这篇文章是关于我们如何使用lint和自动重构来帮助管理Python代码库的规模的。 在接下来的几周中,我们将分享为管理代码库质量的其他方面而开发的其他工具和技术的更多细节。
If you’re interested in trying out some of the ideas mentioned in this post, we recently open-sourced LibCST which serves as the heart of many of our internal linting and automated refactoring tools.
如果您有兴趣尝试这篇文章中提到的一些想法,那么 我们最近开放了LibCST的源代码 ,它是我们许多内部整理和自动重构工具的核心。
[1] For more about how we use Django, watch the talk “Django at Instagram” we gave at Django Under the Hood conference in 2016.[2] For more on our continuous deployment, watch the talk “Releasing the world’s largest Python site every seven minutes” we gave at PyCon 2019.
[1]有关如何使用Django的更多信息,请观看我们在2016年的Django Under the Hood会议上发表的“ Instagram上的Django”演讲。[2] 有关我们持续部署的更多信息,请观看我们在PyCon 2019上发表的演讲`` 每七分钟发布一次全球最大的Python站点'' 。
Linting:按需文档 (Linting: Documentation On-Demand)
Linting helps developers find and diagnose issues or anti-patterns they may not have known about as they encounter them. This is important for us, because with hundreds of engineers it becomes increasingly difficult to disseminate these ideas.
整理可以帮助开发人员发现和诊断他们遇到的问题或反模式。 这对我们很重要,因为随着数百名工程师的努力,传播这些想法变得越来越困难。

Linting is just one of many forms of static analysis that we use within Instagram. The naive way of implementing a lint rule is with a regular expression. Regular expressions are easy to write, but Python is not a regular language, and so it’s difficult (or sometimes impossible) to robustly match a pattern in the code with a regular expression.
整理只是我们在Instagram中使用的多种静态分析形式之一。 实现棉绒规则的幼稚方式是使用正则表达式。 正则表达式很容易编写,但是Python 不是正则语言 ,因此很难(有时甚至是不可能)将代码中的模式与正则表达式进行健壮匹配。
On the other end of the spectrum, we have tools like mypy and Pyre, two Python static type checkers, which can do whole-program analysis. Instagram uses Pyre. These tools are powerful, but hard to extend and customize.
另一方面,我们拥有mypy和Pyre之类的工具,这是两个Python静态类型检查器,它们可以进行整个程序分析。 Instagram使用Pyre。 这些工具功能强大,但是很难扩展和定制。
When we talk about linting at Instagram, we’re usually referring to simple abstract syntax tree based lint rules. This is how we typically write custom lint rules for Instagram’s server codebase.
当我们在Instagram上谈论棉绒时,通常是指基于简单抽象语法树的棉绒规则。 这就是我们通常为Instagram服务器代码库编写自定义棉绒规则的方式。
When Python executes a module, it starts by running a parser over the source code. That implicitly creates a parse tree, a kind of concrete syntax tree (CST). This parse tree is a lossless representation of the input source code. Every detail, like comments, parenthesis, and commas are preserved in this tree. We could regenerate the original source code using this tree.
当Python执行模块时,它首先在源代码上运行解析器。 隐式创建一个解析树,一种具体的语法树(CST) 。 该解析树是输入源代码的无损表示形式。 该树中保留了每个详细信息,例如注释,括号和逗号。 我们可以使用该树重新生成原始源代码。

Unfortunately, this creates a complex tree, making it hard to extract the semantics we care about.
不幸的是,这创建了一个复杂的树,使我们难以提取我们关心的语义。
Python compiles the parse tree into an abstract syntax tree, or AST. This is a lossy conversion, and details about “syntactic trivia”, like comments, parenthesis, and commas are thrown away. However, the semantics of the code are preserved.
Python将解析树编译成抽象语法树或AST。 这是有损的转换,有关“语法琐事”的详细信息(如注释,括号和逗号)被丢弃了。 但是,代码的语义得以保留。

