





aws使用
介绍 (Introduction)
In this post, I have penned down AWS Glue and PySpark functionalities which can be helpful when thinking of creating AWS pipeline and writing AWS Glue PySpark scripts.
在本文中,我简化了AWS Glue和PySpark功能,这些功能在考虑创建AWS管道和编写AWS Glue PySpark脚本时会很有帮助。
AWS Glue is a fully managed extract, transform, and load (ETL) service to process large amounts of datasets from various sources for analytics and data processing.
AWS Glue是一项完全托管的提取,转换和加载(ETL)服务,可处理来自各种来源的大量数据集以进行分析和数据处理。
While creating the AWS Glue job, you can select between Spark, Spark Streaming, and Python shell. These jobs can run a proposed script generated by AWS Glue, or an existing script that you provide or a new script authored by you. Also, you can select different monitoring options, job execution capacity, timeouts, delayed notification threshold, and non-overridable and overridable parameters.
创建AWS Glue作业时,可以在Spark,Spark Streaming和Python Shell之间进行选择。 这些作业可以运行由AWS Glue生成的建议脚本,您提供的现有脚本或您编写的新脚本。 另外,您可以选择不同的监视选项,作业执行能力,超时,延迟的通知阈值以及不可覆盖和可覆盖的参数。
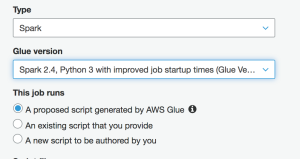
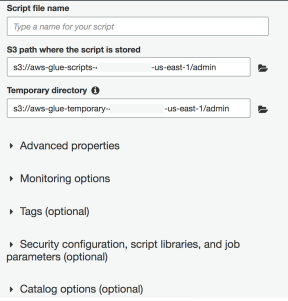
Recently AWS recently launched Glue version 2.0 which features 10x faster Spark ETL job start times and reducing the billing duration from a 10-minute minimum to 1-minute minimum.
最近,AWS最近发布了Glue 2.0版 ,其功能将Spark ETL作业启动时间缩短了10倍,并将账单持续时间从最少10分钟缩短为最少1分钟。
With AWS Glue you can create development endpoint and configure SageMaker or Zeppelin notebooks to develop and test your Glue ETL scripts.
使用AWS Glue,您可以创建开发终端节点并配置SageMaker或Zeppelin笔记本以开发和测试您的Glue ETL脚本。
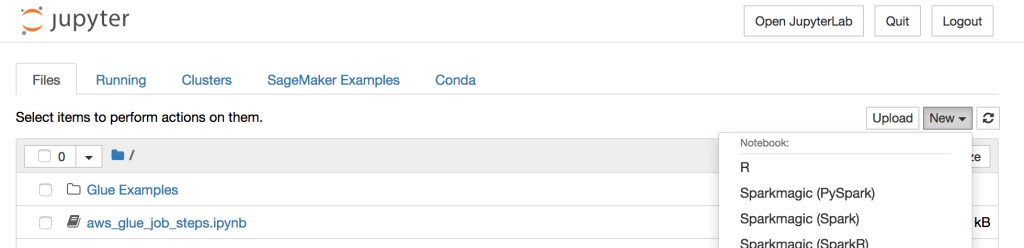
I create a SageMaker notebook connected to the Dev endpoint to the author and test the ETL scripts. Depending on the language you are comfortable with, you can spin up the notebook.
我创建了一个连接到开发者端点到作者的SageMaker笔记本,并测试了ETL脚本。 根据您喜欢的语言,可以旋转笔记本计算机。
Now, let’s talk about some specific features and functionalities in AWS Glue and PySpark which can be helpful.
现在,让我们讨论一下可能有用的AWS Glue和PySpark中的一些特定功能。
1. Spark DataFrames (1. Spark DataFrames)
Spark DataFrame is a distributed collection of data organized into named columns. It is conceptually equivalent to a table in a relational database. You can create DataFrame from RDD, from file formats like csv, json, parquet.
Spark DataFrame是组织为命名列的分布式数据集合。 从概念上讲,它等效于关系数据库中的表。 您可以使用csv,json,parquet等文件格式从RDD创建DataFrame。
With SageMaker Sparkmagic(PySpark) Kernel notebook, the Spark session is automatically created.
