





ml模型
深度学习(Deep Learning)
Deep learning has found its way into all kinds of research areas in the present times and has also become an integral part of our lives. The words of Andrew Ng help us to sum it up really well,
深度学习在当今时代已进入各种研究领域,也已成为我们生活中不可或缺的一部分。 吴家祥的话可以帮助我们很好地总结一下,
“Artificial Intelligence is the new electricity.”
“人工智能是新的电力。”
However, with any great technical breakthroughs come a large number of challenges too. From Alexa to Google Photos to your Netflix recommendations, everything at its core is just deep learning, but it comes with a few hurdles of its own:
但是,随着任何重大的技术突破,也带来了许多挑战。 从Alexa到Google相册,再到您的Netflix建议,其核心只是深度学习,但它本身也有一些障碍:
- Availability of huge amounts of data 大量数据的可用性
- Availability of suitable hardware for high performance适用于高性能硬件的可用性
- Overfitting on available data过度拟合可用数据
- Lack of transparency缺乏透明度
- Optimization of hyperparameters超参数的优化
This article will help you solve one of these hurdles, which is optimization.
本文将帮助您解决这些障碍之一,即优化。
典型方法的问题: (The problem with the typical approach:)
A deep neural network usually learns by using stochastic gradient descent and the parameters θ (or weights ω) are updated as follows:
深度神经网络通常通过使用随机梯度下降学习,并且参数θ(或权重ω)的更新如下:
where L is a loss function and α is the learning rate.
其中L是损失函数, α是学习率。
We know that if we set the learning rate too small, the algorithm will take too much time to converge fully, and if it’s too large, the algorithm will diverge instead of converging. Hence, it is important to experiment with a variety of learning rates and schedules to see what works best for our model.
我们知道,如果将学习速率设置得太小,则算法将花费太多时间才能完全收敛;如果太大,则算法将发散而不是收敛。 因此,重要的是尝试各种学习率和进度表,以找出最适合我们模型的方法。
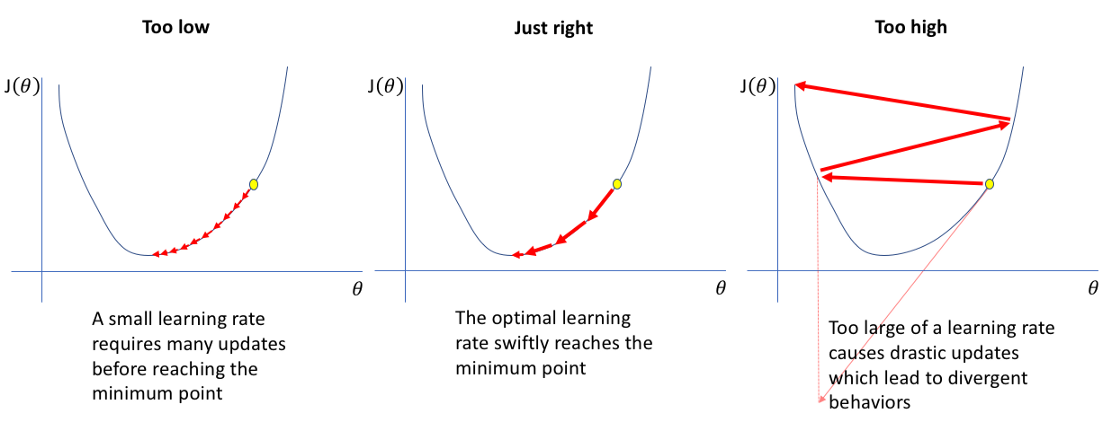
In practice, there are a few more problems which arise due to this method:
实际上,由于此方法,还会出现一些其他问题:
The deep learning model and optimizer are sensitive to our initial learning rate. A bad choice of the starting learning rate can greatly hamper the performance of our model from the beginning itself.
深度学习模型和优化器对我们的初始学习率敏感。 错误选择起始学习速率会从一开始就极大地阻碍我们模型的性能。
It could lead to a model that is stuck at local minima or in a saddle point. When that happens, we may not be able to descend to a place of lower loss even if we keep on lowering our learning rate further.
这可能会导致模型陷入局部最小值或鞍点。 发生这种情况时,即使我们继续进一步降低学习率,我们也可能无法下降到损失更低的地方。
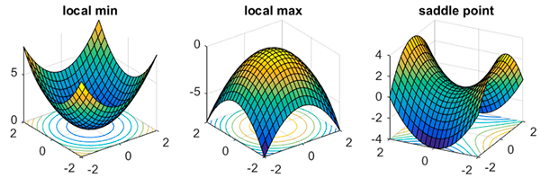
循环学习率可帮助我们克服这些问题(Cyclic Learning Rates help us overcome these problems)
Using Cyclical Learning Rates you can dramatically reduce the number of experiments required to tune and find an optimal learning rate for your model.