At Instagram, we’ve developed LibCST, which provides the best of both worlds. It provides a lossless representation like a concrete syntax tree (CST), but still makes it easy to extract semantics like an abstract syntax tree (AST).
在Instagram, 我们开发了LibCST ,它提供了两全其美的方法。 它提供了像具体语法树(CST)一样的无损表示形式,但是仍然很容易像抽象语法树(AST)这样提取语义。

Our lint rules use LibCST’s syntax tree to match patterns in code. As a high level representation, the syntax tree is easy to inspect and removes the problem of dealing with a non-regular language.
我们的lint规则使用LibCST的语法树来匹配代码中的模式。 作为高级表示,语法树易于检查,并消除了处理非常规语言的问题。
Let’s say that you’ve got a circular dependency in your module due to a type-only import. Python lets you solve this by putting type-only imports behind an if TYPE_CHECKING: guard to avoid actually importing anything at runtime.
假设由于仅类型导入,模块中已经有了循环依赖项。 Python使您可以通过在if TYPE_CHECKING:保护后面放置纯类型导入来解决此问题,从而避免在运行时实际导入任何内容。
# value imports
from typing import TYPE_CHECKING
from util import helper_fn
# type-only imports
if TYPE_CHECKING:
from circular_dependency import CircularTypeLater, someone adds another type-only dependency to the code and guards it. However, they might fail to realize that there was already a type guard in the module.
后来,有人在代码中添加了另一个仅类型的依赖关系并加以保护。 但是,他们可能无法意识到模块中已经存在类型防护。
# value imports
from typing import TYPE_CHECKING
from util import helper_fn
# type-only imports
if TYPE_CHECKING:
from circular_dependency import CircularType
if TYPE_CHECKING: # Whoops! Duplicate type guard!
from other_package import OtherTypeWe can prevent this redundancy with a lint rule!
我们可以使用皮棉规则来防止这种冗余!
We’ll start by initializing a counter of type checking blocks we’ve encountered.
我们将从初始化遇到的类型检查块的计数器开始。
class OnlyOneTypeCheckingIfBlockLintRule(CstLintRule):
def __init__(self, context: Context) -> None:
super().__init__(context)
self.__type_checking_blocks = 0Then, when we encounter a type-checking conditional, we’ll increment the counter, and verify that there is no more than one type checking block. If this happens, we’ll generate a warning at that location by calling our report helper.
然后,当我们遇到类型检查条件时,我们将增加计数器,并验证不超过一个类型检查块。 如果发生这种情况,我们将通过致电报告助手在该位置生成警告。
def visit_If(self, node: cst.If) -> None:
if node.test.value == "TYPE_CHECKING":
self.__type_checking_blocks += 1
if self.__type_checking_blocks > 1:
self.context.report(
node,
"More than one 'if TYPE_CHECKING' section!"
)These lint rules work by traversing LibCST’s tree, and collecting information. In our linter, this is done using the visitor pattern. As you may have noticed, rules override visit and leave methods associated with a node’s types. Those visitors get called in a specific order.
这些皮棉规则通过遍历LibCST的树并收集信息来工作。 在我们的linter中,这是使用visitor模式完成的 。 您可能已经注意到,规则会覆盖与节点类型相关联的访问和离开方法。 这些访客会按特定顺序被呼叫。
class MyNewLintRule(CstLintRule):
def visit_Assign(self, node):
... # called first
def visit_Name(self, node):
... # called for each child
def leave_Assign(self, name):
... # called after all children
Our philosophy at Instagram is to “do the simple thing first”. Our first custom lint rules were implemented in a single file, with a single visitor, using shared state.
Instagram理念是“先做简单的事情”。 我们的第一个自定义皮棉规则是使用共享状态在一个文件中,一个访问者中实现的。

The single visitor class had to be aware of the state and logic of all of our unrelated lint rules, and it wasn’t always clear what state corresponded with what rule. This works fine when you’ve got a few custom lint rules, but we have nearly a hundred custom lint rules, which made the single-visitor pattern unmaintainable.
单个访问者类必须了解我们所有不相关的皮棉规则的状态和逻辑,而且并不总是清楚什么状态与什么规则相对应。 当您有一些自定义棉绒规则时,这很好用,但是我们有近一百个自定义棉绒规则,这使得单访客模式无法维护。