使用SageMaker Sparkmagic(PySpark)内核笔记本,将自动创建Spark会话。
To create DataFrame -
要创建DataFrame-
# from CSV files
S3_IN = "s3://mybucket/train/training.csv"
csv_df = (
spark.read.format("org.apache.spark.csv")
.option("header", True)
.option("quote", '"')
.option("escape", '"')
.option("inferSchema", True)
.option("ignoreLeadingWhiteSpace", True)
.option("ignoreTrailingWhiteSpace", True)
.csv(S3_IN, multiLine=False)
)
# from PARQUET files
S3_PARQUET="s3://mybucket/folder1/dt=2020-08-24-19-28/"
df = spark.read.parquet(S3_PARQUET)
# from JSON files
df = spark.read.json(S3_JSON)
# from multiline JSON file
df = spark.read.json(S3_JSON, multiLine=True)2. GlueContext (2. GlueContext)
GlueContext is the entry point for reading and writing DynamicFrames in AWS Glue. It wraps the Apache SparkSQL SQLContext object providing mechanisms for interacting with the Apache Spark platform.
GlueContext是在AWS Glue中读写DynamicFrames的入口点。 它包装了Apache SparkSQL SQLContext对象,提供了与Apache Spark平台进行交互的机制。
from awsglue.job import Job
from awsglue.transforms import *
from awsglue.context import GlueContext
from pyspark.context import SparkContext
from awsglue.utils import getResolvedOptions
from awsglue.dynamicframe import DynamicFrame
glueContext = GlueContext(SparkContext.getOrCreate())3. DynamicFrame (3. DynamicFrame)
AWS Glue DynamicFrames are similar to SparkSQL DataFrames. It represents a distributed collection of data without requiring you to specify a schema. Also, it can be used to read and transform data that contains inconsistent values and types.
AWS Glue DynamicFrames与SparkSQL DataFrames类似。 它表示数据的分布式集合,而无需您指定架构。 同样,它可以用于读取和转换包含不一致的值和类型的数据。
DynamicFrame can be created using the following options -
可以使用以下选项创建DynamicFrame-
create_dynamic_frame_from_rdd — created from an Apache Spark Resilient Distributed Dataset (RDD)
create_dynamic_frame_from_rdd —从Apache Spark弹性分布式数据集(RDD)创建
create_dynamic_frame_from_catalog — created using a Glue catalog database and table name
create_dynamic_frame_from_catalog —使用Glue目录数据库和表名创建
create_dynamic_frame_from_options — created with the specified connection and format. Example — The connection type, such as Amazon S3, Amazon Redshift, and JDBC
create_dynamic_frame_from_options-使用指定的连接和格式创建。 示例—连接类型,例如Amazon S3,Amazon Redshift和JDBC
DynamicFrames can be converted to and from DataFrames using .toDF() and fromDF(). Use the following syntax-
可以使用.toDF()和fromDF()在DynamicFrame和DataFrame之间进行转换。 使用以下语法-
#create DynamicFame from S3 parquet files
datasource0 = glueContext.create_dynamic_frame_from_options(
connection_type="s3",
connection_options = {
"paths": [S3_location]
},
format="parquet",
transformation_ctx="datasource0")
#create DynamicFame from glue catalog
datasource0 = glueContext.create_dynamic_frame.from_catalog(
database = "demo",
table_name = "testtable",
transformation_ctx = "datasource0")
#convert to spark DataFrame
df1 = datasource0.toDF()
#convert to Glue DynamicFrame
df2 = DynamicFrame.fromDF(df1, glueContext , "df2")You can read more about this here.
您可以在此处了解更多信息。
4. AWS Glue作业书签 (4. AWS Glue Job Bookmark)
AWS Glue Job bookmark helps process incremental data when rerunning the job on a scheduled interval, preventing reprocessing of old data.
AWS Glue 作业书签在按计划的时间间隔重新运行作业时可帮助处理增量数据,从而防止重新处理旧数据。
You can read more about this here. Also, you can read this.
5.写出数据 (5. Write out data)
The DynamicFrame of the transformed dataset can be written out to S3 as non-partitioned (default) or partitioned. “ partitionKeys “ parameter can be specified in connection_option to write out the data to S3 as partitioned. AWS Glue organizes these datasets in Hive-style partition.