使用循环学习率,您可以大大减少为模型调整和找到最佳学习率所需的实验次数。
Now, instead of monotonically decreasing the learning rate, we:
现在,我们不是单调地降低学习率,而是:
Define a lower bound on our learning rate (base_lr).
定义学习率的下限( base_lr )。
Define an upper bound on the learning rate (max_lr).
定义学习率的上限( max_lr )。
So the learning rate oscillates between these two bounds while training. It slowly increases and decreases after every batch update.
因此,训练时学习率在这两个界限之间波动。 每次批量更新后,它缓慢增加和减少。
With this CLR method, we no longer have to manually tune the learning rates and we can still achieve near-optimal classification accuracy. Furthermore, unlike adaptive learning rates, the CLR method requires no extra computation.
使用这种CLR方法,我们不再需要手动调整学习速率,并且仍然可以实现接近最佳的分类精度。 此外,与自适应学习率不同,CLR方法不需要额外的计算。
The improvement will be clear to you by seeing an example.
通过查看示例,改进将对您很明显。
在数据集上实施CLR (Implementing CLR on a dataset)
Now we will train a simple neural network model and compare the different optimization techniques. I have used here a dataset on Cardiovascular disease.
现在,我们将训练一个简单的神经网络模型,并比较不同的优化技术。 我在这里使用了心血管疾病的数据集。
These are all the imports you’ll need over the course of the implementation:
这些是实施过程中所需的全部导入:
And this is what the data looks like:
数据如下所示:
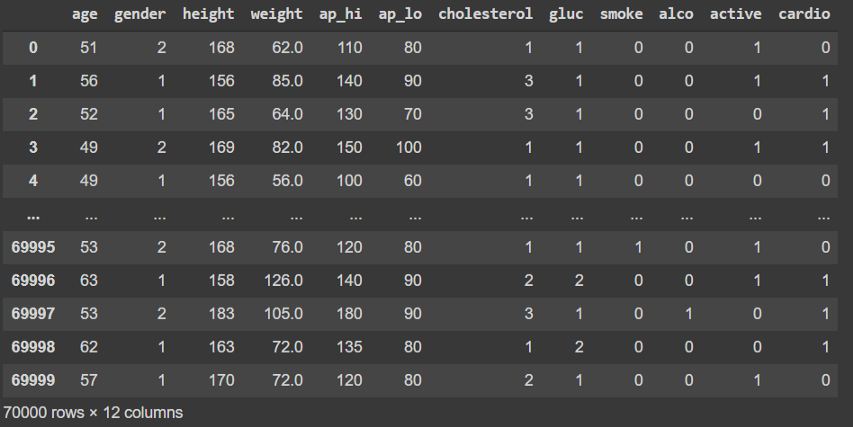
The column cardio is the target variable, and we perform some simple scaling of the data and split it into features (X_data) and targets (y_data).
cardio列是目标变量,我们对数据进行一些简单的缩放,然后将其分为y_data ( X_data )和目标( y_data )。
Now we use train_test_split to get a standard train to test ratio of 80–20. Then we define a very basic neural network using aSequential model from Keras. I have used 3 dense layers in my model, but you can experiment with any number of layers or activation functions of your choice.
现在,我们使用train_test_split来获得80-20的标准火车测试比率。 然后,我们使用Keras的Sequential模型定义了一个非常基本的神经网络。 我在模型中使用了3个密集层,但是您可以尝试任意数量的层或您选择的激活函数。
没有CLR的培训: (Training without CLR:)
Here I have compiled the model using the basic ‘SGD’ optimizer which has a default learning rate of 0.01. The model is then trained over 50 epochs.