Of course, one possible solution to this problem is to define multiple visitors and to have each visitor re-traverse the entire tree each time. However, this would incur a large performance penalty, and the linter must remain fast.
当然,解决此问题的一种可能方法是定义多个访客,并使每个访客每次都重新遍历整棵树。 但是,这将导致较大的性能损失,并且短绒必须保持快速。
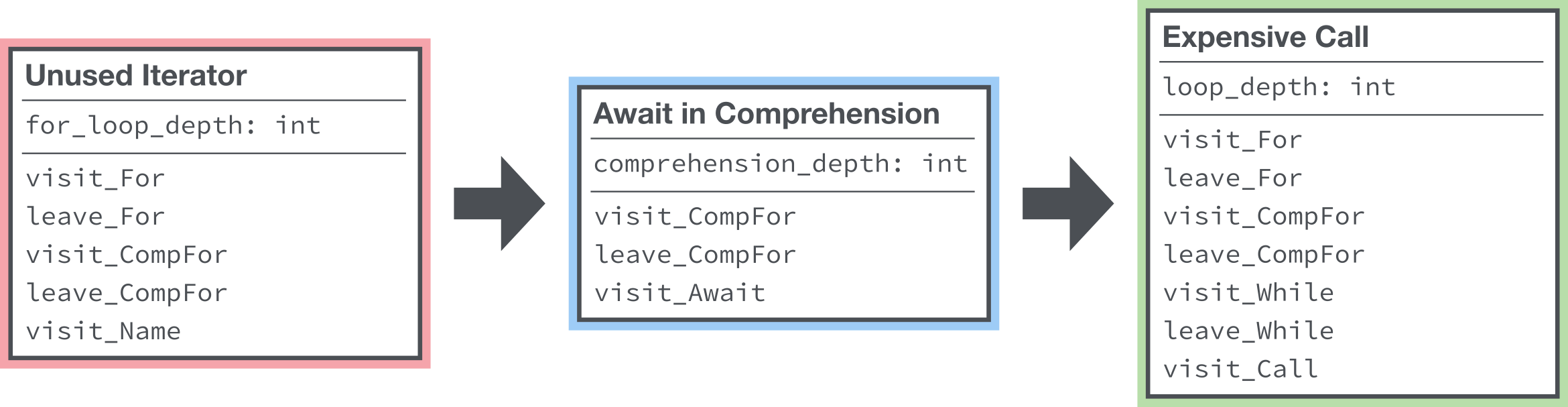
Instead, we took inspiration from linters in other language ecosystems, like JavaScript’s ESLint, and developed a centralized visitor registry.
相反,我们从其他语言生态系统(如JavaScript的ESLint)中获得了灵感,并开发了集中式访客注册表。