可以将转换后的数据集的DynamicFrame作为未分区(默认)或分区写入S3。 可以在connection_option中指定“ partitionKeys ”参数,以将数据分区后写入S3。 AWS Glue在Hive样式分区中组织这些数据集。
In the following code example, AWS Glue DynamicFrame is partitioned by year, month, day, hour, and written in parquet format in Hive-style partition on to S3.
在以下代码示例中,AWS Glue DynamicFrame按年,月,日,小时进行分区,并以拼花格式在Hive样式的分区中写入S3。
S3_location = "s3://bucket_name/table_name"
datasink = glueContext.write_dynamic_frame_from_options(
frame= data,
connection_type="s3",
connection_options={
"path": S3_location,
"partitionKeys": ["year", "month", "day", "hour"]
},
format="parquet",
transformation_ctx ="datasink")You can read more about this here.
您可以在此处了解更多信息。
6.“ glueparquet”格式选项 (6. “glueparquet” format option)
glueparquet is a performance-optimized Apache parquet writer type for writing DynamicFrames. It computes and modifies the schema dynamically.
gumparquet是用于编写DynamicFrames的性能优化的Apache Parquet编写器类型。 它动态地计算和修改模式。
datasink = glueContext.write_dynamic_frame_from_options(
frame=dynamicframe,
connection_type="s3",
connection_options={
"path": S3_location,
"partitionKeys": ["year", "month", "day", "hour"]
},
format="glueparquet",
format_options = {"compression": "snappy"},
transformation_ctx ="datasink")You can read more about this here.
您可以在此处了解更多信息。
7. S3 Lister和其他用于优化内存管理的选项 (7. S3 Lister and other options for optimizing memory management)
AWS Glue provides an optimized mechanism to list files on S3 while reading data into DynamicFrame which can be enabled using additional_options parameter “ useS3ListImplementation “ to true.
AWS Glue提供了一种优化的机制,可以在将数据读入DynamicFrame时在S3上列出文件,可以使用Additional_options参数“ useS3ListImplementation ”启用它来启用true。
You can read more about this here.
您可以在此处了解更多信息。
8.清除S3路径 (8. Purge S3 path)
purge_s3_path is a nice option available to delete files from a specified S3 path recursively based on retention period or other available filters. As an example, suppose you are running AWS Glue job to fully refresh the table per day writing the data to S3 with the naming convention of s3://bucket-name/table-name/dt=<data-time>. Based on the defined retention period using the Glue job itself you can delete the dt=<date-time> s3 folders. Another option is to set the S3 bucket lifecycle policy with the prefix.
purge_s3_path是一个不错的选项,可用于根据保留期限或其他可用过滤器从指定的S3路径递归删除文件。 作为示例,假设您正在运行AWS Glue作业,每天使用s3:// bucket-name / table-name / dt = <data-time>的命名约定将数据写入S3来完全刷新表。 根据使用胶粘作业本身定义的保留期限,您可以删除dt = <date-time> s3文件夹。 另一个选项是使用前缀设置S3存储桶生命周期策略。
#purge locations older than 3 daysprint("Attempting to purge S3 path with retention set to 3 days.")glueContext.purge_s3_path(
s3_path=output_loc,
options={"retentionPeriod": 72})You have other options like purge_table, transition_table, and transition_s3_path also available. The transition_table option transitions the storage class of the files stored on Amazon S3 for the specified catalog’s database and table.
您还可以使用其他选项,例如purge_table,transition_table和transition_s3_path。 transition_table选项为指定目录的数据库和表转换存储在Amazon S3上的文件的存储类。
You can read more about this here.
您可以在此处了解更多信息。
9.关系类 (9. Relationalize Class)
Relationalize class can help flatten nested json outermost level.
Relationalize类可以帮助展平嵌套的json最外层。
You can read more about this here.
您可以在此处了解更多信息。
10.拆箱类 (10. Unbox Class)
The Unbox class helps the unbox string field in DynamicFrame to specified format type(optional).
Unbox类有助于将DynamicFrame中的unbox字符串字段设置为指定的格式类型(可选)。
You can read more about this here.
您可以在此处了解更多信息。
11.巢穴类 (11. Unnest Class)
The Unnest class flattens nested objects to top-level elements in a DynamicFrame.
Unnest类将嵌套对象展平为DynamicFrame中的顶级元素。
root
|-- id: string
|-- type: string
|-- content: map
| |-- keyType: string
| |-- valueType: stringWith content attribute/column being map Type, we can use the unnest class to unnest each key element.
