





菲力宾做开发
In part 1, we were working through the beginning stages of creating a data set directly from information available on Wikipedia. In that post I covered how I used the Requests and Beautiful Soup packages to scrape a list of links from one page that would lead to other pages with the information needed for data set. In this post, I will continue to walk through the process I used to create a custom function to retrieve and store targeted information directly from web pages.
在第1部分中 ,我们正在研究直接从Wikipedia上提供的信息创建数据集的开始阶段。 在那篇文章中,我介绍了如何使用“请求”和“美丽的汤”包从一页中抓取链接列表,这些链接会指向其他页面,并包含数据集所需的信息。 在本文中,我将继续介绍创建自定义函数以直接从网页检索和存储目标信息的过程。
我们离开的地方... (Where We Left Off…)
At this point we have a list of all HTML elements on our root page that hold the tag “a” (anchor), meaning they contain a hyperlink (href) to another web page or different part of the current page.
至此,我们在根页面上有了所有HTML元素的列表,这些HTML元素包含标签“ a” ( anchor ),这意味着它们包含指向另一个网页或当前页面不同部分的超链接(href)。
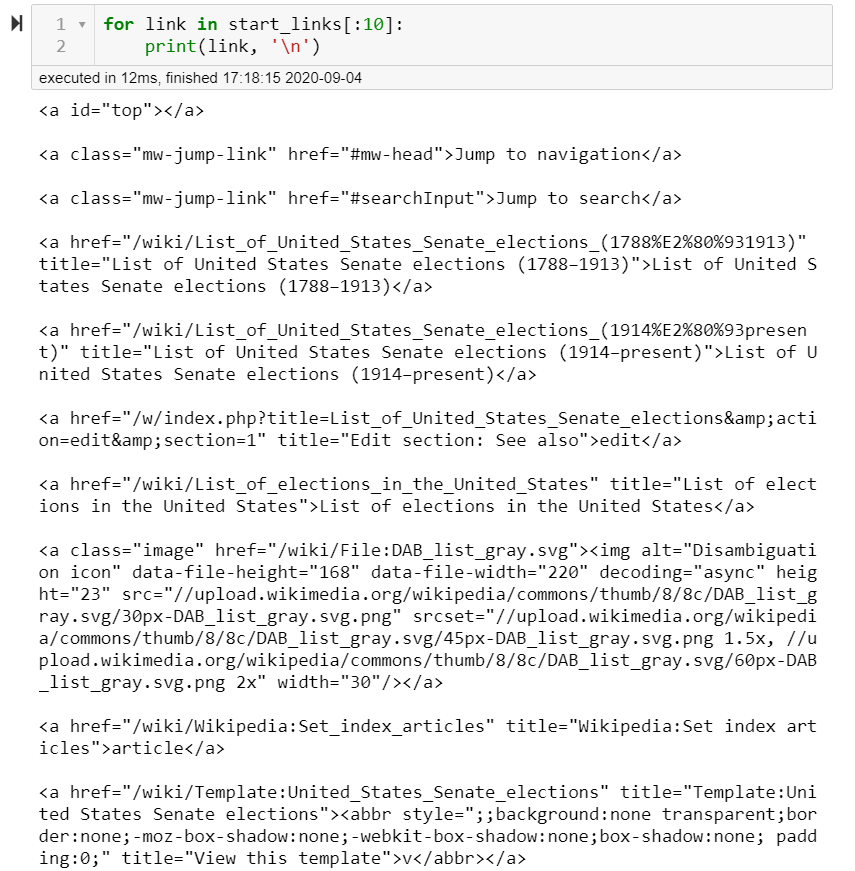
In this specific case, I did not need all of the links that were on this page, just a small section of them. In order to make sure I caught everything I wanted, I had to do some manual searching through the captured links and on the web pages themselves using the “Inspect” feature on Chrome.