When a lint rule is initialized, all of the rule’s method overrides are stored in the registry. When we traverse the tree, we look up all of the registered visitors and call them. If a method is not implemented, we don’t need to call it.
初始化lint规则后,该规则的所有方法替代都存储在注册表中。 当我们遍历树时,我们会查找所有已注册的访问者并将其称为。 如果未实现方法,则无需调用它。
This reduces the computation cost of every new lint rule. Though we usually run the linter over the small number of recently changed files, we can run all of our new lint rules in parallel over Instagram’s whole server codebase in just 26 seconds.
这减少了每个新的皮棉规则的计算成本。 尽管我们通常在少数最近更改的文件上运行linter,但我们可以在短短26秒内在Instagram整个服务器代码库上并行运行所有新的lint规则。
Once we had a performant framework in place, we built a testing framework that works to enforce best practices by requiring tests for both false-positives, and false-negatives.
一旦建立了性能框架,我们就建立了一个测试框架,该框架通过要求对误报和误报进行测试来实施最佳实践。
class MyCustomLintRuleTest(CstLintRuleTest):
RULE = MyCustomLintRule
VALID = [
Valid("good_function('this should not generate a report')"),
Valid("foo.bad_function('nor should this')"),
]
INVALID = [
Invalid("bad_function('but this should')", "IG00"),
]皮棉疲劳 (Lint Fatigue)
With nearly a hundred custom rules, pedantic lints can quickly turn into a waste of time for developers. Spending time fixing style nits and deprecated coding patterns gets in the way of more important progress.
借助近百个自定义规则,学究的皮棉会很快变成开发人员的时间浪费。 花费时间修复样式问题和不建议使用的编码模式会阻碍更重要的进展。
We’ve found that with too many nags engineers start to ignore all lints, even the important ones. At a certain point, it doesn’t matter what good advice we present, it just gets ignored.
我们发现,由于na太多,工程师开始忽略所有绒毛,即使是重要的绒毛。 在某个时候,我们提出的好建议并不重要,只是被忽略了。
Let’s say we needed to deprecate a function named ‘fn’ for a better named function called called ‘add’. Unless developers are made aware of the fact that ‘fn’ is deprecated, they won’t know not to use it. Even worse, they won’t know what to use instead. So, we can create a lint. But any sufficiently large codebase is bound to have plenty of other lints already. Chances are that this important lint will get lost in the noise.
假设我们需要弃用名为“ fn”的函数,以获得一个名为“ add”的更好命名的函数。 除非开发人员意识到'fn'已被弃用,否则他们不会不使用它。 更糟糕的是,他们不知道该用什么。 因此,我们可以创建一个皮棉。 但是,任何足够大的代码库注定都已经有很多其他功能。 这种重要的棉绒很可能会在噪音中迷失。

So, what can we do about it?
那么我们能做些什么呢?
We can automatically fix many issues found by lint. Much like lint itself is documentation on demand, auto-fixers can provide fixes on-demand. Given the sheer number of developers at Instagram, it’s not feasible to teach each developer all of our best practices. Adding auto-fixers allows us to educate and on-board developers to new best practices on-demand. Auto-fixers also allow us to preserve developer focus by removing monotonous changes. Essentially, auto-fixers are more actionable and educational than simple lint warnings.
我们可以自动修复lint发现的许多问题。 就像皮棉本身就是按需文档一样,自动修复程序可以按需提供修复程序。 鉴于Instagram上开发人员的数量众多,向每个开发人员教授我们所有的最佳实践是不可行的。 添加自动修复程序使我们可以按需培训新手最佳实践。 自动修复程序还允许我们通过消除单调的更改来保持开发人员的注意力。 从本质上讲,自动修复程序比简单的棉绒警告更具操作性和教育意义。
So, how do you build an auto-fixer? Syntax tree based linting gives us the offending node. There’s no need to duplicate discovery logic since the lint rule itself already exists! Since we know the node we want to replace, and we know its location in source, we can replace it with the updated function name safely! This works great for fixing individual lint violations as they are introduced, but when we introduce a new lint rule we may have hundreds of existing violations of it. Can we proactively resolve all the existing cases at once?
那么,您如何构建自动修复程序? 基于语法树的棉绒给了我们令人讨厌的节点。 由于棉绒规则本身已经存在,因此无需重复发现逻辑! 由于我们知道要替换的节点,并且知道其在源代码中的位置,因此可以安全地用更新的函数名称替换它! 这对于修复引入的单个皮棉违规非常有用,但是当我们引入新的皮棉规则时,可能已有数百种现有的对它的违规。 我们可以一次解决所有现有案件吗?
Codemods (Codemods)
A codemod is just a scriptable way to find issues and make changes to source code. Think of a codemod as a refactor on steroids: It can be as simple as renaming a variable in a function or as complex as rewriting a function to take a new argument. It uses the exact same concept as a lint, but instead of alerting the developer, it can take action automatically.
Codemod只是发现问题并更改源代码的脚本编写方式。 将codemod视为对类固醇的重构:它可以像在函数中重命名变量一样简单,也可以像重写函数以采用新参数一样复杂。 它使用与皮棉完全相同的概念,但是它可以自动采取措施,而不是警告开发人员。
So, why would you write a codemod instead of a lint? In this example, we want to deprecate the use of get_global. We could use a lint, but the fix time is unbounded and spread across multiple developers. Even with an auto fixer in place, it can be some time before all code is upgraded.
那么,为什么要编写codemod而不是皮棉呢? 在此示例中,我们要弃用get_global 。 我们可以使用皮棉,但是修复时间不受限制,并且分散在多个开发人员中。 即使安装了自动修复程序,也可能需要一段时间才能升级所有代码。