通过将content属性/列设置为map Type,我们可以使用unnest类取消嵌套每个关键元素。
unnested = UnnestFrame.apply(frame=data_dynamic_dframe)
unnested.printSchema()root
|-- id: string
|-- type: string
|-- content.dateLastUpdated: string
|-- content.creator: string
|-- content.dateCreated: string
|-- content.title: string12. printSchema() (12. printSchema())
To print the Spark or Glue DynamicFrame schema in tree format use printSchema().
要以树格式打印Spark或Glue DynamicFrame模式,请使用printSchema() 。
datasource0.printSchema()
root
|-- ID: int
|-- Name: string
|-- Identity: string
|-- Alignment: string
|-- EyeColor: string
|-- HairColor: string
|-- Gender: string
|-- Status: string
|-- Appearances: int
|-- FirstAppearance: choice
| |-- int
| |-- long
| |-- string
|-- Year: int
|-- Universe: string13.字段选择 (13. Fields Selection)
select_fields can be used to select fields from Glue DynamicFrame.
select_fields可用于从Glue DynamicFrame中选择字段。
# From DynamicFrame
datasource0.select_fields(["Status","HairColor"]).toDF().distinct().show()To select fields from Spark Dataframe to use “ select “ -
要从Spark Dataframe选择字段以使用“ select ”-
# From Dataframe
datasource0_df.select(["Status","HairColor"]).distinct().show()14.时间戳 (14. Timestamp)
For instance, the application writes data into DynamoDB and has a last_updated attribute/column. But, DynamoDB does not natively support date/timestamp data type. So, you could either store it as String or Number. In case stored as a number, it’s usually done as epoch time — the number of seconds since 00:00:00 UTC on 1 January 1970. You could see something like “1598331963” which is 2020–08–25T05:06:03+00:00 in ISO 8601.
例如,应用程序将数据写入DynamoDB,并具有last_updated属性/列。 但是,DynamoDB本身不支持日期/时间戳数据类型。 因此,您可以将其存储为字符串或数字。 如果以数字形式存储,则通常以纪元时间(自1970年1月1日00:00:00 UTC以来的秒数)完成。您会看到类似“ 1598331963”的内容,即2020–08–25T05:06:03+在ISO 8601中为00:00。
You can read more about Timestamp here.
您可以在此处阅读有关时间戳的更多信息。
How can you convert it to a timestamp?
如何将其转换为时间戳?
When you read the data using AWS Glue DynamicFrame and view the schema, it will show it as “long” data type.
当您使用AWS Glue DynamicFrame读取数据并查看架构时,它将显示为“长”数据类型。
root
|-- version: string
|-- item_id: string
|-- status: string
|-- event_type: string
|-- last_updated: longTo convert the last_updated long data type into timestamp data type, you can use the following code-
要将last_updated长数据类型转换为时间戳数据类型,可以使用以下代码-
import pyspark.sql.functions as f
import pyspark.sql.types as t
new_df = (
df
.withColumn("last_updated", f.from_unixtime(f.col("last_updated")/1000).cast(t.TimestampType()))
)15. Spark DataFrame中的临时视图 (15. Temporary View from Spark DataFrame)
In case you want to store the Spark DataFrame as a table and query it using spark SQL, you can convert the DataFrame into a temporary view that is available for only that spark session using createOrReplaceTempView.
如果要将Spark DataFrame存储为表并使用spark SQL查询它,则可以使用createOrReplaceTempView将DataFrame转换为仅适用于该Spark会话的临时视图。
df = spark.createDataFrame(
[
(1, ['a', 'b', 'c'], 90.00),
(2, ['x', 'y'], 99.99),
],
['id', 'event', 'score']
)
df.printSchema()
root
|-- id: long (nullable = true)
|-- event: array (nullable = true)
| |-- element: string (containsNull = true)
|-- score: double (nullable = true)
df.createOrReplaceTempView("example")
spark.sql("select * from example").show()
+---+---------+-----+
| id| event|score|
+---+---------+-----+
| 1|[a, b, c]| 90.0|
| 2| [x, y]|99.99|
+---+---------+-----+16.从ArrayType中提取元素 (16. Extract element from ArrayType)
Suppose from the above example, you want to create a new attribute/column to store only the last event. How would you do it?
