





Before diving into the details, we need to understand how we represent the data.
在深入研究细节之前,我们需要了解如何表示数据。
If you haven’t read the previous post, the introduction, here’s the link.
如果您还没有阅读上一篇文章的介绍,那么这里是链接。
书 (Book)
The posts about “Automated Planning and Acting” here are based on the book with same title by Malik Ghallab, Danau Nau and Paolo Traverso.
此处有关“自动化计划和代理”的帖子是根据Malik Ghallab,Danau Nau和Paolo Traverso的同名书改写的。
规划领域 (Planning Domain)
In the previous post, we discussed about descriptive models of actions which describe the states that may happen as result of performing actions.
在上一篇文章中,我们讨论了动作的描述性模型,这些模型描述了由于执行动作而可能发生的状态。
The models are often called Planning Domain or State-Transition System (think about finite state machine).
这些模型通常称为“计划域”或“状态转换系统” (请考虑有限状态机)。
A planning domain is a 4-tuple of:
计划域是以下内容的4元组:
Σ =(S, A, γ, cost)
Σ=(S , A,γ,成本)
Where:S: a set of statesA: a set of actionsγ: state-transition function, or prediction functioncost: the cost of performing an action
其中:S:状态集合A:动作集合γ:状态转换函数或预测函数cost:执行动作的成本
For state transition function, we can write in the following form:γ(s₀, a) = s₁
对于状态转换函数,我们可以用以下形式写:γ(s₀,a)=s₁
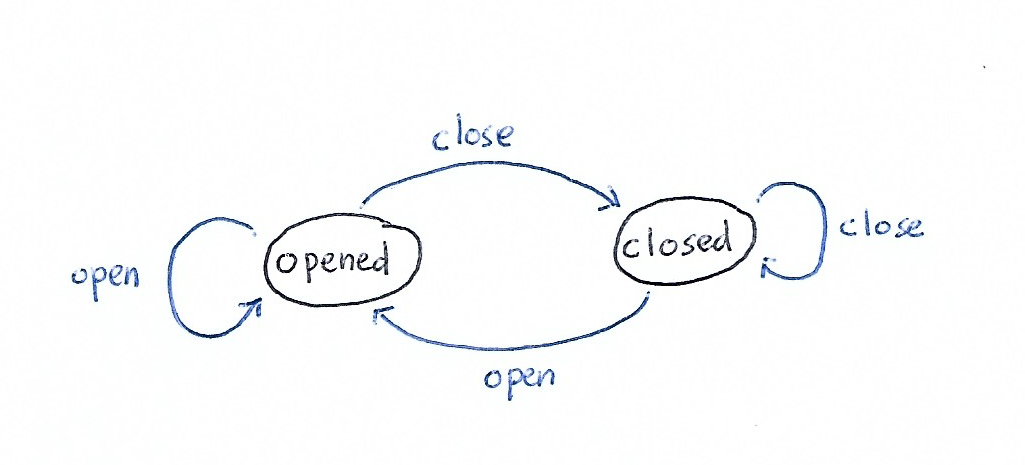
例 (Example)
An example is a simple door system.S = {opened, closed}A = {open, close}
一个简单的门系统就是一个例子。S = {打开,关闭} A = {打开,关闭}
There are 4 transition functions:γ(opened, open) = openedγ(opened, close) = closedγ(closed, open) = openedγ(closed, close) = closed
共有4个转换函数:γ(打开,打开)=打开γ(打开,关闭)=关闭γ(关闭,打开)=打开γ(关闭,关闭)=关闭
For this simple example, let’s assume that the cost is uniform, 1.
对于这个简单的示例,我们假设成本是统一的,即1。
对象和状态变量(Objects and State Variables)
To understand state variables, we start with the meaning of the state in our model.
为了理解状态变量,我们从模型中状态的含义开始。
State is a description of the properties of various objects in the environment — Automated Planning and Acting
状态是对环境中各种对象的属性的描述-自动规划和执行
That means if we have multiple objects in the environment, we will have one unique state if one of the object’s property changes.
这意味着,如果我们在环境中有多个对象,则如果对象的属性之一发生更改,我们将具有一个唯一状态。
There are two different types of property:
有两种不同类型的属性:
Rigid
刚硬
If it remains the same in different states, for example the adjacency of rooms in a floor plan
如果在不同状态下保持不变,例如平面图中房间的邻接
Varying
变化的
If it may differ in one state and another
如果在一个州和另一个州可能有所不同
状态变量(State Variable)
State variable is represented as x=sv(b₁, …, bᴋ), where:
状态变量表示为x = sv(b₁,…,bᴋ),其中:
- sv: state variable’s name sv:状态变量的名称
- b: object’s nameb:对象名称
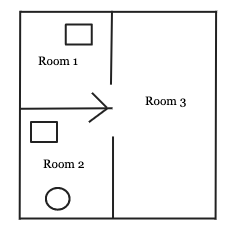
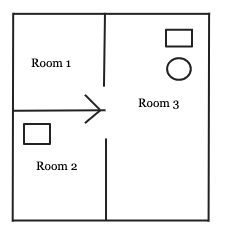
Let’s look at an example. In our floor plan below, we have 3 objects:
让我们来看一个例子。 在下面的平面图中,我们有3个对象:
- robot (circle) 机器人(圆)
- objects (rectangle) 对象(矩形)
- rooms 房间
Rigid relations can be represented as:
刚性关系可以表示为:
Adjacent = [(Room1, Room2), (Room1, Room3), (Room2, Room1), (Room2, Room3), (Room3, Room1), (Room3, Room2)]This won’t change because they are rigid.