在这里,我使用基本的“ SGD”优化器(默认学习率为0.01)来编译模型。 然后在50个纪元内训练模型。
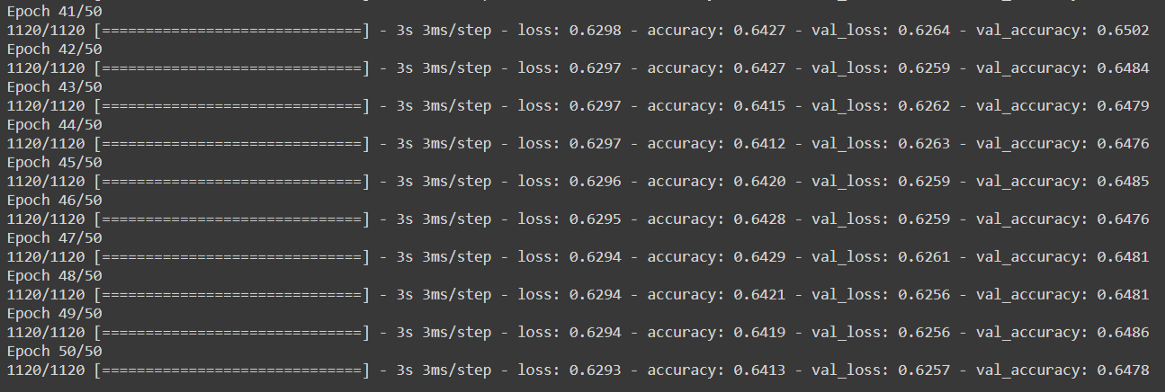
To show you just the last few epochs, the model takes 3s per epoch and in the end, gives 64.1% training accuracy and 64.7% validation accuracy. In short, this is the result our model gives us after ~150 seconds of training:
为了向您展示最后几个纪元,该模型每个纪元需要3 s,最后,该模型提供了64.1%的训练准确度和64.7%的验证准确度。 简而言之,这是我们的模型经过约150秒的训练后为我们提供的结果:

使用CLR进行培训: (Training using CLR:)
Now we use Cyclical Learning Rates and see how our model performs. TensorFlow has this optimizer already built-in and ready to use for us. We call it from the TensorFlow Addons and define it as follows:
现在,我们使用循环学习率,看看我们的模型如何运行。 TensorFlow已经内置了此优化器,可供我们使用。 我们从TensorFlow插件中调用它 并定义如下:
The value of step_size can be easily computed from the number of iterations in one epoch. So here, iterations per epoch
step_size的值可以很容易地根据一个时期中的迭代次数来计算。 所以这里,每个时期的迭代
= (no. of training examples)/(batch_size)
=(训练示例数)/(批量大小)
= 70000/350
= 70000/350
= 200.
= 200。
“experiments show that it often is good to set stepsize equal to 2 − 10 times the number of iterations in an epoch.”¹
“实验表明,通常最好将步长设置为等于某个时代迭代次数的2到10倍。”¹
Now compiling our model using this newly defined optimizer,
现在,使用这个新定义的优化器来编译模型,


we see that now our model trains much faster, taking even less than 50 seconds in total.
我们看到,现在我们的模型训练更快,总共花费不到50秒。
Loss value converges faster and oscillates slightly in the CLR model as we would expect.
损耗值收敛更快,并且在CLR模型中略有波动,正如我们期望的那样。
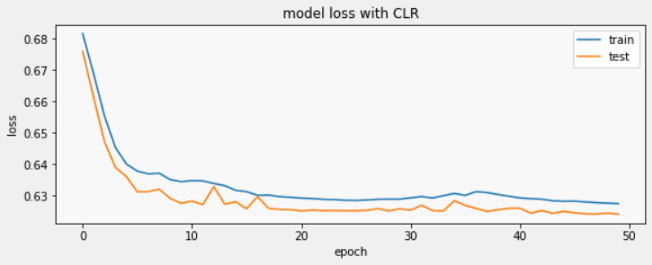
Training accuracy has increased from 64.1% to 64.3%.
训练准确性从64.1%提高到64.3%。
Testing accuracy also improves, from 64.7% to 65%.
测试准确性也从64.7%提高到65%。
结论 (Conclusion)
When you start working with any new dataset, the same values of learning rates you used in previous datasets will not work for your new data. So you have to perform an LR Range Test which gives you a good range for learning rates suitable for your data. Then you can compare your CLR with a fixed learning rate optimizer, as we saw above, to see what suits best to the performance goal you have. So to get this optimal range for the learning rate, you can run the model on a less number of epochs as long as the learning rate keeps increasing linearly. Then oscillating the learning rate between these bounds will be enough to give you a close to optimal result in a few iterations itself.
当您开始使用任何新数据集时,与先前数据集中使用的学习率相同的值将不适用于新数据。 因此,您必须执行LR范围测试,以提供适合您数据的学习率的良好范围。 然后,您可以将CLR与固定学习率优化器进行比较,如上所述,以了解最适合您的性能目标的方法。 因此,要获得最佳的学习率范围,只要学习率保持线性增长,就可以在较少的时期内运行模型。 然后在这些边界之间振荡学习率就足以在几次迭代中使您接近最佳结果。
This optimization technique is clearly a boon as we no longer have to tune the learning rate ourselves. We achieve better accuracy in fewer iterations.
这种优化技术显然是一个福音,因为我们不再需要自己调整学习速度。 我们以更少的迭代次数实现了更高的准确性。
翻译自: https://medium.com/towards-artificial-intelligence/improve-your-ml-models-training-fc0b7a49da4
ml模型















 1532
1532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