在这种特殊情况下,我并不需要所有的这个页面上,他们的只是一小部分的链接。 为了确保捕捉到我想要的一切,我必须使用Chrome上的“检查”功能,对捕获的链接以及网页本身进行一些手动搜索。
切片链接 (Slicing Links)
In order to find the links I needed to target within the start_links list, I just used the inspect tool on Chrome to find the first and last links and matched that to the indices they represent (depending on your needs and the page, this may not be necessary). Eventually I came up with this:
为了在start_links列表中找到我需要定位的链接,我只是使用Chrome上的检查工具来查找第一个和最后一个链接,并将其与它们所代表的索引进行匹配(取决于您的需求和页面,这可能不会是必要的)。 最终我想到了这个:

At this point, I have what is needed to access each subsequent page on the senate elections stored in start_sen_links . My next step is to pull out the information stored in the href attribute and use it to navigate from page to page within a single scraping function.
至此,我需要访问存储在start_sen_links的参议院选举中的每个后续页面。 我的下一步是提取存储在href属性中的信息,并使用它在单个抓取功能内在页面之间导航。
连结在一起 (Linking Together)
If you’ve been following along with my code on your own, you may have noticed that each string stored in the href attribute does not contain the full URL to a web page, just what appears to be the last bits of one. This is actually the case, as we will need to determine the base URL component that will take us to the desired web page before scraping using a custom function.
如果您自己一直遵循我的代码,则可能已经注意到,存储在href属性中的每个字符串都不包含网页的完整URL,而仅仅是URL的最后一位。 实际情况就是这样,因为在使用自定义功能进行抓取之前,我们需要确定基本的URL组件,它将使我们进入所需的网页。
Luckily, this only meant navigating to the web page in Chrome (or your preferred browser) and copying the part of the URL that precedes the information stored in the href attribute. This part will vary depending on the site, so make sure to research where you are trying to navigate and adjust your code accordingly. Wikipedia fortunately was very consistent, meaning I only needed one base URL for all the targeted pages.
幸运的是,这仅意味着导航到Chrome(或您喜欢的浏览器)中的网页,并复制URL中存储在href属性中的信息之前的部分。 这部分内容会因站点而异,因此请确保研究尝试导航的位置并相应地调整代码。 幸运的是,维基百科非常一致,这意味着我只需一个基本URL即可访问所有目标页面。
In order for the function to work, I need to be able to combine the two parts into a single URL that can be used by the Requests and Beautiful Soup packages to connect and scrape the data I need.
为了使该功能正常工作,我需要能够将这两个部分合并为一个URL,Requests和Beautiful Soup程序包可以使用该URL连接和抓取所需的数据。
This can be achieved with the .get() method within Beautiful Soup and Python string operations.
这可以通过.get()实现 Beautiful Soup和Python字符串操作中的方法。
## Example for one link
base_url = "https://en.wikipedia.org"
link = <a href="/wiki/1994_United_States_Senate_elections" title="1994 United States Senate elections">1994</a>
end_url = link.get('href')
full_url = base_url + end_url
print(full_url)
## https://en.wikipedia.org/wiki/1994_United_States_Senate_elections变得Loop (Getting Loopy)
Currently, I have everything needed to build the function out:
目前,我具备构建该功能所需的一切:
- A list of HTML anchor elements containing the end of the URLs to our targeted web pages HTML锚元素列表,其中包含指向我们目标网页的URL的末尾
- A confirmed base URL to combine with end URLs for more scraping 确认的基本URL与结束URL结合使用以进行更多抓取
- A confirmed process that combines URLs into a usable link 将URL合并为可用链接的确认过程
I now need to implement code that will do all of these steps in an iterative fashion, storing the collected data appropriately along the way.
我现在需要实现将以迭代方式完成所有这些步骤的代码,并在此过程中适当地存储收集的数据。
In hind sight, I would have taken more time to investigate more of the pages I was going to scrape prior to doing so. In my specific case, Wikipedia has updated/altered how they identify certain items in the HTML over time, meaning the same items on separate pages may need to be looked up differently. In making my function able to account for this, I used a lot of time up towards my deadline.
事后看来,在这样做之前,我会花更多时间研究要刮掉的更多页面。 在我的特定情况下,维基百科已随着时间的推移更新/更改了它们如何识别HTML中的某些项目,这意味着可能需要以不同的方式查找单独页面上的相同项目。 为了使我的职能能够解决这个问题,我在截止日期前花了很多时间。
After a first trial with my code, it became apparent that the election result tables I wanted from each page did not come with the state’s information once scraped. I would need to come up with a (creative) solution that did not involve scraping a different source. This solution came by way of the table of contents for each page, as it contained by name each state’s election for that year.