因为它们是刚性的,所以不会改变。
State variables can be represented as follows, (let’s assume that rectangle in Room 1 is object 1):
状态变量可以表示如下(假设房间1中的矩形是对象1):
location(robot) = Room2
location(object1) = Room1
location(object2) = Room2
occupied(Room1) = True
occupied(Room2) = True
occupied(Room3) = FalseSo, current state of our world is:
因此,我们世界的当前状态是:
current_state = [location(robot) = Room2, location(object1) = Room1, location(object2) = Room2, occupied(Room1) = True, occupied(Room2) = True, occupied(Room3) = False]If one of the state variables in current_state changes, it is another state.
如果current_state中的状态变量之一更改,则为另一状态。
The code snippet is just for illustration, when we code it is better to create a class to represent the “world”.
代码段仅用于说明,当我们进行编码时,最好创建一个类来表示“世界”。
动作和动作模板 (Actions and Action Templates)
The next part in our planning domain is action. Action is important part of the domain model because this is the component where we predict what the next state will be.
我们计划领域的下一部分是行动。 动作是域模型的重要组成部分,因为这是我们预测下一个状态将是什么的组件。
Action has the three parts:
行动包括三个部分:
- input parameters 输入参数
- pre-conditions前提条件
- effects效果
Action template is a generic form, action is an instance of action template.
动作模板是通用形式,动作是动作模板的实例。
Action template is written in the following format:
操作模板以以下格式编写:
action(*params):
cost = 1
if preconditions(current_state):
return effects(), cost
else:
return current_state, costif preconditions() returns true, the effects of the action is returned. Otherwise this action isn’t applicable in current state of the world/environment.
如果preconditions()返回true,则返回操作的效果。 否则,此操作不适用于当前的世界/环境。
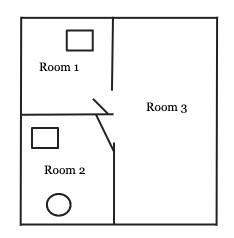
Let’s look at an example. In Example 1 above we can add an action, let’s call it move.
让我们来看一个例子。 在上面的示例1中,我们可以添加一个动作,我们称其为move 。
move(from, to):
cost = 1
if preconditions(current_state, from, to):
return effects(), cost
else:
return current_state, costNow, the preconditions:
现在,前提条件:
preconditions(current_state, from, to):
if current_state.door(from, to) == OPENED:
return True
else:
return FalseThe effects:
效果:
effects(current_state, from, to):
predicted_state = current_state
predicted_state.location(robot, to)
return predicted_stateWe can see from the example above how the action and action template works, the predicted state will contain robot’s location in the new room. If the door is not opened, the action is not applicable.
从上面的示例中我们可以看到动作和动作模板如何工作,预测状态将包含机器人在新房间中的位置。 如果门未打开,则该操作不适用。
计划和计划问题(Plans and Planning Problems)
The final part is plans and planning problems.
最后一部分是计划和计划问题。
计划 (Plan)
The definition of plan is:
计划的定义是:
A finite sequence of actions
有限的动作序列
plan = [action1, action2, action3]In this example, the length of the plan is 3 and the cost is the total cost of all the actions.
在此示例中,计划的长度为3,成本为所有操作的总成本。
plan_cost = 0
for action in plan:
plan_cost = plan_cost + action.cost规划问题 (Planning Problem)
Planning problem is the tuple of planning domain, initial state and goal(desired) state.
计划问题是计划域,初始状态和目标(期望)状态的元组。
Planning Problem is the problem that we want to solve, the plan solves the planning problem.
计划问题是我们要解决的问题,计划可以解决计划问题。
planning_problem = PlanningProblem(planning_domain, initial_state, goal_state)Remember that Planning Domain is our tuple of:
请记住,规划域是我们的元组:
- states 状态
- actions行动
- state-transition functions状态转换功能
- cost成本
Now, that we have the complete understanding of the representation, let’s look at one example.
现在,我们已经完全了解了表示形式,让我们看一个示例。
This is the initial state,
这是初始状态
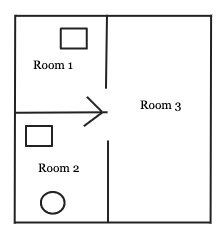
This is our goal state,
这是我们的目标状态,
We add 3 more actions:
我们再添加3个动作:
grab(object)
carry(object, from, to)
place(object)So, we can create the plan as follows to solve this planning problem:
因此,我们可以如下创建计划以解决该计划问题:
plan = [move(room2, room3), move(room3, room1), grab(object1), carry(object1, room1, room3), place(object1)]We say that plan is the solution to our planning problem.
我们说计划是解决我们计划问题的方法。
Of course this is a simplified example where there is only one actor, our robot, and the assumption that the world is static.
当然,这是一个简化的示例,其中只有一个演员,我们的机器人以及假设世界是静态的。
In later chapter, we’ll see the examples with Python to solve real planning problems.
在后面的章节中,我们将看到使用Python解决实际计划问题的示例。
We’ll discuss about search algorithms in the next posts.
我们将在下一篇文章中讨论搜索算法。
翻译自: https://medium.com/ai-in-plain-english/state-variables-representation-762a736f27e















 367
367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









