





数据库存储引擎
Firstly, We have to agree that if you are a software engineer and you are about to decide which database you will choose for your new application it is essential to have a good understanding of the underlying storage engine to reason about how the database actually delivers
首先,我们必须同意,如果您是一名软件工程师,并且要决定要为新应用程序选择哪个数据库,那么必须对底层存储引擎有一个很好的了解,才能推断出该数据库实际上是如何交付的。
We are going to talk about storage engines that are used in both traditional relational databases and NOSQL databases.
我们将讨论在传统的关系数据库和NOSQL数据库中都使用的存储引擎。
We will talk about the two most popular of the storage engines Log-structured storage engines, and page-oriented storage engines.
我们将讨论两种最流行的存储引擎:日志结构存储引擎和面向页面的存储引擎。
The main idea about the storage engines is how it stores and retrieves the data and how the index is created to speed the performance of the reads.
有关存储引擎的主要思想是它如何存储和检索数据以及如何创建索引以加快读取性能。
We are going to start with the Log-structured storage engines and how it handles these operation.
我们将从日志结构的存储引擎及其如何处理这些操作开始。
Hash indexes
^ h 灰分指标
Lets assume we have a key value data set and our data storage is a file and we only appending to it (no updates).
假设我们有一个键值数据集,而我们的数据存储是一个文件,我们只附加到它(没有更新)。
So we will have an in-memory hash map with the key of the data and an offset to the first byte of the value in the log file to seek for , when we add new key-value record we append it first to the end of the log file (our storage) and update the hash map.
因此,我们将获得一个内存中的哈希映射,其中包含数据的键和要查找的日志文件中值的第一个字节的偏移量,当我们添加新的键值记录时,我们首先将其附加到末尾日志文件(我们的存储)并更新哈希图。
This approach is very efficient if all the keys fit in the available memory (RAM), since the hash map is kept completely in memory.
如果所有密钥都适合可用内存(RAM),则此方法非常有效,因为哈希映射完全保留在内存中。
So if we have an application has a lot of writes but there are too many distinct keys and you have a large number of writes for those keys this approach will be suitable for you and there is an storage engine working like that (Bitcask).
因此,如果我们的应用程序有很多写入操作,但有太多不同的密钥,而您对这些密钥有大量写入操作,则此方法将适合您,并且有一个存储引擎可以像这样工作(Bitcask)。
Critical problem!
关键问题!
As we mentioned before we will have a lot of writes to the log file, we may have for each key more than one million write per hour and all the writes will be appended to the end of the file because there is no updates so we will have a lot of duplicates records and we can running out of disk space.
如前所述,我们将对日志文件进行大量写操作,每个键每小时可能有超过一百万个写操作,并且所有写操作都将追加到文件末尾,因为没有更新,因此我们将记录有很多重复, 我们可能会用光磁盘空间 。
A good solution is to break the log into segments of a certain size by closing a segment file when it reaches this size, and making subsequent writes to a new segment file.
一个好的解决方案是通过在达到某个大小的段文件时将其关闭,然后将其写入新的段文件,将日志分成一定大小的段。
This can be done by performing compression on the segments by throwing away duplicate keys in the log, and keeping only the most recent update for each key.
可以通过丢弃日志中的重复键并仅保留每个键的最新更新来对段执行压缩,以完成此操作。

Each segment now has its own in-memory hash table, mapping keys to file offsets.
现在,每个段都有自己的内存哈希表,将键映射到文件偏移量。
Since the compression process makes segments smaller because each segment may have a lot of duplicates we can perform a merge process at the same time with the compression over the segments.
由于每个段可能都有很多重复项,因此压缩过程使段更小,因此我们可以在对段进行压缩的同时执行合并过程。
The merging and compression of frozen segments can be done in a background thread, and while it is going on, we can still continue to serve read and write requests as normal, using the old segment files.
冻结段的合并和压缩可以在后台线程中完成,并且在进行中时,我们仍然可以继续使用旧的段文件继续正常处理读取和写入请求。
After the merging process is complete, we switch read requests to using the new merged segment instead of the old segments — and then the old segment files can simply be deleted.
合并过程完成后,我们将读取请求切换为使用新的合并段而不是旧段-然后可以简单地删除旧段文件。

In order to find the value for a key, we first check the most recent segment’s hash map; if the key is not present we check the second-most-recent segment, and so on.
为了找到键的值,我们首先检查最近段的哈希图; 如果密钥不存在,我们检查最近的第二部分,依此类推。
Limitations:
局限性:
1- The hash table must fit in memory: if you have a lot of keys which will not fit to the available memory this approach will not fit.
1-哈希表必须适合内存:如果您有很多不适合可用内存的键,则此方法不适合。
2- Range queries are not efficient: you cannot easily scan over all keysbetween red0 and red99 — you’d have to look up each key individually in the hash maps.
2-范围查询效率不高:您无法轻松地扫描red0和red99之间的所有键-您必须在哈希图中分别查找每个键。
To get over these limitations we will talk about another approach for indexing.
为了克服这些限制,我们将讨论另一种索引方法。
SSTables and LSM-Trees
S 稳定站和LSM树
As we mentioned before our segments is appending only so the orderof key-value pairs in the file does not matter.
如前所述,我们的段仅附加,因此文件中键/值对的顺序无关紧要。
We can make a simple change by sorting segments by key and here we call it Sorting String Table (SSTable), then merge them to sorted segment like the merge sort algorithm .
我们可以通过按键对段进行排序来进行简单的更改,这里我们将其称为“排序字符串表( SSTable )”,然后像合并排序算法一样将它们合并到已排序的段中。