在对我的代码进行第一次试用之后,很明显,我想要的每一页选举结果表都没有附带州信息。 我需要提出一个(创意)解决方案,该解决方案不涉及其他来源的检索。 该解决方案是通过每个页面的目录来实现的,因为它按名称包含了当年各州的选举。
Keeping this in mind, here is the for-loop portion of the code I came up with for my function:
请记住,这是我为函数想到的代码的for循环部分:
## Base of url for all senate election pages
base_url = 'https://en.wikipedia.org'
## Containers for results + counter for visual check during execute
yr_dfs = {}
yr_tocs = {}
count = 0
## Loop same process for all links + storage
for link in start_sen_links:
## Q.C during execute
count += 1
if count in [25, 50]:
print('Checkpoint! (25 loops)')
## Collecting strings for use
end_url = link.get('href')
year = link.get_text()
full_url = base_url + end_url
## Making soup + collecting all tables with appropriate class attribute
link_resp = requests.get(full_url)
link_soup = BeautifulSoup(link_resp.text, 'html.parser')
link_tables = link_soup.findAll('table', attrs={'class': ['wikitable', 'infobox vevent', 'infobox']})
## Collecting list of states with elections in each year; code inspired by:
## https://www.crummy.com/software/BeautifulSoup/bs4/doc/#kinds-of-filters
link_toc = link_soup.find('div', attrs={'id':'toc'})
link_toc = link_toc.findAll('a', href=is_state)
toc_list = [tag.get('href').replace('#', '') for tag in link_toc] ## href was like '#Alabama'
## Converting HTML to dataframe + storage
elect_df = pd.read_html(str(link_tables))
yr_dfs[year] = elect_df
yr_tocs[year] = toc_listOne thing to point out in this code is my use of the attrs parameter in the Beautiful Soup objects. When using the attrs parameter you only need to input a dictionary with:
该代码中要指出的一件事是,我在Beautiful Soup对象中使用了attrs参数。 使用attrs参数时,只需输入具有以下内容的字典:
- The key(s) set as the HTML attribute(s) to select for 设置为HTML属性的键
- The value(s) set as one or more strings (in a list if multiple) specifying the version of attribute to collect 设置为一个或多个字符串的值(如果有多个,则在列表中),指定要收集的属性的版本
By using this parameter I was able to only collect tables that contained election data (save some edge cases)!
通过使用此参数,我只能收集包含选举数据的表(节省一些边缘情况)!
Secondly, I took advantage of a custom filter in line 30 called is_state . This enabled Beautiful Soup to look at each of the links in the table of contents and, based upon the link, decide whether or not to save it into the link_toc variable. Here’s a link to the documentation that showed me how to do it: Filtering with functions.
其次,我利用了第30行中名为is_state的自定义过滤器。 这使Beautiful Soup可以查看目录中的每个链接,并根据该链接决定是否将其保存到link_toc变量中。 以下是指向文档的链接,该文档向我展示了操作方法: 使用函数进行过滤 。
def is_state(href):
## Helper list with all U.S. states formatted
states_list = ['Alabama', 'Alaska', 'Arizona', 'Arkansas', 'California',
'Colorado', 'Connecticut', 'Delaware', 'Florida', 'Georgia',
'Hawaii', 'Idaho', 'Illinois', 'Indiana', 'Iowa', 'Kansas',
'Kentucky', 'Louisiana', 'Maine', 'Maryland',
'Massachusetts', 'Michigan', 'Minnesota', 'Mississippi',
'Missouri', 'Montana', 'Nebraska', 'Nevada', 'New_Hampshire',
'New_Jersey', 'New_Mexico', 'New_York', 'North_Carolina',
'North_Dakota', 'Ohio', 'Oklahoma', 'Oregon', 'Pennsylvania',
'Rhode_Island', 'South_Carolina', 'South_Dakota',
'Tennessee', 'Texas', 'Utah', 'Vermont', 'Virginia',
'Washington', 'West_Virginia', 'Wisconsin', 'Wyoming']
## Confirming known states in link before returning it
for state in states_list:
if state in href:
return hrefLastly, line 34 is very important to this process, as it turns the HTML for each table into a closer representation to what it appears like in a browser or the typical Pandas DataFrame. Tip: this method requires the HTML to be in string format for it to convert properly.