To fix this, in addition to linting against get_global, we can also write a codemod! At Instagram, we believe that deprecated patterns and APIs left to slowly wither away take focus away from developers and reduce code readability. We’d rather proactively remove deprecated code than let it disappear over time. Given the sheer size of the code and number of active developers, this often means automating deprecations. If we can remove deprecated patterns from our code quickly, we keep all of Instagram productive.
为了解决这个问题,除了针对get_global ,我们还可以编写一个codemod! 在Instagram上,我们认为缓慢弃用的不赞成使用的模式和API会将焦点转移到开发人员身上,并降低了代码的可读性。 我们宁愿主动删除不推荐使用的代码,也不愿随时间消失。 考虑到代码的巨大规模和活跃的开发人员的数量,这通常意味着自动化弃用。 如果我们可以快速从代码中删除不推荐使用的模式,那么我们将使所有Instagram保持高效。
Okay, so how do you actually codemod? How do you replace just the text you care about, while preserving comments, spacing, and everything else? You can use a concrete syntax tree like LibCST to surgically modify code while preserving comments and spacing. So, if I wanted to rename “fn” to “add” in the below tree, I would update the Name node to have the value “add” instead of “fn” and then write the tree back to disk!
好吧,那么您实际上如何进行代码调制? 在保留注释,空格和其他所有内容的同时,如何只替换您关心的文本? 您可以使用像LibCST这样的具体语法树来通过外科手术修改代码,同时保留注释和空格。 因此,如果要在下面的树中将“ fn”重命名为“ add”,则将“名称”节点更新为值“ add”而不是“ fn”,然后将树写回到磁盘!
Now that we know a bit about codemods, let’s look at a practical example. Instagram has been working hard on getting to a fully typed codebase, and we’ve made a lot of progress using codemods.
现在我们对codemods有所了解,让我们看一个实际的例子。 Instagram一直在努力开发完全类型化的代码库,并且我们在使用codemods方面取得了很多进展。
Given a body of untyped functions, we can try to generate return types by simple inference! For example, if a function returns only one primitive type, we assign it that return type. If a function returns the result of a boolean operation such as a comparison or “isinstance”, we assign it a bool return type. We found that in practice this is a pretty safe operation to perform across Instagram’s codebase.
给定大量无类型的函数,我们可以尝试通过简单的推断来生成返回类型! 例如,如果一个函数仅返回一种原始类型,则我们将其分配给该返回类型。 如果函数返回布尔运算的结果(例如比较或“实例”),则我们为其分配布尔返回类型。 我们发现在实践中,这是在Instagram代码库中执行的相当安全的操作。

Well, what if a function doesn’t explicitly return or it implicitly returns None? if a function doesn’t explicitly return a type, assign it a None type. Unlike the last example, this can be more dangerous due to common developer patterns. For example, I might throw a NotImplemented exception in a base class method and return a string in all subclass overrides. Its important to note that all of these techniques are a heuristic, but they turn out to be right often enough to be useful!
好吧,如果一个函数没有显式返回或隐式返回None怎么办? 如果函数未明确返回类型,则将其分配为None类型。 与最后一个示例不同,由于常见的开发人员模式,这可能更加危险。 例如,我可能会在基类方法中引发NotImplemented异常,并在所有子类重写中返回一个字符串。 重要的是要注意,所有这些技术都是一种启发式方法,但事实证明它们经常是正确的,对您有用!