Now we solved the second option in the limitations which is range queries, so now with the sstable segments with sorted key you can perform range query.
现在,我们解决了范围查询的局限性,这是第二种选择,因此现在使用带有已排序键的sstable段可以执行范围查询。
Also we can avoid the memory limitations of the hash maps because now we don’t have to store all the keys in the in-memory hash maps, we will just store small number of keys with their offsets and with the sorting if you search for key not exists in the hash map you will know the range to search between for this key.
同样,我们也可以避免哈希映射的内存限制 ,因为现在我们不必将所有键都存储在内存哈希图中,我们只存储少量键及其偏移量和排序(如果您搜索)密钥在哈希图中不存在,您将知道该密钥之间的搜索范围。
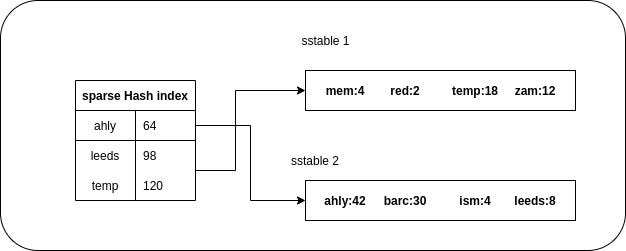
正如我们提到的,日志结构是仅追加的方法,这意味着我们对段进行了顺序写入,因此如何使这些段按键排序? (As we mentioned the log structure is an appending only approach so that means we make a sequential writes to segments so how we will make these segments sorted by key ?)
Memtable
中号 emtable
We can now make our storage engine work as follows:• When a write comes in, add it to an in-memory balanced tree data structure (for example, a red-black tree). This in-memory tree is sometimes called a memtable.• When the memtable gets bigger than some threshold, typically a few megabytes, write it out to disk as an SSTable file. This can be done efficiently because the tree already maintains the key-value pairs sorted by key.
现在,我们可以使存储引擎按以下方式工作:•进行写入时,将其添加到内存平衡树数据结构(例如,红黑树)中。 该内存树有时称为内存表。•当内存表大于某个阈值(通常为几兆字节)时,请将其作为SSTable文件写出到磁盘中。 由于树已经维护了按键排序的键值对,因此可以高效地完成此操作。
The new SSTable file becomes the most recent segment of the database. While the SSTable is being written out to disk, writes can continue to a new memtable instance.• In order to serve a read request, first try to find the key in the memtable, then in the most recent on-disk segment, then in the next-older segment, etc.• From time to time, run a merging and compaction process in the background to combine segment files and to discard overwritten or deleted values.
新的SSTable文件成为数据库的最新段。 在将SSTable写入磁盘时,写操作可以继续到新的memtable实例。•为了满足读取请求,首先尝试在memtable中查找键,然后在最近的磁盘段中查找,然后在•时不时在后台运行合并和压缩过程,以合并段文件并丢弃被覆盖或删除的值。
And that is we called Log-Structured Merge-Tree (LSM).
这就是我们所说的对数结构合并树( LSM )。
LSM engines are now default in popular NoSQL databases including Apache Cassandra, Elasticsearch (Lucene), Google Bigtable, Apache HBase, and InfluxDB. Even widely adopted embedded data stores such as LevelDB and RocksDB are LSM based.
LSM引擎现在是流行的NoSQL数据库(包括Apache Cassandra,Elasticsearch(Lucene),Google Bigtable,Apache HBase和InfluxDB)中的默认数据库。 甚至被广泛采用的嵌入式数据存储(例如LevelDB和RocksDB)也基于LSM。
Now we finished the Log-structured storage engine, lets start with the page-oriented storage engines which presented by the B-Trees.
现在,我们完成了日志结构的存储引擎,让我们从B-Trees提供的面向页面的存储引擎开始。
B-Trees
B 树
It is the most widely used indexing structure in most of the database special the relational databases (Postgres, Mysql, Sql and Oracle).
它是大多数数据库中最广泛使用的索引结构,特别是关系数据库(Postgres,Mysql,Sql和Oracle)。
B-trees break the database down into fixed-size pages, traditionally 4 KB in size (sometimes bigger), and read or write one page at a time.
B树将数据库分为固定大小的页面,传统上大小为4 KB(有时更大),并且一次读取或写入一页。
Each page can be identified using an address or location, which allows one page to refer to another — similar to a pointer, but on disk instead of in memory and the keys in the pages is sorted.
可以使用一个地址或位置来标识每个页面,该地址或位置允许一个页面引用另一个页面-类似于指针,但是在磁盘上而不是在内存中,并且页面中的键被排序。
The internal nodes consists of pointer to the other nodes and the leaf nodes contains the actual reference to the data rows in db.
内部节点由指向其他节点的指针组成,叶节点包含对db中数据行的实际引用。

The number of references to child pages in one page of the B-tree is called thebranching factor.
B树的一页中对子页面的引用数称为分支因子。
A B-tree with n keys always has a depth of O(log n).
具有n个键的B树的深度始终为O(log n)。
Most databases can fit into a B-tree that is three or four levels deep, so you don’t need to follow many page references to find the page you are looking for. (A four-level tree of 4 KB pages with a branching factor of 500 can tore up to 256 TB).
大多数数据库都可以放入三层或四层深的B树中,因此您无需遵循大量页面引用即可查找所需的页面。 (一个4 KB页的四层树,其分支因子为500,最多可破坏256 TB)。
Finally we finished, i hope this article help you to determine your storage engine, good luck with that.
最后,我们完成了,希望本文能帮助您确定存储引擎,祝您好运。
Summary
摘要

翻译自: https://medium.com/@mohamedveron23/guide-to-database-storage-engines-2b188bd3e9e3
数据库存储引擎















 7689
7689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