最后,第34行对于此过程非常重要,因为它将每个表HTML转换成更接近于它在浏览器或典型的Pandas DataFrame中的显示形式。 提示:此方法要求HTML为字符串格式,以便正确转换。
检查我们的工作 (Checking Our Work)
Putting together the code from part 1 with this, we now have a function that will:
将第1部分中的代码与此结合在一起,我们现在有了一个函数,该函数将:
- Connect to a web page with links to more pages and scrape them 连接到包含更多页面链接的网页并将其抓取
- Combine ending URLs with base URL to access these pages 将结尾URL与基本URL组合以访问这些页面
- Use Beautiful Soup methods to collect all tables with senate election data and the table of contents for each page for state referencing later 使用Beautiful Soup方法收集具有参议院选举数据的所有表以及每个页面的目录,以供以后引用状态
- Convert tables from HTML is to easily workable Pandas DataFrames 将表格从HTML转换为易于使用的Pandas DataFrames
- Store table of contents and DataFrames in a dictionary with the corresponding year for the elections as the keys 将目录和DataFrames存储在字典中,并以相应的选举年份作为关键字
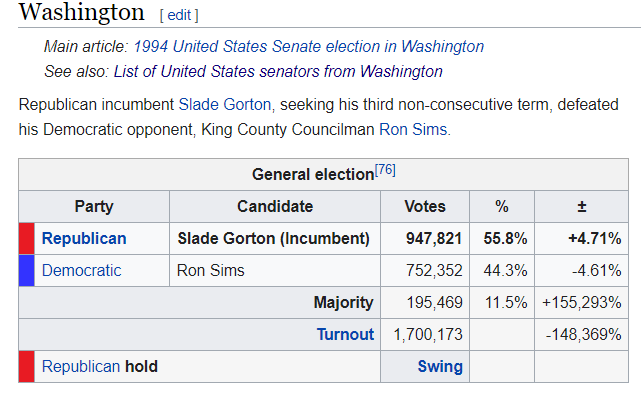
During each step, we’ve verified the code will take a table from Wikipedia like this:
在每个步骤中,我们已经验证了代码将采用Wikipedia的表格,如下所示:
Turn it into it’s base HTML elements:
将其变成基本HTML元素:

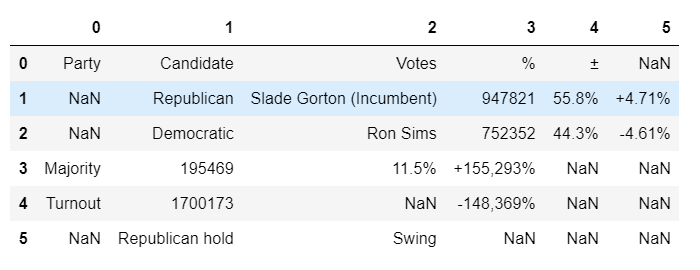
Then return a Jupyter Notebook friendly version via Pandas:
然后通过Pandas返回Jupyter Notebook友好版本:
下一步是什么? (What’s Next?)
The next step(s) in creating a data set from this would be to reformat and/or clean the data as necessary. The specific methods required will vary depending on the source material. The more consistent the source is with their HTML, the easier this will be, so make sure to do this process in manageable chunks with respect to any deadlines you may have if the HTML is inconsistent (like in my case).
从中创建数据集的下一步是根据需要重新格式化和/或清除数据。 所需的特定方法将取决于源材料。 来源与其HTML越一致,越容易做到这一点,因此请确保在HTML不一致时(例如我的情况),针对可能存在的任何截止日期,以可管理的块形式进行此过程。
In part 3 (hopefully the finale), I will show the final results of my scraping and scrubbing along with some of the cool visuals I was able to create it!
在第3部分(希望是结局)中,我将展示我进行刮擦和擦洗的最终结果以及我能够创建的一些很酷的视觉效果!
菲力宾做开发















 4227
4227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









