






 本文将探讨有助于精通机器学习项目研究的几种技术和工具,强调在研究阶段应追求简单和专注。
本文将探讨有助于精通机器学习项目研究的几种技术和工具,强调在研究阶段应追求简单和专注。
In my post Research guidelines for Machine Learning project, I explained how to split any Machine Learning projects into two stages (Research and Development) and some tricks to boost the Research stage.
在我的机器学习项目研究指南中,我解释了如何将任何机器学习项目分为两个阶段(研究和开发),以及一些提高研究阶段的技巧。
在本文中,我将深入研究一些技术和工具,以帮助您精通研究。 在此阶段工作时,您应该努力做到简单和专注。 (In this post, I will delve into some techniques and tools that will help you out mastering your Research. While working in this stage, you should strive for simplicity and focus.)
项目布局 (Project layout)
This is the folder layout I tend to use at the beginning of any ML project. This layout is open to extension (such as adding a tests folder, deploy folder, etc) as soon as the project needs to grow up.
这是我在任何ML项目开始时都倾向于使用的文件夹布局。 项目需要长大后,此布局便可以扩展(例如添加tests文件夹, deploy文件夹等)。
project # project root
├── data # data files
├── models # machine learning models
├── notebooks # notebook files
└── src # helper functionsUnlike regular software development projects, ML projects have 3 foundational stones: the source code (notebooks and src), the data consumed/produced by the code, and the model built/consumed by the code and the data.
与常规软件开发项目不同,机器学习项目具有3个基础:源代码(笔记本和src),代码消耗/产生的数据以及代码和数据建立/使用的模型。
📁数据 (📁 data)
After ingesting the data, my recommendation is to process the data in stages, where each stage has its own folder. For example:
摄取数据后,我的建议是分阶段处理数据,每个阶段都有自己的文件夹。 例如:
data
├── raw # original files
├── interim # preprocessed files
└── processed # result filesFrom this layout, you can follow the flow of the data, as in a pipeline: from raw to interim, and then to processed.
通过这种布局,您可以像在管道中那样跟踪数据流:从raw到interim ,再到已processed 。
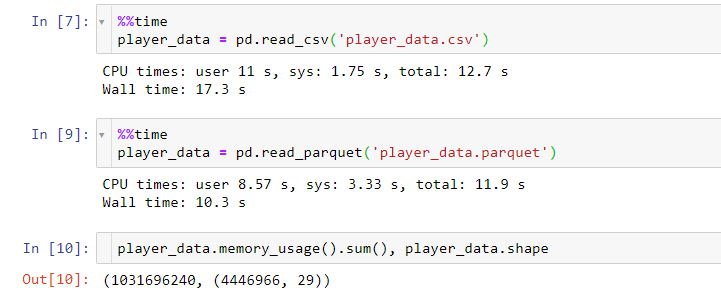
Firstly, the 📁 raw folder stores the data in its original format. In case you can work with offline data, it is very handy to keep always a frozen (read-only) copy of your data. Second, the 📁 interim folder is meant to store data resulting from the data transformations. Probably, these transformations might end up enlarging your dataset. This is the reason I tend to use binary formats, which gain better performance around serialization/deserialization tasks. One of the most used binary formats is parquet (check out how to read/save parquet data using pandas).
首先,📁 raw文件夹存储原始格式的数据。 如果可以使用脱机数据,则始终保持数据的冻结(只读)副本非常方便。 其次,📁 interim文件夹用于存储由数据转换产生的数据。 这些转换可能最终会扩大您的数据集。 这就是我倾向于使用二进制格式的原因,该格式在序列化/反序列化任务方面获得更好的性能。 实木复合地板是最常用的二进制格式之一(查看如何使用pandas读取/保存实木复合地板数据)。
Lastly, the 📁 processed folder is used to store the results of the machine learning model.
最后,已processed文件夹用于存储机器学习模型的结果。
Even though the raw folder can store files in many formats (.csv, .json, .xls, etc), my recommendation is to use some a common format in the interim folder (for example: binary formats such as .parquet, .feather, or raw formats such as .csv, .png) and use a customer-friendly format in the processed folder (for example: .csv or excel file allows stakeholders to review the results of your model). Sometimes makes sense to include summary plots about the results of your model (for example: when building a recommender system, does the distribution of your recommendations follows a similar pattern than your sales distribution?)
即使raw文件夹可以存储多种格式的文件( .csv , .json , .xls等),我的建议还是在interim文件夹中使用一些通用格式(例如: .parquet , .feather等二进制格式)或原始格式(如.csv , .png ),并在processed文件夹中使用客户友好的格式(例如: .csv或excel文件允许涉众查看模型的结果)。 有时包含有关模型结果的摘要图是有意义的(例如:在构建推荐系统时,您的推荐分布是否遵循与销售分布类似的模式?)
📁笔记本 (📁 notebooks)
While working in the Research stage, I use Jupyter Notebooks as my execution platform/IDE. This is the reason most of the code that supports the Machine Learning Lifecycle is hosted in Jupyter Notebooks
在研究阶段工作时,我将Jupyter Notebooks作为执行平台/ IDE。 这就是大多数支持机器学习生命周期的代码托管在Jupyter Notebooks中的原因

So, the notebooks folder resembles (up to some degree) the ML lifecycle:
因此,笔记本文件夹类似于ML生命周期(在某种程度上):
notebooks
├── 1__ingestion # |-> data/raw
├── 1_1__eda
├── 2__preprocessing # |<- data/raw
│ |-> data/interim
├── 2_1__eda
├── 3_1__model_fit_variant_1 # |-> model/variant_1.pkl
├── 3_2__model_fit_variant_2 # |-> model/variant_2.pkl
├── 3_3__models_validation
└── 4__model_predict # |<- data/interim, model/*.pkl
|-> data/processedI won’t delve into detail into what is every notebook responsible, as I think most of you should be related to the Machine Learning lifecycle.
我不会深入研究每个笔记本的责任,因为我认为你们大多数人都应该与机器学习生命周期有关。
And in any case, you should apply the layout and naming conventions that fit your way of working (or use more complex layout templates if you wish). Maybe you will need a couple or more of iterations to find your own blueprint but take it as part of the learning process. For example, I like to split the EDA into two parts, the first one uses only raw data and the second one focuses on the “new data” produced after the pre-processing stage. But if you like doing a single EDA, this is fine also. These project layouts shown here are meant to make you do things with a purpose and do not act following your free will. This will be important once you hand over the project to the next stage (Development), as your teammates will be able to recognize the shape and the components of your project.
在任何情况下,您都应应用适合您工作方式的布局和命名约定(或根据需要使用更复杂的布局
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