用Pyre增强Codemod (Enhancing Codemods with Pyre)
Let’s take it a step further. Instagram uses Pyre, a full-program static type checker similar to mypy, to verify types in our codebase. What if we used Pyre’s output in order to make this codemod more powerful? As you can see in the below Pyre output snippet, Pyre gives us basically everything we need to fix up annotations automatically!
让我们更进一步。 Instagram使用Pyre(类似于mypy的全程序静态类型检查器)在我们的代码库中验证类型。 如果我们使用Pyre的输出以使此codemod更强大怎么办? 如下面的Pyre输出片段所示,Pyre基本上为我们提供了自动修复注释所需的一切!
$ pyre
ƛ Found 2 type errors!
testing/utils.py:7:0 Missing return annotation [3]: Returning `SomeClass` but no return type is specified.
testing/utils.py:10:0 Missing return annotation [3]: Returning `testing.other.SomeOtherClass` but no return type is specified.When pyre runs it constructs a detailed analysis of control flow in each function. So, it can sometimes have a pretty good guess as to what an unannotated function should be returning. This means that if pyre thinks that a function returns a simple type, then we assign it that return type. However, now we potentially have to handle imports. Which means we have to know if something is already imported or is defined locally. I’ll touch a little bit on how we figure that out later.
运行柴堆时,它将对每个功能的控制流进行详细分析。 因此,对于未注释的函数应该返回什么,有时可能会有一个很好的猜测。 这意味着,如果pyre认为函数返回简单类型,则我们将其分配给该返回类型。 但是,现在我们可能必须处理进口。 这意味着我们必须知道某些东西是否已经导入或在本地定义。 我将在稍后讨论我们如何解决这一问题。
What benefit do we get from automatically adding easy to infer types? Well, types are documentation! If a function is fully typed, developers don’t have to read the code to understand its pre- and post-conditions.
通过自动添加易于推断的类型,我们可以获得什么好处? 好吧,类型就是文档! 如果函数是完全类型化的,则开发人员无需阅读代码即可了解其前提条件。
def get_description(page: WikiPage) -> Optional[str]:
if page.draft:
return None
return page.metadata["description"] # <- what type is this?Lots of us have run into Python code like this, and Instagram’s code is no exception. If get_description was not typed, I might have to look at multiple source modules to figure out what exactly this function returns. Even for simpler functions that are easy to infer, function definitions with types are much easier for humans to read.
我们很多人都遇到过这样的Python代码,Instagram代码也不例外。 如果未键入get_description ,则可能必须查看多个源模块才能弄清楚此函数返回的内容。 即使对于易于推断的简单函数,带有类型的函数定义对于人类来说也更容易理解。
Also, Pyre doesn’t evaluate correctness inside a function body unless the function itself is fully annotated. In the below example, it would be nice to know that our call to some_function is going to crash before it gets to production.
同样,Pyre不会评估函数体内的正确性,除非对函数本身进行完全注释。 在下面的示例中,很高兴知道我们对some_function的调用将在生产之前崩溃。
def some_function(in: int) -> bool:
return in > 0
def some_other_function():
if some_function("bla"): # <- should get a type violation
print("Yay!")In this case we will end up learning the hard way because some_other_function is missing a return annotation! If we had auto-inferred a “None” return type using our heuristic, we would find out about this issue before it causes a problem. This example is obviously contrived, but the issue remains an important one for Instagram. If you have millions of lines of code, you end up missing seemingly obvious problems like this during reviews.
在这种情况下,由于some_other_function缺少返回注释,我们最终将学习困难。 如果我们使用启发式方法自动推断出“无”返回类型,则可以在此问题引起问题之前就对其进行查找。 这个例子显然是人为设计的,但对于Instagram来说,这个问题仍然很重要。 如果您有数百万行代码,那么最终在审查过程中会丢失看起来如此明显的问题。
At Instagram, these simple inferences got us an almost 10% boost to functions typed. That adds up to thousands upon thousands of functions that a human no longer has to fix up. The benefits of better typed code are obvious, but leads to yet another benefit: Having a fully-typed codebase unlocks even more advanced codemods.
在Instagram上,这些简单的推论使我们将键入的函数提升了近10%。 这就增加了人们不再需要修复的成千上万的功能。 更好地键入代码的好处是显而易见的,但是却带来了另一个好处:拥有完全键入的代码库可以解锁甚至更高级的代码模块。
If we trust our type annotations then we can use Pyre to unlock additional possibilities. Lets look back at our function renaming example. What if the function we’re renaming is a class method, not a global function?
如果我们相信类型注释,那么我们可以使用Pyre来解锁其他可能性。 让我们回顾一下函数重命名示例。 如果我们要重命名的函数是类方法而不是全局函数怎么办?

