





chrome扩展程序
Recently I looked into improving the vocal recognition instance of my chrome extension, orange. Basically, it allows the user to control a webpage with their voice. Primarily I use it to control playback from sites like Netflix, Spotify, and Youtube.
最近,我研究了改进我的Chrome扩展名Orange的声音识别实例。 基本上,它允许用户使用他们的声音来控制网页。 首先,我使用它来控制来自Netflix,Spotify和Youtube等网站的播放。
Here’s a quick demo of the updated version:
这是更新版本的快速演示:
The main issue I had with the older version is the sound from whatever source I was listening to would drown out my voice causing the recognition to mess up.
我使用较旧版本的主要问题是,无论我听什么来源的声音,都会淹没我的声音,导致识别混乱。
In this article I am going to write about some of the techniques I used to improve the voice recognition instance of the extension. I have previously written about the basic workings of the extension which can be found here:
在本文中,我将写一些我用来改进扩展的语音识别实例的技术。 我之前已经写了关于扩展的基本原理的文章,可以在这里找到:
Also it is published to the chrome webstore and can be downloaded here
Polarity Invert
极性反转
The first idea I had to improve the speech recognition involves filtering the browser audio from the mic’s audio stream.
我必须改善语音识别的第一个想法是从麦克风的音频流中过滤浏览器音频。
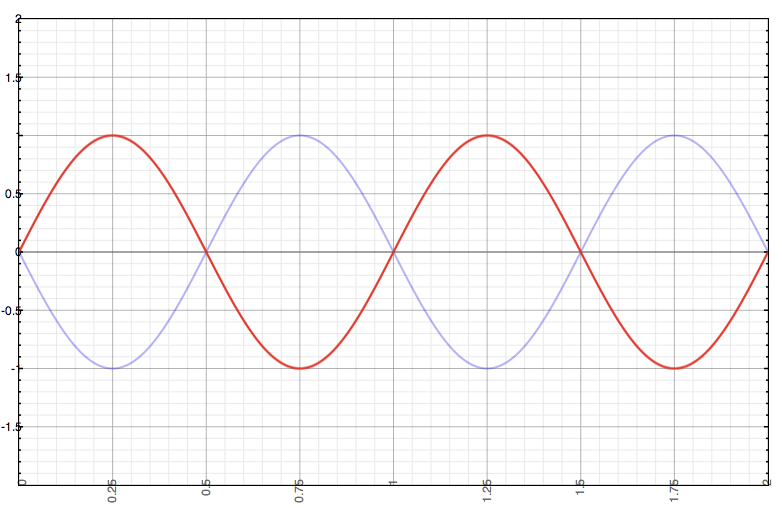
This is similar to a technique I would use while working as an audio engineer. Basically, if you have a duplicate sound and invert the polarity of one of the streams they will cancel each other out. The image below shows two waves that are inverted. When the red wave’s amplitude is at +1 the blue’s is at -1 thus canceling each other out.
这类似于我在担任音频工程师时使用的技术。 基本上,如果您有重复的声音并反转其中一个流的极性,它们将互相抵消。 下图显示了两个反转的波。 当红波的振幅为+1时,蓝波的振幅为-1,因此彼此抵消。
So if I grabbed the browser audio from the browser audio and inverted it; then merged it with the mic input stream it should filter out the unwanted audio in the mic stream leaving just the spoken command word right?
因此,如果我从浏览器音频中获取浏览器音频并将其反转; 然后将其与麦克风输入流合并,它应该过滤掉麦克风流中不需要的音频,而只剩下口头命令字对吗?
Unfortunately this is more complicated than I am making it seem. For the polarity invert technique to work the sounds have to match up completely. The polarity invert technique I describe doesn’t work because it does not account for the transfer function of the acoustic path from the speakers to the microphone.
不幸的是,这比我看起来要复杂得多。 为了使极性反转技术起作用,声音必须完全匹配。 我描述的极性反转技术不起作用,因为它不能解决从扬声器到麦克风的声路传递函数。
However this problem is solvable; using Acoustic Echo Cancellation you can account for the transfer function of the acoustic path. Once I got to this point however I felt like I was reaching a bit to far and decided to look at other alternatives.
但是这个问题是可以解决的。 使用声学回声消除功能,您可以考虑声学路径的传递函数。 一旦达到这一点,我就觉得自己已经走到了很远,并决定考虑其他选择。
Volume Control
音量控制
Stepping back I decided I should just log the output of the recognition and see how it responds when I play the volume from my computer at full. And what I found was the recognition would pick up at least one of the two words in the command (ex. “orange play”) and most of the time it would be “orange”.
退后一步,我决定只记录日志的输出,并查看当我从计算机上完全播放音量时响应如何。 我发现,识别将至少拾取命令中的两个词之一(例如“橙色游戏”),大多数情况下将是“橙色”。
And to get a better idea of how this command event is working here is a diagram.
为了更好地了解此命令事件在此处的工作方式,请使用图表。

As you can see I look for and instance of the word “orange” and then call whatever word is after it. This is the code that needs improvement since I am relying on both words being recognized.
如您所见,我在寻找“ orange”一词的实例,然后调用其后的任何词。 这是需要改进的代码,因为我依靠两个单词都可以被识别。
Since I was able to pick up “orange” most of the time I changed the command event to this:
因为大多数时候我都能拾取“橙色”,所以我将命令事件更改为:

By using a boolean to manage the state of the command event I can improve recognition. When the word “orange” is spoken; the audio in the current browser is lowered and the state is changed to listening. This state will last for around 4 seconds giving the user time to speak their second command word.
通过使用布尔值来管理命令事件的状态,我可以提高识别度。 当说出“橙色”一词时; 当前浏览器中的音频会降低,并且状态会变为聆听。 此状态将持续约4秒钟,使用户有时间说第二个命令字。

One reason I like this method is not only does it improve the recognition but it helps direct the user in how to call a command. I added in a sound effect to emphasize this that will play once audio has been lowered and the state is set to listening. Once the sound effect is played the user knows to speak the second command word.
我喜欢这种方法的一个原因不仅在于它可以提高识别能力,而且还可以指导用户如何调用命令。 我添加了声音效果来强调这一点,该声音将在降低音频并将状态设置为聆听后播放。 一旦播放了声音效果,用户便会说出第二个命令字。
Anyway hope you have found this read interesting. Feel free to drop a comment below if you want to chat about the extension!
无论如何,希望您发现这读起来很有趣。 如果您想聊天扩展,请在下面发表评论!
chrome扩展程序















 384
384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}