假设从上面的示例开始,您想创建一个新的属性/列以仅存储最后一个事件。 你会怎么做?
You use the element_at function. It returns an element of the array at the given index in extraction if col is an array. Also, it can be used to extract the given key in extraction if col is a map.
您使用element_at函数。 如果col是一个数组,它将在提取中给定索引处返回该数组的元素。 此外,如果col是地图,则可用于提取提取中的给定键。
import pyspark.sql.functions as element_at
newdf = df.withColumn("last_event", element_at("event", -1))
newdf.printSchema()
root
|-- id: long (nullable = true)
|-- event: array (nullable = true)
| |-- element: string (containsNull = true)
|-- score: double (nullable = true)
|-- last_event: string (nullable = true)
newdf.show()
+---+---------+-----+----------+
| id| event|score|last_event|
+---+---------+-----+----------+
| 1|[a, b, c]| 90.0| c|
| 2| [x, y]|99.99| y|
+---+---------+-----+----------+17.爆炸 (17. explode)
The explode function in PySpark is used to explode array or map columns in rows. For example, let’s try to explode “event” column from the above example-
PySpark中的爆炸功能用于爆炸行中的数组或映射列。 例如,让我们尝试从上面的示例中爆炸“事件”列-
from pyspark.sql.functions import explode
df1 = df.select(df.id,explode(df.event))
df1.printSchema()
root
|-- id: long (nullable = true)
|-- col: string (nullable = true)
df1.show()
+---+---+
| id|col|
+---+---+
| 1| a|
| 1| b|
| 1| c|
| 2| x|
| 2| y|
+---+---+18. getField (18. getField)
In a Struct type, if you want to get a field by name, you can use “ getField “. The following is its syntax-
在Struct类型中,如果要按名称获取字段,则可以使用“ getField ”。 以下是其语法-
import pyspark.sql.functions as f
from pyspark.sql import Row
from pyspark.sql import Row
df = spark.createDataFrame([Row(attributes=Row(Name='scott', Height=6.0, Hair='black')),
Row(attributes=Row(Name='kevin', Height=6.1, Hair='brown'))]
)
df.printSchema()
root
|-- attributes: struct (nullable = true)
| |-- Hair: string (nullable = true)
| |-- Height: double (nullable = true)
| |-- Name: string (nullable = true)
df.show()
+-------------------+
| attributes|
+-------------------+
|[black, 6.0, scott]|
|[brown, 6.1, kevin]|
+-------------------+
df1 = (df
.withColumn("name", f.col("attributes").getField("Name"))
.withColumn("height", f.col("attributes").getField("Height"))
.drop("attributes")
)
df1.show()
+-----+------+
| name|height|
+-----+------+
|scott| 6.0|
|kevin| 5.1|
+-----+------+19.开始于 (19. startswith)
In case, you want to find records based on a string match you can use “ startswith “.
如果要基于字符串匹配查找记录,可以使用“ startswith ”。
In the following example I am searching for all records where value for description column starts with “[{“.
在下面的示例中,我正在搜索描述列值以“ [{”开头的所有记录。
import pyspark.sql.functions as f
df.filter(f.col("description").startswith("[{")).show()20.提取年,月,日,小时 (20. Extract year, month, day, hour)
One of the common use cases is to write the AWS Glue DynamicFrame or Spark DataFrame to S3 in Hive-style partition. To do so you can extract the year, month, day, hour, and use it as partitionkeys to write the DynamicFrame/DataFrame to S3.
常见用例之一是在Hive样式分区中将AWS Glue DynamicFrame或Spark DataFrame写入S3。 为此,您可以提取年,月,日,小时,并将其用作分区键以将DynamicFrame / DataFrame写入S3。
import pyspark.sql.functions as f
df2 = (raw_df
.withColumn('year', f.year(f.col('last_updated')))
.withColumn('month', f.month(f.col('last_updated')))
.withColumn('day', f.dayofmonth(f.col('last_updated')))
.withColumn('hour', f.hour(f.col('last_updated')))
)Originally published at https://www.analyticsvidhya.com on August 28, 2020.
最初于 2020年8月28日 发布在 https://www.analyticsvidhya.com 上。
aws使用

















 4860
4860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