If we pair type information we get from pyre with a rename codemod, we can suddenly fix up the call sites as well as the definition! In this example, since we know the left hand side of a.fn, we know that it is safe to rename to a.add.
如果我们将来自pyre的类型信息与重命名codemod配对,则我们可以突然修复调用站点以及定义! 在此示例中,由于我们知道a.fn的左侧,因此我们知道将其重命名为a.add是安全的。
更高级的静态分析 (More Advanced Static Analysis)

We can unlock more powerful codemods with scope analysis. Remember the problem from earlier, where adding type hints meant that we had to potentially add imports? If you have scope analysis then you know what types used in the file come from imports, which ones are defined locally, and which types are missing. Similarly, if you know that a global variable is shadowed by a function argument, you can avoid accidentally changing it if you are renaming that global variable.
我们可以通过范围分析来解锁功能更强大的代码模块。 还记得以前的问题吗?添加类型提示意味着我们必须潜在地添加导入? 如果您进行范围分析,那么您将知道文件中使用的哪些类型来自导入,哪些在本地定义以及哪些类型丢失。 同样,如果知道全局变量被函数参数遮盖,则可以避免在重命名该全局变量时意外更改它。
One thing has become clear in our quest to fix all of the problems at Instagram: Finding the code we want to modify is often more important than the modification itself. Often, people want to do simple things, such as renaming a function, adding an argument to a method or splitting a module up. None of these is hard to do, but with the size of our codebase it becomes impossible for a human to find every line that needs modifying. That’s why pairing the ability to codemod with robust static analysis is so important. It allows us to narrow down what pieces of the code we should consider in order to make codemods safer and more powerful.
解决我们在Instagram上所有问题的努力已经变得很明显:找到我们想要修改的代码通常比修改本身更重要。 人们经常想做一些简单的事情,例如重命名功能,在方法中添加参数或拆分模块。 这些都不是很难做到的,但是随着我们代码库的大小,人们不可能找到需要修改的每一行。 这就是为什么将代码调制功能与强大的静态分析配对非常重要的原因。 它使我们能够缩小应考虑的代码范围,以使codemods更安全,更强大。
Many thanks to my team members: Jennifer Taylor (who co-wrote this article), Mark Vismonte, Jimmy Lai, Ray Zeng, Carl Meyer, Anirudh Padmarao, Keith Blaha, and Lee Bierman.
非常感谢我的团队成员:詹妮弗·泰勒(Jennifer Taylor)(共同撰写本文),马克·维斯蒙特,吉米·赖,雷·曾,卡尔·迈耶,阿尼鲁德·帕德玛劳,基思·布拉哈和李·比尔曼。
If you want to learn more about this work or are interested joining one of our engineering teams, please visit our careers page, follow us on Facebook or on Twitter.
如果您想了解更多有关这项工作的信息,或者有兴趣加入我们的工程团队之一,请访问我们的职业页面 , 在Facebook或Twitter上关注我们。
翻译自: https://instagram-engineering.com/static-analysis-at-scale-an-instagram-story-8f498ab71a0c
instagram分享















 815
815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









